1.本发明涉及机器人路径规划技术领域,具体涉及一种基于深度强化学习和块规划 的月面快速路径规划系统和方法。
背景技术:
2.月面机器人的路径规划是月面探测任务的设计和实施过程中的重要环节,对于提高月球 探测效率、保证探测机器人系统安全性具有重要意义。
3.一般来说,机器人的路径规划也可以分为全局规划和局部规划。月面全局路径规划是指 在月面遥感图像规划出从初始位置出发,规避撞击坑等障碍物并到达目标位置的自由路径节 点序列;而月面局部规划是指根据机器人在线或短期内感知到的局部地图,进行短期、短距 离的避障规划。目前,受到星表机器人局部感知能力运动能力的约束,其局部自主规划能够 覆盖的范围只有数米,月球机器人或火星机器人的路径规划以局部规划为主,无法无人自主 地实现远距离规划。随着月面探测活动范围的扩大和探测自主性要求的增加,有必要开展基 于月面遥感地图的远距离的快速路径规划方法。
4.在一些传统的全局路径规划中,首先将地图编码表征为可计算的栅格图或维诺图等,然 后基于搜索或者采样的原理进行机器人的安全路径求解,常用的算法包括粒子群算法,a*算 法,遗传算法,rrt,果蝇算法等。许多学者为提高月面全局路径规划的安全性、平滑性、 求解速度等,对这些算法做了许多改进。但是,这些算法通常是基于搜索或采样的,因此其 路径规划速度严重依赖于求解空间的大小,当然规划任务范围增大或障碍物比较复杂时,算 法应用的时间消耗会按指数规律增大,这在一定程度上限制了月面大范围地形上的路径规划 的应用。
5.近年来,随着深度学习和深度强化学习方法在图像推理和机器人控制领域得到了广泛研 究和应用。深度学习具有很强的深度数据建模能力,善于提取图像、语音、语言等信息中的 时间和空间特征;而强化学习模拟生物对外界刺激做出反应的现象,能够从过去的经验中, 而不需要标签数据的监督下进行自学习。基于学习的方法进行路径规划具备一些传统方法难 以突破的优势。首先,其可以直接基于地图像素矩阵进行路径规划,而不需人为地将地图表 征成计算机可计算的障碍空间和自由空间;此外,基于学习的方法构建端到端的规划器,通 过网络推理进行路径规划,相比基于搜索和采样原理的方法,在求解时间上有巨大的潜在优 势。但是,目前的基于学习的方法的缺点在于,受限于神经网络的结构,其通常只能对特定 尺寸的地图进行规划,而如果规划范围较大时,缩小尺寸后进行规划可能会导致严重的精度 损失,导致规划的路径不可用。
6.现有技术的缺点总结如下:
7.1.a*,rrt等传统路径规划算法首先需要将地图表征为障碍空间和安全空间,其规划效 果依赖于人为经验;
8.2.传统路径规划算法的求解速度严重依赖于求解空间的大小,当然规划任务范围增大或 障碍物比较复杂时,算法应用的时间消耗会按指数规律增大,这在一定程度上限制
了月面大 范围地形上的路径规划的应用;
9.3.对基于学习的规划方法来说,受限于神经网络的结构,其通常只能对特定尺寸的地图 进行规划,而如果规划范围较大时,缩小尺寸后进行规划可能会导致严重的精度损失,导致 规划的路径可用性较差。
技术实现要素:
10.本发明的目的在于针对现有技术的不足,提供一种基于深度强化学习和块规划的 月面快速路径规划方法,用于解决以下问题:
11.(1)通过端到端的方法实现直接基于二值化可通行性地图进行路进规划,而不需 要在地图上进行障碍物识别、定位和计算图表征。
12.(2)实现月面机器人在大范围月面地形上的快速路径规划,减小规划时间消耗;
13.(3)解决现有的基于学习方法受限于神经网络结构而无法对任意尺度地图进行精 确路径规划的困难。
14.本发明采用的技术方案如下:
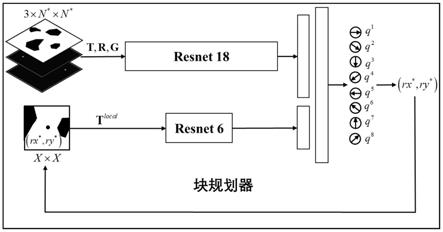
