一种基于yolo-tsm的轻量级实时监控异常行为检测方法
技术领域
1.本发明涉及一种基于yolo-tsm的轻量级实时监控异常行为检测方法,属于时空行为检测的技术领域。
背景技术:
2.随着社会的发展与科技的进步,实时监控的覆盖范围越来越广泛,无论是公共场合还是在私人场所,都离不开摄像头进行监控。因此,伴随着视频监控的扩大使用,不可避免的需要监控人员的数量以及付出一定的精力,但仍不可避免出现异常情况的遗漏。很多研究人员为了解决这个问题,在视频理解的基础上,提出了对于网络摄像头的行为检测方法,即对各个场景下人类个体进行实时行为检测,避免人为原因而导致的异常情况遗漏。所以,实时行为检测是满足安防等领域需要的视频检测技术。
3.基于传统rgb深度学习的行为检测(action detection)算法主要分为基于2dcnn的双流卷积算法和3dcnn算法。双流卷积算法由于采用2d卷积网络,所以推理速度即实时性具有较大优势,但对于时间特征的提取能力较差,因此在准确性上不具有优势;3d卷积网络算法则相反,由于网络参数过多实时性较差,而准确性有较大优势。
4.相对于传统的行为识别算法,时空行为检测算法(spatiotemporal action detection)在保证实时性和准确率的基础上,能将场景中的行为定义到识别的每个检测到的个人上,实现基于对象更精确的识别,但相对计算量会较大,所以,目前对于应用在实时视频监控的时空行为检测算法较少。
5.综上,现有技术中存在两大难题,主要难题是:目前对异常行为的实时监控分析,在达到一定准确性的情况下,实时性效果较差,即无法做到对于异常行为实时分析处理。次要难题是:目前通常的行为识别只是将场景内发生的整体行为进行定义,缺少对于场景中每个个体的行为检测分析。
技术实现要素:
6.针对现有技术的不足,本发明提供了一种基于yolo-tsm的轻量级实时监控异常行为检测方法;
7.术语解释:
8.1、mosaic数据增强:将四张传入的关键帧图片,对四张图片进行拼接,每一张图片都有其对应的框框,将四张图片拼接之后就获得一张新的图片,同时也获得这张图片对应的检测框,将目标检测的背景进行丰富。
9.2、cfam模块:cfam模块是基于格拉姆矩阵的注意力机制模型,能够进行全局的特征融合。
10.3、ava数据集:包括youtube公开视频的url,使用包含80个原子动作(atomic action)集进行标注(如[走路]、[踢(某物)]、[握手]),所有动作都有时空定位,从而产生57.6k视频片段、96k标注人类动作和210k动作标签,本发明选择其中的异常行为(打架、跌
倒、奔跑等)作为目标进行训练测试。
[0011]
4、k均值聚类算法(k-mean):是一种迭代求解的聚类分析算法,其步骤是,预将数据分为k组,则随机选取k个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。聚类中心以及分配给它们的对象就代表一个聚类。每分配一个样本,聚类的聚类中心会根据聚类中现有的对象被重新计算。这个过程将不断重复直到满足某个终止条件。
[0012]
5、tsm模块:一种能够使2dcnn不增加大量运算的基础上实现对时间维度信息的特征提取的模块,即扩大了时间感受野,获得了时间信息。
[0013]
本发明的技术方案为:
[0014]
一种基于yolo-tsm的轻量级实时监控异常行为检测方法,包括步骤如下:
[0015]
步骤1:获取数据集并进行预处理;
[0016]
步骤2:构建tsm网络模型;
[0017]
步骤3:构建yolo轻量级网络模型;
[0018]
步骤4:构建特征融合模型;
[0019]
步骤5:将步骤1预处理后得到的数据集对步骤2、3、4构建的tsm网络模型、yolo轻量级网络模型及特征融合模型进行端到端的训练;
[0020]
步骤6:将待检测的视频预处理后输入训练后的yolo-tsm轻量级模型,yolo-tsm轻量级模型包括训练后的tsm网络模型、yolo轻量级网络模型及特征融合模型,tsm网络模型、yolo轻量级网络模型均连接特征融合模型;使用训练得到的权重文件,根据输入的视频信息进行推理,将视频流中行为个体的进行目标检测,并进行行为识别,最终把异常行为定位到场景中的个体身上。
[0021]
根据本发明优选的,所述数据集包括ava数据集和异常行为数据集。
