一种基于fpga的卷积神经网络量化实现方法以及装置
技术领域
1.本发明涉及深度学习技术领域,尤其涉及一种基于fpga的卷积神经网络量化实现方法以及装置。
背景技术:
2.cnn(convolutiona lneura lnetworks,卷积神经网络)是一类包含卷积计算且具有深度结构的前馈神经网络(feedforward neura lnetworks),是深度学习(deep learning)的代表算法之一。在硬件层面上,当前cnn的部署主要是基于cpu、gpu、asic和fpga实现,各类部署均具有各自的优缺点:
3.1、基于cpu
4.cpu的运算时串行的,它具有灵活性高、可迁移性好的特点,但它在大规模并行运算上延时过大,难以在大规模cnn网络上应用,只能应用于一些专门设计的小规模网络。
5.2、基于gpu
6.gpu的灵活性较cpu略差,但gpu具有很多计算核心,这也让它有更强大的并行处理能力,同时它还有更加强大的控制数据流和储存数据的能力。但gpu功耗过大,这限制了它在一些嵌入式设备上的使用。
7.3、基于asic
8.asic功耗最低,在大批量生产时具有成本优势。asic定制化的特点决定了它的可迁移性低,其开发代价高昂,生产周期长,在网络和数据快速迭代的当下也限制了其发展。
9.4、基于fpga
10.fpga在gpu和asic中取得了权衡,很好的兼顾了处理速度和功耗和开发成本。但是fpga的一个缺点是其要求使用者能使用硬件描述语言对其进行编程,开发难度较大。
11.fpga(field programmable gate array)是在pal、gal、cpld等可编程逻辑器件的基础上进一步发展的产物。它是作为专用集成电路领域中的一种半定制电路而出现的,既解决了全定制电路的不足,又克服了原有可编程逻辑器件门电路数有限的缺点。fpga的开发相对于传统pc、单片机的开发有很大不同。fpga以并行运算为主,以硬件描述语言来实现;相比于pc或单片机(无论是冯诺依曼结构还是哈佛结构)的顺序操作有很大区别。fpga开发需要从顶层设计、模块分层、逻辑实现、软硬件调试等多方面着手。fpga可以通过烧写位流文件对其进行反复编程,目前,绝大多数fpga都采用基于sram(static random access memory静态随机存储器)工艺的查找表结构,通过烧写位流文件改变查找表内容实现配置。相对于gpu、fpga虽然灵活性和可迁移性较差、开发难度高,但fpga具有功耗低、速度快的优点,同时还有一定的成本优势,适合在一定批量的前提下的嵌入式终端部署。相对于asic,fpga与日增长的门资源和内存带宽使得它有更大的设计空间,同时fpga还省去了asic方案中所需要的流片过程,开发周期短,开发成本低。
12.使用fpga进行fpga部署时,需要将cnn网络分解为适合fpga实现的结构,fpga的计算单元分为dsp、乘加器、lut(逻辑查找表),需要将cnn的每个操作按fpga的计算单元1:1映
射到对应的操作逻辑,在fpga端再使用片上资源,整合数据搬运操作、数据计算操作所需单元,形成硬件操作层。
13.网络量化是现深度学习在应用端实现的关键,目前各类深度学习框架都已启用量化,通过网络量化可以实现:
14.1、降低内存容量。当卷积层的权重由32位浮点数量化为8位整型数时,权重的内存容量便减低为原来的1/4,这使得边缘端可以节约更多的内存容量和存储空间。
15.2、降低内存带宽。当卷积层的激活值由32位浮点数量化为8位整型数时,激活值向下传递时的内存带宽可以降低为原来的1/4,这对降低内存占用、提高读取性能有很大的帮助。
16.3、节约计算资源。在进行卷积运算时,当权重和激活值均由32位浮点数量化为8位整型数时,在支持8位乘法的设备上其运算效率可以提高4倍以上,大大节约了cpu的运算资源。
17.4、专门设计的量化方法使得网络在低端fpga上实现成为可能。fpga具有能耗低、可编程等优点,当专门设计的量化网络在fpga上实现时,可以做到算法硬件化,节约成本。
