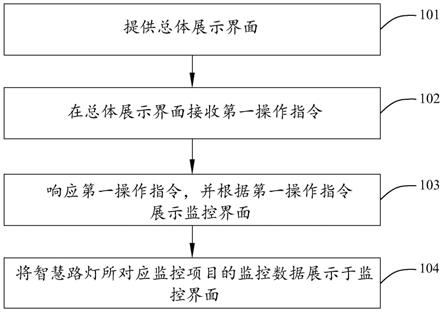
一种检测hdfs小文件和数据倾斜的自动化测试方法及工具
技术领域:
:1.本发明属于信息
技术领域:
:,具体涉及一种检测hdfs小文件和数据倾斜的自动化测试方法及工具。
背景技术:
::2.随着大数据时代的到来,大数据相关的软件蓬勃发展,关于大数据相关的测试也在进行不断的丰富完善,其中大数据的存储作为大数据整个体系中基础且重要的一环,针对其存储合理性的检测也是至关重要的,因此,本文发明针对数据存储的合理性检测,提供了一种hdfs系统小文件及数据倾斜的测试方法以及自动化测试工具的实现,以便读者可参考借鉴。技术实现要素:3.本发明的目的在于现有软件测试体系对大数据测试方法的不足,提出并开发一种关于hdfs小文件和数据倾斜的自动化测试方法工具。具体说明如下:4.一种检测hdfs小文件和数据倾斜的自动化测试方法及工具,其可支持的测试内容包含:5.1.校验hdfs文件系统中是否存在小文件6.2.校验hdfs文件系统中是否存在文件数据倾斜7.所述可支持的测试内容的具体实现方式:8.步骤1:在pg库中创建用例层及结果层,分别对应schema_case和schema_report,以及创建对应的测试用例表case_table和用例结果表report_table;9.测试用例表和用例结果表的设计具体如下:10.测试用例表字段包含:用例id、项目名称、提测版本、测试层名、测试表名、测试类型(按表或者按层测试)、是否检测到分区粒度、数据切斜倍率、期望单文件占系统文件块比例、用例状态、用例创建时间、用例创建时间、用例更新用户、用例更新时间和备注等;11.用例结果表字段包含:用例id、项目名称、测试版本号、测试表名、是否测试通过、测试结论说明、实际数据倾斜率、存在小文件数量、总文件大小、总文件数、最大文件大小、平均文件大小和创建时间等字段;其中用例id为该用例结果表的外键,对应小文件和数据倾斜的测试用例表中的用例id字段;12.步骤2:在用例层配置测试用例数据,按测试需求配置测试用例数据,内容包含:项目名称、提测版本、测试层名、测试表名、测试类型(按表或者按层测试)、是否检测到分区粒度、数据切斜倍率、期望单文件占系统文件块比例、用例状态、用例创建用户、用例创建时间、用例更新用户、用例更新时间和备注等;13.步骤3:读取用例表中的测试用例数据,并构造用于查询文件存储情况的hdfs命令,以及调用shell测试脚本。14.3-1.构造用于查询文件存储情况的hdfs命令如下:15.#获取需要执行检测的hdfs路径;16.hdfsdicpath=$hdfspath/$shcemaname/$tablename17.#获取目录下包含子目录下的文件总数量;18.filetotalcount=$(hadoopfs-count$hdfsdicpath/|awk'{print$2}')19.#获取所有文件总大小(b)20.filetotalsize=$(hadoopfs-count$hdfsdicpath/|awk'{print$3}')21.filetotalsizekb=$(echo"scale=2;${filetotalsize}/1024"|bc)22.#获取所有文件中最大的文件大小值(b)23.maxfilesize=$(hadoopfs-ls-r$hdfsdicpath/*|sort-nrꢀ‑k5|awk'{print$5}'|head-1)24.maxfilesizekb=$(echo"scale=2;${maxfilesize}/1024"|bc)25.#计算文件内存平均值(kb)26.avgfilesize=$(echo"scale=2;27.($filetotalsize/1024)/$filetotalcount"|bc)28.其中,shcemaname为用例数据中测试层名内容,tablename为用例数据中测试表名内容,hdfsdicpath为需要执行检测的hdfs路径,filetotalcount为测试路径下文件总数量,filetotalsizekb为获取所有文件总大小(单位为kb),maxfilesizekb为获取所有文件中最大的文件大小值((单位为kb),avgfilesize为文件内存平均值(单位为kb),awk是shell语言脚本自带的方法,用于匹配查询文件中的字符串,$()表示参数引用标志符,hadoopfs是hdfs的文件查询命令,echo是shell语言脚本的字符串打印输出命令,与print类似;scale表示计算后数值保留的精确位。29.3-2.判断是否存在小文件逻辑具体实现如下:30.