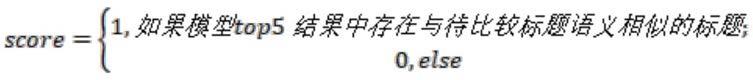
1.本发明涉及一种政策公文标题相似度计算方法,属于公文语义相似度计算技术领域。
背景技术:
2.公文语义相似度计算具有广阔的使用场景,如政研分析人员需要统计相似公文的属地信息、政务公务人员需要参考发达地区相似公文的政策差异、市民企业需要比较不同属地相似公文的优惠政策,而政策公文具有较为固定的格式,特别是标题,其一般由“发文机构”、“发文事由”和“公文体裁”三个部分组成。政策公文的标题相似度,主要考察公文是否在阐述同一个业务,这是语义相似度计算的范畴。
3.面向业务的公文语义相似度需要构建语义相似度语料库,特别是深度学习,需要大规模的标注数据,传统人工标注的方式,面临巨大的挑战。
4.传统相似度计算方式基于字词,无法考虑其内在语义信息。从word2vec开始,语义相似度计算迎来突破,然而word2vec为代表的语义相似度考虑的是静态词嵌入,不能解决一词多义的问题,以elmo和bert为代表的动态词嵌入技术,基本解决了语义相似度的问题。
技术实现要素:
5.为解决上述技术问题,本发明提供了一种政策公文标题相似度计算方法,该政策公文标题相似度计算方法结合关键词抽取和短文本聚类,通过人工调整后,构造三角损失数据集,最后利用albert基于triplet损失训练语义相似度模型,仅需少量人工参与即可构建大量适用公文业务相似度计算的标注数据,且具有很好的相似度计算准确率与召回率。
6.本发明通过以下技术方案得以实现。
7.本发明提供的一种政策公文标题相似度计算方法,包括以下步骤:
8.①
数据清洗:清除标题中因为数据采集混杂进来的错误公文标题,以及无实际业务内容的标题;
9.②
标题处理:识别标题中的机构、日期、体裁信息并剥离相应信息得到业务相关描述;
10.③
业务关键词生成:利用关键词抽取算法,从业务相关描述中抽取每个标题对应的关键词;
11.④
业务聚类:利用短文本主题模型对标题关键词进行聚类;
12.⑤
总体相似度计算:计算标题的总体相似度,使得类内的相似度高于类间的相似度,且类内的相似度重要性以业务相似度、日期相似度、体裁相似度、机构相似度递减;
13.⑥
人工修正:对类内的低相似度标题对和类间高相似度标题对进行手动干预,修正最终的聚类类别数目以及类内、类间的标题相似度可靠程度;
14.⑦
riplet数据集构造t:根据步骤
⑥
的结果,构造triplet数据集;
15.⑧
训练:根据triplet数据集,训练模型,获取公文标题相似度计算模型。
16.所述步骤
②
分为以下步骤:
17.(2.1)时间识别:利用命名实体识别工具识别标题中的日期,并结合正则表达式识别公文标题中的日期段、日期、年度、季度以及季节信息;
18.(2.2)机构识别:利用命名实体识别工具识别标题中的机构,并清洗相关的数字、标点信息;
19.(2.3)体裁识别:根据体裁的组成规则识别体裁位置;
20.(2.4)槽位填充:抽取上述相应信息,并在对应位置填入槽位识别码,步骤(2.1)对应“date”,步骤(2.2)对应“org”,步骤(2.3)对应“theme”。
21.所述步骤
③
中,利用jieba抽取关键词,结合词性来增进抽取结果,每个标题最多允许10个关键词。
22.所述步骤
④
中,采用gsdmm短文本聚类模型对所有标题进行聚类,得到主题类别-主题词信息与主题类别-标题信息,并计算类内、类间标题对的相似性。
23.所述步骤
⑤
中,标题的总体相似度计算公式如下:
24.sim
title
=0.6
×
sim
bus
0.15
×
sim
date
0.1
×
sim
theme
0.5
×
sim
org
25.其中,sim
title
为标题总体相似度,sim
bus
业务相似度,sim
date
为日期相似度,sim
theme
为体裁相似度,sim
org
为机构相似度。
26.所述步骤