15.一种基于深度强化学习和块规划的月面快速路径规划系统,由一个基于深度q网络的块 规划器和一个块规划应用架构构成;
16.基于深度q网络的块规划器:基于深度q网络的端到端的规划器,用于特定的n
*
×n*
尺 寸的月面可穿越性地图上的路径规划,采用一种双通道输入的深度q网络来建立全局状态信 息到最佳运动方向的映射关系,包括全局通道和局部通道两个通道。全局通道用于提取全局 信息,包括全局可穿越性地图t,机器人的当前位置(rx
*
,ry
*
)和目标位置(gx
*
,gy
*
)。全局状态 通过一个维度为3
×n*
×n*
的3层状态立方来表示,包括全局可穿越性地图t、机器人位置图r 和目标位置图g,其中机器人位置层和目标位置层是n
*
×n*
的空白图上标记位置信息构成的。 全局通道通过一个18层的残差卷积神经网络(resnet18)进行特征提取。局部通道用于进行 机器人瞬时位置周边近距离的x个单元格范围内障碍物信息提取和推理,其输入矩阵维度为1
×
x
×
x,记为t
local
。局部通道由于其输入局部地图的尺度较小,采用一个6层的残差卷积神 经网络(resnet 6)进行信息推理。全局特征和局部特征通过两个全连接层进行融合,进而进 行机器人运动方向评价值的估计。网络输出为指向机器人周边8个方向动作的评价值。经训 练,该q网络输出的最大评价值所对应动作即为当前全局和局部状态输入情况下的最优动作。 经块规划器的迭代求解,可以求出地图t上的一条轨迹,记为 17.块规划应用架构:基于分层思想设计的一种块规划应用架构,一方面能够有效压缩大范 围地图上路径规划的求解空间,另一方面克服了单一块规划器只能进行特定尺寸地图上路径 规划的缺点。对于一张尺寸为n
×
n的二值化可穿越性地图(n>n
*
),首先将其缩小为n
*
×n*
的可规划图,利用块规划器进行粗略初始路径求解;然后,沿着初始粗略路径均匀地选取一 些导航点;然后,利用块规划器依次在每两个相邻导航点之间进行精确路径求解;最后依次 将每两个相邻导航点之间的路径进行拼接,得到原n
×
n尺寸地图上的路径规划结果。
18.进一步地,其训练奖励采用一种稠密奖励机制,用于促进算法学会趋近目标、规避
障碍 物以及优化路径长度等行为,从而能够自动地基于输入可穿越性地图和机器人、目标位置信 息进行规划。奖励函数包含目标到达奖励、目标趋近奖励、触障奖励、能量优化奖励以及平 滑奖励,最终的奖励是这四项奖励的求和。目标到达奖励,记为如果时刻k机器人到 达目标位置,则其取值为1,否则为0;目标趋近奖励,记为将其设计为机器人趋近 目量的线性函数,可以表示为其中如果在 时刻k机器人趋近了目标,则取值为正,否则为负;触障奖励记为当机器人到达障碍 物区域时,其取值为-1,否则取值为0。在我们的算法中,触碰障碍物可以通过t(rx,ry)=0来 判定。表示能量成本奖励,其设置的目的是优化路径长度,其取值取决于当时选取的动作, 如果规划器选取了沿grid边的奖励,则如果规划器选取了沿着grid对角线的奖励, 其中c表示机器人行走单位长度的能量成本,并且有c<0;平滑性奖励记为其目的是为了使得到的路径更加平滑,如果当前时刻规划器选取的动作是否与前一时刻的相 同则其取值s=0,否则s<0。最终算法在k时刻的奖励可以通过上述奖励项求和得到:
[0019][0020]