以用例数据中测试表tablename为单位,满足当该表文件使用的总大小在0m~50m之间,且文件数量k》10;或者当该表文件使用的总大小》50m,且(总文件大小s/(文件系统块大小s1*期望单文件占系统文件块比例系数a1) 1)《当前文件数量k,即:(s/(s1*a1) 1)<k,则认为文件数不满足预期,存在小文件;31.存在小文件的判断逻辑实现代码如下:32.[0033][0034]其中,filetotalsize为获取所有文件总大小(单位为b),filesizeper为期望的文件总大小(单位为b),filetotalcount为获取的文件总数量,filecountpre为期望的文件总数量,sfc_flag为是否存在小文件的标识,le与gt是shell语言脚本中小于等于和大于等于的表达式,$()表示参数引用标志符,-a表示两个条件且的关系,即为and,-eq表示equal等于的含义,expr是shell中进行复杂四则运算的前置命令。[0035]3-3.数据倾斜的判断逻辑实现如下:[0036]以用例数据中测试表tablename为单位,表中最大文件值与所有文件大小的均值的比值大于数据倾斜倍率,则认为出现数据倾斜。[0037]数据倾斜的判断逻辑实现代码如下:[0038][0039]其中,maxfilesize为获取文件中最大文件的大小(单位为b),avgfilesize为获取的所有文件平均大小(单位为b),tiltrate为文件的实际数据倾斜率,tiltratelimit为期望文件不超过的数据倾斜率,tilt_flag为是否存在小文件的标识,le与gt是shell语言脚本中小于等于和大于等于的表达式,$()表示参数引用标志符;echo是shell语言脚本的字符串打印输出命令,scale表示计算后数值保留的精确位,-eq表示equal等于的含义,expr是shell中进行复杂四则运算的前置命令。[0040]3-4.测试用例数据通过的条件如下:[0041]当小文件判断标志sfc_flag=0并且数据倾斜判断标志tilt_flag=0,则测试通过,其他均为测试不通过。[0042]步骤4:然后根据测试用例数据id,循环执行每一条测试用例数据所构造的hdfsm命令和shell脚本,通过hdfs命令读取系统路径下的被测表,得到被测表的测试结果;[0043]步骤5:在关键步骤打印日志,以便排查使用者排查问题;关键步骤包括:[0044]1)执行时输入的参数校验;[0045]2)获取测试用例数据生成用例dataframe,将用例数据作为入参传入shell脚本中待执行;[0046]3)循环执行所有用例,得到被测数据的真实存储空间占用值;[0047]4)解析返回的测试结果数据,提取需要的数据作为后续的测试结果存入dataframe;[0048]5)执行完成提示(失败或成功)。[0049]步骤6:将步骤4获取的实际测试的测试结果与预先设定的预期结果进行比较,得出最终测试结果,使用is_pass字段(即用例结果表中的是否通过测试字段)标识测试用例数据是否通过;[0050]步骤7:存储最终测试结果:[0051]将最终测试结果存储在用例结果表中:is_pass为1表示测试通过,对应的conclusion为正常;is_pass为0表示测试未通过,对应的conclusion可能为文件数量超额、数据倾斜或数据倾斜和文件数量超额同时存在;[0052]步骤8:测试人员访问最终测试结果表查看测试结果。[0053]所述的自动化测试工具的技术架构具体如下[0054]工具技术架构分为5大模块:读取测试用例内容模块、解析用例中配置参数模块、循环调用执行shell判断脚本模块、结果对比模块、结果存储模块。[0055]所述的读取测试用例内容模块:将测试用例表中已配置的测试用例内容读取到dataframe中;[0056]所述的解析用例中配置参数模块:通过读取测试用例内容模块得到的数据,按照测试所需的参数,将用例表中配置的字段处理为循环执行shell判断脚本模块的输入参数;[0057]所述的循环执行shell判断脚本模块:根据用例id,从解析用例中配置参数模块中解析出所需参数后,循环调用shell脚本执行测试代码;[0058]所述的结果对比模块,将循环执行shell判断脚本模块中得到真实文件存储数据,以及经过逻辑判断后的小文件和数据倾斜的状态值,若小文件和数据倾斜状态值同时满足预期状态值等于‘1’,则测试通过;若两者不能同时满足预期状态值不等于‘1’则测试不通过;[0059]所述的结果存储模块,将结果对比模块得到的测试结果数据、用例id、真实存储空间占用数据等信息,存储到pg数据库的测试结果表中;[0060]所述自动化测试工具的执行方法及日志存储:[0061]执行方式:通过spark-submit命令直接调用执行用例。