[0022]
根据本发明优选的,步骤1中,对获取的数据集进行预处理,将数据集分别处理为输入tsm网络模型和yolo轻量级网络模型的两种形式:
[0023]
将数据集处理为输入tsm网络模型的形式即张量a,张量a∈r(n,c,t,h,w),n是批处理大小,c是通道数,t是时间维,h和w是空间分辨率;
[0024]
将数据集处理为输入yolo轻量级网络模型的形式即张量b,张量b∈r(n,c,h,w);mosaic数据增强,进行裁剪压缩为h*w,得到张量b,张量b的维度为(n,c,h,w);
[0025]
根据本发明优选的,所述yolo轻量级网络模型的骨干网络为darknet53,包括依次连接的第一conv卷积层、第二conv卷积层、第一residual block模组、第三conv卷积层、第二residual block模组、第四conv卷积层、第三residual block模组、第五conv卷积层、第四residual block模组、第六conv卷积层、第五residual block模组;
[0026]
第一residual block模组包括1个residual block,第二residual block模组包括2个residual block,第三residual block模组包括8个residual block,第四residual block模组包括8个residual block,第五residual block模组包括4个residual block;
[0027]
第一conv卷积层中,经过一个padding=1的[3,3]卷积网络,输出特征,再经过一个标准化层和一个激活函数,继续输出;
[0028]
第二conv卷积层中,经过一次步长为2的[3,3]卷积网络,输出特征;
[0029]
第一residual block模组、第二residual block模组、第三residual block模组、
第四residual block模组、第五residual block模组均包括两个conv层、一个标准化函数和一个激活函数即batchnorm relu层,先通过一个[1,1]的conv层,调整通道数,再经过一个batchnorm relu层,最后经过一个padding=1的[3,3]conv层,输出特征;
[0030]
第三conv卷积层、第四conv卷积层、第五conv卷积层、第六conv卷积层为步长为2、padding=1的[3,3]conv层;
[0031]
最终,yolo轻量级网络模型获得一个[c,h,w]的空间特征张量。
[0032]
根据本发明优选的,tsm网络模型的骨干网络为加入tsm模块的resnet50,包括依次连接的conv卷积层、最大池化层、第一残差模块、第二残差模块、第三残差模块、第四残差模块、以及每一个残差模块之间的激活函数;
[0033]
conv卷积层中,经过一个[7,7]卷积网络,输出特征,再经过一个标准化层和一个激活函数,继续输出;
[0034]
最大池化层中,经过一个[3,3]最大池化层,进行降维减少输入量;
[0035]
第一残差模块包括1个第一模型model-1与2个第二模型model-2;第二残差模块包括1个第一模型model-1与3个第二模型model-2;第三残差模块包括1个第一模型model-1与5个第二模型model-2;第四残差模块包括1个第一模型model-1与3个第二模型model-2;
[0036]
第一模型model-1分为两个分支,一分支首先经过tsm模块再输入进一个[1,1]的conv层,调整通道数,再经一个标准化层和一个激活函数,输入进一个的[3,3]conv层,获取特征,再经过一个标准化层和一个激活函数,输入进不同通道数一个[1,1]的conv层,调整通道数,经一个标准化层,输出;二分支为输入,最终的输出为两个分支相加进行输出;
[0037]
第二模型model-2分为两个分支,一分支首先经过tsm模块输入进一个[1,1]的conv层,调整通道数,再经一个标准化层和一个激活函数,输入进一个的[3,3]conv层,获取特征,再经过一个标准化层和一个激活函数,输入进一个[1,1]的conv层,调整通道数,经一个标准化层,输出;二分支首先进入一个[1,1]的conv层,调整通道数,再经过一个标准化层和一个激活函数,最终的输出为两个分支相加进行输出;