18.传统的浮点卷积或定点数卷积需要依赖大量的乘法和加法,因而要在fpga中实现cnn网络量化会存在大量的计算,导致计算量大,cnn实现效率低。当前神经网络在fpga的部署一般都是使用8bw/8ba或4bw/4ba量化,均需要基于乘法操作,不能充分利用fpga的强大逻辑运算能力,因而实际量化效率并不高。而现有技术中各类网络量化算法要实现低位量化,如hash映射、非均匀量化等,实现逻辑通常是非硬件友好的,即不便于在硬件中实现,难以推广到通用场景,以至几乎无法引入软件栈,并不适用于cnn在fpga中的部署量化。
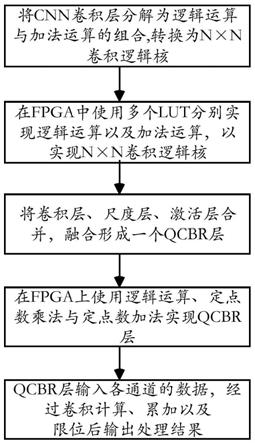
技术实现要素:
19.本发明要解决的技术问题就在于:针对现有技术存在的技术问题,本发明提供一种基于fpga的卷积神经网络量化实现方法以及装置,能够充分利用fpga的强大逻辑运算能力,高效实现cnn网络低位量化。
20.为解决上述技术问题,本发明提出的技术方案为:
21.一种基于fpga的卷积神经网络量化实现方法,该方法包括量化卷积核步骤,包括:
22.将cnn卷积层分解为逻辑运算与加法运算的组合,转换为n
×
n卷积逻辑核,n为大于2的正整数;
23.在fpga中使用多个lut分别实现所述逻辑运算以及加法运算,以实现所述n
×
n卷积逻辑核。
24.进一步的,所述n
×
n卷积逻辑核,通过将所述cnn卷积层中量化激活值按照预设量化位数进行按位拆分,分解为多个同或运算与多个加法运算的组合得到;所述n
×
n卷积逻辑核中包括转换后量化卷积参数w
′
与量化激活值的各个位之间的同或运算。
25.进一步的,当n=3,实现3
×
3卷积逻辑核时,使用多个lut计算3卷积逻辑核时,使用多个lut计算其中以及分别为量化激活值的第2、1、0位,w
′1、w
′2、w
′3分别为对应位的转换后量化卷积参数,
⊙
为同或符号,使用一个lut实现三个两位数加法,以及使用加法器实现各个分支输出的求和。
26.进一步的,该方法还包括将卷积层、尺度层、激活层合并,融合形成一个qcbr层,所
述qcbr层由所述n
×
n卷积逻辑核与倍数系数相乘后再与尺度层偏移系数相加得到,以使得在fpga上使用逻辑运算、定点数乘法与定点数加法实现所述qcbr层。
27.进一步的,实现所述qcbr层的步骤包括:
28.在fpga中使用所述n
×
n卷积逻辑核计算输入通道上的各个n
×
n卷积,得到n
×
n卷积结果;
29.使用加法器将所有输入通道上的所述n
×
n卷积结果进行累加,得到卷积累加结果;
30.使用乘加器将所述卷积累加结果与对应预设倍数系数相乘后与尺度层偏移系数相加,得到尺度运算结果;
31.对所述尺度运算结果进行限位后输出。
32.进一步的,该方法还包括训练步骤,包括:
33.构造初始cnn网络n并进行训练,得到预训练模型bwn-model;
34.将所述初始cnn网络n中的激活层替换为预设的激活层qrelu,形成更新后cnn网络qn;
35.将所述预训练模型bwn-model的各层权重加载到所述更新后cnn网络qn中,并对所述更新后cnn网络qn进行训练,直至训练完成。
36.进一步的,所述对所述更新后cnn网络qn进行训练的过程中包括分批次更新每个所述激活层qrelu的量化系数,步骤包括:
37.每次取当前批次的数据,对当前网络进行前向推理,判断所述更新后cnn网络qn中每一个所述激活层qrelu的输入,如果不存在大于0的数,则根据当前批次b更新所述量化系数,否则计算[aj,-aj]的标准差δ,aj为所述激活层qrelu中大于0的数,2δ为量化映射范围,根据所述标准差δ以及当前批次b更新所述量化系数。
[0038]
一种基于fpga的卷积神经网络量化实现装置,包括fpga,所述fpag上配置有量化卷积核模块,量化卷积核模块包括:
[0039]
第一lut单元,包括多个lut,用于计算将cnn卷积层转换为n
