1.本发明属于大数据异常检测技术领域,特别是一种基于机器学习的风电场站运行数据异常识别方法。
背景技术:
2.风电场站的数据量庞大、数据种类较多,涵盖风电场生产的方方面面,接入工作比较繁琐且精细化要求高,数据在储存、处理、传输等过程中面临各种各样的风险。随之而来对场站的管控和监控的要求也越来越严峻,不可避免地含有缺失、重复、漏数、错数等各类问题,给风电场站的安全生产和调度精细化管理带来了新的挑战。同时随着电力交易的改革,新能源跨省跨区现货交易的开展,以及省内新能源新货交易的推进,对新能源的实时性、准确性都提出了更高的要求。
3.风电场站的运行数据主要包括场站的气象预报数据、功率预测数据、理论功率数据、可用功率数据。风场场站数据的质量直接影响新能源场站的功率预测精度,并对电网的运行调度计划和新能源最大消纳能力产生重要影响。
4.目前,针对风电场站大数据异常识别的研究较少。文献《风电场输出功率异常数据识别与重构方法研究》(朱倩文等,电力系统保护与控制,2015)采用四分位算法的数学模型对风电场输出功率异常数据进行识别,并采用基于临近风电场出力模型和三次样条插值的方法去重构缺失的数据。同时,针对风电场的弃风异常数据簇,文献《风电场弃风异常数据簇的特征及处理方法》(赵永宁等,电力系统自动化,2014)提出一种四分位和聚类分析的异常数据组合筛选模型,利用四分位法剔除常规的分散性异常数据,再使用k-means聚类算法剔除堆积型数据集,但k-means聚类算法需要提前确定聚类个数k。此外,文献《风电场有功功率异常运行数据重构方法》(张东英等,电力系统自动化,2014)采用分段判定的方法识别风电场有功功率异常运行数据,并利用风电场之间的出力数据的延时相关性还原重构缺失性数据;对于风电自身出力数据,采用基于自回归滑动平均模型重构完整的时间序列。然而,针对以上方法,仅是从数理统计和无监督聚类算法的角度对风电场站的异常运行数据进行识别。
5.因此,考虑以上研究方法的缺点和有监督机器学习算法的快速发展,为了进一步提高提高风电场站运行数据异常识别的准确性、快速性和通用性,如何对大规模风电场站运行数据的异常识别算法进行优化,成为当前研究的关键问题。
技术实现要素:
6.鉴于上述问题,本发明提供一种至少解决上述部分技术问题的一种基于机器学习的风电场站运行数据异常识别方法,该方法能够对大规模风电场站运行数据的异常识别算法进行优化,提高提高风电场站运行数据异常识别的准确性、快速性和通用性。。
7.本发明实施例提供了一种基于机器学习的风电场站运行数据异常识别方法,包括:
8.s1、收集风电场站的历史风速数据和对应的功率运行数据;
9.s2、确定所述历史风速数据和对应的功率运行数据中的正常运行数据和异常运行数据;
10.s3、构建深度学习算法模型,将分别带有相应标签的正常运行数据和异常运行数据,对所述深度学习算法模型进行学习、训练和测试,获得最优模型;
11.s4、将待识别风电场站的风速数据和对应的功率运行数据,通过所述最优模型,输出异常运行数据的识别结果。
12.进一步地,所述s2中的异常运行数据,包括:
13.普通异常数据点、离散型异常数据点和堆积型异常数据点。
14.进一步地,所述s2具体包括:
15.s21、根据物理机理识别所述普通异常数据点;
16.s22、采用横纵四分位法识别所述离散型异常数据点;
17.s23、采用近邻传播聚类算法识别所述堆积型异常数据点。
18.进一步地,所述s21具体包括:
19.所述历史风速数据和对应的功率运行数据中,如果在任一时刻下满足预设条件,则为所述普通异常数据点:
20.所述预设条件包括以下一种或多种:
21.(1)当所述历史风速数据和对应的功率运行数据中,任意一个小于或等于0;