[0038]
最后输出一个[c1,h1,w1]大小的时空特征张量。
[0039]
根据本发明优选的,所述特征融合模型包括依次连接的信道融合模块、cfam模块、第一conv层、第二conv层;
[0040]
信道融合模块中,将tsm网络模型输出的[c1,h1,w1]先输入进一个[1,1]的卷积层,调整为[c2,h,w],再将yolo轻量级网络模型输出[c,h,w]和此特征张量[c2,h,w]在通道维进行链接,得到张量[c3,h,w],c3=c2 c,输入进一个[1,1]的conv层,调整通道数b[c4*h*w],再将每个通道的特征向量的一维化,即使特征向量变为f[c3,n],n=h*w;
[0041]
cfam模块中,将输入的特征向量f[c3,n]与自身的转置向量进行向量乘法,得到格拉姆矩阵g[n,n];计算得到格拉姆矩阵g[n*n]后,使用softmax层生成通道注意图m,进行通道注意图m与f进行矩阵乘法,将得到的结果重新整形为与输入张量b形状相同的三维空间(c*h*w),将此结果与原始输入特征图b结合;
[0042]
第一conv层中,输入进一个[1,1]的conv层,调整通道数,再经过一个标准化层和一个激活函数;
[0043]
第二conv层中,输入进一个[1,1]的conv层,调整通道数,输出特征融合模型的输出d[c4,h,w]。
[0044]
根据本发明优选的,步骤6中,在特征融合模型将最后的卷积层使用1
×
1大小的卷积核,调整输出通道,用k-means算法在相应的数据集上选择5个先验框,生成具有5*(numclasses 4 1)通道数的特征张量,numclasses表示有数据集中numclasses个行为分类置信度得分,4代表目标检测框的4个坐标,1代表检测的置信度;根据这些锚点对边界框的回归进行细化,最终实现对于目标的准确定位检测及行为识别,即时空行为检测。
[0045]
一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现基于yolo-tsm的轻量级实时监控异常行为检测方法的步骤。
[0046]
一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现基于yolo-tsm的轻量级实时监控异常行为检测方法的步骤。
[0047]
本发明的有益效果为:
[0048]
本发明尝试了将优秀的实时目标检测模型yolo与行为识别模型tsm相结合的方式,并使用注意力机制进行特征融合,在保证一定准确度的同时,提高了实时推理速率,并将行为检测精细化,定位场景中检测到的每个行为个体。
附图说明
[0049]
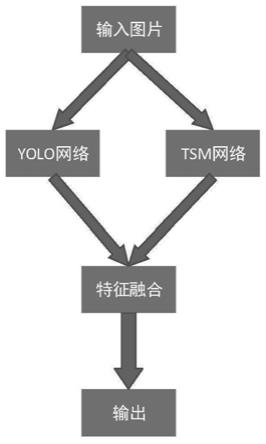
图1为本发明基于yolo-tsm的轻量级实时监控异常行为检测方法的流程示意图;
[0050]
图2为yolo网络的结构示意图;
[0051]
图3为residual block的结构示意图;
[0052]
图4为residual block之间连接结构示意图;
[0053]
图5为tsm网络的结构示意图;
[0054]
图6为残差模块的结构示意图;
[0055]
图7为第一模型model-1的结构示意图;
[0056]
图8为第二模型model-2的结构示意图;
[0057]
图9为tsm网络的原理示意图;
[0058]
图10为特征融合模型的结构示意图;
[0059]
图11为cfam模块的结构示意图;
[0060]
图12为异常行为检测方法的效果图。
具体实施方式
[0061]
下面结合说明书附图和实施例对本发明作进一步限定,但不限于此。
[0062]
实施例1
[0063]
一种基于yolo-tsm的轻量级实时监控异常行为检测方法,如图1所示,包括步骤如下:
[0064]
步骤1:获取数据集并进行预处理;
[0065]
步骤2:构建tsm网络模型;
[0066]
步骤3:构建yolo轻量级网络模型;
[0067]
步骤4:构建特征融合模型;
[0068]
步骤5:将步骤1预处理后得到的数据集对步骤2、3、4构建的tsm网络模型、yolo轻量级网络模型及特征融合模型进行端到端的训练;
[0069]
