1.本发明属于数据库技术领域,尤其涉及一种数据库服务端运行状态的检测方法及检测装置。
背景技术:
2.随着信息社会的不断发展,越来越多的用户通过网络来获取想要的数据。一般地,不同的数据存储于对应的数据库服务端中,用户则通过客户端来访问数据库服务端以获取数据。数据存储于数据库服务端内,不仅便于对数据的管理,也便于用户针对性地获取想要的数据,提高了对数据的获取速度与准确度,为用户提供了较好的数据获取体验。
3.可以理解,数据库服务端与客户端之间的任一者的运行状态出现异常,都会影响用户对数据的获取。
4.现有技术中,一般在后台检测到数据库服务端或客户端之间出现运行状态异常后,依靠运维人员进一步地确定具体的异常原因,或直到用户向后台反馈运行状态出现异常后,才通知运维人员对数据库服务端或客户端进行维护。以上方式都无法及时、有效地判定数据库服务端和客户端的运行状态异常以及异常原因,导致运维人员无法及时、有效地得到异常反馈,更是无法及时、准确地确定异常原因以进行维护,不但影响数据库服务端与客户端之间的正常交互,也导致用户的体验感较差。
技术实现要素:
5.本发明实施例提供一种数据库服务端运行状态的检测方法及检测装置,旨在解决针对数据库服务端与客户端之间的数据交互,缺乏有效的检测机制来检测数据库服务端的运行状态异常,无法及时、有效地确定数据库服务端的运行状态发生异常的问题。
6.本发明是这样实现的,一种数据库服务端运行状态的检测方法,所述数据库服务端与客户端通信连接,所述检测方法包括:
7.持续性地获取所述数据库服务端在至少一个预设时间间隔内相对所述客户端的至少一个第一响应时间;
8.对至少一个所述第一响应时间做数据处理,得到所述数据库服务端在每个所述预设时间间隔内的第一平均响应时间、与由至少一个所述预设时间间隔组成的预设时间段的第二平均响应时间;
9.对所述第二平均响应时间与至少一个所述第一平均响应时间做数据处理,得到第一平均响应时间判断值与第二平均响应时间阈值;
10.判断所述第一平均响应时间判断值是否大于所述第二平均响应时间阈值;
11.若是,则判定所述数据库服务端的运行状态异常。
12.本发明还提供了一种数据库服务端运行状态的检测装置,所述数据库服务端与客户端通信连接,所述检测装置包括:
13.第一获取模块,用于持续性地获取所述数据库服务端在至少一个预设时间间隔内
相对所述客户端的至少一个第一响应时间;
14.第一处理模块,用于对至少一个所述第一响应时间做数据处理,得到所述数据库服务端在每个所述预设时间间隔内的第一平均响应时间、与由至少一个所述预设时间间隔组成的预设时间段的第二平均响应时间;
15.第二处理模块,用于对所述第二平均响应时间与至少一个所述第一平均响应时间做数据处理,得到第一平均响应时间判断值与第二平均响应时间阈值;
16.第一判断模块,用于判断所述第一平均响应时间判断值是否大于所述第二平均响应时间阈值;
17.第一判定模块,用于若是,则判定所述数据库服务端的运行状态异常。
18.本发明实施例的有益效果是,可及时、简便、智能、有效地根据数据库服务端与客户端之间交互所产生的数据,来判定数据库服务端的运行状态是否异常,若发生异常,后续还可根据异常情况进一步地确定异常原因,使运维人员可及时地得到异常运行状态的反馈并确定异常原因,以根据异常原因及时、有效地解决数据库服务端当前的异常运行状态,保证数据库服务端与客户端之间的正常数据交互,保证用户体验。
附图说明
19.图1是本发明实施例的数据库服务端与客户端之间的结构示意图;
20.图2是本发明实施例的检测方法的流程示意图;
21.图3是本发明实施例的数据库服务端运行状态异常时响应数据的变化示意图;
22.图4至图7是本发明实施例的检测方法的流程示意图;
23.图8至图12是本发明实施例的检测装置的结构示意图。
具体实施方式
24.为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