×
n卷积逻辑核中的逻辑运算,所述n
×
n卷积逻辑核为通过将cnn卷积层分解为逻辑运算与加法运算的组合转换得到;
[0040]
第二lut单元,包括多个lut,用于计算将cnn卷积层转换为n
×
n卷积逻辑核中的加法运算;
[0041]
加法器单元,用于对各个分支进行求和,得到最终的结果。
[0042]
进一步的,所述第一lut单元具体计算3
×
3卷积逻辑核中权重参数与量化激活值第0、1、2位之间的逻辑运算,所述第二lut单元具体计算3
×
3卷积逻辑核中权重参数与量化激活值第1位之间的各逻辑运算结果的加法运算,所述第一lut单元的输出端还设置有位拼接电路,以用于将各所述lut62的各位数据进行位拼接,所述第二lut单元的输出端还设置有末位补0电路,以用于将所述第二lut单元的输出数据进行末尾补0。
[0043]
进一步的,还包括将卷积层与尺度层、激活层融合形成的qcbr层实现模块,所述qcbr层实现模块包括:
[0044]
量化卷积单元,用于使用所述量化卷积核模块计算输入通道上的各个n
×
n卷积,得到n
×
n卷积结果;
[0045]
累加器,用于将所有输入通道上的所述n
×
n卷积结果进行累加,得到卷积累加结果;将所述卷积累加结果与对应预设融合系数相乘后与尺度层偏移系数相加,得到尺度运算结果;
[0046]
限位器,用于对所述尺度运算结果进行限位后输出。
[0047]
与现有技术相比,本发明的优点在于:
[0048]
1、本发明通过将cnn卷积层分解为逻辑运算与加法运算,转换为n
×
n卷积逻辑核,然后在fpga中实现该n
×
n卷积逻辑核,由于只需要进行逻辑运算与加法运算,适合于fpga实现,可以充分发挥fpga的强大逻辑运算能力,大幅降低所需的计算量、内存容量和读写带宽,实现高效的低位量化cnn卷积层。
[0049]
2、本发明进一步将卷积层、尺度层、激活层合并,融合形成一个qcbr层,qcbr层仅包含简单的逻辑元算、定点数乘法与定点数加法,适合于fpga实现,因而可以充分利用fpga同时高效的实现卷积层、尺度层以及激活层的计算功能,进一步降低所需的计算量、内存容量和读写带宽。
[0050]
3、本发明进一步通过采用边训练边量化的前量化方法进行低位量化cnn网络量化,相比于传统量化方式,可以有效提高量化训练的效率以及精度,实现低位量化cnn网络高精度训练。
附图说明
[0051]
图1是本实施例基于fpga的卷积神经网络量化实现方法的流程示意图。
[0052]
图2是本发明具体应用实施例中基于fpga实现3
×
3卷积逻辑核的结构原理示意图。
[0053]
图3是本实施例中基于fpga实现qcbr层的结构原理示意图。
[0054]
图4是传统混合量化方式的流程示意图。
具体实施方式
[0055]
以下结合说明书附图和具体优选的实施例对本发明作进一步描述,但并不因此而限制本发明的保护范围。
[0056]
cnn的网络模型量化主要包括两个部分,一是针对权重weight量化,一是针对激活值activation量化,将权重和激活值量化到8bit时可以等价32bit的性能。在神经网络中的基本操作就是权重和激活值的卷积、乘加操作,如果将其中一项量化到{-1,1},那么就能够将乘加操作简化为了加减操作,如果两项都量化到{-1,1},乘加操作就简化为了按位操作,通过上述将cnn的量化简化为加减、按位操作,可以使得量化过程对于硬件计算是友好的,即便于硬件实现。本发明基于上述考虑,通过将cnn卷积层分解为逻辑运算与加法运算,转换为n
×
n卷积逻辑核,n为卷积核数,然后在fpga中实现该n
×
n卷积逻辑核,由于只需要进行逻辑运算与加法运算,可以充分发挥fpga的强大逻辑运算能力,实现高效的低位量化cnn卷积层。
[0057]
如图1所示,本实施例基于fpga的卷积神经网络量化实现方法包括量化卷积核步骤,包括:
[0058]
s01.将cnn卷积层分解为逻辑运算与加法运算的组合,转换为n
×