步骤6:将待检测的视频预处理后输入训练后的yolo-tsm轻量级模型,yolo-tsm轻量级模型包括训练后的tsm网络模型、yolo轻量级网络模型及特征融合模型,tsm网络模型、yolo轻量级网络模型均连接特征融合模型;使用训练得到的权重文件,根据输入的视频信息进行推理,将视频流中行为个体的进行目标检测,并进行行为识别,最终把异常行为定位到场景中的个体身上。
[0070]
实施例2
[0071]
根据实施例1所述的一种基于yolo-tsm的轻量级实时监控异常行为检测方法,其区别在于:
[0072]
数据集包括ava数据集(部分)和异常行为数据集。异常行为数据集是从youtube网站上采集的视频数据集,包括打架、跌倒、奔跑等异常行为,也包括站立、行走等正常行为,一共约1000段10s的视频。
[0073]
步骤1中,对获取的数据集进行预处理,将数据集分别处理为输入tsm网络模型和yolo轻量级网络模型的两种形式:
[0074]
将数据集处理为输入tsm网络模型的形式即张量a,张量a∈r(n,c,t,h,w),n是批处理大小,c是通道数,t是时间维,h和w是空间分辨率;具体是指:取连续的8帧图片,并进行裁剪压缩为224*224,即将维度变为(1,3,8,224,224)输入tsm网络模型。
[0075]
将数据集处理为输入yolo轻量级网络模型的形式即张量b,张量b∈r(n
×c×h×
w);具体是指:取若干张图片的关键帧,对其进行mosaic数据增强,进行裁剪压缩为h*w,得到张量b,张量b的维度为(n,c,h,w);取8张图片的关键帧,这里选择第8张,进行mosaic数据增强,并进行裁剪压缩为416*416,b的维度为(1,3,416,416),后输入yolo轻量级网络模型。
[0076]
yolo轻量级网络模型的骨干网络(backbone)为darknet53,如图2所示,包括依次连接的第一conv卷积层、第二conv卷积层、第一residual block模组、第三conv卷积层、第二residual block模组、第四conv卷积层、第三residual block模组、第五conv卷积层、第四residual block模组、第六conv卷积层、第五residual block模组;
[0077]
第一residual block模组包括1个residual block,第二residual block模组包括2个residual block,第三residual block模组包括8个residual block,第四residual block模组包括8个residual block,第五residual block模组包括4个residual block;
[0078]
第一conv卷积层中,经过一个padding=1的[3,3]卷积网络,输出特征,再经过一个标准化层(batchnorm)和一个激活函数(relu),继续输出;
[0079]
第二conv卷积层中,经过一次步长为2的[3,3]卷积网络,输出特征;
[0080]
第一residual block模组、第二residual block模组、第三residual block模组、第四residual block模组、第五residual block模组均包括两个conv层、一个标准化函数(batchnorm)和一个激活函数(relu)即batchnorm relu层,如图3所示,先通过一个[1,1]的conv层,调整通道数,再经过一个batchnorm relu层,最后经过一个padding=1的[3,3]conv层,输出特征;
[0081]
第三conv卷积层、第四conv卷积层、第五conv卷积层、第六conv卷积层为步长为2、padding=1的[3,3]conv层;
[0082]
如图4所示,在第一residual block模组、第二residual block模组、第三residual block模组、第四residual block模组、第五residual block模组之间,经过一个
步长为2、padding=1的[3,3]conv层,输出特征;
[0083]
最终,yolo轻量级网络模型获得一个[c,h,w]的空间特征张量。
[0084]
tsm网络模型的骨干网络(backbone)为加入tsm模块的resnet50,如图5所示,包括依次连接的conv卷积层、最大池化层、第一残差模块(block1)、第二残差模块(block2)、第三残差模块(block3)、第四残差模块(block4)、以及每一个残差模块之间的激活函数(relu);