进一步地,其块规划器的训练地图集通过以下方法进行构建:首先,人工构造的一个仿 真月面地形图,包含若干个撞击坑和若干个高地。将仿真地形图上的撞击坑和高地的数字高 程数据提取出来,分别独立进行横、纵尺寸的变换,随后将其随机叠加到一张平地的大尺度 地形图上。地形尺寸变化倍数因子和每张地图上的障碍(撞击坑和高地)的数量服从均匀分 布,每个障碍物的随机初始化位置坐标服从独立的均匀分布。通过上述操作,得到了包含若 干张障碍物随机分布的大尺度地图。在每一张大尺度地图上随机截取若干张不同尺度的地图, 其每个边幅尺寸服从均匀分布。最终获取了包含大量障碍物随机分布、不同尺寸月面地形图 的训练集。
[0021]
进一步地,块规划器的算法流程按次序包含:块规划输入,块规划变量初始化,步规划, 位置更新和路径输出。
[0022]
(1)块规划器输入
[0023]
对于一张给定的尺寸为n
*
×n*
的二值化可穿越性地图t上的规划任务,明确起始位置和 目标位置(sx
*
,sy
*
),(gx
*
,gy
*
)。
[0024]
(2)块规划器变量初始化
[0025]
将起始位置设置为机器人初始位置,即将局部通道输入尺寸初始化为 x
×
x。
[0026]
(3)步规划
[0027]
块规划器的每一步规划通过一次深度q网络推理来实现。在步规划时,根据当前时刻机 器人的位置和局部通道输入尺寸x,按照t
local
=t(rx
*-x/2:rx
*
x/2,ry
*-x/2:ry
*
x/2) 计算局部通道输入t
local
。将t
local
与t,r,g一起输入到q网络中进行当前状态下8个动作 的评价值的估计,并以最大评价值所对应的动作作为当前状态对应的最优动作,即: ak=arcmax(qk(sk,a))。
转换公式为:
[0046][0047]
然后,以为输入,利用块规划器进行两点之间的精确 路径规划,输出路径记为
[0048]
最后,将块规划器输出的路径转化为原来尺寸为n
×
n的地图上的路径路径节点坐 标转换表达式为:
[0049][0050]
(6)路径拼接
[0051]
将j-1个块地图上的路径规划结果依次进行拼接,得到最终的路径ψ
final
,可以表示为:
[0052][0053]
本发明的有益效果如下:
[0054]
1.本发明所提供的基于深度强化学习和块规划的月面快速路径规划方法,是一种 端到端的方法,能够直接基于二值化可通行性地图进行路进规划,而不需要在地图上 进行障碍物识别、定位和计算图表征。
[0055]
2.本发明通过端到端和块规划应用架构的设计,有效压缩了大范围地图上路径规 划的求解空间,实现月面机器人在大范围月面地形上的快速路径规划,减小规划时间 消耗;
[0056]
3.本发明通过块规划应用架构的设计,突破了现有基于学习方法受限于神经网络 结构而无法对任意尺度地图进行精确路径规划的限制。
附图说明
[0057]
图1为块规划器;
[0058]
图2为块规划器的训练地图集构建方法
[0059]
图3为块规划器的算法流程图;
[0060]
图4为块规划应用架构;
[0061]
图5为块规划应用架构的操作流程图;
[0062]
图6为基于深度强化学习和块规划的月面快速路径规划方法的一种具体应用结果 示例图。
具体实施方式
[0063]
下文中,结合附图和实施例对本发明作进一步阐述。
[0064]
本发明基于深度强化学习和块规划的月面快速路径规划系统,由一个基于深度q网络的 端到端的块规划器和一个块规划应用架构构成。
[0065]
1.基于深度q网络的块规划器
[0066]
1.1.块规划器的构成
[0067]
块规划器是一种基于深度q网络的端到端的规划器,用于特定的n
*
×n*
尺寸的月面可穿 越性地图上的路径规划,其中n
*
表示用于规划器输入的地图的尺寸。可穿越性地图是基于月面数 字高程模型生成的二值化地图,其像素值取“1”的位置为可穿越区域,像素值取“0”的位 置为不可以穿越区域。块规划器采用一种双通道输入的深度q网络来建立全局状态信息到最 佳运动方向的映射关系,其输入包含全局通道和局部通道两个通道。全局通道用于提取全局 信息,包括全局可穿越性地图t,机器人的当前位置(rx
