1.本发明涉及机器学习和城市规划交叉领域中的公共空间活力分析问题,尤其是涉及基于人群聚类轨迹熵的空间活力量化方法。
背景技术:
2.随着城市社会的发展,公共空间生活受到人们的关注,城市公共空间活力是实现城市生活质量的最基本要素。城市公共空间中“人”的状态是衡量空间活力的重要因素,人群的活动可以真实体现人在空间中的感受,反映空间质量现状。人群活动作为体现空间活力的特征,已经成为城市空间活力研究的主要方向。
3.然而,传统行为活动数据获取和空间活力评估方法具有一定的局限性,比如现场观察法来获取活动类型数据,受到人力时间成本的限制。随着互联网、物联网等信息技术的发展,时空大数据等新技术逐渐被研究者所使用,城市公共空间下的摄像头视频可以提供公共空间人群运动轨迹状态信息,这些数据大量用于公共社会学的研究。人群轨迹数据由于覆盖面积广、运动自由等特点,包含了丰富的公共空间状态信息和市民活动信息。时空轨迹描述了运动人群在公共空间中的运动模式和行为特征,揭示了公共空间中人群流量和空间占用率,还可以通过分析解释公共空间的活力特性。本发明利用机器学习技术,采用人群轨迹聚类的方法提取人群的运动模式簇,并使用信息学和热力学熵的概念对运动轨迹模式簇量化分析并且感知人群在空间中的活力状态。该发明通过聚类轨迹熵描述空间中人群轨迹分布的均匀性和不确定性,给城市规划者调查领域研究公共空间活力提供了新思路。
技术实现要素:
4.本发明的目的是提供一种基于人群聚类轨迹熵的空间活力量化方法,将轨迹熵的概念与公共空间活力分析结合。首先,根据人群轨迹的局部相关性利用匹配轨迹段间相关性和邻近匹配点数改进聚类相似性度量,然后采用轮廓系数作为评价指标对相似运动趋势轨迹自动寻找轨迹聚类簇数并得到轨迹聚类结果,最后以轨迹聚类结果计算空间轨迹熵,其描述空间中轨迹分布的不均匀性和不确定性,由空间轨迹熵定义特性,揭示了公共空间中人群运动模式和空间占有率,从而反映公共空间活力大小。
5.为了方便说明,首先引入如下概念:
6.相似性度量(similarity measurement):在分类聚类算法中,时常需要计算两个变量的距离,即综合评定两条轨迹之间相近程度的一种度量。
7.轮廓系数(silhouette coefficient):是聚类效果好坏的一种评价方式,它结合内聚度和分离度两种因素。可以用来在相同原始数据的基础上用来评价不同算法、或者算法不同运行方式对聚类结果所产生的影响。
8.本发明具体采用如下技术方案:
9.提出了一种基于人群聚类轨迹熵的空间活力量化方法,其特征在于:
10.a.采用匹配轨迹段间的余弦相关性和临近匹配点数的方法处理人群运动轨迹,得
到任意两条轨迹间的相似性度量距离;
11.b.采用密度峰值聚类算法对空间轨迹聚类,利用轮廓系数增加筛选出最佳的聚类中心;
12.c.利用轨迹聚类结果计算空间轨迹熵,并使用空间轨迹熵量化分析空间活力;
13.该方法主要包括以下步骤:
14.(1)使用先进的多目标跟踪算法从公有的公共空间视频中提取轨迹数据,并对轨迹数据预处理,去除掉比较短的轨迹段;
15.(2)利用步骤(1)预处理后的轨迹数据,并基于两条轨迹结构相似性关系得到两条轨迹结构位置一致的匹配点;
16.(3)利用由匹配点组成的匹配线段,基于余弦相似性方法对匹配的轨迹段进行度量并得出余弦相关性增强系数α;
17.(4)设定轨迹匹配点间距离参数阈值β,轨迹中小于此阈值β的匹配点称其为临近匹配点,统计满足此条件的匹配点数。临近匹配点数与余弦相关性增强系数α共同作为相似性度量增强参数,最后计算出所有轨迹间相似性度量矩阵;
18.(5)以轮廓系数作为评价指标,利用轨迹相似度量矩阵作为峰值密度聚类算法的特征输入自适应得到聚类轨迹簇数;
19.(6)采用每条轨迹到所有轨迹聚类中心的距离计算不相似度概率,然后计算空间轨迹熵作为空间活力值。
20.本发明的有益效果是:
21.(1)结合人群运动轨迹的不确定性特点,利用匹配线段的余弦相似性度量和临近匹配点作为增强系数,提升轨迹聚类结果簇内相似度和簇间离散度。