22.(2)所述历史风速数据和对应的功率运行数据中,当所述历史风速数据小于切入风速且所述功率运行数据大于0;
23.(3)所述历史风速数据和对应的功率运行数据中,当所述历史风速数据大于切出风速且所述功率运行数据大于0;
24.(4)所述历史风速数据和对应的功率运行数据中,当所述功率运行数据大于1.2倍的额定功率。
25.进一步地,所述s22具体包括:
26.对历史风速数据进行等间隔划分,获得多个区间的历史风速数据;采用四分位算法依次对每个区间内所述历史风速数据对应的功率运行数据的离散型异常数据点进行识别;
27.对功率运行数据进行等间隔划分,获得多个区间的功率运行数据;采用四分位算法依次对每个区间内所述功率运行数据对应的风速数据的离散型异常数据点进行识别。
28.进一步地,所述s23具体包括:
29.将所述历史风速数据和对应的功率运行数据作为潜在的聚类中心,根据不同时刻下所述历史风速数据和对应的功率运行数据的相似度,构建相似度矩阵;
30.采用近邻传播聚类算法对所述相似度矩阵进行迭代计算,实现对历史风速数据和对应的功率运行数据的聚类,基于此识别所述堆积型异常数据点。
31.与现有技术人相比,本发明记载的一种基于机器学习的风电场站运行数据异常识别方法,具有如下有益效果:
32.采用基于物理机理、横纵四分位法和近邻传播聚类的联合方法,可以识别出部分风电场站的正常运行数据和异常运行数据。在此基础上,对正常数据和异常数据点进行打
标签,可以将运行数据异常识别问题转化为二分类问题。进一步,利用深度学习算法学习以上场站数据的分布规律和故障特征,利用完成训练的深度学习算法模型去识别风电场站实际运行数据中的异常数据,可以加快异常数据识别速度和精度,实现新能源场站发电功率的精准预测和电网调度中心辅助决策优化。
33.本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明书、权利要求书、以及附图中所特别指出的结构来实现和获得。
34.下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
35.附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
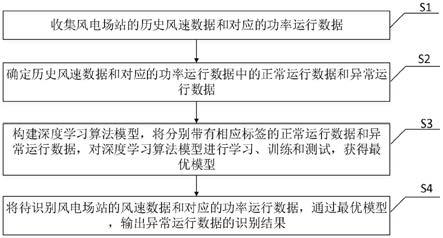
36.图1为本发明实施例提供的一种基于机器学习的风电场站运行数据异常识别方法流程图。
37.图2为本发明实施例提供的基于物理机理识别普通异常数据点结果图。
38.图3为本发明实施例提供的四分位法的示意图
39.图4为本发明实施例提供的纵四分位法识别异常运行数据流程图。
40.图5为本发明实施例提供的纵四分位法识别异常运行数据结果图
41.图6为本发明实施例提供的横四分位法识别异常运行数据结果图
42.图7为本发明实施例提供的基于联合横纵四分位法异常识别结果图。
43.图8为本发明实施例提供的基于深度学习算法模型的风电场站异常运行数据识别原理图。
具体实施方式
44.下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。
45.参见图1所示,本发明实施例提供了一种基于机器学习的风电场站运行数据异常识别方法,具体包括如下步骤:
46.s1、收集风电场站的历史风速数据和对应的功率运行数据;
47.s2、确定历史风速数据和对应的功率运行数据中的正常运行数据和异常运行数据;
48.s3、构建深度学习算法模型,将分别带有相应标签的正常运行数据和异常运行数据,对深度学习算法模型进行学习、训练和测试,获得最优模型;
49.s4、将待识别风电场站的风速数据和对应的功率运行数据,通过最优模型,输出异常运行数据的识别结果。