25.现有技术中,缺少及时、有效地判定数据库服务端和客户端的运行状态异常以及异常原因的机制,导致运维人员无法及时、有效地得到异常反馈,更是无法及时、准确地确定异常原因以进行维护,不但影响数据库服务端与客户端之间的正常交互,也影响用户体验。
26.本发明以获取到的数据库服务端在预设时间段内与客户端交互产生的至少一个第一响应时间为基础,再得到第一平均响应时间、第二平均响应时间、第二平均响应时间判断值与第二平均响应时间阈值,通过对以上数据的处理与对比,达到判断数据库服务端的运行状态是否异常的目的。
27.实施例一
28.请参阅图1与图2,本发明实施例的数据库服务端与客户端运行状态的检测方法,数据库服务端与客户端通信连接,检测方法包括步骤:
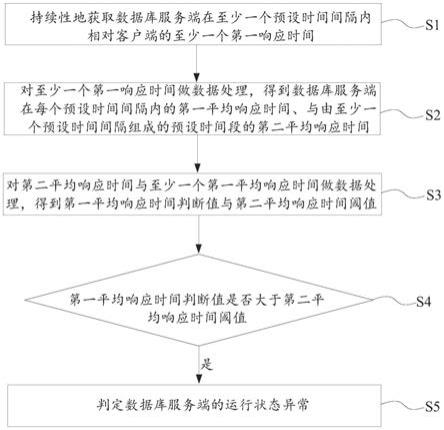
29.s1:持续性地获取数据库服务端在至少一个预设时间间隔内相对客户端的至少一个第一响应时间;
30.s2:对至少一个第一响应时间做数据处理,得到数据库服务端在每个预设时间间隔内的第一平均响应时间、与由至少一个预设时间间隔组成的预设时间段的第二平均响应时间;
31.s3:对第二平均响应时间与至少一个第一平均响应时间做数据处理,得到第一平均响应时间判断值与第二平均响应时间阈值;
32.s4:判断第一平均响应时间判断值是否大于第二平均响应时间阈值;
33.s5:若是,则判定数据库服务端的运行状态异常。
34.请参阅图1,图1为数据库服务端(date base,db)与客户端(application,app)之间的结构示意图,一个数据库服务端与至少一个客户端通信连接并发生数据交互。数据库服务端与客户端之间的交互是通过网络请求和网络应答建立的,并通过传输控制协议(transmission control protocol,tcp)进行数据传输交互,通过实时抓取并解析网络dump包中的流量,可检测发现数据库服务端与客户端的实时运行状态,实现对两者之间的运行状态的监控。
35.数据库服务端与客户端之间正常的一次数据交互为:一次网络请求数对应一次网络应答数,完成一次请求与应答即为完成一次数据交互。例如,客户端对数据库服务端发送一次网络请求,数据库服务端对客户端回复一次网络应答,此时,数据库服务端与客户端之间即完成一次数据交互。
36.而当某个阶段内的网络请求总数与网络响应总数不相等时,或者网络响应时间越来越长,网络响应率越来越低时,则说明数据库服务端与客户端之间存在异常的数据交互。此时,可根据在一定时间内异常的响应时间或响应率,来判定数据库服务端与客户端之间的运行状态是否出现异常。
37.需要说明的是,数据库服务端与客户端之间交互的响应时间、响应率以及数据量等可直接通过相关设备或程序获取。本发明实施例通过cnstat模块获取数据库服务端与客户端之间的交互数据,在其他实施例中,还可通过其他方式以及设备获取,在此不做赘述。
38.在本发明的实施例中,上述检测方法用于在数据库服务端与客户端之间有连接,但是数据库服务端所接受的请求数在正常值上下频繁波动,且数据库服务器的响应时间也在正常值上下起伏,形成一种“颠簸”的异常运行状态,在本发明实施例中将上述运行状态认定为“颠”运行状态。同时,本发明实施例所确定的异常原因即为数据库服务端的响应时间上下起伏(或请求数、响应率上下波动等),运维人员则可根据所确定的“颠”运行状态、以及数据库服务端的响应时间上下起伏的异常原因,对数据库服务端进行维护。
39.具体地,在发明实施例中,在判断数据库服务端运行状态的过程中,需要获取数据库服务端在某段时间内的所有交互数据用以分析,而根据不同的实际需求,则需要获取一段或多段时间内对应的一个或多个数据来针对不同的情况进行分析。因此,在上述步骤s1中,预设时间间隔至少为一个,预设时间间隔可以理解为一段时长,而每个第一响应时间为每个预设时间间隔内对应的响应时间,因此也至少为一个。对预设时间间隔内的第一响应时间持续性地获取,以检测当前阶段下的数据库服务端的运行状态,同时可避免遗漏第一响应时间而导致对数据库服务端运行状态的误判。
40.值得注意的是,此处的第一响应时间为未经处理的原始数据,可通过相关器件或软件获取得到。在选定一个时间点后,获取该时间点前、后的预设时间间隔内的第一响应时