[0062]日志存储:执行结束后日志存储在log目录中,包含loginfo.log和report.log两份日志文件,其中loginfo中存储的是执行过程日志,report.log中存储的是各测试表的数据文件存储情况的简略版说明,用户均可自行查看,可以初步了解到被检测的表数量、对应表的小文件和数据倾斜率的指标值等执行信息。[0063]本小文件和数据倾斜自动化测试工具的优势:[0064]从用例配置层面,根据测试需求,通过测试用例的配置可以实现一条用例仅测试某一张表的场景,也可以实现一条用例测试整个schema模式层下的所有表的场景,用例配置具有灵活性,便捷性和易操作性;[0065]从测试时间层面,手工检测一张表在hdfs系统上的小文件情况,从编写命令,执行命令到判断计算结果过程大致需要15分钟,通过该方法及工具15分钟基本可完成15张表左右的小文件和数据倾斜的检测,从测试速率上得到了较大的提升;[0066]从测试准确度层面,可根据不同测试表存储的业务数据差异性,灵活调整期望的数据倾斜倍率和期望单个文件存储大小,得到与业务数据情况更符合,更准确的检测结果。[0067]本发明有益效果:[0068]本发明通过总结大数据测试方法,提出一种检测hdfs小文件和数据倾斜的数据文件存储合理性的测试方法,并且开发出对应的数据文件存储合理性检测的自动化测试工具。完善了大数据测试体系,也提升了数据测试的丰富性和全面性。[0069]本发明使数据测试体系中关于数据文件存储是否合理的测试方法得到补充,并将该测试方法实现了自动化测试工具,该方法及工具可以较为高效地完成hdfs小文件和数据倾斜的测试。本方法及工具亦可保存历史已配置好的用例,进行自动化回归测试,以及可运用在基于相同产品架构下的不同定制项目中,本数据测试方法及工具可极大提升测试工作效率。附图说明[0070]图1是本发明实施例测试对象的数据存储结构及测试用例表、测试结果表层级结构;[0071]图2是本发明实施例采用该数据存储合理性测试方法及自动化测试工具的具体流程图。具体实施方式[0072]下面结合附图、附表详细描述本发明,本发明的目的和结果将变得更加明显。将从编写测试用例,使用自动化测试工具,查看测试结果,达到校验数据文件存储是否合理行的测试目的。[0073]步骤1:在pg库中初始化创建用例层及结果层两层,分别对应schema_case和schema_report,按测试类型创建测试用例表和用例结果表,用例、结果及被测数据的架构如图1所示;[0074]步骤2:在用例配置层的用例表中配置测试用例内容;[0075]小文件及数据倾斜用例表:用例id、项目名称、提测版本、测试层名、测试表名、测试类型(按表或者按层测试)、是否检测到分区粒度、数据倾斜倍率、期望单文件占系统文件块比例、用例状态、用例创建用户、用例创建时间、用例更新用户、用例更新时间、备注等,具体用例编辑实施示例见表1;[0076]表1[0077][0078]步骤3:然后执行数据校验的内部逻辑流程,如图2所示。首先,[0079]读取用例表中的测试用例数据,解析用例数据后传给shell脚本作为入参,然后调用执行shell脚本,具体hdfs命令内容如下:[0080]#获取需要执行检测的hdfs路径[0081]hdfsdicpath=hdfs://test.master1.linezonedata.com:8020/user/hive/warehouse/tenant_1000000134_edw.db/fct_sales[0082]#获取目录下包含子目录下的文件总数量[0083]filetotalcount=$(hadoopfs-count[0084]hdfs://test.master1.linezonedata.com:8020/user/hive/warehouse/tenant_1000000134_edw.db/fct_sales/|awk'{print$2}')[0085]》》》》filetotalcount:1119个文件[0086]#获取所有文件总大小(b)[0087]filetotalsize=$(hadoopfs-count[0088]hdfs://test.master1.linezonedata.com:8020/user/hive/warehouse/tenant_1000000134_edw.db/fct_sales/|awk'{print$3}')[0089]》》》》filetotalsize:46687954b[0090]filetotalsizekb=$(echo"scale=2;${filetotalsize}/1024"|bc)