n卷积逻辑核,n
为大于2的正整数;
[0059]
s02.在fpga中使用多个lut(逻辑查找表)分别实现逻辑运算以及加法运算,以实现n
×
n卷积逻辑核。
[0060]
本实施例中n
×
n卷积逻辑核,具体是通过将所述cnn卷积层中量化激活值按照预设量化位数进行按位拆分,分解为多个同或运算与多个加法运算的组合得到。上述n
×
n卷积逻辑核中包括转换后量化卷积参数w
′
与量化激活值的各个位之间的同或运算。
[0061]
当量化位n=k时,k为大于1的正整数,将量化卷积公式转换得到3
×
3卷积逻辑核的推导过程如下:
[0062][0063][0064]
其中,x
i,j
为量化激值,i表示1到c的任意一个通道,c为输入通道数,j表示n*n块中的第j个数值,w
i,j
为权重系数,中的q表示一个累加变量。
[0065]
以n=3,量化位数为3为例,将量化卷积公式转换得到3
×
3卷积逻辑核的推导过程如下:
[0066]
[0067]
上式中,w为量化卷积参数,其值为[-1,1],c为输入通道数;w
′
为转换量化卷积参数,值为[0,1],与w的值互为映射;x为3位量化激活值,其值为[0,1,
…
,6,7],x2为量化激活值第2位,其值为[0,1];x1为量化激活值第1位,其值为[0,1];x0为量化激活值第0位,其值为[0,1]。
[0068]
上述推导过程中,首先将量化激活值x
ij
按位进行拆分表示,即由于w
i,j
的值为[-1,1],的值为[0,1],相乘后会出现3值情况,无法用1位表示,因此将变换为变换后相乘的结果为[-1,1]仍为2值;由于的值为[-1,1],1位无法表示,因此通过公式将进行同等替换,其中
⊙
为同或符号,则转换得到3
×
3卷积逻辑核为由于w
i,j
与c均为已知数,设则βc为常数项,可以与后面的尺度(scale)层合并。上述3
×
3卷积逻辑核基于3位量化位分解得到,各部分均只需要一位表示,在fpga中通过lut与加法器,即可实现上述1bw3ba的3*3卷积核逻辑。
[0069]
为实现上述3
×
3卷积逻辑核f3×3(w
′i,xi),如图2所示,具体可使用多个lut计算其中以及分别为量化激活值的第2、1、0位,w
′1、w
′2、w
′3分别为对应位的转换后量化卷积参数,使用一个lut实现三个两位数(outmh、outmm、outml)加法,以及使用加法器实现各个分支(out1、out2、out3、out4)输出的求和。
[0070]
参见图2,使用22个lut(包括9个lut62以及1个lut64,每个lut62由2个lut组成,lut64由4个lut组成)、若干位操作电路和加法器实现上述3
×
3卷积逻辑核f3×3(w
′i,xi),lut是fpga最小可编程单元,运算结果是一bit数据,图2即是使用lut实现3bit特征图1bit权重的3乘3卷积,其中到是输入的9个3bit的特征数据的最低位,到是输入的9个3bit的特征图的中间位,到是输入的9个3bit的特征图的最高位,w
′
i,1
到w
′
i,9
是输入的9个1bit的权重。由lut62实现计算功能,即实现权重wi,1-wi,9分别和量化激活值xi,1~xi,9的第0位、第1位、第2位进行逻辑运算,输出为2位,值域为[0,3];lut64实现三个两位数(outmh、outmm、outml)加法功能,outmh、outmm、outml分别为w
′
i,1
到w
′
i,9
与到的三个逻辑运算结果,输出为4位,值域为[0,9],乘2后值域为[0,18];加法器实现4个分支(out1、out2、out3、out4)输出的求和,得到3*3卷积的结果,其输出值域为[0,63],刚好使用一个6位无符号整数表示。位拼接电路设置在各lut62的输出端,用于将各bit数据结合在一起,并不占用lut资源;末位补0电路输出在lut64的输出端,用于将1bit0数据拼接到该数据末尾,也不占用fpga资源。
[0071]
