1.本发明涉及一种多智能体一致性控制方法,特别是涉及一种多智能体一致性强化学习控制方法。
背景技术:
2.由于分布式计算、传感器技术,以及通信技术的迅速发展,实际系统的每个单元都具有协同计算和处理复杂任务的能力。因此,多智能体系统应运而生。多智能体系统一致性问题是多智能系统研究中基本并且相当重要的问题,其主要任务是利用智能体之间的状态信息设计一致性控制协议,从而随着时间的推移使得所有智能体的状态相同。
3.在实际应用中,多智能系统的动力学模型不能完全准确的确定,系统多为非线性系统,并且含有干扰,智能体之间相互耦合,再加上智能体之间通信时滞的存在,使得多智能体系统一致性控制更加困难。滑模控制是一种鲁棒控制方法,其根本特点是可以针对系统的不确定性和受到外部扰动时系统具有良好的控制性能和强鲁棒性。强化学习是机器学习的子领域,其参照哺乳动物的学习机制,即智能体不断地通过与环境的交互改变其行为以实现累积奖励最大化。
4.现有多智能体一致性控制方法大多只考虑系统为一阶或者二阶的情形,然而实际有些场景要求多智能体系统具有很强的机动性,即要求多智能体系统实现高阶一致性。部分多智能体一致性控制方法未考虑智能体之间由于通信带宽有限而存在的时滞、外部干扰对多智能体系统一致性的影响,或者仅考虑的多智能体系统为线性多智能体,然而实际中绝大部分多智能体系统为非线性系统。
技术实现要素:
5.针对现有的多智能体系统一致性控制方法存在的问题以及为了实现多智能体系统达到最优一致性,本发明的目的是提供一种多智能体一致性强化学习控制方法,该方法设计的分布式滑膜积分控制器不仅能抵抗外界扰动使系统具有强鲁棒性,而且使系统具有自学习能力从而实现最优一致性。
6.为了解决现有技术存在的问题,本发明采用以下技术方案:
7.一种基于滑模控制的多智能体一致性强化学习控制方法,所述多智能体系统中跟随者的模型为:
[0008][0009]
其中,代表智能体i的第j阶的状态,f(xi)为连续非线性函
数,ui(t)为控制输入,di(t)为未知干扰;
[0010]
所述多智能体系统中领导者动力学方程为:
[0011][0012]
其中,代表领导者的第j阶的状态,f(x0)为连续非线性函数,d0(t)为未知干扰;
[0013]
n个跟随者智能体能够获取自身的各阶状态信息以及与其相连接的延迟时间τ的邻居智能体j的状态信息;
[0014]
包括以下步骤:
[0015]
步骤1:由所述多智能体系统模型,定义智能体i的第j个分量的局部邻居误差:
[0016][0017]
其中,a
ij
为智能体i与智能体j之间的权重,bi为智能体i与领导者的权重,∑为拓扑图中智能体j到智能体i的所有拓扑关系的总和;
[0018]
步骤2:通过式(3)得到智能体i的局部邻居误差系统方程:
[0019][0020]
步骤3:定义虚拟控制器:v
iι
(t)=f(xi) ui(t)
ꢀꢀꢀꢀ
(5)
[0021]
步骤4:根据实际多智能体之间通信存在的时滞,构建公式,定义如下:
[0022][0023]
其中,其中,为分布式最优控制器,为分布式积分滑模控制器,为智能体j具有时滞信息的虚拟控制器,τ为通信时滞;
[0024]
步骤5:n个跟随者智能体根据自己的状态信息及其邻居智能体的信息来分别构建局部邻居误差动力学方程向量形式为:
[0025]
[0026]
其中,δi(t)为智能体i的状态误差向量,为智能体i的复合控制器,v
jι
(t)为关于智能体j的虚拟控制器,δ
ij
(t)=∑a
ij
(di(t)-dj(t)) bi(di(t)-dj(t));
[0027]
步骤6:设计分布式积分滑模控制器;
[0028]
步骤7:设计分布式最优控制器。
[0029]
进一步地,所述步骤6设计分布式积分滑模控制器包括以下步骤:
[0030]
步骤6.1:对所述分布式积分滑模控制器,选用积分滑模面为:
[0031][0032]
其中,δi为智能体i的状态误差向量,si(δi)为滑模函数,s
i0