间,在一个实施例中,若预设时间间隔与第一响应时间均为多个,则可将多个第一响应时间按照时间发生的先后顺序,添加形成为第一响应时间集合,如此,既便于记录第一响应时间,也便于对第一响应时间做批量处理。当然,即使第一响应时间为一个,也可在将其获取后添加形成为第一响应时间集合,以在后续处理时,作为明确的数据来源。
41.可以理解,若预设时间间隔为一个,则第一响应时间也为一个,第一响应时间集合内为一个第一响应时间;若预设时间间隔为多个,则第一响应时间也为多个,第一响应时间集合内为多个第一响应时间。预设时间间隔可以为10s、30s、1min、2min、10min、30min、1h等时间数值,示例性地,当预设时间间隔为1min时,第一响应时间则为1min内的响应时间,第一响应时间集合则为1min内的响应时间组成的集合。
42.在本发明实施例中,预设时间间隔为1min,且其数量为多个,通过获取数据库服务端在多个预设时间间隔组成的一段时间内每1min的响应时间,来较为准确地对数据库服务端的运行状态进行判断;在其他实施例中,预设时间间隔可以为其他时长,其数量也可以为1个,在实际的实施例中具体设置即可。
43.在步骤s2中,在得到第一响应时间后对其进行数据处理,数据处理包括但不限于计算至少一个第一响应时间的平均值、与将至少一个第一响应时间相加等处理。在对至少一个第一响应时间的处理过程中,可先将第一响应时间形成上述的第一响应时间集合,以对第一响应时间为多个时做批量的处理。
44.进一步地,在对上述第一响应时间集合的处理过程中,包括计算第一响应时间集合中的第一响应时间的平均值,得到数据库服务端对应每个预设时间间隔的第一平均响应时间,计算第一响应时间的平均值可避免在仅获取到预设时间间隔内的某些响应时间的数值较为极端(过大或过小)时,对最终数值与判断结果所造成的影响。
45.在对由第一响应时间所形成的第一响应时间集合的处理过程中,还包括将预设时间间隔相加得到预设时间段、以及对后续的第一平均响应时间相加得到第二平均响应时间。预设时间段由至少一个预设时间间隔构成,其中,预设时间间隔为在预设时间段内按一定时长间隔选择的时间点,如此,方式较为简易,预设时间间隔的分布较为均匀,且减少了在预设时间间隔上所得到的第一响应时间的偶然性。可以理解,若预设时间间隔为1个,则预设时间段的时长等于该预设时间间隔。由每个预设时间间隔内的每个第一平均响应时间,相加得到预设时间段内的第二平均响应时间,第二平均响应时间为数据库服务端在预设时间段内的总的平均响应时间,可用以判断数据库服务端在以整个预设时间段内的响应时间的变化趋势。可以理解,若第一平均响应时间为1个,则第二平均响应时间的时长等于该第一平均响应时间,示例性地,若第一平均响应时间为10s,则第二平均响应时间也为10s。
46.在本发明实施例中,预设时间间隔设定为1min,数量为10个,则预设时间段为10min,获取的第一响应时间为第0min-第1min、第1min-第2min、第2min-第3min、第3min-第4min、第4min-第5min、第5min-第6min、第6min-第7min、第7min-第8min、第8min-第9min、第9min-第10min内共10组的响应时间,若每min的第一平均响应时间分别为0.1ms、0.2ms、0.3ms、0.4ms、0.5ms、0.1ms、0.2ms、0.3ms、0.4ms、0.5ms,则第二平均响应时间则为上述数值相加的值,等于3ms,即数据库服务端在10min内的平均响应时间为3ms。
47.请结合图3,在本发明实施例中,可建立有横轴x为实际时间,纵轴y为响应时间的