*
,ry
*
)和目标位置(gx
*
,gy
*
)。为了让网络 更加直接的理解机器人位置和目标位置的空间关系,在全局可穿越性地图的基础上,增加一 层机器人位置层和一层目标位置层,机器人位置层和目标位置层是n
*
×n*
的空白图上标记位 置信息构成的,如图1所示。因此,全局状态通过一个维度为3
×n*
×n*
的3层状态立方来表 示,包括全局可穿越性地图t、机器人位置图r和目标位置图g。全局通道通过一个18层的 残差卷积神经网络(resnet18)进行特征提取。局部通道主要用于进行机器人瞬时位置周边近 距离的x个单元格范围内障碍物信息提取和推理,其输入矩阵维度为1
×
x
×
x,记为t
local
。局 部通道由于其输入局部地图的尺度较小,采用一个6层的残差卷积神经网络(resnet6)进行 信息推理,其由3个basicblock模块串联构成。全局特征和局部特征通过两个全连接层进行 融合,进而进行机器人运动方向评价值的估计。网络输出为指向机器人周边8个方向动作的 评价值。经训练,该q网络输出的最大评价值所对应动作即为当前全局和局部状态输入情况 下的最优动作。经块规划器的迭代求解,可以求出地图t上的一条轨迹,记为 其中ψ
*
表示规划器输出的路径,表示路径上的节点,i表 示节点索引,的坐标,本文用ψ
*
表示块规划器的内部变量,用下标i表示一条路径 上节点的索引值。
[0068]
1.2.块规划器的训练
[0069]
(1)奖励函数设计
[0070]
为实现规划器的快速训练,设计了一种稠密奖励机制,用于促进算法学会趋近目标、规 避障碍物以及优化路径长度等行为,从而能够自动地基于输入可穿越性地图和机器人、目标 位置信息进行规划。奖励函数包含目标到达奖励、目标趋近奖励、触障奖励、能量成本奖励 以及平滑奖励,最终的奖励是这四项奖励的求和。目标到达奖励,记为如果时刻k机 器人到达目标位置,则其取值为1,否则为0;目标趋近奖励,记为将其设计为机器 人趋近目量的线性函数,可以表示为其中其中λ线性放大系数,(rxk,ryk)为k时刻机器人的位置,(gx,gy)为目标位置,如果在时刻k机器人趋 近了目标,则取值为正,否则为负;触障奖励记为当机器人到达障碍物区域时,其取 值为-1,否则取值为0。在本发明的算法中,触碰障碍物可以通过t(rxk,ryk)=0来判定,其中 (rxk,ryk)为机器人当前时刻的位置。表示能量成本奖励,其设置的目的是优
化路径长度, 其取值取决于当时选取的动作,如果规划器选取了沿grid边的奖励,则如果规划器 选取了沿着grid对角线的奖励,其中c表示机器人行走单位长度的能量成本,并且 有c<0;平滑性奖励记为其目的是为了使得到的路径更加平滑,如果当前时刻规划器 选取的动作是否与前一时刻的相同则其取值s=0,否则s<0。最终算法在k时刻的奖励可以通 过上述奖励项求和得到:
[0071][0072]
(2)训练地图集构建与训练
[0073]
构建训练地图集,进行块规划器的训练,如图2所示。首先,人工构造的一个仿真月面 地形图,包含若干个撞击坑和若干个高地。将仿真地形图上的撞击坑和高地的数字高程数据 提取出来,分别独立进行横、纵尺寸的变换,随后将其随机叠加到一张平地的大尺度地形图 上。地形尺寸变化倍数因子和每张地图上的障碍(撞击坑和高地)的数量服从均匀分布,每 个障碍物的随机初始化位置坐标服从独立的均匀分布。通过上述操作,得到了包含若干张障 碍物随机分布的大尺度地图。在每一张大尺度地图上随机截取若干张不同尺度的地图,其每 个边幅尺寸服从均匀分布。最终获取了包含大量障碍物随机分布、不同尺寸月面地形图的训 练集。
