基于redis的分布式id生成方法、装置及介质
技术领域
1.本发明涉及分布式id生成技术领域,具体地说是基于redis的分布式id 生成方法、装置及介质。
背景技术:
2.现有的分布式id生成方案包括数据库自增长序列、uuid以及 uid-generator等。
3.数据库自增长序列是最常见的方式之一,利用数据库生成,全数据库唯一。其具有如下缺点:
4.(1)不同数据库语法和实现不同,数据库迁移的时候或多数据库版本支持的时候需要进行处理;
5.(2)在单个数控或读写分离或一主多从的情况下,只有一个主库可以生成,有单点故障的风险;
6.(3)在性能达不到要求的情况下,比较难以扩展;
7.(4)如果遇见多个系统需要合并或涉及到数据迁移会相当痛苦;
8.(5)分表分库的时候会有麻烦。
9.uuid是常见方式,可以利用数据库生成,可以利用程序生成,一般来说全球唯一。其具有如下缺点:
10.(1)没有排序,无法保证趋势递增;
11.(2)uuid往往是使用字符串存储,查询的效率比较低;
12.(3)存储空间比较大,如果是海量数据库,就需要考虑存储量的问题;
13.(4)传输数据量大。
14.uidgenerator项目基于snowflake原理实现,只是修改了机器id部分的定义(实例重启的次数),并且64位bit的分配支持配置,官方提供的默认分配方式如图1所示。snowflake算法描述:指定机器&同一时刻&某一并发序列,是唯一的。据此可生成一个64bits的唯一id(long)。
15.sign(1bit),固定1bit符号标识,即生成的uid为正数;
16.delta seconds(28bits),当前时间,相对于时间基点"2016-05-20"的增量值,单位:秒,最多可支持约8.7年;
17.worker id(22bits),机器id,最多可支持约420w次机器启动。内置实现为在启动时由数据库分配,默认分配策略为用后即弃,后续可提供复用策略;
18.sequence(13bits),每秒下的并发序列,13bits可支持每秒8192个并发。
19.该uidgenerator只能用8.7年,机器id总共有420万个,应用重启一次减少一个。
20.在复杂分布式系统中,需要对大量的数据和消息进行唯一标识。传统的数据库自增主键,或者单体的自增主键,已经不能满足需求。
21.传统的基于雪花算法实现的分布式id生成器,由于应用较少可以手动配置 workid。目前大多数公司的系统使用的都是微服务架构,微服务架构将应用程序构造为一
组松散耦合的服务,服务是细粒度的,应用数量比较多,并且使用容器化部署,软件系统会根据负载情况自动扩容和缩容,应用没有固定的ip,不能像传统应用那样进行手动设置雪花算法中的workid。
22.基于上述分析,如何在不依赖数据库的情形下快速稳定的生成workid,并实现workid的自动灵活配置,是需要解决的技术问题。
技术实现要素:
23.本发明的技术任务是针对以上不足,提供基于redis的分布式id生成方法、装置及介质,来解决如何在不依赖数据库的情形下快速稳定的生成workid,并实现workid的自动灵活配置的技术问题。
24.第一方面,本发明的基于redis的分布式id生成方法,对于每个应用节点,通过如下步骤分配workid:
25.应用节点定时启动时,如果所述应用节点未被分配workid,执行id分配步骤为所述应用节点分配workid;
26.如果所述应用节点已被分配workid,基于worid判断redis中存储的 value值是否与所述应用节点的value值一致,如果一致,根据需要选择性地更新所述应用节点的过期时间,如果不一致,执行workid分配步骤重新为所述应用节点分配workid;
27.所述workid分配步骤包括:从redis中获取空闲列表,并遍历空闲列表查找未被其它应用节点占用的空闲workid,将所述空闲workid分配给所述应用节点作为key,将所述应用节点的ip和端口号作为value存储至redis,并为所述应用节点的workid设置过期时间;