[0091]》》》》filetotalsizekb:45594kb约为45mb[0092]#获取所有文件中最大的文件大小值(b)[0093]maxfilesize=$(hadoopfs-ls-r[0094]hdfs://test.master1.linezonedata.com:8020/user/hive/warehouse/tenant_1000000134_edw.db/fct_sales/*|sort-nr-k5|awk'{print$5}'|head-1)[0095]》》》》maxfilesize:131780b[0096]maxfilesizekb=$(echo"scale=2;${maxfilesize}/1024"|bc)[0097]》》》》maxfilesizekb:129kb[0098]#计算文件内存平均值(kb)[0099]avgfilesize=$(echo"scale=2;[0100]($filetotalsize/1024)/$filetotalcount"|bc)[0101]》》》》avgfilesize:40.74kb[0102]#计算文件数量期望值[0103]prerate=0.6[0104]filecountpre=$(echo"scale=2;[0105]$filetotalsize/(64*1024*1024*$prerate) 1"|bc)[0106]》》》》filecountpre:1.56个文件约为2个文件[0107]filesizeper=$(echo"scale=2;50*1024*1024"|bc)[0108]》》》》filesizeper:50mb[0109]判断是否存在小文件逻辑[0110][0111]存在小文件的判断逻辑为:以表为单位:满足当表文件使用总大小0m~50m之间,文件数量》10;或者当表文件使用总大小》50m,总文件大小/(文件系统块大小*期望单文件占系统文件块比例系数) 1《当前文件数量,则认为文件数不满足预期,存在小文件)[0112]当前fct_sales表:表文件总大小为45mb《50mb,文件个数为1119个》10个,因此执行过程满足以下红色部分的判断逻辑,小文件标识sfc_flag=1;[0113]数据倾斜的判断逻辑[0114][0115]数据倾斜的判断逻辑为:以每张表为单位:某表中最大文件值/所有文件大小的均值》数据倾斜倍率,则认为出现数据倾斜。[0116]当前fct_sales表:测试用例表中配置数据倾斜率阈值《3,当前tiltrate等于3.16》3,因此存在数据倾斜现象,数据倾斜标识tilt_flag=1。[0117]步骤4:然后按照用例id,循环执行每一条测试用例,依次执行每一张的被测数据表,得到实际测试的数据结果;[0118]步骤5:在关键步骤打印日志;[0119]步骤6:将实际数据结果与用例中配置的预期结果进行比较,得出测试结论,使用is_pass字段标识测试是否通过,conclusion字段标识测试结论的描述信息;[0120]步骤7:存储测试结果:将测试结果存储在数据库中,is_pass为1表示测试通过,is_pass为0表示测试未通过;[0121]步骤8:自动化测试用例jar上传到测试服务器,配置数据库连接文件,调用spark-submit命令执行脚本进行执行:[0122]spark2-submit‑‑class[0123]com.linezonedata.data.validation.smallfilemonitot‑‑masteryarn‑‑deploy-modeclient[0124]linezone_qa_data_validation_1_2.11-0.1.jar[0125]‑‑autotestreportschemaauto_test_report‑‑casesquerysql[0126]″select*fromauto_test_case.small_file_check_test_casewhereid=1″‑‑batchnumberv5.1.0‑‑appid1000000134[0127]步骤9:测试人员可在对应的校验类型结果表中查看测试结果。[0128]表2[0129][0130]表2是使用本发明的自动化测试工具执行测试后,得到的测试结果表。其中is_pass为1,表示该条用例的测试结果为通过;is_pass为0,表示该条用例的测试结果为未通过。[0131]本发明不仅局限于上述具体实施方式,本领域一般技术人员根据本发明公开的内容,可以采用其它多种具体实施方案实施本发明。因此,凡是采用本发明的设计结构和思路,做一些简单的变化或更改的设计,都落入本发明保护范围。当前第1页12当前第1页12