50.下面分别对上述各个步骤进行详细的说明。
51.在上述步骤s1中风电场站的年历史运行大数据主要包括气象数据和功率数据,功
率数据包含可用功率、理论功率和实际调度功率;在本发明实施例中,主要以风速和功率运行数据为例展开论述。
52.在上述步骤s2中,历史风速数据和对应的功率运行数据中的异常数据点,包括普通异常数据点、离散型异常数据点和堆积型异常数据点;本实施例中,根据物理机理识别普通异常数据点;采用横纵四分位法识别离散型异常数据点;采用近邻传播聚类算法识别堆积型异常数据点;接下来针对这三种识别异常数据点的方法进行详细说明:
53.根据物理机理识别普通异常数据点,该步骤即对历史风速数据和对应的功率运行数据进行预处理,具体方法如下:在历史风速数据和对应的功率运行数据中,如果在任一时刻下满足:风速和有功功率二者中,任意一个小于或等于0;或,风速小于切入风速,同时有功功率大于0;或,风速大于切出风速,同时功率大于0;或,实际运行功率大于1.2倍的额定功率;则该时刻下的历史风速数据和对应的功率运行数据为普通异常数据点,通过该方法可以识别部分异常数据点,有效地对风电场站历史运行的历史风速数据和对应的功率运行数据进行预处理;识别效果如图2所示,最下方圆圈和右方部分零散圆圈为异常数据点;主要剔除风速大于0但输出功率为零和超出切出风速对应的功率点,可以有效地对风电场站大数据进行预处理。
54.采用横纵四分位法识别离散型异常数据点,即利用横纵四分位法对风电场站的风速和功率数据进行分散点去除,四分位法不需要考虑风电场站数据集的分布特征,而是将待处理的数据按照升序排列并平均分为4份,处于分割点位置的三个数值即为四分位数,第一四分位(q1)为样本中所有数据升序排列后前25%的数据,第二个四分位数(q2)为样本中所有数据升序排列后中间50%的数据,第三个四分位数(q3)为样本中所有数据升序排列后的最后25%的数据。四分位法的原理如图3所示的箱型示意图,四分位距(interquartile range,iqr)为q3和q1之差,将iqr 1.5q3和iqr-1.5q1之外的数据识别为异常数据。由于风速和功率的分布范围较广,不适合直接使用四分位法对风电场站数据进行异常数据识别,因此需要从风速和功率两个角度分别对风速与风电功率形成的数据簇进行四分位处理,具体步骤如下:
55.(1)纵四分位法
56.对风速运行数据进行等间隔划分,在本实施例中将风速运行数据按照0.5m/s分段,获得多个区间的风速运行数据;采用四分位算法依次对每个区间内风速运行数据对应的功率运行数据的离散型异常数据点进行识别;该风电功率数据的异常识别流程如图4所示,首先输入某个风电场站的风速和风电功率数据;接着以0.5m/s为间隔将整个风电场站的风速区间分成h个子区间,可以获得各个风速子区间下所对应的待处理风电功率数据;然后将第i个区间的风电功率按顺序排列,再计算每个区间风电功率序列pi的四分位数q
i,1
,q
i,3
和四分位距iqri,计算四分位法有效下限f
i,1
和上限f
i,u
,将内限[f
i,1
,f
i,u
]之外的风电功率数据识别为异常点;依次循环,直至i》=h,输出整个风电场站功率数据异常值。图5是基于纵四分位法的异常数据识别结果,图中左上和右下圆圈点是被识别为异常的数据点,纵四分位法主要识别了左上方和右下方的异常功率点,而左下方和右上方的异常数据点未能进行有效识别。按照流程图4,对m个风电场站依次执行纵四分位法来识别风电功率数据的异常值。
[0057]
(2)横四分位法
[0058]