[0085]
conv卷积层中,经过一个[7,7]卷积网络,输出特征,再经过一个标准化层(batchnorm)和一个激活函数(relu),继续输出;
[0086]
最大池化层中,经过一个[3,3]最大池化层,进行降维减少输入量;
[0087]
如图6所示,残差模块(block)由1个第一模型model-1和多个第二模型model-2连接组成;
[0088]
第一残差模块包括1个第一模型model-1与2个第二模型model-2;第二残差模块包括1个第一模型model-1与3个第二模型model-2;第三残差模块包括1个第一模型model-1与5个第二模型model-2;第四残差模块包括1个第一模型model-1与3个第二模型model-2;
[0089]
如图7所示,第一模型model-1分为两个分支,一分支首先经过tsm模块再输入进一个[1,1]的conv层,调整通道数,再经一个标准化层(batchnorm)和一个激活函数(relu),输入进一个的[3,3]conv层,获取特征,再经过一个标准化层(batchnorm)和一个激活函数(relu),输入进不同通道数一个[1,1]的conv层,调整通道数,经一个标准化层(batchnorm),输出;二分支为输入,最终的输出为两个分支相加进行输出;
[0090]
如图8所示,第二模型model-2分为两个分支,一分支首先经过tsm模块输入进一个[1,1]的conv层,调整通道数,再经一个标准化层(batchnorm)和一个激活函数(relu),输入进一个的[3,3]conv层,获取特征,再经过一个标准化层(batchnorm)和一个激活函数(relu),输入进一个[1,1]的conv层,调整通道数,经一个标准化层(batchnorm),输出;二分支首先进入一个[1,1]的conv层,调整通道数,再经过一个标准化层(batchnorm)和一个激活函数(relu),最终的输出为两个分支相加进行输出;
[0091]
tsm网路改进后的残差模块(block):如图7,8,在所有残差模块(block)的所有model-1和model-1的一分支输入先加入一个tsm模块。
[0092]
tsm模块:tsm网络则是在每一个残差分支中,加入tsm模块,并取消最后的全连接层,直接输入至特征融合模型,原理如图9所示,时刻tensor中temporal和channel维度;中间是通过stm模块位移后的的矩阵,可见前两个channel向前位移一步来表征的feature maps,最后位移后的空缺padding补零。对于每个插入的时间移位模块,时间感受野将扩大2,就好像沿着时间维度运行内核大小为3的卷积一样。因此,tsm模块具有很大的时间感受野,可以获取高度复杂的时空信息。
[0093]
激活函数:在每一个model的连接之间(包括两个残差模块之间的model)都经过一个激活函数(relu)。
[0094]
最后输出一个[c1,h1,w1]大小的时空特征张量。
[0095]
步骤4采用的特征融合模型根据通道之间的关系如图10所示,将不同分支的特征进行平滑的聚合,所述特征融合模型包括依次连接的信道融合模块(channel fusion)、cfam模块、第一conv层、第二conv层;
[0096]
信道融合模块(channel fusion)中,将tsm网络模型输出的[c1,h1,w1]先输入进一个[1,1]的卷积层,调整为[c2,h,w],再将yolo轻量级网络模型输出[c,h,w]和此特征张量[c2,h,w]在通道维进行链接,得到张量[c3,h,w],c3=c2 c,输入进一个[1,1]的conv层,调整通道数b[c4*h*w],再将每个通道的特征向量的一维化,即使特征向量变为f[c3,n],n=h*w;
[0097]
cfam模块中,如图11所示,将输入的特征向量f[c3,n]与自身的转置向量进行向量乘法,得到格拉姆矩阵g[n,n];gram(格拉姆)矩阵可以映射通道间的依赖关系;计算得到格拉姆矩阵g[n*n]后,使用softmax层生成通道注意图m,进行通道注意图m与f进行矩阵乘法,将得到的结果重新整形为与输入张量b形状相同的三维空间(c*h*w),将此结果与原始输入特征图b结合;
[0098]