技术领域:
:1.本发明属于信息
技术领域:
:,具体涉及一种检测hdfs小文件和数据倾斜的自动化测试方法及工具。
背景技术:
::2.随着大数据时代的到来,大数据相关的软件蓬勃发展,关于大数据相关的测试也在进行不断的丰富完善,其中大数据的存储作为大数据整个体系中基础且重要的一环,针对其存储合理性的检测也是至关重要的,因此,本文发明针对数据存储的合理性检测,提供了一种hdfs系统小文件及数据倾斜的测试方法以及自动化测试工具的实现,以便读者可参考借鉴。技术实现要素:3.本发明的目的在于现有软件测试体系对大数据测试方法的不足,提出并开发一种关于hdfs小文件和数据倾斜的自动化测试方法工具。具体说明如下:4.一种检测hdfs小文件和数据倾斜的自动化测试方法及工具,其可支持的测试内容包含:5.1.校验hdfs文件系统中是否存在小文件6.2.校验hdfs文件系统中是否存在文件数据倾斜7.所述可支持的测试内容的具体实现方式:8.步骤1:在pg库中创建用例层及结果层,分别对应schema_case和schema_report,以及创建对应的测试用例表case_table和用例结果表report_table;9.测试用例表和用例结果表的设计具体如下:10.测试用例表字段包含:用例id、项目名称、提测版本、测试层名、测试表名、测试类型(按表或者按层测试)、是否检测到分区粒度、数据切斜倍率、期望单文件占系统文件块比例、用例状态、用例创建时间、用例创建时间、用例更新用户、用例更新时间和备注等;11.用例结果表字段包含:用例id、项目名称、测试版本号、测试表名、是否测试通过、测试结论说明、实际数据倾斜率、存在小文件数量、总文件大小、总文件数、最大文件大小、平均文件大小和创建时间等字段;其中用例id为该用例结果表的外键,对应小文件和数据倾斜的测试用例表中的用例id字段;12.步骤2:在用例层配置测试用例数据,按测试需求配置测试用例数据,内容包含:项目名称、提测版本、测试层名、测试表名、测试类型(按表或者按层测试)、是否检测到分区粒度、数据切斜倍率、期望单文件占系统文件块比例、用例状态、用例创建用户、用例创建时间、用例更新用户、用例更新时间和备注等;13.步骤3:读取用例表中的测试用例数据,并构造用于查询文件存储情况的hdfs命令,以及调用shell测试脚本。14.3-1.构造用于查询文件存储情况的hdfs命令如下:15.#获取需要执行检测的hdfs路径;16.hdfsdicpath=$hdfspath/$shcemaname/$tablename17.#获取目录下包含子目录下的文件总数量;18.filetotalcount=$(hadoopfs-count$hdfsdicpath/|awk'{print$2}')19.#获取所有文件总大小(b)20.filetotalsize=$(hadoopfs-count$hdfsdicpath/|awk'{print$3}')21.filetotalsizekb=$(echo"scale=2;${filetotalsize}/1024"|bc)22.#获取所有文件中最大的文件大小值(b)23.maxfilesize=$(hadoopfs-ls-r$hdfsdicpath/*|sort-nrꢀ‑k5|awk'{print$5}'|head-1)24.maxfilesizekb=$(echo"scale=2;${maxfilesize}/1024"|bc)25.#计算文件内存平均值(kb)26.avgfilesize=$(echo"scale=2;27.($filetotalsize/1024)/$filetotalcount"|bc)28.其中,shcemaname为用例数据中测试层名内容,tablename为用例数据中测试表名内容,hdfsdicpath为需要执行检测的hdfs路径,filetotalcount为测试路径下文件总数量,filetotalsizekb为获取所有文件总大小(单位为kb),maxfilesizekb为获取所有文件中最大的文件大小值((单位为kb),avgfilesize为文件内存平均值(单位为kb),awk是shell语言脚本自带的方法,用于匹配查询文件中的字符串,$()表示参数引用标志符,hadoopfs是hdfs的文件查询命令,echo是shell语言脚本的字符串打印输出命令,与print类似;scale表示计算后数值保留的精确位。29.3-2.判断是否存在小文件逻辑具体实现如下:30.