28.对于超过过期时间的应用节点,将所述应用节点的workid释放并回收,重新生成空闲列表并存储至redis。
29.作为优选,所述workid分配步骤中,从redis中获取空闲列表,并遍历空闲列表查找未被其它应用节点占用的空闲workid,如果空闲列表所有应用节点均已被其它应用节点占用,通过雪花算法重新为所述redis配置 workid。
30.作为优选,所述workid分配步骤中,如果redis中不存在空闲列表,通过所述应用节点生成一个空闲列表并存储至redis中,通过雪花算法为所述redis配置workid。
31.作为优选,将所述应用节点的ip和端口号作为value存储至redis时,所述value格式为:ip:端口号。
32.作为优选,所述应用节点定时启动任务的周期间隔小于其workid在 redis的过期时间。
33.作为优选,监控所述应用节点占用workid对应的机器列表中应用节点的个数以及对应的空闲列表中空闲workid的个数,如果应用节点的个数得到最大数的workid,通过雪花算法重新为所述空闲列表配置workid。
34.第二方面,本发明的装置,包括:至少一个存储器和至少一个处理器;
35.所述至少一个存储器,用于存储机器可读程序;
36.所述至少一个处理器,用于调用所述机器可读程序,执行第一方面任一所述的方法。
37.第三方方面,本发明的介质,为计算机可读介质,所述计算机可读介质上存储有计
算机指令,所述计算机指令在被处理器执行时,使所述处理器执行第一方面任一所述的方法。
38.本发明的基于redis的分布式id生成方法、装置及介质具有以下优点:
39.1、使用redis保证了雪花算法中的workid唯一,每个应用节点启动时从redis 获取workid的空闲列表,生成唯一workid;
40.2、应用节点定时为本节点使用的workid续期,redis中以workid作为key, ip和端口号作为value,避免了同一workid对应多个节点的情况。
附图说明
41.为了更清楚地说明本发明实施例中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域的普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
42.下面结合附图对本发明进一步说明。
43.图1为雪花算法的结构示意图;
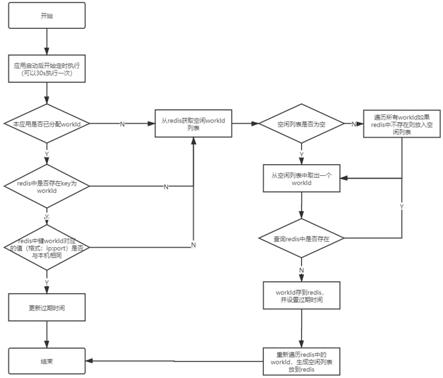
44.图2为基于redis的分布式id生成方法的流程框图。
具体实施方式
45.下面结合附图和具体实施例对本发明作进一步说明,以使本领域的技术人员可以更好地理解本发明并能予以实施,但所举实施例不作为对本发明的限定,在不冲突的情况下,本发明实施例以及实施例中的技术特征可以相互结合。
46.本发明实施例提供基于redis的分布式id生成方法、装置及介质,用于解决如何在不依赖数据库的情形下快速稳定的生成workid,并实现workid的自动灵活配置的技术问题。
47.实施例1:
48.本发明基于redis的分布式id生成方法,对于每个应用节点,通过如下步骤分配workid:
49.应用节点定时启动时,如果所述应用节点未被分配workid,执行id分配步骤为所述应用节点分配workid;
50.如果所述应用节点已被分配workid,基于worid判断redis中存储的 value值是否与所述应用节点的value值一致,如果一致,根据需要选择性地更新所述应用节点的过期时间,如果不一致,执行workid分配步骤重新为所述应用节点分配workid;
51.workid分配步骤包括:从redis中获取空闲列表,并遍历空闲列表查找未被其它应用节点占用的空闲workid,将所述空闲workid分配给所述应用节点作为key,将所述应用节点的ip和端口号作为value存储至redis,并为所述应用节点的workid设置过期时间;
