1.本发明属于人工智能、神经网络技术领域,特别涉及一种基于脉冲神经网 络的多智能体博弈的方法。
背景技术:
2.现实社会中,存在大量复杂的动态决策问题,例如,路面交通系统,经济 预测,军事决策等。这些实际的问题对仿生型智能体的需求越来越强烈,一群 智能体是否能够在动态、不确定的环境中像人一样的工作,是解决这些问题的 关键,但当前的多智能体技术还难以应对复杂情况下的挑战。深度学习和深度 强化学习利用自身强大的信息处理能力,在多智能体博弈中表现出优势,但仍 面临着挑战,主要表现为无法进行网络的自生长和自组织,所以面对不确定性 因素时无法进行实时决策,不具备学习推理能力。
技术实现要素:
3.为了克服上述现有技术的缺点,本发明的目的在于提供一种基于脉冲神经 网络的多智能体博弈的方法,结合脉冲神经网络的仿生型特性,不仅具备学习 推理能力,还大大降低了运算需求,适用于多种环境中的多智能体博弈,可使 所述智能体能够模仿人类操作。
4.为了实现上述目的,本发明采用的技术方案是:
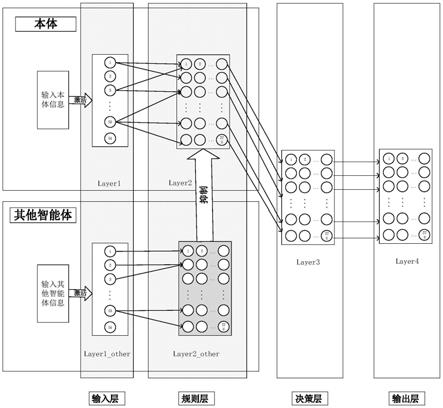
5.一种基于脉冲神经网络的多智能体博弈的方法,包括如下步骤:
6.步骤1:将环境中的多智能体区分为本体和其他智能体,本体需要学习的 内容包括本体输入以及其他智能体对本体的影响;
7.步骤2:建立除本体外的其他智能体的输入层layer1_other,对其他多智能 体的输入信息进行预处理,将输入信息转换为脉冲信号,生成并激发输入层 layer1_other神经元;
8.步骤3:建立和输入层layer1_other对应的规则层layer2_other,获得其他 智能体满足的事件规则,将所有可能发生的事件划分为基本事件即样本点,每 一个样本点对应产生规则层layer2_other的一个神经元,将所有能够激发样本 点的输入层layer1_other神经元与该样本点对应的规则层layer2_other神经元 全连接;
9.步骤4:建立本体的输入层layer1,对环境中的本体输入信息进行预处理, 将输入信息转换为脉冲信号,生成并激发该输入层神经元;
10.步骤5:建立和layer1对应的规则层layer2,获得本体满足的事件规则, 将所有可能发生的事件划分为基本事件即样本点,每一个样本点对应产生规则 层layer2的一个神经元,将所有可以激发样本点的输入层layer1神经元与该样 本点对应的规则层layer2神经元全连接;
11.步骤6:建立多智能体博弈的决策层layer3,在决策层layer3生成神经元, 决策层layer3神经元个数和规则层layer2神经元个数相等,将规则层layer2神 经元和决策层
layer3神经元一一对应,同时layer2至layer3的信息传递还必须 受到规则层layer2_other规则的约束,只有和规则层layer2_other的激发规则 一致的规则层layer2神经元才能允许输入至决策层layer3,根据决策层 layer3内神经元的激发情况生成决策层layer3的层内突触连接;
12.步骤7:建立多智能体博弈的输出层layer4,输出层layer4生成的神经元 个数和决策层layer3神经元个数相等,决策层layer3神经元和输出层layer4 神经元建立一对一的连接,通过调整决策层layer3和输出层layer4的连接权 值,得到最终的输出信号。
13.进一步地,所述步骤1具体包括以下步骤:
14.步骤1.1:确定训练对象,并将其定义为本体;
15.步骤1.2:将环境中的除本体之外的其他智能体定义为其他智能体。
16.进一步地,所述步骤2具体包括以下步骤:
17.步骤2.1:根据多智能体环境下的信息确定其他智能体的输入层信息;
18.步骤2.2:将输入信息进行数据的预处理,按照脉冲转换规则将输入信息 转换为脉冲发射时间t1,t2
……
tn;
19.步骤2.3:根据预处理后的信息确定输入层layer1_other的神经元个数,每 一个神经元对应一种预处理后的数据,在输入层layer1_other生成n个输入层 神经元;