以用例数据中测试表tablename为单位,满足当该表文件使用的总大小在0m~50m之间,且文件数量k》10;或者当该表文件使用的总大小》50m,且(总文件大小s/(文件系统块大小s1*期望单文件占系统文件块比例系数a1) 1)《当前文件数量k,即:(s/(s1*a1) 1)<k,则认为文件数不满足预期,存在小文件;31.存在小文件的判断逻辑实现代码如下:32.[0033][0034]其中,filetotalsize为获取所有文件总大小(单位为b),filesizeper为期望的文件总大小(单位为b),filetotalcount为获取的文件总数量,filecountpre为期望的文件总数量,sfc_flag为是否存在小文件的标识,le与gt是shell语言脚本中小于等于和大于等于的表达式,$()表示参数引用标志符,-a表示两个条件且的关系,即为and,-eq表示equal等于的含义,expr是shell中进行复杂四则运算的前置命令。[0035]3-3.数据倾斜的判断逻辑实现如下:[0036]以用例数据中测试表tablename为单位,表中最大文件值与所有文件大小的均值的比值大于数据倾斜倍率,则认为出现数据倾斜。[0037]数据倾斜的判断逻辑实现代码如下:[0038][0039]其中,maxfilesize为获取文件中最大文件的大小(单位为b),avgfilesize为获取的所有文件平均大小(单位为b),tiltrate为文件的实际数据倾斜率,tiltratelimit为期望文件不超过的数据倾斜率,tilt_flag为是否存在小文件的标识,le与gt是shell语言脚本中小于等于和大于等于的表达式,$()表示参数引用标志符;echo是shell语言脚本的字符串打印输出命令,scale表示计算后数值保留的精确位,-eq表示equal等于的含义,expr是shell中进行复杂四则运算的前置命令。[0040]3-4.测试用例数据通过的条件如下:[0041]当小文件判断标志sfc_flag=0并且数据倾斜判断标志tilt_flag=0,则测试通过,其他均为测试不通过。[0042]步骤4:然后根据测试用例数据id,循环执行每一条测试用例数据所构造的hdfsm命令和shell脚本,通过hdfs命令读取系统路径下的被测表,得到被测表的测试结果;[0043]步骤5:在关键步骤打印日志,以便排查使用者排查问题;关键步骤包括:[0044]1)执行时输入的参数校验;[0045]2)获取测试用例数据生成用例dataframe,将用例数据作为入参传入shell脚本中待执行;[0046]3)循环执行所有用例,得到被测数据的真实存储空间占用值;[0047]4)解析返回的测试结果数据,提取需要的数据作为后续的测试结果存入dataframe;[0048]5)执行完成提示(失败或成功)。[0049]步骤6:将步骤4获取的实际测试的测试结果与预先设定的预期结果进行比较,得出最终测试结果,使用is_pass字段(即用例结果表中的是否通过测试字段)标识测试用例数据是否通过;[0050]步骤7:存储最终测试结果:[0051]将最终测试结果存储在用例结果表中:is_pass为1表示测试通过,对应的conclusion为正常;is_pass为0表示测试未通过,对应的conclusion可能为文件数量超额、数据倾斜或数据倾斜和文件数量超额同时存在;[0052]步骤8:测试人员访问最终测试结果表查看测试结果。[0053]所述的自动化测试工具的技术架构具体如下[0054]工具技术架构分为5大模块:读取测试用例内容模块、解析用例中配置参数模块、循环调用执行shell判断脚本模块、结果对比模块、结果存储模块。[0055]所述的读取测试用例内容模块:将测试用例表中已配置的测试用例内容读取到dataframe中;[0056]所述的解析用例中配置参数模块:通过读取测试用例内容模块得到的数据,按照测试所需的参数,将用例表中配置的字段处理为循环执行shell判断脚本模块的输入参数;[0057]所述的循环执行shell判断脚本模块:根据用例id,从解析用例中配置参数模块中解析出所需参数后,循环调用shell脚本执行测试代码;[0058]所述的结果对比模块,将循环执行shell判断脚本模块中得到真实文件存储数据,以及经过逻辑判断后的小文件和数据倾斜的状态值,若小文件和数据倾斜状态值同时满足预期状态值等于‘1’,则测试通过;若两者不能同时满足预期状态值不等于‘1’则测试不通过;[0059]所述的结果存储模块,将结果对比模块得到的测试结果数据、用例id、真实存储空间占用数据等信息,存储到pg数据库的测试结果表中;[0060]所述自动化测试工具的执行方法及日志存储:[0061]执行方式:通过spark-submit命令直接调用执行用例。