1.本发明涉及图像识别技术领域,具体涉及一种图像识别模型训练方法及系统和图像识别方法。
背景技术:
2.目前深度学习是学习样本数据的内在规律和表示层次,这些学习过程中获得的信息对诸如文字,图像和声音等数据的解释有很大的帮助。它的最终目标是让机器能够像人一样具有分析学习能力,能够识别文字、图像和声音等数据。深度学习是一个复杂的机器学习算法,在语音和图像识别方面取得的效果,远远超过先前相关技术。
3.深度学习在搜索技术,数据挖掘,机器学习,机器翻译,自然语言处理,多媒体学习,语音,推荐和个性化技术,以及其他相关领域都取得了很多成果。深度学习使机器模仿视听和思考等人类的活动,解决了很多复杂的模式识别难题,使得人工智能相关技术取得了很大进步。
4.而另一项技术自动驾驶,也成为了研究的热点。自动驾驶系统采用先进的通信、计算机、网络和控制技术,对列车实现实时、连续控制。采用现代通信手段,直接面对列车,可实现车地间的双向数据通信,传输速率快,信息量大,后续追踪列车和控制中心可以及时获知前行列车的确切位置,使得运行管理更加灵活,控制更为有效,更加适应自动驾驶的需求。自动驾驶系统是一个汇集众多高新技术的综合系统,作为关键环节的环境信息获取和智能决策控制依赖于传感器技术、图像识别技术、电子与计算机技术与控制技术等一系列高新技术的创新和突破。无人驾驶汽车要想取得长足的发展,有赖于多方面技术的突破和创新。
5.那么将深度学习图像识别技术与无人驾驶技术进行融合,通过准确的图像识别,实现道路的准确判断,作为辅助无人驾驶的手段,成为一项全新的研究对象。
6.目前针对无人驾驶领域的图像识别,还没有很好准确识别的方法。
技术实现要素:
7.鉴于上述问题,本发明提供一种至少解决上述部分技术问题的图像识别模型训练方法及系统和图像识别方法,该方法训练所需的计算量较小,识别准确性高。
8.第一方面,本发明实施例提供一种图像识别模型训练方法,包括:
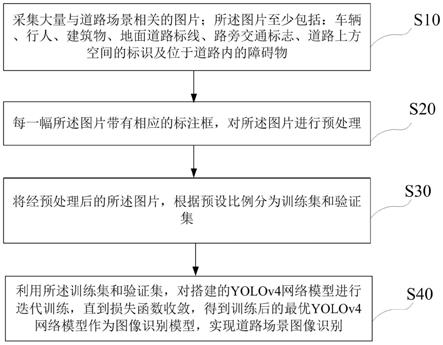
9.s10、采集大量与道路场景相关的图片;所述图片至少包括:车辆、行人、建筑物、地面道路标线、路旁交通标志、道路上方空间的标识及位于道路内的障碍物;
10.s20、每一幅所述图片带有相应的标注框,对所述图片进行预处理;
11.s30、将经预处理后的所述图片,根据预设比例分为训练集和验证集;
12.s40、利用所述训练集和验证集,对搭建的yolov4网络模型进行迭代训练,直到损失函数收敛,得到训练后的最优yolov4网络模型作为图像识别模型,实现道路场景图像识别。
13.在一个实施例中,每一幅所述图片带有相应的标注框,包括:
14.利用labelimg软件对所述图片标注成voc格式,标注每幅图片中的车辆、行人、建筑物、地面道路标线、路旁交通标志、道路上方空间的标识及位于道路内的障碍物。
15.在一个实施例中,对所述图片进行预处理,包括:
16.使用mosaic数据增强方法增加样本的数量。
17.在一个实施例中,所述yolov4网络模型采用轻量mobilenetv3网络,且在检测器中引入深度可分离卷积和inception网络结构。
18.第二方面,本发明实施例提供一种图像识别模型训练系统,包括:
19.采集模块,用于采集大量与道路场景相关的图片;所述图片至少包括:车辆、行人、建筑物、地面道路标线、路旁交通标志、道路上方空间的标识及位于道路内的障碍物;
20.预处理模块,用于对所述图片进行预处理;且每一幅所述图片带有相应的标注框;
21.构建模块,用于将经预处理后的所述图片,根据预设比例分为训练集和验证集;
22.训练模块,利用所述训练集和验证集,对搭建的yolov4网络模型进行迭代训练,直到损失函数收敛,得到训练后的最优yolov4网络模型作为图像识别模型,实现道路场景图像识别。
23.第三方面,本发明实施例还提供一种图像识别方法,包括:
24.车辆在前进行驶过程中,实时获取前方道路场景图像;