除上述量化为3位以外,还可以采用其他的量化位数(量化位数大于等于2),即将一个n位的激活值表示为:xi代表x的第i位;然后按照上述量化卷积公式进行同理推导,在不同的量化位数时,可以得出不同的fpga实现方式。
[0072]
以下以量化位数n=4为例重新推导得到:
[0073][0074][0075]
即量化位n=4时,3
×
3卷积逻辑核f3×3(w
′i,xi)为)为
[0076]
除构造如上述的3
×
3卷积逻辑核外,当然还可以构造其它n
×
n卷积,n位量化位数,原理与上述相同,即为:
[0077][0078]
其中,x
ij
量化激活值,w
i,j
为权重系数。
[0079]
以n=5为例,卷积逻辑核推导如下:
[0080][0081][0082]
综上,本实施例是通过将cnn卷积层按照量化位n,分解为多个逻辑运算与多个加法运算,构造出n
×
n卷积逻辑核,卷积逻辑核中各运算部分均可以使用1位进行表示,使得通过fpga中lut与加法器即可高效实现n
×
n卷积逻辑核。通过将cnn网络分解为适合fpga实现的结构,可以大幅降低cnn所需的计算量、内存容量和读写带宽。以一个3
×
3卷积为例,不同量化方式的计算量如下表1所示:
[0083]
表1:一个3x3卷积不同量化方式对比
[0084]
量化方式参数大小(bit)激活值大小(bit)计算量fp32288329次浮点乘法 9次浮点加法int87289次8位乘法 9次32位加法1bw 3ba9322次逻辑操作 4次6位加法
[0085]
如上述,量化卷积公式中转换后除卷积逻辑核外其余部分为常量,因为可以和尺度层合并。本实施例还包括将卷积层、尺度层、激活层合并,融合形成一个qcbr层,在fpga上使用逻辑运算、定点数乘法与定点数加法实现qcbr层,从而利用fpga的运算性能可以高效的同时实现卷积层、尺度层、激活层的功能。
[0086]
为构建qcbr层,本实施例首先为qcbr层定义以下参数:
[0087]
(1)c:输入通道数;
[0088]
(2)l:卷积层的序号;
[0089]
(3)w:量化卷积参数,其值为[-1,1];
[0090]
(4)第l层卷积层的参数量化系数;
[0091]
(5)x:uint3量化输入激活值,是第l-1层qcbr层的量化输出,第l层qcbr层的量化输入;
[0092]
(6)第l-1层qcbr层输出激活值的量化系数,单系数常量;
[0093]
(7)第l层qcbr层输出激活值的量化系数,单系数常量;
[0094]
(8)第l层尺度层倍数系数;
[0095]
(9)第l层尺度层偏移系数;
[0096]
(10)第l层qcbr层倍数系数;
[0097]
(11)第l层qcbr层偏移系数。
[0098]
然后将卷积层、尺度层与激活层融合形成qcbr层:
[0099]
卷积层表示为:
[0100][0101]
尺度层表示为:
[0102][0103]
激活层表示为:
[0104][0105]
将上述(4)、(5)、(6)融合形成:
[0106][0107]
其中,
[0108]
函数为限位函数,当x小于a时,输出为a;当x大于b时,输出为b;否则输出x。
[0109]
上述量化卷积逻辑核仅是以3
×
3卷积逻辑核为例,当然还可以为其他n
×
n卷积逻辑核。
[0110]
在fpga中通过计算单元实现上式(8),即可以实现qcbr层,qcbr层由卷积逻辑核与倍数系数相乘后再与尺度层偏移系数相加构成,仅包含简单的逻辑元算、定点数乘法与定点数加法,因而通过fpga可以同时的高效实现卷积层、尺度层以及激活层的计算功能。
[0111]
本实施例中,实现qcbr层的步骤包括:
[0112]
在fpga中使用n
×
n卷积逻辑核计算输入通道上的各个n
×
n卷积,得到n
×
n卷积结果;
[0113]
使用加法器将所有输入通道上的n
×
n卷积结果进行累加,得到卷积积加结果;
[0114]
使用乘加器将卷积累加结果与对应预设倍移系数相乘后与尺度层偏移系数相加,得到尺度运算结果;