[0074]
在每个训练回合开始时,从训练集中随机选取一张尺寸为n
×
n的地形图,将其转化为尺 寸为n
*
×n*
的二值化可穿越性地图。将机器人的初始位置和目标位置按照均匀分布进行随机 初始化。训练采用边采样边训练的方式。将k时刻机器人的位置记为其综合状态为sk, 那么若机器人采用动作ak之后获得了奖励rk,并到达位置,得到 新的综合状态那么[sk,ak,rk,sk]构成一个训练样本。将q网络代表的规划 策略为π(θk),其中θk表示网络权值。那么网络训练的损失函数可以基于贝尔曼方程表示为:
[0075][0076]
上式中,γ表示未来奖励的折扣因子,表示过去某一时刻的网络模型的权重,q
π
表示 策略π下的动作评价值,a'表示下一个时刻可能采取的动作。
[0077]
1.3.块规划器的算法流程
[0078]
块规划器的算法按次序包含:块规划器输入,块规划器变量初始化,步规划,位置更新 和路径输出。图3所示为块规划器的算法流程图。
[0079]
(1)块规划器输入
[0080]
对于一张给定的尺寸为n
*
×n*
的二值化可穿越性地图t上的规划任务,明确规划任务的 起始位置(sx
*
,sy
*
)和规划任务目标位置(gx
*
,gy
*
)。
[0081]
(2)块规划器变量初始化
[0082]
将规划任务起始位置(sx
*
,sy
*
)设置为机器人初始位置即将局 部通道输入尺寸初始化为x
×
x。
[0083]
(3)步规划
[0084]
块规划器的每一步规划通过一次深度q网络推理来实现。在步规划时,根据当前时
刻机 器人的位置(rx
*
,ry
*
)和局部通道输入尺寸x,按照t
local
=t(rx
*-x/2:rx
*
x/2,ry
*-x/2:ry
*
x/2) 计算局部通道输入t
local
。将t
local
与t,r,g一起输入到q网络中进行当前状态下8个动作 的评价值的估计,并以最大评价值所对应的动作作为当前状态对应的最优动作,即: ak=arcmax(qk(sk,a)),其中ak为当前时刻的动作,sk为当前时刻的综合状态,qk(sk,a)为当前状态的动 作评价值,a表示动作变量。
[0085]
(4)位置更新
[0086]
通过位置更新使得规划进入下一步。首先判断机器人是否到达了目标位置,如果且则进入第(5)步进行路径输出;否则,按照更新机器人位置,并返回到第(3) 步进行下一步规划。
[0087]
(5)块规划器输出
[0088]
输出规划结果,用来表示规划器在t上求解出的一 条轨迹。
[0089]
2.块规划应用架构
[0090]
2.1.块规划应用架构的构成
[0091]
基于分层思想设计了一种块规划应用架构,一方面能够有效压缩大范围地图上路径规划 的求解空间,另一方面克服了单一块规划器只能进行特定尺寸地图上路径规划的缺点。对于 一张尺寸为n
×
n的二值化可穿越性地图(n>n
*
),首先将其缩小为尺寸为n
*
×n*
的可规划 图,利用块规划器进行粗略初始路径求解;然后,沿着初始粗略路径均匀地选取一些导航点; 然后,利用块规划器依次在每两个相邻导航点之间进行精确路径求解;最后依次将每两个相 邻导航点之间的路径路径进行拼接,即得到原n
×
n尺寸地图上的路径规划结果。图4所示为 本发明所提供的块规划应用架构。
[0092]
2.2.块规划应用架构的操作流程
[0093]
块规划应用架构与块规划器联合使用。其操作流程如图5所示,包括:任务初始化;尺 寸变换;初始粗略规划;导航点求解;精确路径规划;路径拼接。
[0094]
(1)任务初始化
[0095]