25.将所述前方道路场景图像输入图像识别模型;所述图像识别模型通过所述上述实施例所述的图像识别模型训练方法训练得到;
26.通过所述图像识别模型输出所述前方道路场景图像的识别结果。
27.本发明实施例提供的上述技术方案的有益效果至少包括:
28.本发明实施例提供的一种图像识别模型训练方法,该方法包括:采集大量与道路场景相关的图片;所述图片至少包括:车辆、行人、建筑物、地面道路标线、路旁交通标志、道路上方空间的标识及位于道路内的障碍物;每一幅所述图片带有相应的标注框,对所述图片进行预处理;将经预处理后的所述图片,根据预设比例分为训练集和验证集;利用所述训练集和验证集,对搭建的yolov4网络模型进行迭代训练,直到损失函数收敛,得到训练后的最优yolov4网络模型作为图像识别模型,实现道路场景图像识别。该方法相比传统cnn模型,可降低计算量,且同时不会造成精度上的损失;检测速度更快、实时性更强。
29.本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明书、权利要求书、以及附图中所特别指出的结构来实现和获得。
30.下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
31.附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
32.图1为本发明实施例提供的图像识别模型训练方法的流程图;
33.图2为本发明实施例提供的yolov4网络模型的结构图;
34.图3为本发明实施例提供的mobilenetv3网络结构图;
35.图4a为本发明实施例提供的inception网络结构图;
36.图4b为本发明实施例提供的调整后的inception网络结构图;
37.图5为本发明实施例提供的图像识别模型训练系统框图。
具体实施方式
38.下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。
39.实施例1:
40.参照图1所示,本发明实施例提供的一种图像识别模型训练方法,包括:
41.s10、采集大量与道路场景相关的图片;所述图片至少包括:车辆、行人、建筑物、地面道路标线、路旁交通标志、道路上方空间的标识及位于道路内的障碍物;
42.s20、每一幅所述图片带有相应的标注框,对所述图片进行预处理;
43.s30、将经预处理后的所述图片,根据预设比例分为训练集和验证集;
44.s40、利用所述训练集和验证集,对搭建的yolov4网络模型进行迭代训练,直到损失函数收敛,得到训练后的最优yolov4网络模型作为图像识别模型,实现道路场景图像识别。该方法相比传统cnn模型,可降低计算量,且同时不会造成精度上的损失;检测速度更快、实时性更强。
45.在一个实施例中,步骤s20中的每一幅所述图片带有相应的标注框,可使用标注工具labelimg对图片进行标注,生成xml标注文件。比如可将约500000张视频帧图片进行随机编号,给图片编一个合理的序号,比如0000000~0499999;利用labelimg软件标注数据,每一个图片名对应的有一个相应名字的xml标注文件,比如图片0000000.jpg,标注文件是0000000.xml。标注的范围包括:图像所在位置、图像名称(如0000000.jpg)、图像宽高、图像维度、标注的预选框名称以及预选框的坐标值;标注的类型包括:车辆、行人、建筑物、地面道路标线、路旁交通标志、道路上方空间的标识及位于道路内的障碍物,比如立交桥、或是阻碍交通的物体(非正常出现在道路上的物体)等。其中对图像数据进行划分,可分为训练数据集、测试数据集和验证数据集,其中训练数据集占70%,测试数据集占20%,测试数据集占10%。
46.在一个实施例中,步骤s20的对图片进行预处理包括:使用mosaic数据增强增加样本的数量。