⑤
分为以下步骤:
27.(5.1)业务相似度:根据主题类别-主题词信息与主题类别-标题信息,采用jaccard系数计算业务描述的字符串相似度,获取sim
bus
业务相似度;
28.(5.2)日期相似度计算:日期相似度权重最高为0.95,优先级年份最高,季度次之,计算公式如下:
29.sim
date
=λ-(year
i-yearj)/100-δ
i,j
30.其中,λ是预设参数,取0.95,yeari与yearj为两个标题中出现的日期,默认为2000,δ
i,j
为标题中日期附带的季度信息的相似度,取值如下:
[0031][0032]
(5.3)体裁相似度计算:两篇公文的体裁如果相同,则相似度为0.9,否则为0.1;
[0033]
(5.4)机构相似度:机构相似度的计算具体按照以下规则计算:
[0034]
(5.4.1)机构和其简称的相似度置为0.95;
[0035]
(5.4.2)同一机构在不同行政区域的不同称呼之间的相似度置为0.85;
[0036]
(5.4.3)其它则利用余弦相似度进行计算获取;
[0037]
(5.5)以聚类数据初始值为80,端点值为300,以步长为10进行迭代步骤
④
,并按照如下公式计算数据集的总体相似度sim
all
,当sim
all
取得最大值时,得到最佳的聚类数量:
[0038][0039][0040]
sim
all
=sim
inter-sim
corss
[0041]
其中,sim
inter
表示类内平均相似度,sim
corss
表示类间平均相似度,simi表示第i个聚类的类内平均相似度,利用聚类内部所有标题之间的相似度取平均获取,sim
i,j
表示第i个聚类和第j个聚类的相似度,利用属于两个不同聚类的标题之间的相似度取平均获取,n为聚类数目。
[0042]
所述步骤
⑦
分为以下步骤:
[0043]
(7.1)从全量数据中采样获得所需训练数据,设置采样规模:
[0044]
(7.2)随机采样一个标题并取得改标题对应的聚类信息;
[0045]
(7.3)从该聚类中随机采样一个不同于步骤(7.2)中得到的标题样本作为正样本;
[0046]
(7.4)从不属于该聚类的其它标题中随机采样一个作为负样本;
[0047]
(7.5)组合步骤(7.2)~(7.4)的标题样本,生成一个triplet样本;
[0048]
(7.6)循环(7.2)~(7.5)直至样本数量达到(7.1)所设置的采样规模,结束。
[0049]
所述步骤
⑧
中,以中文版预训练模型albert为基础语言模型,利用步骤
⑦
构造的triplet数据集,采用triplet损失来进行训练,获取能够表示并进行语义相似度计算的公文标题语义向量模型。
[0050]
所述triplet损失的计算方式如下:
[0051][0052]
其中,表示锚样本的向量,表示正样本的向量,表示负样本的向量,α是预设间隔。
[0053]
所述步骤
⑧
中公文标题相似度计算模型可以将公文标题文本表示成连续的数值向量,利用余弦距离或者欧式举例可计算两个标题之间的相似度。
[0054]
本发明的有益效果在于:以聚类结果作为语义相似度标注数据基础,极大降低了标注数据的人工工作量;通过依据相似度来人工干预聚类结果的方式,提升了聚类效果,从而改进了相似度计算结果;采用albert语言模型和triplet损失,进一步降低了相似度计算所需的标注数据,也提升了模型的表示效果。
具体实施方式
[0055]
下面进一步描述本发明的技术方案,但要求保护的范围并不局限于所述。
[0056]
实施例1
[0057]
一种政策公文标题相似度计算方法,包括以下步骤:
[0058]
①
数据清洗:清洗掉因为数据采集带来的错误公文标题以及无意义的公文标题,比如“xxx号提案”等;
[0059]
②
标题处理:识别标题中的机构、日期、体裁信息并剥离相应信息得到业务相关描述,具体可分为以下几个步骤:
[0060]
(2.1)时间识别:利用命名实体识别工具识别标题中的日期,并结合正则表达式识别公文标题中的日期段、日期、年度、季度以及季节信息,如“2014至2015学年第一学期”、“2018年年度”、“2016年第一季度”、“2012年春季”等;
[0061]
(2.2)机构识别:利用命名实体识别工具识别标题中的机构,并清洗相关的数字、
标点等信息;
[0062]
(2.3)体裁识别:根据体裁的组成规则识别体裁位置;
[0063]
(2.4)槽位填充:抽取出2.1、2.2、2.3的相应信息,并在对应位置填入槽位识别码,2.1对应“date”,2.2对应“org”,2.3对应“theme”;
[0064]
③
业务关键词生成:利用关键词抽取算法,从业务相关描述中抽取每个标题对应的关键词;
[0065]
进一步的,利用jieba抽取关键词,结合词性来增进抽取结果,每个标题最多允许10个关键词;
[0066]
④
业务聚类:利用短文本主题模型对标题关键词进行聚类,并计算类内、类间标题对的相似性;
[0067]
进一步的,采用gsdmm短文本聚类模型对所有标题进行聚类,得到主题类别-主题词信息与主题类别-标题信息;
[0068]
⑤
总体相似度计算:计算标题的总体相似度,使得类内的相似度高于类间的相似度,而类内的相似度重要性以业务相似度、日期相似度、体裁相似度、机构相似度递减;
[0069]
标题相似度按照如下公式进行计算:
[0070]
sim
title
=0.6
×
sim
bus
0.15
×
sim
date
0.1
×
sim
theme
0.5
×
sim
org
[0071]
其中,sim
title
为标题总体相似度,sim
bus
业务相似度,sim
date
为日期相似度,sim
theme
为体裁相似度,sim
org
为机构相似度;
[0072]
标题中各部分内容通过步骤
②
的槽位识别码进行区分;
[0073]
进一步的,具体分为以下步骤:
[0074]
(5.1)业务相似度:根据主题类别-主题词信息与主题类别-标题信息,采用jaccard系数计算业务描述的字符串相似度;
[0075]
(5.2)日期相似度计算:日期相似度权重最高为0.95,优先级年份最高,季度次之,计算公式如下:
[0076]
sim
date
=λ-(year
i-yearj)/100-δ
i,j
[0077]
其中,λ是预设参数,一般取0.95,yeari与yearj为两个标题中出现的日期(标题中的日期主要就是年份),默认为2000,δ
i,j
为标题中日期附带的季度信息的相似度,取值如下:
[0078][0079]
(5.3)体裁相似度计算:两篇公文的体裁如果相同,则相似度为0.9,否则为0.1;
[0080]
(5.4)机构相似度:机构相似度的计算具体按照以下规则计算相似度:
[0081]
1)机构和其简称的相似度置为0.95:机构简称可以通过手工结合公开网络数据如百度百科整理得到,比如“科学技术委员会”的简称为“科委”;
[0082]
2)同一机构在不同行政区域的不同称呼之间的相似度置为0.85:这部分数据由于案例较少,也可通过手工整理,比如“科技厅”在北京称为“科委”;
[0083]
3)其它则利用余弦相似度进行计算得到;
[0084]
(5.5)聚类数据初始值为80,端点值为300,以步长为10进行迭代步骤
④
,并按照如下公式计算数据集的总体相似度sim
all
。当sim
all
取得最大值时,得到最佳的聚类数量:
[0085][0086][0087]
sim
all
=sim
inter-sim
corss
[0088]
其中,sim
inter
表示类内平均相似度,其值越大约好,sim
corss
表示类间平均相似度,值越小越好。simi表示第i个聚类的类内平均相似度,利用聚类内部所有标题之间的相似度取平均得到,sim
i,j