20.步骤2.4:根据对应关系,设置输入层layer1_other神经元的脉冲发射时间 分别为t1,t2,
……
,tn,脉冲发射时间不为0的神经元即是被激发的神经元。
21.进一步地,所述步骤4具体包括以下步骤:
22.步骤4.1:根据多智能体环境下的信息确定本体的输入层信息;
23.步骤4.2:将本体输入信息进行数据的预处理,按照脉冲转换规则将信息 转换为脉冲发射时间t1,t2
……
ta;
24.步骤4.3:根据预处理后的信息确定输入层layer1的神经元个数,每一个 神经元对应一种预处理后的数据,在输入层layer1生成a个输入层神经元;
25.步骤4.4:根据对应关系,设置输入层layer1神经元的脉冲发射时间分别 为t1,t2,
……
,ta,脉冲发射时间不为0的神经元即是被激发的神经元。即, 脉冲发射时间又称脉冲激发时间。设置输入层layer_other神经元的脉冲发射时 间后,发射时间又代表神经元的激发时间,也表明对应这些神经元被激发。
26.进一步地,所述步骤2.1具体包括以下步骤:
27.步骤2.1.1:根据具体的多智能体环境,确定环境中的输入信息;
28.步骤2.2.2:在所有的输入信息中,找出对其他智能体输出结果有影响的输 入信息,即是其他智能体的输入层信息;
29.所述步骤2.2和将输入信息进行数据的预处理,具体操作是:对原始的输 入信息进行数据转换,使原始输入信息转换成适合数据处理的形式;
30.所述步骤4.1具体包括以下步骤:
31.步骤4.1.1:根据具体的多智能体环境,确定环境中的输入信息;
32.步骤4.2.2:在所有的输入信息中,找出对本体输出结果有影响的输入信息, 即是本体的输入层信息;
33.所述步骤4.2将输入信息进行数据的预处理,具体操作是:对原始的本体 输入信
息进行数据转换,使原始输入信息转换成适合数据处理的形式。
34.进一步地,所述步骤3具体包括以下步骤:
35.步骤3.1:将所有可能发生的事件划分为m个基本事件;
36.步骤3.2:在规则层layer2_other生成m个神经元,将m个基本事件分别 对应规则层layer2_other中的m个神经元;
37.步骤3.3:设置规则层layer2_other中的m个神经元与输入层layer1_other 神经元的连接关系,将所有能够激发某一基本事件的输入层layer1_other神经 元与该基本事件对应的规则层layer2_other神经元全连接,并设置权值保证规 则层layer2_other神经元的正确激发,对应不同的输入,所述权值的设置能够 保证输入层layer1_other到规则层layer2_other的正确激发。
38.进一步地,所述步骤5具体包括以下步骤:
39.步骤5.1:将所有可能发生的事件划分为m个基本事件;
40.步骤5.2:在规则层layer2中生成m个神经元,将m个基本事件分别对应 规则层layer2中的m个神经元;
41.步骤5.3:设置规则层layer2中的m个神经元与本体输入层layer1神经元 的连接关系,将所有能够激发某一基本事件的输入层layer1神经元与该基本事 件对应的规则层layer2神经元全连接,并设置权值保证规则层layer2神经元 的正确激发,对应不同的输入,所述权值的设置能够保证输入层layer1到规则 层layer2的正确激发;
42.其中,步骤3和步骤5中的m取值相同。
43.进一步地,所述步骤3.3和步骤步骤5.3中,权值设置满足以下三个权值调 整规则:a)以一个规则层layer2_other神经元为基本规则进行权值调试,将基 本规则记为神经元a;b)保证与神经元a有连接关系的所有输入层 layer1_other神经元能够激发神经元a,且不会对规则层layer2_other的其他神 经元造成激发;c)保证与神经元a有连接关系的输入层layer1_other的每一 个神经元都不能够单独激发神经元a。
44.进一步地,所述步骤6具体包括以下步骤:
45.步骤6.1:在决策层layer3生成m个神经元;
46.步骤6.2:将规则层layer2神经元和决策层layer3神经元一对一连接;