[0115]
对尺度运算结果进行限位后输出。
[0116]
以实现如上式(8)的qcbr层为例,在fpga中首先使用量化卷积逻辑核计算输入通道上的每个3
×
3卷积,然后使用加法器将所有输入通道的上的3×
3卷积结果累加;然后使用乘加器实现卷积累加结果乘以并加上得到尺度运算结果;最后使用比较器对尺度运算结果进行限位后输出。
[0117]
训练量化也即为前量化,既网络边训练边进行量化,具有精度高、模型一致的特点,且低位量化网络必须使用训练量化。为在fpga中实现上述低位量化cnn网络前,本实施例采用训练量化方法实现网络的量化,该训练量化方法包括:
[0118]
构造初始cnn网络n并进行训练,得到预训练模型bwn-model;
[0119]
将初始cnn网络n中的激活层替换为预设的qrelu层,形成更新后cnn网络qn;
[0120]
将预训练模型bwn-model的各层权重加载到更新后cnn网络qn中,并对更新后cnn网络qn进行训练,直至训练完成。
[0121]
上述qrelu层按照下式定义激活值:
[0122][0123]
其中qr为qrelu层的量化系数,初始值为6/(2
q-1);ai为qrelu层的输入激活值,ak为qrelu层的输出激活值,a、b为预设阈值。
[0124]
传统fp32与int8的混合量化方式(如图4所示),在fp32在推理期间使用int8取代,但是训练仍然是基于fp32,因而训练效率以及精度并不高。本实施例通过的采用边训练边量化的前量化方法进行低位量化cnn网络量化,相比于传统fp32与int8的混合量化方式,可以有效提高量化训练的效率以及精度,实现低位量化cnn网络高精度训练。
[0125]
本实施例中,对更新后cnn网络qn进行训练的过程中包括分批次更新每个qrelu层的量化系数,具体步骤包括:
[0126]
每次取当前批次的数据,对当前网络进行前向推理,判断更新后cnn网络qn中每一qrelu层的输入,如果不存在大于0的数,则根据当前批次b更新所述量化系数,否则计算[aj,-aj]的标准差δ,aj为qrelu层中大于0的数,2δ为量化映射范围,根据标准差δ以及当前批次b更新量化系数。
[0127]
在具体应用实施例中,采用上述训练方法的详细步骤为:
[0128]
步骤1、构造l层cnn网络n,网络中所有的relu层均替换为relu6层,即使用relu6作为激活函数,relu6具体表示为:
[0129][0130]
步骤2、对网络n进行训练(网络训练方式可根据实际需求选取,如
×
nor-netbwn网络训练方式),得到预训练模型bwn-model。
[0131]
步骤3、定义激活值量化位数q,q为大于1的正整数;将网络n中的relu6层替换为qrelu层,生成新的量化网络命名为qn,其中qrelu层的激活值按上述式(8)定义,且梯度定义为:
[0132][0133]
其中,为qrelu层的输入激活值的梯度,为qrelu层的输出激活值的梯度。
[0134]
将预训练模型bwn-model的各层权重加载到qn中。
[0135]
步骤4、定义训练总轮数e,设当前训练轮数e为0。
[0136]
步骤5、更新每个qrelu层的量化系数qr。
[0137]
步骤5.1令b为一个轮次的最小批次的个数,设当前批次b为0;
[0138]
步骤5.2取当前批次b的数据,对网络进行前向推理,对于l层cnn量化网络qn中每一qrelu层的输入进行如下操作:
[0139]
设l为l层cnn量化网络中某一层,1≤l≤l,取第l层的qrelu层的输入中大于0的数,记为aj。若aj的个数为0,更新令否则计算[aj,-aj]的标准差δ,2δ为量化映射范围,更新令
[0140]
步骤5.3当前批次b递增1,如果b大于等于b,跳转6;否则跳转5.2。
[0141]
步骤6、对网络qn进行训练。
[0142]
步骤7、当前训练轮数e递增1,如果e大于等于e,结束;否则跳转5。