47.比如:光度畸变:调整亮度、对比度、色调、饱和度和噪声等;几何畸变:随机缩放、剪切、翻转、旋转和风格迁移等。也可以通过随机擦除,填充随机或互补的0值来构造数据集;再比如可随机或均匀的选择图像中的多个矩形区域,并将其全部替换为0,实现在特征图上进行数据增强。
48.还可以把多张图像拼接在一起,使网络训练效果更佳,增加了数据多样性。
49.增加目标个数、bn能一次性统计多张图片的参数:如果使用bn层,batch_size要尽量设的大一点,因为bn层主要求均值和方差,batch_size越大,越接近整个数据集的均值和方差,效果会变好。但由于显存受限,batch_size不能无限增大,但是可以把n张图片拼接在
一起,等效于并行输入batch_size=n的原始图像。比如mosasic利用了四张图片,可丰富检测物体的背景。且在bn计算的时候一下子会计算四张图片的数据。实现方法:每次读取四张图片,分别对四张图片进行翻转、缩放、色域变化等,并且按照四个方向位置摆好,进行图片的组合和框的组合。
50.在一个实施例中,如图2所示,yolov4目标检测网络以cspdarknet53为主干,包含5个csp模块,各模块前的卷积核大小为3
×
3,步幅为2,能够进一步增强网络学习能力;路径聚合网络(panet)作为颈部,增添空间金字塔池(spp)附加模块,采用1
×
1,5
×
5,9
×
9,13
×
13最大池化方式,能够增加感受区并分离出更重要的上下文特征;沿用yolov3检测头作为头部。最后通过全连接层输出训练结果,包括边框回归坐标、目标分类结果和置信度大小。可以看到yolov4网络每一层的输出,每一层layer是如何得到的注释在了每一行后面,没有注释的就是对上一行的特征图进行卷积。yolov4网络共有161层,在608
×
608分辨率下,计算量总共128.46bflops,yolov3为141bflops。
51.本实施例中,为了进一步降低yolov4网络模型对gpu内存和模型存储要求,特将yolov4的特征提取网络改为mobilenetv3网络结构,参照图3所示,在bottlenet结构中加入了se结构,并且放在了depthwise filter之后。因为se结构会消耗一定的时间,所以在含有se的结构中,将expansion layer的channel变为原来的1/4,可提高了精度,同时还没有增加时间消耗。即:降低模型的参数,同时获取一定的精度。其次,为了进一步轻量化模型,在检测网络的cbl_block1、cbl_block2模块中使用深度可分离卷积代替传统卷积,避免了复杂模型导致的内存不足和高延迟。最后,将原yolov4网络每个尺度的最后一层conv2d 3
×
3卷积,改为inception网络结构,以提高图片中障碍物检测的准确率。
52.具体地,为了实现图像识别模型轻量化、小型化,本实施例中采用mobilenetv3网络作为骨干特征提取网络替换yolov4中原有的cspdarknet-53网络,以减少网络的整体计算量和内存占有量。
53.为了进一步使网络模型的轻量化,提升算法的实时性。本实施例中在检测网络中引入了深度可分离卷积代替传统卷积,降低模型对gpu内存和模型存储的要求。而在深度可分离网络中,卷积操作可以被分为两个步骤,假设卷积核的尺寸为dk
×
dk,输入特征图尺寸为df
×
df,m、n表示输入和输出的通道数,传统卷积的计算总量为f1,深度可分离卷积的计算总量为f2,两者计算量之比f2/f1可由下述公式来描述。
[0054][0055]
原始spp结构前后的cbl_block1,它包含2个1
×
1的卷积层和1个3
×
3的卷积层,和panet网络中,紧跟在concat操作之后的cbl_block2结构,它包括3个1
×
1的卷积层和2个3
×
3的卷积层。借鉴深度可分离卷积的思想,本实施例中,将采用1
×
1的点卷积和3
×
3的深度卷积代替原有的3
×