坐标轴,以预设时间段为10min,预设时间间隔为1min为例。在横轴x上存在预设时间段的起点a与终点b,起点a即当前的时间点,终点b即在横轴x上以当前的时间点过去预设时间段的时间长度的点(b点即10min前的点)。在预设时间段(10min)内每个预设时间间隔(每1min)所获取的第一响应时间,按时间先后顺序排列(如从按横轴x的终点b向起点a算起),此时第一响应时间为10个,如图3所示的每个点,10个第一响应时间组成第一响应时间集合,而后对第一响应时间集合内的10个第一响应时间求平均值,得到10段预设时间间隔内的10个第一平均响应时间,将10个第一平均响应时间相加得到第二平均响应时间。
48.值得注意的是,在数据库服务端与客户端之间不断的交互过程中,预设时间段始终为固定数值,对数据库服务端的运行状态的判断也是持续性进行的,为保证随着时间的变化对应、有效地判断数据库服务端的运行状态,当时间超过预设时间段时,在第一响应时间集合内,所获取到的新的一个预设时间间隔内的第一响应时间,将替换原先所获取到的第一个预设时间间隔内的第一响应时间,如在10min的预设时间段内,每1min为预设时间间隔,获取到的第11min的第一响应时间,将替换10min内的第1min的第一响应时间,所获取到的第12min的第一响应时间,将替换10min内的第2min的第一响应时间,以此类推,保证对数据库服务端运行状态判断的即时性与有效性。
49.在步骤s3中,对第二平均响应时间的数据处理包括但不限于在第二平均响应时间的基础上加、减、乘、除设定数值得到第二平均响应时间阈值,对至少一个第一平均响应时间的数据处理包括但不限于对其做线性拟合等。在本发明实施例中,在第二平均响应时间的基础上乘以设定数值得到第二平均响应时间阈值,将至少一个第一平均响应时间做线性拟合得到第一平均响应时间判断值。
50.通过第一平均响应时间判断值与第二平均响应时间阈值的对比,用以确定预设时间段内、对应于每个时间间隔的响应时间与第二平均响应时间阈值之间的差距,用以判断呈连续性地、在多个时间间隔与时间段内的响应数据所发生的波动。当第一平均响应时间判断值大于第二平均响应时间阈值时,证明数据库服务端与客户端之间的交互数据波动较为剧烈,即可及时、简便、智能、有效地判定数据库服务端的运行状态异常,该异常运行状态为“颠”运行状态。
51.而进一步地可确认异常原因为,数据库服务端的响应时间上下起伏。运维人员则可及时地根据所确定的“颠”运行状态、以及数据库服务端的响应时间上下起伏的异常原因,对数据库服务端进行维护,及时、有效地解决当前的异常运行状态,保证数据库服务端与客户端之间的正常数据交互,保证用户体验。
52.实施例二
53.更进一步地,请参阅图4,步骤s1之前包括步骤:
54.s6:选定预设时间点;
55.步骤s2包括步骤:
56.s11:持续性地获取数据库服务端在预设时间点前的至少一个预设时间间隔内相对客户端的至少一个第一响应时间。
57.具体地,对数据库服务端的运行状态的检测与判断是实时进行的,为准确了解某段时间的运行状态,需要先选定时间轴上的预设时间点,再以预设时间点为基点,沿时间轴往前或往后一定时间长度(预设时间间隔)到下一个点,若预设时间间隔为多个,则在上述“下一个点”继续往前或往后一定时间长度(预设时间间隔)到下下个点,以此不断向前或向后推进。
58.示例性地,若预设时间点为10:00,预设时间间隔为1min,则选定1min前的时间点,即选定9:59这个时间点,获取9:59后1min的响应时间,即9:59到10:00这1min内的响应时间,用以判定预设时间点的运行状态。
59.本发明实施例中,通过获取数据库服务端在预设时间点前的预设时间间隔内的第一响应时间,以做为对已发生的、数据库服务端与客户端之间的数据交互、运行状态是否异常的判断,避免在预设时间点之后的时间内,如果数据库服务端与客户端之间仍旧发生异常,而仍然会影响数据库服务端与客户端接下来的数据交互的问题。
60.实施例三
61.更进一步地,请参阅图5,步骤s2包括步骤:
62.s21:计算至少一个第一响应时间的平均值,得到数据库服务端在每个预设时间间隔内的第一平均响应时间;
63.s22:将至少一个预设时间间隔相加得到预设时间段,并将至少一个第一平均响应时间相加得到第二平均响应时间。