22.(2)考虑到聚类参数选取困难问题,采用轮廓系数决定聚类簇数,有效减少参数对聚类结果的影响,提高了算法的自适应性。
23.(3)充分考虑到轨迹在空间分布量化表示问题,求解空间轨迹熵值可以有效的体现空间活力强度信息。
24.(4)将信息熵计算方法引入到城市空间活力研究中,避免了传统方法主观因素多的问题,提高研究价值。
附图说明
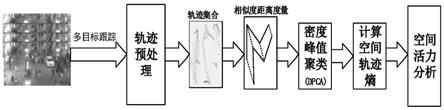
25.图1为基于聚类轨迹熵的空间活力分析框架图;
26.图2为四个公共空间a、b、c、d某时刻空间聚类轨迹图,space a中有38条轨迹和17类簇,space b中有21条轨迹9类簇,space c中有11条轨迹4类簇,space d中有19条轨迹2类簇;
27.图3为四个空间a、b、c、d空间轨迹聚类熵对比图。
具体实施方式
28.下面通过实例对本发明作进一步的详细说明,有必要指出的是,以下的实施例只用于对本发明做进一步的说明,不能理解为对本发明保护范围的限制,所属领域技术熟悉人员根据上述发明内容,对本发明做出一些非本质的改进和调整进行具体实施,应仍属于
本发明的保护范围。
29.图1中,基于人群聚类轨迹熵的空间活力量化方法,具体包括以下步骤:
30.(1)使用先进的多目标跟踪算法从数据视频中提取轨迹数据,并对轨迹数据预处理,去除掉存在时间比较短的轨迹段。
31.(2)基于轨迹结构相似性对应关系,两条轨迹匹配点间一一对应,保证两条轨迹对应结构比例位置差最小得到对应匹配点,如公式1,tr_pos[i]表示轨迹点pi对应轨迹结构的比例位置,qj和pi是一对匹配点。
[0032]
qj=map{min(abs(tr_pos[i]-trq_pos[j]),p
i=0,1,...,n
)}
ꢀꢀꢀ
(1)
[0033]
(3)计算相关性增强系数:针对上述的匹配点以及匹配点组成的匹配线段,基于cosine余弦相似性方法对匹配的轨迹段进行度量,如公式(2),pqθi的范围是[0,π],pqθi为0表示两条匹配段方向一致且相关性比较强,pqθi为π表示匹配段没有相关性。对于两条轨迹存在大量相关性强的匹配轨迹段,对应轨迹段的结构就趋近于相似,轨迹间距离可用轨迹点间距离衡量。对于结构差异比较大的轨迹,需要相关性增强系数,如式3,要在轨迹点距离基础上乘上增强系数,增大相似性度量距离。
[0034][0035][0036]
(4)临近匹配点统计和计算轨迹相似性度量:针对两条轨迹不仅结构相似而且每个匹配点距离都比较近,那么这两条轨迹更可能是一个类群,因此定义匹配点距离阈值β,统计满足小于此阈值的匹配点数,如公式4,称其为临近匹配点,临近匹配点的数量决定了轨迹相似度距离能够缩小程度,相似度距离小的轨迹更容易聚成同一类。临近匹配点数与(3)中的相关性增强系数共同作为相似性度量的增强系数并计算出相似性度量矩阵,如公式5,||ps
i-qsi||代表匹配点间的欧式距离,增强系数作为缩放因子共同决定相似度度量距离的大小。
[0037][0038][0039]
(5)依据轨迹相似性特征,基于密度峰值聚类算法将局部密度与高局部密度点间距离乘上排序后依次添加到聚类中心中,然后计算所有轨迹到中心轨迹点距离并计算轮廓系数,选取最大的轮廓系数对应的聚类中心和聚类个数作为所有轨迹的聚类中心和聚类簇数。
[0040]
(6)计算空间轨迹熵:依据轨迹类别间的离群程度和轨迹在空间中混乱程度,综合考虑行为轨迹可以表达空间环境信息和空间中的轨迹分布状态,定义公式6、7,其中,p(li,lj)代表轨迹li与各个聚类中心的不相似性概率,lj表示聚类中心代表性轨迹,dist(li,lj)
代表两个轨迹间的相似度距离,clus表示聚类中心的数量,表示轨迹li与各个聚类中心lk距离之和。根据公式7计算空间轨迹熵作为空间活力值,表示轨迹在空间分布的情况,空间轨迹熵取值越大表示空间中非延时型活动越多,不同运动趋势或者运动方向的轨迹分布越均匀,对应空间活力越大。
[0041][0042]
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。