47.步骤6.3:信息由规则层layer2传输至决策层layer3受到其他智能体规则 的限制;
48.步骤6.4:根据hebb规则以及决策层layer3神经元的所处的空间位置建 立层内连接。
49.进一步地,所述决策层layer3设置为二维分布;所述步骤6.4中,hebb 规则为:当两个独立神经元激发时间差值小于阈值时,两个神经元会建立连接; 在hebb规则基础上加上空间位置的限制:只有两个空间距离小于某一距离阈 值的时候,hebb才有效;从而在时间和空间的连接规则下,形成决策层的层 内连接。
50.进一步地,所述步骤7具体包括以下步骤:
51.步骤7.1:在输出层layer4生成m个神经元;
52.步骤7.2:将决策层layer3神经元和输出层layer4神经元一对一连接;
53.步骤7.3:根据stdp规则调整决策层layer3至输出层layer4的连接权值;
54.步骤7.4:取输出层layer4最先激发的神经元作为最终的输出结果。
55.进一步地,所述步骤7.3中的stdp规则为:通过调整引导神经元的激发 时间间接调整目标权值,将引导神经元的激活时间记为t3,将突触前端神经元 记为npre,激活时间记为t1;突触后端神经元记为npost,激活时间记为t2, 调整引导神经元的激活时间t3,改变神经元npost的激活时间t2,突触权值的 变化幅度与突触连接前后神经元激活时间差有关,权值和时间关系如公式1和 公式2所示:
56.δt=t
2-t1ꢀꢀ
公式1
57.。
[0058][0059]
与现有技术相比,本发明的有益效果是:
[0060]
1)、本发明的小样本学习能力突出,不涉及大量的数据运算,节约了算 力和时间。
[0061]
2)、本发明智能化程度高,是依据仿生学特性提出的多智能体博弈,具 有动态学习和联想推理能力,通过训练可模仿人类操作。
[0062]
3)、本发明设计的结构对环境中的多智能体博弈具有通用性。
附图说明
[0063]
图1是本发明整体框图。
[0064]
图2是stdp规则示意图
[0065]
图3是实施例1中输入层和规则层的连接示意图。
具体实施方式
[0066]
下面结合附图和实施例详细说明本发明的实施方式。
[0067]
参考图1,本发明一种基于脉冲神经网络的多智能体博弈的方法,包括如 下步骤:
[0068]
步骤1:将环境中的多智能体区分为本体和其他智能体,本体需要学习的 内容包括本体输入以及其他智能体对本体的影响。具体包括以下步骤:
[0069]
步骤1.1:确定训练对象,并将其定义为本体;
[0070]
步骤1.2:将环境中的除本体之外的其他智能体定义为其他智能体。
[0071]
步骤2:建立除本体外的其他智能体的输入层layer1_other(每一个智能体 均需构建一个layer1_other网络,例如,其他多智能体包含4个智能体,则按 照步骤2生成4个layer_other层),对其他多智能体的输入信息进行预处理, 将输入信息转换为脉冲信号,生成并激发输入层layer1_other神经元。具体包 括以下步骤:
[0072]
步骤2.1:根据多智能体环境下的信息确定其他智能体的输入层信息;
[0073]
步骤2.1.1:根据具体的多智能体环境,确定环境中的输入信息;
[0074]
步骤2.2.2:在所有的输入信息中,找出对其他智能体输出结果有影响的输 入信息,即是其他智能体的输入层信息;
[0075]
步骤2.2:将输入信息进行数据的预处理,按照脉冲转换规则将输入信息 转换为脉冲发射时间t1,t2
……
tn,其中预处理的具体操作是:对原始的输入 信息进行数据转换,使原始输入信息转换成适合数据处理的形式;其中支持数 据转换的策略有:特征构造、规
范化、离散化等多种策略,具体场景具体分析;
[0076]
步骤2.3:根据预处理后的信息确定输入层layer1_other的神经元个数,每 一个神经元对应一种预处理后的数据,在输入层layer1_other生成n个输入层 神经元;
[0077]
步骤2.4:根据对应关系,设置输入层layer1_other神经元的脉冲发射时间 分别为t1,t2,
……