64.具体地,在得到第一响应时间后对其进行数据处理,数据处理包括但不限于计算至少一个第一响应时间的平均值、与将至少一个第一响应时间相加等处理。在对至少一个第一响应时间的处理过程中,可先将第一响应时间形成第一响应时间集合,以在第一响应时间为多个时做批量的处理,提高数据处理效率。
65.在对第一响应时间集合的处理过程中,还包括将预设时间间隔相加得到预设时间段、以及对后续的第一平均响应时间相加得到第二平均响应时间。预设时间段由至少一个预设时间间隔构成,其中,预设时间间隔为在预设时间段内按一定时长间隔选择的时间点,预设时间间隔的分布较为均匀,且减少了在预设时间间隔上所得到的第一响应时间的偶然性。可以理解,若预设时间间隔为1个,则预设时间段的时长等于该预设时间间隔。
66.由每个预设时间间隔内的每个第一平均响应时间,相加得到预设时间段内的第二平均响应时间,第二平均响应时间为数据库服务端在预设时间段内的总的平均响应时间,可用以判断数据库服务端在以整个预设时间段内的响应时间的变化趋势。可以理解,若第一平均响应时间为1个,则第二平均响应时间的时长等于该第一平均响应时间,示例性地,若第一平均响应时间为10s,则第二平均响应时间也为10s。
67.在本发明实施例中,预设时间间隔设定为1min,数量为10个,则预设时间段为10min;若每min的第一平均响应时间分别为0.1ms、0.2ms、0.3ms、0.4ms、0.5ms、0.1ms、0.2ms、0.3ms、0.4ms、0.5ms,则第二平均响应时间则为上述数值相加的值,等于3ms,即数据库服务端在10min内的平均响应时间为3ms。
68.进一步地,请结合图3,在本发明实施例中,可建立有横轴x为实际时间,纵轴y为数据库服务端的响应时间的坐标轴,以预设时间段为10min,预设时间间隔为1min为例,在横轴x上存在预设时间段的起点a与终点b,起点a即当前的时间点,终点b即在横轴x上以当前的时间点过去预设时间段的时间长度的点(b点即10min前的点)。在预设时间段(10min)内每个预设时间间隔(每1min)所获取的第一响应时间,如图3所示的每个点,按时间先后顺序排列(如从按横轴x的终点b向起点a算起),此时第一响应时间为10个,10个第一响应时间组
成第一响应时间集合,而后对第一响应时间集合内的10个第一响应时间求平均值。
69.值得注意的是,在数据库服务端与客户端之间不断的交互过程中,预设时间段始终为固定数值,对数据库服务端的运行状态的判断也是持续性进行的。为保证随着时间的变化对应、有效地判断数据库服务端的运行状态,当时间超过预设时间段时,在第一响应时间集合内,所获取到的新的一个预设时间间隔内的第一响应时间,将替换原先所获取到的第一个预设时间间隔内的第一响应时间。如在10min的预设时间段内,每1min为预设时间间隔,获取到的第11min的第一响应时间,将替换10min内的第1min的第一响应时间,所获取到的第12min的第一响应时间,将替换10min内的第2min的第一响应时间,以此类推,保证对数据库服务端运行状态判断的即时性与有效性。
70.实施例四
71.更进一步地,请参阅图6,步骤s3包括步骤:
72.s31:将至少一个第一平均响应时间按时间先后顺序添加并形成第一平均响应时间序列;
73.s32:对第一平均响应时间序列做线性拟合,得到每个预设时间间隔的第一平均响应时间的均方根误差,将均方根误差做为第一平均响应时间判断值;
74.s33:在第二平均响应时间基础上乘以设定倍数得到第二平均响应时间阈值。
75.具体地,对第二平均响应时间的数据处理包括但不限于在第二平均响应时间的基础上加、减、乘、除设定数值得到第二平均响应时间阈值,对至少一个第一平均响应时间的数据处理包括但不限于对其做线性拟合等。