52.对于超过过期时间的应用节点,将应用节点的workid释放并回收,重新生成空闲列表并存储至redis。
53.本实施例中应用节点的ip和端口号作为value存储至redis时,所述value 格式为:ip:端口号。
54.workid分配步骤中,从redis中获取空闲列表,并遍历空闲列表查找未被其它应用节点占用的空闲workid,如果空闲列表所有应用节点均已被其它应用节点占用,通过雪花算法重新为所述redis配置workid。
55.workid分配步骤中,如果redis中不存在空闲列表,通过所述应用节点生成一个空闲列表并存储至redis中,通过雪花算法为所述redis配置workid。
56.在设置应用节点的定时启动任务周期时,应用节点定时启动任务的周期间隔小于其workid在redis的过期时间。
57.雪花(snowflake)算法生成id的结果是一个64bit大小的整数,它的结构如图1所示。
58.第一个1bit,不可用,因为二进制中最高位是符号位,1表示负数,0表示正数。生成的id一般都是用整数,所以最高位固定为0。
59.中间一组的41bit,为时间序列,精确到毫秒级,41位的长度可以使用69 年。注意,41位时间戳不是存储当前时间的时间戳,而是存储时间戳的差值(当前时间戳-开始时间戳)后得到的值,这里的的开始时间戳,一般是我们的id 生成器开始使用的时间,由我们程序来指定的。
60.中间一组的10bit,为机器标识,10位的长度最多支持部署1024个节点。
61.最后一组的12bit,为计数序列号,序列号即一系列的自增id,可以支持同一节点同一毫秒生成多个id序号,12位的计数序列号支持每个节点每毫秒产生4096个id序号。
62.雪花算法存在机器id的分配和回收问题,目前机器id需要每台机器不一样,这样的方式分配需要有方案进行处理,同时也要考虑,如果该机器宕机了,对应的workerid分配后的回收问题。百度的uid-generator基于雪花算法实现,只是修改了机器id部分的定义(实例重启的次数)。workid由10bit改为22bit,内置实现为在启动时由数据库分配,默认分配策略为用后即弃。百度通过在数据库建表,生成不重复且递增的机器id,解决了机器id重复的问题,但只能用8.7年,机器id总共有420万个,应用重启一次减少一个。
63.本实施例基于redis实现的分布式id生成,使用的是雪花算法,雪花算法生成唯一的分布式id的基础是机器号workid必须是唯一的。基于redis生成唯一workid的流程如图2所示。每个应用节点启动时从redis获取workid的空闲列表,生成唯一workid,具体流程为:
64.如果空闲列表存在,则循环判断空闲列表的workid是否被占用,如果未被占用,则向redis注册,即workid作为key,应用节点的ip和端口号作为value 存到redis中(格式可以为ip:port),并设置过期时间,过期时间设置的不宜过长,设置过期时间的目的是防止应用节点宕机,workid一直被占用,导致无法回收的问题。每次获取完workid,对不用的workid进行回收,重新生成空闲列表,然后存到redis;
65.如果从redis中未取到空闲列表,则由该应用节点生成,为防止出现并发问题,对生成空闲列表的逻辑加上分布式锁,同一时间只允许一个节点生成。
66.生成workid空闲列表的逻辑如下:如果workid用10bit表示,则可以供1024 个不重复的节点使用,值为0-1023。遍历所有workid,如果redis中不存在则把该workid放入空闲列表,最后再保存到redis。
67.本实施例中应用节点定时为本节点使用的workid续期,每个应用节点启动一个定时任务,定时任务的执行间隔小于workid在redis的过期时间。这个定时任务的目的是向