对功率运行数据进行等间隔划分,在本实施例中将功率运行数据按照5mw分段,获得多个区间的功率运行数据;采用四分位算法依次对每个区间内功率运行数据对应的风速运行数据的离散型异常数据点进行识别;该风速数据的异常值识别过程参考上述纵四分位法,首先输入某个风电场站的风速和风电功率数据;接着以5mw为间隔将整个风电场站的风电功率区间分成k个子区间,可以获得各个风电功率子区间下所对应的待处理风速数据;然后将第j个区间的风速按顺序排列,再计算每个区间风速序列vj的四分位数q
j,1
,q
j,3
和四分位距iqrj,计算四分位法的有效下限f
j,1
和上限f
j,u
,将内限[f
i,1
,f
j,u
]之外的风速数据识别为异常点;依次循环,直至j》=k,输出整个风电场站功率数据异常值。横四分位法对风电场站异常识别的结果如图6所示,左、右部分圆圈点为横四分位对风电场站数据异常识别的结果,其可以识别风速与功率散点图左侧和右下方的大部分异常数据点,但在散点图右上方不少零散型和堆积型异常点。按照流程图4,对k个风电场站依次执行横四分位法来识别风电功率数据的异常值。
[0059]
3)联合应用横纵四分位识别异常数据
[0060]
考虑纵四分位法和横四分位法的优势和缺点不同,联合使用横纵四分位法对风电场站的风速与功率数据异常识别结果如图7所示,左下圆圈点和右边部分零散圆圈点为正常数据点,剩余其他颜色的圆圈点为异常数据点。由此可见,横纵四分位识别出大部分异常数据点,但散点图的右上方还存在不少的堆积型异常数据点。
[0061]
采用近邻传播聚类算法识别堆积型异常数据点:在上述两种对风电场站数据异常识别的基础上,利用无需事先设定聚类个数的近邻传播聚类算法对风速和功率数据进行堆积型数据簇异常识别;该算法不需要指定聚类数目,而是将所有数据对象作为潜在的聚类中心,聚类依据数据对象之间的相似度,相似度组成相似矩阵s,近邻聚类算法通过对该矩阵进行自动迭代计算实现对数据对象的聚类。该算法的实现步骤如下:
[0062]
1)先计算数据对象之间的相似度,得到相似矩阵s;
[0063]
2)不断迭代r(i,k)和a(i,k),r(i,k)描述了数据对象k适合作为对象i的聚类中心的程度,a(i,k)描述了数据对象i选择数据对象k作为其聚类中心的适合程度。若r(i,k)和a(i,k)越大,则k成为聚类中心的可能性越大。
[0064]
3)根据聚类中心划分数据对象;对数据进行聚类只是异常数据识别中的一个步骤,其用于寻找堆积型异常数据点。
[0065]
在上述步骤s3中,对风电场站历史大数据中的正常运行数据和异常运行数据打标签。若该点是正常运行数据点,则给其打标签1。若该点是异常运行数据点,则给其打标签0。在给整个风电场站历史大数据打完标签后,无监督的数据异常识别问题就可以转换为有监督的二分类问题;
[0066]
将历史风速数据和对应的功率运行数据作为输入;将带有标签的正常运行数据和异常运行数据作为输出;如图8所示,基于此,使深度学习算法模型学习风电场站运行数据的分布规律和故障特征,根据深度学习算法模型的识别结果和历史运行数据真实类型之间的偏差平方和,利用梯度下降算法来优化模型中的权值和阈值参数,直至满足偏差平方和要求;从历史风速数据和对应的功率运行数据中随机选取出一部分数据,对深度学习算法模型进行训练,在本实施例中对随机提取的带0/1标签的风电场站80%的历史运行数据进行学习训练,根据深度学习算法模型的识别结果和历史运行数据真实类型之间的偏差来优
化模型中的反向传播参数;再利用剩余20%的历史风速数据和对应的功率运行数据对深度学习算法模型进行测试,验证深度学习算法模型识别异常数据的有效性,并进一步优化模型参数。
[0067]
在上述步骤s4中,利用完成训练的深度学习算法模型去识别风电场站实际运行中的异常数据。
[0068]
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