76.进一步地,在对第一平均响应时间的处理过程中,可将至少一个第一平均响应时间,按时间先后顺序添加形成第一平均响应时间序列,如此,在计算得到一个第一平均响应时间后即可添加至设定的序列内,而在需要计算得到第一平均响应时间判断值时,也可对整个第一平均响应时间序列进行批量处理,提高数据处理效率。示例性地,若预设时间段为10min,预设时间间隔为1min,计算得到10段预设时间间隔内的10个第一平均响应时间,若每1min的第一平均响应时间分别为0.1ms、0.2ms、0.3ms、0.4ms、0.5ms、0.1ms、0.2ms、0.3ms、0.4ms、0.5ms,将10个第一平均响应时间按获取时间的先后顺序构成第一平均响应时间序列,第一平均响应时间序列可以为(0.1、0.2、0.3、0.4、0.5、0.1、0.2、0.3、0.4、0.5)、[0.1、0.2、0.3、0.4、0.5、0.1、0.2、0.3、0.4、0.5]或《0.1、0.2、0.3、0.4、0.5、0.1、0.2、0.3、0.4、0.5》等形式。
[0077]
将至少一个第一平均响应时间做线性拟合得到第一平均响应时间判断值,即将组成为整体的第一平均响应时间序列做线性拟合,并形成如图3所示的拟合曲线。同时计算得到每个预设时间间隔的均方误差(mean square error,mse),均方误差mse是指参数估计值与参数真值之差平方的期望值,均方误差mse可以评价数据的变化程度,均方误差mse的值越小,说明预测模型描述实验数据具有更好的精确度。均方误差mse的计算公式为:
[0078][0079]
再由均方误差mse得到均方根误差(root mean square error,rmse),均方根误差rmse的计算公式为:
[0080][0081]
均方根误差rmse是均方误差值mse的平方根,是用来衡量参数估计值与参数真值之间的偏差。将均方根误差rmse做为第一平均响应时间判断值,可用以确定计算得到的预设时间段内的每个预设时间间隔内的第一平均响应时间(参数估计值)与实际的原始响应时间(参数真值)之间的差距,确定预设时间段内响应时间的变化程度。
[0082]
请结合图3,在本发明实施例中,在第二平均响应时间的基础上乘以设定数值得到第二平均响应时间阈值,上述设定数值为:(1
±
0.2,即0.8与1.2),以avg1做为第二平均响应时间的指代,第二平均响应时间阈值为:(0.8*avg1至1.2*avg1),为一个阈值误差范围。
[0083]
判断第一平均响应时间判断值与第二平均响应时间阈值,即判断每个预设时间间隔时间内的响应时间的变化程度,是否位于预设时间段内的总平均响应时间允许的范围内。若数据库服务端的响应时间在第二平均响应时间阈值内波动较为正常,而超过该范围则表明波动较大,存在异常情况。通过第一平均响应时间判断值与第二平均响应时间阈值的对比,用以确定预设时间段内、对应于每个时间间隔的响应时间与第二平均响应时间阈值的实际的最小距离,用以判断呈连续性地、在多个时间间隔与时间段内的响应数据所发生的波动。
[0084]
实施例五
[0085]
更进一步地,请参阅图7,步骤s5之后包括步骤:
[0086]
s7:输出数据库服务端的运行状态异常的异常原因。
[0087]
当第一平均响应时间判断值大于第二平均响应时间阈值时,证明数据库服务端与客户端之间的交互数据波动较为剧烈,即可判定数据库服务端的运行状态异常,该异常运行状态为“颠”运行状态;而异常原因为,数据库服务端对于客户端的响应时间上下起伏。确定该异常原因后,用于检测数据库服务端运行状态的装置,可向运维人员操作的终端(如台式电脑、笔记本电脑、平板电脑、甚至智能手机等)输出该异常原因。运维人员则可根据所确定的“颠”运行状态与数据库服务端相对客户端的响应时间上下起伏的异常原因,及时、有效地对数据库服务端进行维护,保证数据库服务端与客户端之间的正常数据交互,保证用户体验。
[0088]
示例性地,上述检测装置输出异常原因的形式可以为运维人员的终端上弹出提示框、发送提示信息等,在此不对输出异常原因的形式做具体限定,在保证有效地输出异常原因的前提下,在实际的实施例中选择即可。
[0089]
更多地,在数据库服务端输出异常原因的同时,还可输出表征当前数据库服务端的运行状态出现异常的提示信号,以使运维人员及时地接收到运行状态异常的反馈,及时、有效地处理异常。提示信号可以由具备提示功能的相关设备发出,相关设备如运维人员操作的终端、设于运维人员附近的声光报警器等,如当出现异常时,可以通过终端发出即时性的文字弹窗信息等,或通过声光报警器发出声光警报等,以直观、有效地使运维人员获知数据库服务端与客户端发生运行状态异常,提高对数据库服务端与客户端的维护效率。