redis汇报应用节点存活状态(延长redis中的过期时间)。如果应用节点存活,那么它使用的workid就不会被回收。应用节点的workid作为redis的key,value则是ip:port。延长过期时间的时候需要确认workid是不是本应用节点的ip和端口号,防止出现两个应用节点同一机器id的情况。如果redis中没有本应用节点的workid或者对应的ip和端口不是本应用节点,则向redis注册一个机器id,注册的逻辑同应用启动时分配workid的流程。
68.本实施例中监控该应用节点占用workid对应的机器列表中应用节点的个数以及对应的空闲列表中空闲workid的个数,如果应用节点的个数得到最大数的workid,通过雪花算法重新为所述空闲列表配置workid。监控已使用 workid对应的机器列表和空闲workid的情况,如果应用节点达到最大wordid 数(1024),可以考虑workid占的bit数,雪花算法默认是10bit。
69.本实施例基于redis的分布式id生成方法,能够为每个应用分配唯一的 workid,能够快速稳定生成唯一的分布式id,生成id时不依赖于数据库,完全在内存生成,高性能高可用,每秒可生成几百万id。
70.实施例2:
71.本发明的装置,包括:至少一个存储器和至少一个处理器;
72.所述至少一个存储器,用于存储机器可读程序;
73.所述至少一个处理器,用于调用所述机器可读程序,执行实施例1公开的方法。
74.实施例3:
75.本发明的介质,为计算机可读介质,该计算机可读介质上存储有计算机指令,该计算机指令在被处理器执行时,使处理器执行实施例1公开的方法。具体地,可以提供配有存储介质的系统或者装置,在该存储介质上存储着实现上述实施例中任一实施例的功能的软件程序代码,且使该系统或者装置的计算机(或cpu或mpu)读出并执行存储在存储介质中的程序代码。
76.在这种情况下,从存储介质读取的程序代码本身可实现上述实施例中任何一项实施例的功能,因此程序代码和存储程序代码的存储介质构成了本发明的一部分。
77.用于提供程序代码的存储介质实施例包括软盘、硬盘、磁光盘、光盘(如 cd-rom、cd-r、cd-rw、dvd-rom、dvd-ram、dvd-rw、dvd rw)、磁带、非易失性存储卡和rom。可选择地,可以由通信网络从服务器计算机上下载程序代码。
78.此外,应该清楚的是,不仅可以通过执行计算机所读出的程序代码,而且可以通过基于程序代码的指令使计算机上操作的操作系统等来完成部分或者全部的实际操作,从而实现上述实施例中任意一项实施例的功能。
79.此外,可以理解的是,将由存储介质读出的程序代码写到插入计算机内的扩展板中所设置的存储器中或者写到与计算机相连接的扩展单元中设置的存储器中,随后基于程序代码的指令使安装在扩展板或者扩展单元上的cpu等来执行部分和全部实际操作,从而实现上述实施例中任一实施例的功能。
80.需要说明的是,上述各流程和各系统结构图中不是所有的步骤和模块都是必须的,可以根据实际的需要忽略某些步骤或模块。各步骤的执行顺序不是固定的,可以根据需要进行调整。上述各实施例中描述的系统结构可以是物理结构,也可以是逻辑结构,即,有些模块可能由同一物理实体实现,或者,有些模块可能分由多个物理实体实现,或者,可以
由多个独立设备中的某些部件共同实现。
81.以上各实施例中,硬件单元可以通过机械方式或电气方式实现。例如,一个硬件单元可以包括永久性专用的电路或逻辑(如专门的处理器,fpga或 asic)来完成相应操作。硬件单元还可以包括可编程逻辑或电路(如通用处理器或其它可编程处理器),可以由软件进行临时的设置以完成相应操作。具体的实现方式(机械方式、或专用的永久性电路、或者临时设置的电路)可以基于成本和时间上的考虑来确定。
82.上文通过附图和优选实施例对本发明进行了详细展示和说明,然而本发明不限于这些已揭示的实施例,基与上述多个实施例本领域技术人员可以知晓,可以组合上述不同实施例中的代码审核手段得到本发明更多的实施例,这些实施例也在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。