第一conv层中,输入进一个[1,1]的conv层,调整通道数,再经过一个标准化层(batchnorm)和一个激活函数(relu);
[0099]
第二conv层中,输入进一个[1,1]的conv层,调整通道数,输出特征融合模型的输出d[c4,h,w]。
[0100]
步骤5的具体实现过程如下:
[0101]
采用的训练配置如下:
[0102]
硬件环境:
[0103]
cpu:amd ryzen 7 5800h
[0104]
gpu:nvida geforce rtx 3060(6g)
[0105]
内存:16g
[0106]
软件环境:
[0107]
os:windows 10
[0108]
python:anaconda3 python3.7
[0109]
cuda:11.1
[0110]
torch:1.8.0
[0111]
步骤5.1:tsm网络模型采用kinetics上的预训练模型初始化,yolo轻量级网络模型采用co-co数据集上的预训练模型初始化;减少训练所需要的数据量,虽然是两个网络但参数可以联合更新,完整的体系结构是在pytorch中实现和端到端训练的。
[0112]
步骤5.2:训练过程中实时计算loss函数,边界框使用smooth l1loss函数,smooth l1loss函数是将连续的图片输入进tsm网络模型、yolo轻量级网络模型进行进行预测推理,再将真实的结果进行编码,变为tsm网络模型、yolo轻量级网络模型的推理结果的形式,真实的结果包括真实框的位置信息及行为的类别,即:将各个预测框和所有的真实框对比计算四个框坐标的差异以及行为类别种类的差异,作为损失;
[0113]
在计算完损失之后,进行反向传播进行优化;
[0114]
训练中,选择具有权值衰减策略的小批量随机梯度下降算法对损失函数进行优化;
[0115]
在yolo轻量级网络模型上进行数据增强根据随机数种子随机进行镜像、改变比例等,增强泛化能力。初始的学习率设为0.0001,在经过30k次迭代之后会衰减到0.4,对于使用的部分ava数据集在训练15个epoch得到较好的效果,拥有较好的泛化能力。
[0116]
采用的数据集为ava的部分异常行为数据集,ava包括youtube公开视频的url,使用包含80个原子动作(atomic action)集进行标注(如[走路]、[踢(某物)]、[握手]),所有动作都有时空定位,从而产生57.6k视频片段、96k标注人类动作和210k动作标签,本发明选择其中的异常行为(打架、跌倒、奔跑等)作为目标进行训练测试。
[0117]
另外采用自定义数据集进行训练,对网络上的一些异常行为视频进行分析,取得了不错的效果。如表1所示:
[0118]
表1
[0119][0120]
特征融合模型根据通道之间的关系,将不同分支的特征进行平滑的聚合,极大的增强了特征识别能力。在特征融合模型中,实际上实现了将行为定义到了个体身上,将行为与在yolo网络中得到的目标检测结果进行链接,对图像上实施行为的个体的进行标定。
[0121]
步骤6中,在特征融合模型将最后的卷积层使用1
×
1大小的卷积核,调整输出通道,用k-means算法在相应的数据集上选择5个先验框,生成具有5*(numclasses 4 1)通道数的特征张量,numclasses表示有数据集中numclasses个行为分类置信度得分,4代表目标检测框的4个坐标,1代表检测的置信度;根据这些锚点对边界框的回归进行细化,最终实现对于目标的准确定位检测及行为识别,即时空行为检测。
[0122]
图12为本发明检测方法得到的效果图,图12是对网络视频进行实时检测,可以看出本发明对于视频的中两个人员的行为检测为打架(fight),同时对实施行为的人员也进行了定位,取得了较好的检测效果。
[0123]
实施例3
[0124]
一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现基于yolo-tsm的轻量级实时监控异常行为检测方法的步骤。
[0125]
实施例4
[0126]
一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现基于yolo-tsm的轻量级实时监控异常行为检测方法的步骤。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