,tn,脉冲发射时间不为0的神经元即是被激发的神经元。
[0078]
步骤3:建立和输入层layer1_other对应的规则层layer2_other,获得其他 智能体满足的事件规则,将所有可能发生的事件划分为基本事件即样本点,每 一个样本点对应产生规则层layer2_other的一个神经元,将所有能够激发样本 点的输入层layer1_other神经元与该样本点对应的规则层layer2_other神经元 全连接。具体包括以下步骤:
[0079]
步骤3.1:将所有可能发生的事件划分为m个基本事件;
[0080]
步骤3.2:在规则层layer2_other生成m个神经元,将m个基本事件分别 对应规则层layer2_other中的m个神经元;
[0081]
步骤3.3:设置规则层layer2_other中的m个神经元与输入层layer1_other 神经元的连接关系,将所有能够激发某一基本事件的输入层layer1_other神经 元与该基本事件对应的规则层layer2_other神经元全连接,并设置权值保证规 则层layer2_other神经元的正确激发,对应不同的输入(事件),所述权值的 设置能够保证输入层layer1_other到规则层layer2_other的正确激发,即满足 以下三个权值调整规则:a)以一个规则层layer2_other神经元为基本规则进行 权值调试,将基本规则记为神经元a;b)保证与神经元a有连接关系的所有 输入层layer1_other神经元能够激发神经元a,且不会对规则层layer2_other 的其他神经元造成激发;c)保证与神经元a有连接关系的输入层layer1_other 的每一个神经元都不能够单独激发神经元a。
[0082]
步骤4:建立本体的输入层layer1,对环境中的本体输入信息进行预处理, 将输入信息转换为脉冲信号,生成并激发该输入层神经元。具体包括以下步骤:
[0083]
步骤4.1:根据多智能体环境下的信息确定本体的输入层信息;
[0084]
步骤4.1.1:根据具体的多智能体环境,确定环境中的输入信息;
[0085]
步骤4.2.2:在所有的输入信息中,找出对本体输出结果有影响的输入信息, 即是本体的输入层信息;
[0086]
步骤4.2:将本体输入信息进行数据的预处理,按照脉冲转换规则将信息 转换为脉冲发射时间t1,t2
……
ta,其中预处理的具体操作是:对原始的本体 输入信息进行数据转换,使原始输入信息转换成适合数据处理的形式。同样地, 支持数据转换的策略有:特征构造、规范化、离散化等多种策略,具体场景具 体分析;
[0087]
步骤4.3:根据预处理后的信息确定输入层layer1的神经元个数,每一个 神经元对应一种预处理后的数据,在输入层layer1生成a个输入层神经元;
[0088]
步骤4.4:根据对应关系,设置输入层layer1神经元的脉冲发射时间分别 为t1,t2,
……
,ta,脉冲发射时间不为0的神经元即是被激发的神经元。即, 脉冲发射时间又称脉冲激发时间。设置输入层layer_other神经元的脉冲发射时 间后,发射时间又代表神经元的激发时间,也表明对应这些神经元被激发。
[0089]
步骤5:建立和layer1对应的规则层layer2,获得本体满足的事件规则, 将所有可能发生的事件划分为基本事件即样本点,每一个样本点对应产生规则 层layer2的一个神
经元,将所有可以激发样本点的输入层layer1神经元与该样 本点对应的规则层layer2神经元全连接。具体包括以下步骤:
[0090]
步骤5.1:将所有可能发生的事件划分为m个基本事件;
[0091]
步骤5.2:在规则层layer2中生成m个神经元,将m个基本事件分别对应 规则层layer2中的m个神经元;
[0092]
步骤5.3:设置规则层layer2中的m个神经元与本体输入层layer1神经元 的连接关系,将所有能够激发某一基本事件的输入层layer1神经元与该基本事 件对应的规则层layer2神经元全连接,并设置权值保证规则层layer2神经元 的正确激发,对应不同的输入,所述权值的设置能够保证输入层layer1到规则 层layer2的正确激发,具体要求参考步骤3.3。