[0062]日志存储:执行结束后日志存储在log目录中,包含loginfo.log和report.log两份日志文件,其中loginfo中存储的是执行过程日志,report.log中存储的是各测试表的数据文件存储情况的简略版说明,用户均可自行查看,可以初步了解到被检测的表数量、对应表的小文件和数据倾斜率的指标值等执行信息。[0063]本小文件和数据倾斜自动化测试工具的优势:[0064]从用例配置层面,根据测试需求,通过测试用例的配置可以实现一条用例仅测试某一张表的场景,也可以实现一条用例测试整个schema模式层下的所有表的场景,用例配置具有灵活性,便捷性和易操作性;[0065]从测试时间层面,手工检测一张表在hdfs系统上的小文件情况,从编写命令,执行命令到判断计算结果过程大致需要15分钟,通过该方法及工具15分钟基本可完成15张表左右的小文件和数据倾斜的检测,从测试速率上得到了较大的提升;[0066]从测试准确度层面,可根据不同测试表存储的业务数据差异性,灵活调整期望的数据倾斜倍率和期望单个文件存储大小,得到与业务数据情况更符合,更准确的检测结果。[0067]本发明有益效果:[0068]本发明通过总结大数据测试方法,提出一种检测hdfs小文件和数据倾斜的数据文件存储合理性的测试方法,并且开发出对应的数据文件存储合理性检测的自动化测试工具。完善了大数据测试体系,也提升了数据测试的丰富性和全面性。[0069]本发明使数据测试体系中关于数据文件存储是否合理的测试方法得到补充,并将该测试方法实现了自动化测试工具,该方法及工具可以较为高效地完成hdfs小文件和数据倾斜的测试。本方法及工具亦可保存历史已配置好的用例,进行自动化回归测试,以及可运用在基于相同产品架构下的不同定制项目中,本数据测试方法及工具可极大提升测试工作效率。附图说明[0070]图1是本发明实施例测试对象的数据存储结构及测试用例表、测试结果表层级结构;[0071]图2是本发明实施例采用该数据存储合理性测试方法及自动化测试工具的具体流程图。具体实施方式[0072]下面结合附图、附表详细描述本发明,本发明的目的和结果将变得更加明显。将从编写测试用例,使用自动化测试工具,查看测试结果,达到校验数据文件存储是否合理行的测试目的。[0073]步骤1:在pg库中初始化创建用例层及结果层两层,分别对应schema_case和schema_report,按测试类型创建测试用例表和用例结果表,用例、结果及被测数据的架构如图1所示;[0074]步骤2:在用例配置层的用例表中配置测试用例内容;[0075]小文件及数据倾斜用例表:用例id、项目名称、提测版本、测试层名、测试表名、测试类型(按表或者按层测试)、是否检测到分区粒度、数据倾斜倍率、期望单文件占系统文件块比例、用例状态、用例创建用户、用例创建时间、用例更新用户、用例更新时间、备注等,具体用例编辑实施示例见表1;[0076]表1[0077][0078]步骤3:然后执行数据校验的内部逻辑流程,如图2所示。首先,[0079]读取用例表中的测试用例数据,解析用例数据后传给shell脚本作为入参,然后调用执行shell脚本,具体hdfs命令内容如下:[0080]#获取需要执行检测的hdfs路径[0081]hdfsdicpath=hdfs://test.master1.linezonedata.com:8020/user/hive/warehouse/tenant_1000000134_edw.db/fct_sales[0082]#获取目录下包含子目录下的文件总数量[0083]filetotalcount=$(hadoopfs-count[0084]hdfs://test.master1.linezonedata.com:8020/user/hive/warehouse/tenant_1000000134_edw.db/fct_sales/|awk'{print$2}')[0085]》》》》filetotalcount:1119个文件[0086]#获取所有文件总大小(b)[0087]filetotalsize=$(hadoopfs-count[0088]hdfs://test.master1.linezonedata.com:8020/user/hive/warehouse/tenant_1000000134_edw.db/fct_sales/|awk'{print$3}')[0089]》》》》filetotalsize:46687954b[0090]filetotalsizekb=$(echo"scale=2;${filetotalsize}/1024"|bc)[0091]》》》》filetotalsizekb:45594kb约为45mb[0092]#获取所有文件中最大的文件大小值