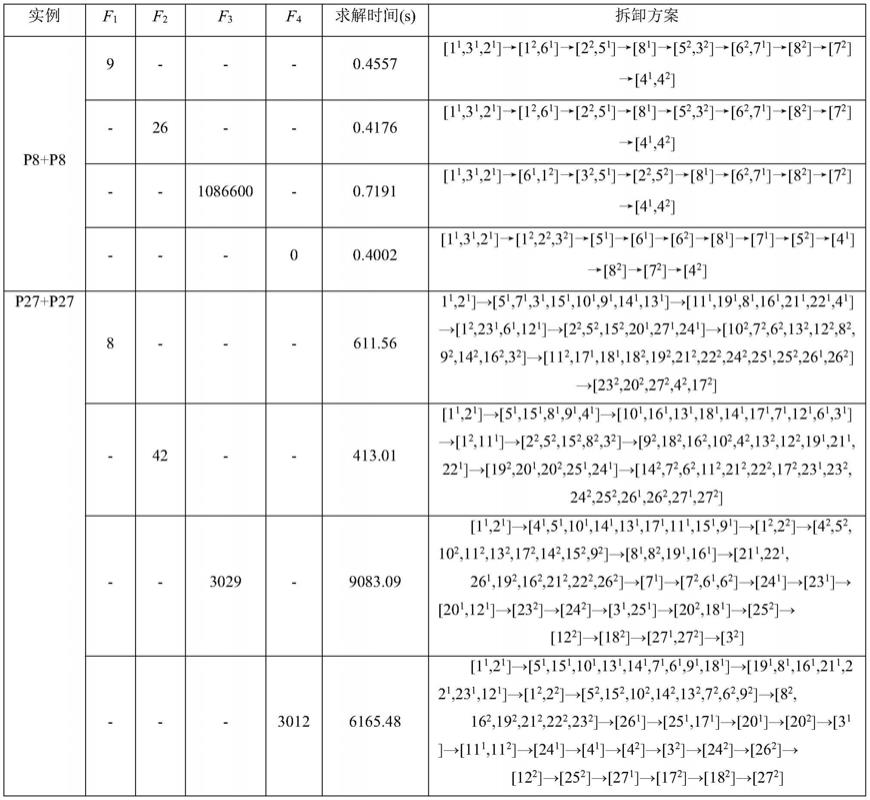
1.本发明涉及一种基于非平行语料库的熵模型英中作者实体自动识别方法,属于人工智能领域。
背景技术:
2.中英文命名实体对齐尤其是人名的对齐一直是自然语言处理中一个非常重要的课题,它对于机器翻译、跨语言信息检索的发展具有重要作用。
3.很多学者采用不同方法对齐进行过研究。一种是在双语实体识别的基础上,利用对齐模型寻找两者的对齐关系,另一种方法是仅在一种语言中识别命名实体,然后利用融合多特征的对齐模型,在另一个语言中寻找它们对应的翻译。
4.音译中的对齐同机器翻译中的一样,都是进行源到目标语言端字符串的对齐概率计算,多种专门针对音译的对齐方法被提出。近几年,非参数模型在各个方向上开始应用并取得了不错的效果;y.huang借助中文拼音创建英文到中文拼音的上下文无关文法,将同步适应文法(synchronousadaptorgrammars)应用到音译中;并利用非参数贝叶斯模型训练每条文法在各种情况下的概率;m.hagiwara将狄利克雷混合模型应用到英译中,也取得了不错的结果。在音译领域已经有一套完整的技术路线,包括:可比语料和网络搜索等方式抽取等价音译对;使用基于规则、基于统计等方式建立音译模型;采用基于音素、基于字素、基于混合、系统融合等思路进行音译模型建立;采用准确率、meanf-score、mrr、mapref等音译指标指标。jinhankim把跨语言命名实体间的语音相似度、命名实体上下文间的相似度、命名实体间关系的相似度和命名实体关系上下文的相似度结合起来,形成图映射方法。音译的解码通常采用对数线性模型,基于特征和权重进行翻译候选的生成。
5.但目前对文献英文表示的作者姓名与中文作者的对齐,仍没有成熟的解决方案。
技术实现要素:
6.本发明着重解决英文表示的文献作者进行中文姓名的翻译问题。发明技术方案如下:
7.步骤一:构建中英文非平行语料库;
8.语料包括来自英文文献数据库中文献的题目、作者、机构、关键词、摘要;中文文献数据库中论文的中英文题目、中英文作者姓名、中英文机构、中英文关键词、中英文摘要;
9.步骤二:基于构建的医学中英文文献摘要非平行语料库生成人名及机构词典;
10.步骤三:构建英中文献作者音译特征函数f1和f2;
11.中文作者姓名cn=cnx cnm,其中cnx由1-2个汉字组成,cnm由1-3个汉字组成,每个汉字转换为拼音,表示为{cnx
11
,cnx
12
,
…
,cnx
1n
,cnx
21
,cnx
22
,...cnx
2m
},cnm对应的拼音字母序列为{cnm1,cnm2...,cnm
t
}英文表达的作者姓名en有m个字母组成,表示为{e1,e2,
…
,em},则cn和en的音译特征函数f1(cn,en)可以表示为:
[0012][0013]
其中,
[0014][0015]
根据f2计算英文字母串与中文拼音串的相似度。其中,p(e’|cnmr)为英文字母串为汉字cnmr的概率,p(cnmr|e’)为汉字cnmr为英文字母串e’的概率;
[0016]
步骤四:构建机构特征函数f3,
[0017][0018]
其中ins()为翻译函数,ins(cn)为中文机构名称翻译后的英文名称字符串,cs(en)为英文机构名称字符串。
[0019]
步骤五:构建论文主题相似特征函数f4,
[0020][0021]
其中
[0022][0023]
a、b、c为是三个n维向量,a是[a1,a2,...,an],b是[b1,b2,...,bn],a是待评价的论文标题、关键词及摘要的词向量,ai是词向量中的第i维;b、c为已确定的某位作者的不同两篇论文的标题、关键词及摘要组成的词向量,bi、ci是词向量中的第i维;在计算主题相似性时将一篇文章标题中的实体及关键词采用fasttext模型进行向量化,然后对生成的向量进行叠加生成文章的主题向量;
[0024]
步骤六:构建最大熵模型
[0025][0026]
其中p为满足约束集条件下的某一统计模型。argmax表示寻找具有最大评分的参量。
[0027]