[0093]
步骤6:建立多智能体博弈的决策层layer3,在决策层layer3生成神经元, 决策层layer3神经元个数和规则层layer2神经元个数相等,将规则层layer2神 经元和决策层layer3神经元一一对应,同时layer2至layer3的信息传递还必须 受到规则层layer2_other规则的约束,只有和规则层layer2_other的激发规则 一致的规则层layer2神经元才能允许输入至决策层layer3,根据决策层 layer3内神经元的激发情况生成决策层layer3的层内突触连接。具体包括以下 步骤:
[0094]
步骤6.1:在决策层layer3生成m个神经元,为了体现空间信息对决策的 作用,同时简化决策的复杂度,该层设置为二维分布;
[0095]
步骤6.2:将规则层layer2神经元和决策层layer3神经元一对一连接;
[0096]
步骤6.3:信息由规则层layer2传输至决策层layer3受到其他智能体规则 的限制;具体表现为:假设此环境中激发的其他智能体规则有rule1、rule2
……ꢀ
等规则神经元,那么只有和rule1、rule2
……
等规则保持一致的本体规则层神经 元才允许被传输至决策层。
[0097]
步骤6.4:根据hebb规则以及决策层layer3神经元的所处的空间位置建 立层内连接,hebb规则为:当两个独立神经元激发时间差值小于阈值时,两 个神经元会建立连接;在hebb规则基础上加上空间位置的限制:只有两个空 间距离小于某一距离阈值的时候,hebb才有效;从而在时间和空间的连接规 则下,形成决策层的层内连接。以n1,n2为例进行说明,n1,n2代表两个 神经元。根据神经元的连接状态,激活状态的及神经元空间位置,可建立n1, n2的连接关系。如表1所示。
[0098]
表1
[0099][0100]
步骤7:建立多智能体博弈的输出层layer4,输出层layer4生成的神经元 个数和决策层layer3神经元个数相等,决策层layer3神经元和输出层layer4 神经元建立一对一的连接,通过调整决策层layer3和输出层layer4的连接权 值,得到最终的输出信号。具体包括以下步骤:
[0101]
步骤7.1:在输出层layer4生成m个神经元;
[0102]
步骤7.2:将决策层layer3神经元和输出层layer4神经元一对一连接;
[0103]
步骤7.3:根据stdp规则调整决策层layer3至输出层layer4的连接权值, stdp规则为:通过调整引导神经元的激发时间间接调整目标权值,如图2所 示,将“引导”神经元的激活时间记为t3,将突触前端神经元记为npre,激活时 间记为t1;突触后端神经元记为npost,激活时间记为t2。调整“引导”神经元 的激活时间t3,可以改变“npost”神经元的激活时间t2,突触权值的变化幅度与 突触连接前后神经元激活时间差有关,权值和时间关系如公式1和公式2所示:
[0104]
δt=t
2-t1ꢀꢀ
公式1
[0105]
。
[0106][0107]
步骤7.4:取输出层layer4最先激发的神经元作为最终的输出结果。
[0108]
本发明中,智能体博弈指的是智能体与智能体之间的交流对抗过程,例如 卡牌游戏、即时战略游戏等三方或者以上玩家参与的游戏或者战略,都属于多 智能体博弈。其原理是通过学习人类在应用(比如游戏、自动驾驶、武器突防 等)当中的数据样本,达到训练数据的效果,从而使这个智能体能够模仿人类 应用的操作。博弈的水平全部由智能体从人类样本学习模仿而来。
[0109]
以下是本发明的在棋牌游戏中的两个具体应用实施例。
[0110]
实施例1
[0111]
以基于脉冲神经网络的在非完美信息条件下多智能体博弈——斗地主出牌 为例,具体说明本发明的步骤与效果。
[0112]
在该例中,共有三名玩家,用一副牌(共54张)进行博弈的游戏。在一 局游戏中分为两方,一个玩家是“地主”,为一方,剩余两个玩家为农民,为另 一方。游戏规定率先出完所有手中卡牌的一方获胜。玩家出牌时,所出的牌必 须是玩家拥有的手牌,且必须和上家出牌的牌型规则保持一致,牌值大小大于 上家。