3传统卷积,同时使用在深层模型效果更优的非线性的h-swish函数作为激活函数取代原有检测网络中使用的leaky relu函数。相对于原始的检测网络,改进的检测网络既加快了计算速度,又使得网络深度进一步增加,增加了网络的非线性。
[0056]
inception网络结构在保持网络稀疏性的同时保持较好的计算性能,如图4a所示,采用不同大小的卷积核意味着不同大小的感受野,最后拼接意味着不同尺度特征的融合;之所以卷积核大小采用1、3和5,主要是为了方便对齐;inception里面也嵌入了pooling;网
络越到后面,特征越抽象,而且每个特征所涉及的感受野也更大了,因此随着层数的增加,3x3和5x5卷积的比例也要增加。
[0057]
为了进一步优化训练速度,可调节层的尺寸,通过调节层的尺寸来平衡各个模型子网间的计算量。采用1x1卷积核来进行降维,参照图4b所示,分别在3x3卷积和5x5卷积层之前增加1x1卷积核;而在3x3最大池化层之后增加1x1卷积核。
[0058]
例如:上一层的输出为100x100x128,经过具有256个输出的5x5卷积层之后(stride=1,pad=2),输出数据的大小为100x100x256。其中,卷积层的参数为5x5x128x256。假如上一层输出先经过具有32个输出的1x1卷积层,再经过具有256个输出的5x5卷积层,那么最终的输出数据的大小仍为100x100x256,但卷积参数量已经减少为1x1x128x32 5x5x32x256,大约减少了4倍。
[0059]
在inception结构中,大量采用了1x1的矩阵,主要是两点作用:1)对数据进行降维;2)引入更多的非线性,提高泛化能力,因为卷积后要经过relu激活函数。
[0060]
实施例2:
[0061]
基于同一发明构思,本发明实施例还提供了一种图像识别模型训练系统,由于该系统所解决问题的原理与前述方法相似,因此该系统的实施可以参见前述方法的实施,重复之处不再赘述。
[0062]
参照图5所示,一种图像识别模型训练系统,包括:
[0063]
采集模块,用于采集大量与道路场景相关的图片;所述图片至少包括:车辆、行人、建筑物、地面道路标线、路旁交通标志、道路上方空间的标识及位于道路内的障碍物;
[0064]
预处理模块,用于对所述图片进行预处理;且每一幅所述图片带有相应的标注框;
[0065]
构建模块,用于将经预处理后的所述图片,根据预设比例分为训练集和验证集;
[0066]
训练模块,利用所述训练集和验证集,对搭建的yolov4网络模型进行迭代训练,直到损失函数收敛,得到训练后的最优yolov4网络模型作为图像识别模型,实现道路场景图像识别。
[0067]
其中,预处理模块中,每一幅所述图片带有相应的标注框,包括:
[0068]
利用labelimg软件对所述图片标注成voc格式,标注每幅图片中的车辆、行人、建筑物、地面道路标线、路旁交通标志、道路上方空间的标识及位于道路内的障碍物。
[0069]
对所述图片进行预处理,包括:使用mosaic数据增强增加样本的数量。
[0070]
训练模块中的yolov4网络模型采用轻量mobilenetv3网络,且在检测器中引入深度可分离卷积和inception网络结构。
[0071]
实施例3:
[0072]
本发明实施例还提供一种图像识别方法,包括:
[0073]
(1)车辆在前进行驶过程中,实时获取前方道路场景图像;
[0074]
(2)将所述前方道路场景图像输入图像识别模型;所述图像识别模型通过所述上述实施例1所述的图像识别模型训练方法训练得到;
[0075]
(3)通过所述图像识别模型输出所述前方道路场景图像的识别结果。
[0076]
通过采用本实施例的图像识别方法,可配合激光雷达点云处理,可更好的辅助于自动驾驶,为自主驾驶智能决策提供参考。
[0077]
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精
神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。