假设存在i个特征,所求的模型是在满足约束集合的条件下生成的模型,特征fi的权重用相对应的参数λi表示,则英中作者对齐的概率公式为:
[0028][0029]
其中y为是否是同一作者,x为特征,i为熵模型特征数量,取值范围为1~4,fi依次
为步骤三、步骤四、步骤五中的f1、f2、f3、f4;
附图说明
[0030]
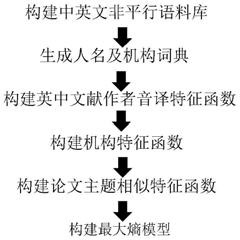
附图1 方法流程图
[0031]
附图2 fasttext模型结构
具体实施例
[0032]
如附图1所示,首先根据步骤一:构建中英文非平行语料库;
[0033]
本发明采集pubmed数据库中国别为中国的论文题目、作者、机构、关键词、摘要;采集万方、cnki中文文献数据库中医学卫生健康领域论文中英文题目、作者姓名、机构、关键词、摘要;
[0034]
根据步骤二,基于步骤一中构建的非平行语料库中文献,生成人名及机构名词典;
[0035]
根据步骤三:构建英中文献作者音译特征函数f1和f2;
[0036]
中文作者姓名cn=cnx cnm,其中cnx由1-2个汉字组成,cnm由1-3个汉字组成,每个汉字转换为拼音,表示为{cnx
11
,cnx
12
,
…
,cnx
1n
,cnx
21
,cnx
22
,...cnx
2m
},cnm对应的拼音字母序列为{cnm1,cnm2...,cnm
t
}英文表达的作者姓名en有m个字母组成,表示为{e1,e2,
…
,em},则cn和en的音译特征函数f1(cn,en)可以表示为:
[0037][0038][0039]
根据f2计算英文字母串与中文拼音串的相似度;其中,p(e’|cnmr)为英文字母串为汉字cnmr的概率,p(cnmr|e’)为汉字cnmr为英文字母串e’的概率;
[0040]
根据步骤四:构建机构特征函数f3,
[0041][0042]
其中ins()为翻译函数,ins(cn)为中文机构名称翻译后的英文名称字符串,cs(en)为英文机构名称字符串。
[0043]
根据步骤五:构建论文主题相似特征函数f4,
[0044][0045]
其中
[0046][0047]
a、b、c为是三个n维向量,a是[a1,a2,...,an],b是[b1,b2,...,bn],a是待评价的论文标题、关键词及摘要的词向量,ai是词向量中的第i维;b、c为已确定的某位作者的不同两篇论文的标题、关键词及摘要组成的词向量,bi、ci是词向量中的第i维;在计算主题相似性时将一篇文章标题中的实体及关键词采用fasttext模型进行向量化,然后对生成的向量进行叠加生成文章的主题向量;
[0048]
fasttext模型结构如图2所示。使用fasttext进行词向量的训练时,词向量的维度是100,窗口大小为5。
[0049]
根据步骤六,构建熵模型
[0050][0051]
其中p为满足约束集条件下的某一统计模型。argmax表示寻找具有最大评分的参量。
[0052]
假设存在i个特征,所求的模型是在满足约束集合的条件下生成的模型,特征fi的权重用相对应的参数λi表示,则英中作者对齐的概率公式为:
[0053][0054]
其中y为是否是同一作者,x为特征,i为熵模型特征数量,取值范围为1~4,fi依次为步骤三、步骤四、步骤五中的f1、f2、f3、f4;
[0055]
如输入英文标题,作者,机构,关键词[oral versus intravenous palonosetron in chinese cancer patients receiving moder;vention;impact;emesis;mascc;esmo;’li,wei’,’jilin univ,hosp 1’]后,输出为可能为同一作者计算结果为:(李薇,吉林大学第一医院):0.985,(李伟,吉林大学第一医院):0.862,(李伟,中山大学肿瘤防治中心):0.471,(李威,中国医科大学附属盛京医院):0.017,(李伟,天津市北辰区中医医院):0.015。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。