对于给定的地形图,将其转化为n
×
n的二值化可穿越性地图t
init
,确定规划任务的起始 位置(sx,sy)和目标位置(gx,gy)。
[0096]
(2)尺寸变换
[0097]
将尺寸n
×
n的二值化可穿越性地图t
init
按照k=n/n
*
变换为尺寸为n
*
×n*
的块规划器的 可规划地图,k表示地图尺寸变换比。将起始位置和目标位置坐标变换到t上,得到块规划 器可输入位置坐标:sx
*
=sx/k,sy
*
=sy/k,gx
*
=gx/k,gy
*
=gy/k。
[0098]
(3)初始粗略规划
[0099]
利用块规划器在缩小地图上进行初始粗略路径的规划。将尺寸变换得到到地图t和位置 变量输入到块规划器,并按照块规划器算法流程进行路径规划,将输出的路径结果记为ψ
init*
。 将块规划器输出的路径节点坐标扩大k倍,即可得到原地图上的初始粗略路径,即ψ
init
=kψ
init*
[0100]
(4)导航点求解
[0101]
导航点求解是在初始粗略路径ψ
init
的基础上进行精确路径求解的前提。导航点是
确定精确 路径块规划位置和块地图的一系列关节点。从起始点(sx,sy)开始,沿着初始路径,均匀地选 取初始路径上的节点作为导航点。导航点的数量j可以根据式确定,l
init
表示初始路 径节点数量,j表示导航点的索引,为第j个导航点的坐标,表示初始路 径上第个节点的坐标;具体按照下式确定导航点坐标:
[0102][0103]
(5)精确块规划
[0104]
从起始点(sx,sy)开始,沿着初始粗略路径,在每两个相邻的导航点之间进行块规划,即求解 从导航点到的精确路径。
[0105]
首先,确定块地图的中心位置坐标和块地图像素矩阵中心坐标的计算公 式为根据块地图的中心坐标,可以确定其像素矩阵为 [0106]
然后,将导航点坐标转化为块地图上的起始点和目标点坐标转换公式为:
[0107][0108]
然后,以为输入,利用块规划器进行两点之间的精确 路径规划,输出路径记为表示第j个块地图上的路 径节点坐标。
[0109]
最后,将块规划器输出的路径转化为原来尺寸为n
×
n的地图上的路径路径节点坐 标转换表达式为:
[0110][0111]
(6)路径拼接
[0112]
将j-1个块地图上的路径规划结果依次进行拼接,得到最终的路径ψ
final
,可以表示为:
[0113][0114]
图6(a)为一个基于深度强化学习和块规划的月面快速路径规划方法的一个具体实施案 例的规划结果。其中,测试地图采用中科院国家天文台提供的ce2tmap2015全月高精度地 图模型中图幅#l007上的某10000m
×
10000m范围的地形上,其分辨率为20m/pixel,
因此原 地图的网格尺寸为500
×
500(n=500),规划任务的起始位置和目标位置分别设为(197,67) 和(405,451),局部通道输入尺寸初始化为10
×
10(x=10);图6(b)为此具体实施案 例的规划过程中每次调用块规划器得到的块地图上的路径结果,其中初始块为缩小地图上的 初始粗略路径,块1-8为沿着初始粗略路径得到的相邻导航点坐标之间的块地图上的路径规 划结果。
[0115]
本发明虽然已以较佳实施例公开如上,但其并不是用来限定本发明,任何本领域技术人 员在不脱离本发明的精神和范围内,都可以利用上述揭示的方法和技术内容对本发明技术方 案做出可能的变动和修改,因此,凡是未脱离本发明技术方案的内容,依据本发明的技术实 质对以上实施例所作的任何简单修改、等同变化及修饰,均属于本发明技术方案的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。