表示第i个聚类和第j个聚类的相似度,利用属于两个不同聚类的标题之间的相似度取平均得到,n为聚类数目;
[0089]
⑥
人工修正:根据步骤
④
和
⑤
的最终结果,对类内的低相似度标题对和类间高相似度标题对进行手动干预,手动拆分低相似度类内标题,合并部分高相似度类间标题,得到最终的聚类结果;
[0090]
⑦
riplet数据集构造t:根据步骤
⑥
的结果,构造triplet数据集;
[0091]
进一步的,triplet数据集的样本形如“锚样本;正样本;负样本”,都包含原始数据集的三个标题:一个锚样本(待比较的标题),一个正样本(与目标标题同属一个聚类的标题),一个负样本(与待比较标题不属于同一个聚类的标题);triplet的目标是使得正样本与目标样本尽可能的接近且尽可能拉远负样本与目标样本的举例;
[0092]
具体的,利用人工修正后的聚类结果,按照以下步骤构造相似性数据集:
[0093]
(7.1)设置采样规模:构造全量原始数据集的triplet数据集规模庞大(o(n3))且没有必要,因此有必要设定一个数量,从全量数据中采样获得所需训练数据;
[0094]
(7.2)随机采样一个标题并取得改标题对应的聚类信息;
[0095]
(7.3)从该聚类中随机采样一个不同于(7.2)中得到的标题样本作为正样本;
[0096]
(7.4)从不属于该聚类的其它标题中随机采样一个作为负样本;
[0097]
(7.5)组合(7.2)、(7.3)、(7.4)的标题样本,生成一个triplet样本;
[0098]
(7.6)循环(7.2)-(7.5)直至样本数量达到(7.1)所设置的采样规模,结束;
[0099]
⑧
训练:采用步骤
⑦
的训练数据,训练模型,得到公文标题相似度计算模型;
[0100]
进一步的,以中文版预训练模型albert为基础语言模型,利用步骤
⑦
构造的triplet数据集,采用triplet损失来进行训练,得到能够表示并进行语义相似度计算的公文标题语义向量模型;
[0101]
优选地,triplet损失的计算方式如下:
[0102][0103]
表示锚样本的向量,表示正样本的向量,表示负样本的向量,α是预设间隔;
[0104]
进一步的,利用步骤
⑧
得到的模型,可以将公文标题文本表示成连续的数值向量,利用余弦距离或者欧式举例即可计算两个标题之间的相似度。
[0105]
实施例2
[0106]
实验结果取自29999个公文标题数据中500个公文标题的语义相似度top1和top5人工比较结果。本文比较了如上数据在三个相似度模型:raw、sts和triplet上的结果,分别计算了top1和top5的相似情况。其中top1的得分计算方式为:
[0107][0108]
top5的计算方式为:
[0109][0110]
其中,raw:模型,利用增量训练与公文数据的albert模型,在nli(语义推断数据集)中文版之上进行调优;sts:模型,利用增量训练与公文数据的albert模型,在利用规则自动构建的公文标题语义相似度数据集上进行调优;triplet:本发明所使用模型,最终结果在所有有效数据上取平均。
[0111]
本发明的执行效果如表1所示:
[0112]
表1:不同方法的结果对比
[0113]
模型top1得分top5得分raw0.6280.731sts0.7440.846triplet0.8460.910
[0114]
从表中可以看出,本发明所使用triplet方法,在相似度计算得分上明显由于原始语义推断数据集语义数据集以及基于公文的语义相似度数据集,其原因在于triplet损失更适合对语义相似度问题进行建模,另外,本发明仅需少量人工,通过一定规则计算自动聚类结果,即可构建适用于深度学习的大规模数据集,极大的减轻了标注数据所需的人力。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