[0113]
一轮游戏中,根据学习的对象,将要训练的一个玩家视为本体,剩余两个 玩家视为其他智能体。
[0114]
斗地主游戏共计54张牌,每一个神经元对应一种牌,所以设定输入层 (layer1_other)神经元个数54个。输入其他智能体的出牌信息,并对所出的 卡牌进行数据处理,按照脉冲转换规则将每一种牌转换为所对应的脉冲发射时 间,在获取其他智能体的出牌信息后,在神经网络的输入层找到对应的神经元, 并设置其脉冲发射时间。
[0115]
根据斗地主出牌过程中所有可能的斗地主规则:单张、双王、炸弹、对子、 三张、三带一、三带二、四带一、四带二、三连对、四连对、五连对、六连对、 七连对、八连对、九连对、十连对、五张顺子、六张顺子、七张顺子、八张顺 子、九张顺子、十张顺子、十一张顺子、十二张顺子、二连飞机、飞机带翅膀、 三连飞机、飞机带两对、四连飞机、三连飞机带翅膀、五连飞机、三连飞机带 三对、四连飞机带翅膀、六连飞机、四连飞机带四对、五连飞机带翅膀,划分 为276个基本事件。在其他智能体的规则层(layer2_other)生成276个神经元, 分别对应276种斗地主规则。将layer2_other中的276个神经元分别与 layer1_other神经元连接,并设置合适权值。以三连对334455为例,需要将 layer1_other中代表33,44,55的神经元与layer2_other中代表334455神经元 全连接。连接关系如图3,并设置权值为400,保证神经元的正确激发,只有 输入层代表33,44,55的神经元全部被激发的时候,代表334455的规则层神 经元才会被激发,且不会造成规则层的其他神经元被激发。
[0116]
然后是本体的信息处理,与其他智能体的输入层处理一致,设定本体输入 层神经元个数为54,每一个神经元对应一种牌。输入本体的出牌信息,并对所 出的卡牌进行数据处理,按照脉冲转换规则将每一种牌转换为所对应的脉冲发 射时间,在获取玩家手牌信息后,在神经网络的输入层找到对应的神经元,并 设置其脉冲发射时间。
[0117]
根据斗地主出牌过程中所有可能的斗地主规则,在本体的规则层(layer2) 生成276个神经元,分别对应276种斗地主规则。将layer2中的276个神经元 分别与layer1神经元连接,并设置合适权值。权值设置方法和其他智能体规则 层权值设置方法相同。
[0118]
在决策层中生成276个神经元,并以二维空间分布。神经元在空间位置分 布上按照从优先级分布,优先级是对斗地主规则牌型大小的排序等级。将 layer2中的神经元和layer3中的神经元采用one-to-one的形式连接并设置权值, 并且加入在layer2至layer3的突触连接中加入使能信号,当使能信号为1时, 突触连接有效,信息才能由layer2传递至layer3,保证layer2到layer3的正确 激发。假设此环境中激发的其他智能体规则有rule1、rule2
……
等规则神经元, 那么只有和rule1、rule2
……
等规则保持一致的本体规则层的突触使能信号才为 1,否则为0。再根据hebb规则形成决策层的内部突触连接:当两个独立神经 元激发时间差值小于阈值时,两个神经元会建立连接。在hebb基础上在加上 空间的
限制:只有两个空间距离小于某一距离阈值的时候,hebb才有效。在 时间和空间的连接规则下,形成了layer3的层内连接。
[0119]
在输出层中生成276个神经元,决策层神经元与输出层神经元采用一对一 的连接关系,设置初始的连接权值为0,利用监督性stdp规则调整连接权值。 取输出层最先激发的神经元作为最终的输出结果。
[0120]
其中决策层至输出层权值调整步骤如表2:
[0121]
表2
[0122][0123][0124]
实施例2
[0125]
以基于脉冲神经网络的在非完美信息条件下多智能体博弈——德州扑克为 例,具体说明本发明的步骤与效果。
[0126]