(b)[0093]maxfilesize=$(hadoopfs-ls-r[0094]hdfs://test.master1.linezonedata.com:8020/user/hive/warehouse/tenant_1000000134_edw.db/fct_sales/*|sort-nr-k5|awk'{print$5}'|head-1)[0095]》》》》maxfilesize:131780b[0096]maxfilesizekb=$(echo"scale=2;${maxfilesize}/1024"|bc)[0097]》》》》maxfilesizekb:129kb[0098]#计算文件内存平均值(kb)[0099]avgfilesize=$(echo"scale=2;[0100]($filetotalsize/1024)/$filetotalcount"|bc)[0101]》》》》avgfilesize:40.74kb[0102]#计算文件数量期望值[0103]prerate=0.6[0104]filecountpre=$(echo"scale=2;[0105]$filetotalsize/(64*1024*1024*$prerate) 1"|bc)[0106]》》》》filecountpre:1.56个文件约为2个文件[0107]filesizeper=$(echo"scale=2;50*1024*1024"|bc)[0108]》》》》filesizeper:50mb[0109]判断是否存在小文件逻辑[0110][0111]存在小文件的判断逻辑为:以表为单位:满足当表文件使用总大小0m~50m之间,文件数量》10;或者当表文件使用总大小》50m,总文件大小/(文件系统块大小*期望单文件占系统文件块比例系数) 1《当前文件数量,则认为文件数不满足预期,存在小文件)[0112]当前fct_sales表:表文件总大小为45mb《50mb,文件个数为1119个》10个,因此执行过程满足以下红色部分的判断逻辑,小文件标识sfc_flag=1;[0113]数据倾斜的判断逻辑[0114][0115]数据倾斜的判断逻辑为:以每张表为单位:某表中最大文件值/所有文件大小的均值》数据倾斜倍率,则认为出现数据倾斜。[0116]当前fct_sales表:测试用例表中配置数据倾斜率阈值《3,当前tiltrate等于3.16》3,因此存在数据倾斜现象,数据倾斜标识tilt_flag=1。[0117]步骤4:然后按照用例id,循环执行每一条测试用例,依次执行每一张的被测数据表,得到实际测试的数据结果;[0118]步骤5:在关键步骤打印日志;[0119]步骤6:将实际数据结果与用例中配置的预期结果进行比较,得出测试结论,使用is_pass字段标识测试是否通过,conclusion字段标识测试结论的描述信息;[0120]步骤7:存储测试结果:将测试结果存储在数据库中,is_pass为1表示测试通过,is_pass为0表示测试未通过;[0121]步骤8:自动化测试用例jar上传到测试服务器,配置数据库连接文件,调用spark-submit命令执行脚本进行执行:[0122]spark2-submit‑‑class[0123]com.linezonedata.data.validation.smallfilemonitot‑‑masteryarn‑‑deploy-modeclient[0124]linezone_qa_data_validation_1_2.11-0.1.jar[0125]‑‑autotestreportschemaauto_test_report‑‑casesquerysql[0126]″select*fromauto_test_case.small_file_check_test_casewhereid=1″‑‑batchnumberv5.1.0‑‑appid1000000134[0127]步骤9:测试人员可在对应的校验类型结果表中查看测试结果。[0128]表2[0129][0130]表2是使用本发明的自动化测试工具执行测试后,得到的测试结果表。其中is_pass为1,表示该条用例的测试结果为通过;is_pass为0,表示该条用例的测试结果为未通过。[0131]本发明不仅局限于上述具体实施方式,本领域一般技术人员根据本发明公开的内容,可以采用其它多种具体实施方案实施本发明。因此,凡是采用本发明的设计结构和思路,做一些简单的变化或更改的设计,都落入本发明保护范围。当前第1页12当前第1页12
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。