[0143]
上述qrelu层的激活值量化系数也可以不基于统计的方式,而是采用直接指定量化范围的方式,如取qr=p/(2
q-1),p为量化映射范围。
[0144]
为验证本发明上述训练方法的有效性,在具体应用实施例中分别对不同类型网络使用传统多种不同量化网络方法与本发明方法进行对比,结果如下表2所示,从表中可以看出,本发明通过特殊的低位量化网络的训练方式,可以使低位量化网络的精度仅仅略低于全精度网络,即可以实现高精度的网络量化。
[0145]
表2:不同类型网络在不同量化方式下指标对比
[0146][0147]
本实施例基于fpga的卷积神经网络量化实现装置,包括fpga,在fpga上配置有量化卷积核模块,量化卷积核模块包括:
[0148]
第一lut单元,包括多个lut,用于计算将cnn卷积层转换为n
×
n卷积逻辑核中的逻辑运算,n
×
n卷积逻辑核为通过将cnn卷积层分解为逻辑运算与加法运算的组合转换得到;
[0149]
第二lut单元,包括多个lut,用于计算将cnn卷积层转换为n
×
n卷积逻辑核中的加法运算;
[0150]
加法器单元,用于对各个分支进行求和,得到最终的结果。
[0151]
本实施例中,第一lut单元具体计算3
×
3卷积逻辑核中权重参数与量化激活值第
0、1、2位之间的逻辑运算,即计算其中以及分别为量化激活值的第2、1、0位,w
′1、w
′2、w
′3分别为对应位的转换后量化卷积参数,
⊙
为同或符号,第二lut单元具体计算3
×
3卷积逻辑核中权重参数与量化激活值第1位之间的各逻辑运算结果的加法运算,第一lut单元的输出端还设置有位拼接电路,以用于将各lut62的各位数据进行位拼接,第二lut单元的输出端还设置有末位补0电路,以用于将第二lut单元的输出数据进行末尾补0。如图2所示,n=3且量化位为3时,量化卷积核模块具体包括9个lut62(由2个lut组成)、1个lut64(由4个lut组成)、若干位操作电路和加法器以实现上述3
×
3卷积逻辑核f3×3(w
′i,xi),即第一lut单元包括9个lut62,实现计算功能,输出为2位,值域为[0,3],各lut62计算量化激活值的各位(xi1~xi9的第0、1、2位)与权重参数(wi1~wi9)之间的逻辑运算;第二lut单元包括1个lut64,实现三个两位数(outmh、outmm、outml)加法功能,输出为4位,值域为[0,9],乘2后值域为[0,18];由位拼接电路将各lut62的各位数据结合在一起,通过末位补0电路将0数据拼接到数据末尾,加法器单元实现4个分支(out1、out2、out3、out4)输出的求和,即将out1、out2、out3、out4四个数加起来得到3*3卷积的结果,其输出值域为[0,63],使用一个6位无符号整数表示。
[0152]
本实施例中,还包括将卷积层与尺度层、激活层融合形成的qcbr层实现模块,如图3所示,qcbr层实现模块包括:
[0153]
量化卷积单元,用于使用量化卷积核模块计算输入通道上的各个n
×
n卷积,得到n
×
n卷积结果;
[0154]
累加器,用于将所有输入通道上的所述n
×
n卷积结果进行累加,得到卷积累加结果;将所述卷积累加结果与对应预设融合系数相乘后与尺度层偏移系数相加,得到尺度运算结果;
[0155]
限位器,用于对所述尺度运算结果进行限位后输出。
[0156]
本实施例基于fpga的卷积神经网络量化实现装置与上述基于fpga的卷积神经网络量化实现方法的原理相同,在此不再一一赘述。
[0157]
上述只是本发明的较佳实施例,并非对本发明作任何形式上的限制。虽然本发明已以较佳实施例揭露如上,然而并非用以限定本发明。因此,凡是未脱离本发明技术方案的内容,依据本发明技术实质对以上实施例所做的任何简单修改、等同变化及修饰,均应落在本发明技术方案保护的范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。