[0090]
实施例六
[0091]
请参阅图8,本发明实施例的数据库服务端与客户端运行状态的检测装置10,数据
库服务端与客户端通信连接,检测装置10包括:
[0092]
第一获取模块11,用于持续性地获取数据库服务端在至少一个预设时间间隔内相对客户端的至少一个第一响应时间;
[0093]
第一处理模块12,用于对至少一个第一响应时间做数据处理,得到数据库服务端在每个预设时间间隔内的第一平均响应时间、与由至少一个预设时间间隔组成的预设时间段的第二平均响应时间;
[0094]
第二处理模块13,用于对第二平均响应时间与至少一个第一平均响应时间做数据处理,得到第一平均响应时间判断值与第二平均响应时间阈值;
[0095]
第一判断模块14,用于判断第一平均响应时间判断值是否大于第二平均响应时间阈值;
[0096]
第一判定模块15,用于若是,则判定数据库服务端的运行状态异常。
[0097]
本发明实施例六所提供的检测装置10,其实现原理及产生的技术效果和前述的检测方法的实施例一相同,为简要描述,检测装置10的实施例六未提及之处,可参考前述方法实施例一中相应内容。
[0098]
实施例七
[0099]
更进一步地,请参阅图9,检测装置10还包括:
[0100]
选定模块16,用于选定预设时间点;
[0101]
第二获取模块17,用于持续性地获取数据库服务端在预设时间点前的至少一个预设时间间隔内相对客户端的至少一个第一响应时间。
[0102]
本发明实施例七所提供的检测装置10,其实现原理及产生的技术效果和前述的检测方法的实施例二相同,为简要描述,检测装置10的实施例七未提及之处,可参考前述方法实施例二中相应内容。
[0103]
实施例八
[0104]
更进一步地,请参阅图10,检测装置10还包括:
[0105]
第一计算模块18,用于计算至少一个第一响应时间的平均值,得到数据库服务端在每个预设时间间隔内的第一平均响应时间;
[0106]
第二计算模块19,用于将至少一个预设时间间隔相加得到预设时间段,并将至少一个第一平均响应时间相加得到第二平均响应时间。
[0107]
本发明实施例八所提供的检测装置10,其实现原理及产生的技术效果和前述的检测方法的实施例三相同,为简要描述,检测装置10的实施例八未提及之处,可参考前述方法实施例三中相应内容。
[0108]
实施例九
[0109]
更进一步地,请参阅图11,检测装置10还包括:
[0110]
第三处理模块20,用于将至少一个第一平均响应时间按时间先后顺序添加并形成第一平均响应时间序列;
[0111]
第三计算模块21,用于对第一平均响应时间序列做线性拟合,得到每个预设时间间隔的第一平均响应时间的均方根误差,将均方根误差做为第一平均响应时间判断值;
[0112]
第四处理模块22,用于在第二平均响应时间基础上乘以设定倍数得到第二平均响应时间阈值。
[0113]
本发明实施例九所提供的检测装置10,其实现原理及产生的技术效果和前述的检测方法的实施例四相同,为简要描述,检测装置10的实施例九未提及之处,可参考前述方法实施例四中相应内容。
[0114]
实施例十
[0115]
更进一步地,请参阅图12,检测装置10还包括:
[0116]
输出模块23,用于输出数据库服务端的运行状态异常的异常原因。
[0117]
本发明实施例十所提供的检测装置10,其实现原理及产生的技术效果和前述的检测方法的实施例五相同,为简要描述,检测装置10的实施例十未提及之处,可参考前述方法实施例五中相应内容。
[0118]
以上仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所做的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。