在该例中,共有2-10名玩家,用一副去掉大小王后的52张牌进行博弈的 游戏。牌局开始时,会给每位玩家发2张“底牌”(只有个人看到),桌面上 分三次陆续发出3张,1张,1张的公共牌,在经过四轮的跟注,加注,弃牌等 押注圈操作后,进入摊牌阶段,在自己的2张底牌和5张公共牌中挑选出最大 的5张组合,按照牌型大小规则分出胜负,赢家拿下所有筹码。
[0127]
一轮游戏中,根据学习的对象,将要训练的一个玩家视为本体,剩余其他 玩家视为其他智能体。
[0128]
德州扑克游戏共计52张牌,每一个神经元对应一种牌,所以设定输入层 (layer1_
other)神经元个数52个。输入其他智能体的出牌信息,并对所出的 卡牌进行数据处理,按照脉冲转换规则将每一种牌转换为所对应的脉冲发射时 间,在获取其他智能体的出牌信息后,在神经网络的输入层找到对应的神经元, 并设置其脉冲发射时间。
[0129]
根据德州扑克游戏过程中所有可能的规则:皇家同花顺,同花顺,四条, 葫芦,同花,顺子,三条,两对,一对,高牌,划分为1326个基本事件。在 其他智能体的规则层(layer2_other)生成1326个神经元,分别对应1326种德 州扑克规则。将layer2_other中的1326个神经元分别与layer1_other神经元连 接,并设置合适权值。以同花顺为例,需要5张同花色的连续牌,例如黑桃 45678的组合就是同花顺,需要将layer1_other中代表黑桃4,5,6,7,8的 神经元与layer2_other中代表黑桃45678(一种同花顺)的神经元全连接,并 设置连接权值为400,保证神经元的正确激发,只有输入层代表黑桃4,5,6, 7,8的神经元全部被激发的时候,代表黑桃45678(一种同花顺)的规则层神 经元才会被激发,且不会造成规则层的其他神经元被激发。
[0130]
然后是本体的信息处理,与其他智能体的输入层处理一致,设定本体输入 层神经元个数为54,每一个神经元对应一种牌。输入本体的出牌信息,并对所 出的卡牌进行数据处理,按照脉冲转换规则将每一种牌转换为所对应的脉冲发 射时间,在获取玩家手牌信息后,在神经网络的输入层找到对应的神经元,并 设置其脉冲发射时间。
[0131]
根据德州扑克出牌过程中所有可能的德州扑克规则,在本体的规则层 (layer2)生成1326个神经元,分别对应1326种德州扑克规则。将layer2中 的1326个神经元分别与layer1神经元连接,并设置合适权值。权值设置方法 和其他智能体规则层权值设置方法相同。
[0132]
在决策层中生成1326个神经元,并以二维空间分布。神经元在空间位置 分布上按照从优先级分布,优先级是对德州扑克规则牌型大小的排序等级。将 layer2中的神经元和layer3中的神经元采用one-to-one的形式连接并设置权值, 并且加入在layer2至layer3的突触连接中加入使能信号,当使能信号为1时, 突触连接有效,信息才能由layer2传递至layer3,保证layer2到layer3的正确 激发。假设此环境中激发的其他智能体规则有rule1、rule2
……
等规则神经元, 那么只有规则大于rule1、rule2
……
等规则的本体规则层的突触使能信号才为1, 否则为0。再根据hebb规则形成决策层的内部突触连接:当两个独立神经元 激发时间差值小于阈值时,两个神经元会建立连接。在hebb基础上在加上空 间的限制:只有两个空间距离小于某一距离阈值的时候,hebb才有效。在时 间和空间的连接规则下,形成了layer3的层内连接。
[0133]
在输出层中生成1326个神经元,决策层神经元与输出层神经元采用一对 一的连接关系,设置初始的连接权值为0,利用监督性stdp规则调整连接权 值。取输出层最先激发的神经元作为最终的输出结果。
[0134]
其中决策层至输出层权值调整步骤如表3:
[0135]
表3
[0136][0137][0138]
本发明还可应用到仿人眼认知中,例如行人、其他车辆与自己车辆的路面 博弈,实现自动驾驶等智慧交通技术。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。