(δi)为关于δi(t)的函数,s
i0
(δ0)为常数,
[0033]
步骤6.2:根据所选积分滑模面式(8)设计分布式积分滑模控制器为:
[0034][0035]
其中,β(0<β<1)为通信时滞系数,定义ri(t)的导数:σ0(σ0>0)为常数,sgn(
·
)为符号函数,v
jι
(t)为关于智能体j的虚拟控制器,δ
ij
(t)=∑a
ij
(di(t)-dj(t)) bi(di(t)-dj(t));
[0036]
所述步骤7设计分布式最优控制器包括以下步骤:
[0037]
步骤7.1:当智能体达到滑模面时,设计式(10)的等效控制器为:
[0038][0039]
步骤7.2:智能体达到滑模面后,式(7)则为:
[0040][0041]
步骤7.3:提出如下性能指标:
[0042][0043]
其中,γi为折扣因子,qi≥0为半正定矩阵,ri>0为正定矩阵;
[0044]
步骤7.4:基于所提出的性能指标,定义其值函数为:
[0045][0046]
步骤7.5:根据最优控制理论,提出如下哈密尔顿函数:
[0047][0048]
有如下hjb方程:
[0049][0050]
步骤7.6:得到分布式最优控制器:
[0051]
进一步地,所述hjb方程采用基于策略迭代强化学习算法的actor-critic神经网络求解,求解过程包括以下步骤:
[0052]
所述值函数采用critic神经网络逼近:其中,表示critic神经网络估计权值,φi(δi)为神经网络激活函数;
[0053]
所述分布式最优控制器采用actor神经网络估计:
[0054][0055]
其中,表示actor神经网络估计权值,为激活函数的导数;
[0056]
所述critic神经网络估计权值采用如下方程更新:
[0057][0058]
其中,q
i1
为critic神经网络的学习率;
[0059]
所述actor神经网络估计权值采用如下方程更新:
[0060][0061]
其中,q
i2
为actor神经网络的学习率,g
i1
与g
i2
为可调参数。
[0062]
进一步地,所述分布式积分滑模控制器具有自适应学习能力,分布式积分滑模控
制器的自适应学习算法,包括以下步骤:
[0063]
s1:初始化;
[0064]
s2:计算
[0065]
s3:计算分布式滑模面:si(δi(t));
[0066]
s4:计算分布式积分滑模控制器:
[0067]
s5:计算复合控制器:
[0068]
s6:由式(6)计算v
iι
(t);
[0069]
s7:计算实际控制器:ui(t)=v
iι
(t)-f(xi(t));
[0070]
s8:计算值函数:
[0071]
s9:更新critic神经网络权值;
[0072]
s10:更新actor神经网络权值;
[0073]
s11:重复步骤s2-s10,直到收敛。
[0074]
优选地,所述步骤s1初始化包括:初始化领导者的状态x0(0)与跟随者的状态xi(0),令并且初始化critic神经网络权值和actor神经网络权值
[0075]
优选地,所述步骤s2是通过式(19)计算
[0076]
优选地,所述步骤s3是通过式(8)计算分布式滑模面si(δi(t))。
[0077]
优选地,所述步骤s4是通过式(10)计算分布式积分滑模控制器
[0078]
优选地,所述步骤s9是通过式(20)更新critic神经网络权值。
[0079]
优选地,所述步骤s10是通过式(21)更新actor神经网络权值。
[0080]
本发明所具有的优点与有益效果是:
[0081]
本发明一种多智能体一致性强化学习控制方法,该方法通过将虚拟控制器和复合控制器相结合来设计分布式滑模控制器,设计的分布式滑膜积分控制器不仅能抵抗外界扰动使系统具有强鲁棒性而且使系统具有自学习能力从而实现最优一致性。
[0082]
本发明方法针对带有模型不确定性和外部干扰以及含有通信时滞的高阶多智能体系统,首次提出考虑智能体通信时滞的包含邻居智能体信息的滑模面设计方法,设计了分布式滑模面,去除了每个智能体的不确定性,使得系统具有很强的鲁棒性。同时,在设计分布式滑模面时,考虑了智能体邻居节点的各阶状态信息,提升了整个多智能体系统的抗扰性能。由于滑模面的设计是基于强化学习求解的最优控制器,使得所有智能体均能够通过近似最优的方法跟随领导者且具有很好的鲁棒性。在设计控制律时为基于高阶多智能体系统设计的并且考虑了智能体之间的通信时滞对多智能体系统一致性的影响,因此本发明还能够满足在时滞的情况下的高阶一致性。
附图说明
[0083]
下面结合附图对本发明具体方法、实现过程,以及实现效果做作进一步的说明,
[0084]
图中:
[0085]
图1为本发明一种多智能体一致性强化学习控制方法的框架图;
[0086]
图2为多智能体系统第一阶状态跟踪图;
[0087]
图3为多智能体系统第二阶状态跟踪图;
[0088]
图4为critic神经网络权值收敛图;
[0089]
图5为actor神经网络权值收敛图;
[0090]
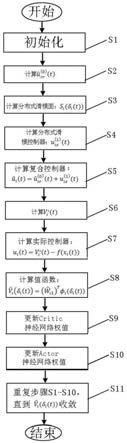
图6为分布式积分滑模控制器自适应学习算法流程图。
具体实施方式
[0091]
为了更好的解释本发明,以便于理解,下面结合附图所示实施例对本发明具体实施方式进行详细说明。
[0092]
如图1所示,本发明一种多智能体一致性强化学习控制方法,包括以下步骤:
[0093]
其中,所述多智能体中跟随者动态模型为:
[0094][0095]
其中,代表智能体i的第j阶的状态,f(xi)为连续非线性函数,ui(t)为控制输入,di(t)为未知干扰。
[0096]
所述多智能体系统中领导者动力学方程为:
[0097][0098]
其中,代表领导者的第j阶的状态,f(x0)为连续非线性函数,d0(t)为未知干扰。
[0099]
步骤1:由所述多智能体动力学模型,定义智能体i的第j个分量的局部邻居误差:
[0100][0101]
其中,a
ij
为智能体i与智能体j之间的权重,bi为智能体i与领导者之间的权重,∑为拓扑图中智能体j到智能体i的所有拓扑关系的总和。
[0102]
步骤2:根据式(3)第j个分量的局部邻居误差方程可得智能体i的局部邻居误差系统方程:
[0103][0104]
步骤3:定义虚拟控制器:v
iι
(t)=f(xi) ui(t)
ꢀꢀꢀꢀ
(5)
[0105]
步骤4:构建公式,该公式考虑到实际多智能体之间通信存在的时滞,定义如下:
[0106][0107]
其中,复合控制器复合控制器为分布式最优控制器,为分布式积分滑模控制器,为智能体j具有时滞信息的虚拟控制器,τ为通信时滞;
[0108]
步骤5:所述n个智能体(跟随者)根据自己的状态信息及其邻居智能体的信息来分别构建局部邻居误差动力学方程向量形式为:
[0109][0110]
其中,δi(t)为智能体i的状态误差向量,为复合控制律,v
jι
(t)为关于智能体j的虚拟控制器,δ
ij
(t)=∑a
ij
(di(t)-dj(t)) bi(di(t)-dj(t))。
[0111]
步骤6:设计分布式积分滑模控制器,包括以下步骤:
[0112]
步骤6.1:选用积分滑模面为:
[0113][0114]
其中,δi为智能体i的状态误差向量,si(δi)为滑模函数,s
i0
(δi)为关于δi(t)的函数,s
i0
(δ0)为常数,
[0115]
步骤6.2:对选用的积分滑模面求导为:
[0116][0117]
步骤6.3:根据所选积分滑模面式(8)设计相应的分布式积分滑模控制器为:
[0118][0119]
其中,β(0<β<1)为通信时滞系数,定义ri(t)的导数:σ0(σ0>0)为常数,sgn(
·
)为符号函数,v
jι
(t)为关于智能体j的虚拟控制器,δ
ij
(t)=∑a
ij
(di(t)-dj(t)) bi(di(t)-dj(t))。
[0120]
步骤7:设计分布式最优控制器,包括以下步骤:
[0121]
步骤7.1:根据式(10),当智能体达到滑模面时,其等效控制器为:
[0122][0123]
步骤7.2:相应地,智能体达到滑模面后,其误差动力学方程则为:
[0124][0125]
步骤7.3:为了实现所述多智能体系统实现最优一致性,提出如下性能指标:
[0126][0127]
其中,γi为折扣因子,qi≥0为半正定矩阵,ri≥0为正定矩阵。
[0128]
步骤7.4:基于所提出的性能指标,定义其值函数为:
[0129][0130]
步骤7.5:根据最优控制理论,提出如下哈密尔顿函数:
[0131][0132]
有如下hamilton-jacobi-bellman(hjb)方程:
[0133][0134]
步骤7.6:由此,得到分布式最优控制器:
[0135]
根据所述最优控制器可知,欲得到最优的控制协议,需要先求解hjb方程。以下,采用基于策略迭代强化学习算法的actor-critic神经网络求解hjb方程,包括以下步骤:
[0136]
所述值函数采用critic神经网络逼近:其中,表示critic神经网络估计权值,φi(δi)为神经网络激活函数。
[0137]
所述最优控制律采用actor神经网络估计:
[0138][0139]
其中,表示actor神经网络估计权值,为激活函数的导数。
[0140]
所述critic神经网络估计权值采用如下方程更新:
[0141][0142]
其中,q
i1
为critic神经网络的学习率。
[0143]
所述actor神经网络估计权值采用如下方程更新:
[0144][0145]
其中,,为actor神经网络的学习率,g
i1
与g
i2
为可调参数。
[0146]
如图6所示,所述分布式积分滑模控制器具有自适应学习能力,由于所述分布式积分滑模控制器自适应学习算法的学习目标是得到最优控制协议:因此所述分布式积分滑模控制器自适应学习算法,包括以下步骤:
[0147]
s1:初始化:初始化领导者的状态x0(0)与跟随者的状态xi(0),令v
jι
(-τ)=0,并且初始化critic神经网络权值和actor神经网络权值
[0148]
s2:由式(19)计算
[0149]
s3:由式(8)计算分布式滑模面:si(δi(t));
[0150]
s4:由式(10)计算分布式滑模控制器:
[0151]
s5:计算复合控制器:
[0152]
s6:由式(6)计算v
iι
(t);
[0153]
s7:计算实际控制器:ui(t)=v
iι
(t)-f(xi(t));
[0154]
s8:计算值函数:
[0155]
s9:由式(20)更新critic神经网络权值;
[0156]
s10:由式(21)更新actor神经网络权值;
[0157]
s11:重复步骤s1-s10,直到收敛。
[0158]
实施例1:
[0159]
为了更加直观的展示本发明所提出的多智能体一致性强化学习控制方法的有效性,采用matlab软件对本发明提出的方法进行仿真实验。
[0160]
跟随者为带有外部干扰的二阶非线性状态方程:
[0161][0162]
其中,i=1,2,3,4,di(t)=2sin(t) 2,
[0163]
领导者的状态方程为:
[0164][0165]
其中,d0(t)=cos(t)。
[0166]
根据实施案例1得到如图2-图5所示的仿真图。图2是多智能体系统第一阶状态跟踪曲线图,图3是多智能体系统第二阶状态跟踪曲线图,从图2和图3可以看出本发明提出的多智能体系统能够在很短的时间内很好的跟上领导者的运动轨迹。图4为critic神经网络权值收敛曲线图,图5是actor神经网络权值收敛曲线图。从图2-图5中可以看出当权值逐渐收敛于稳定值时,系统的状态也趋于一致,收敛速度较快,同时由于所述实施例为非线性含干扰的系统,从仿真曲线可以看出本发明提出的方法具有很好的鲁棒性。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
