一种基于banyan网络和多fpga结构的eda硬件加速方法与系统
技术领域
1.本发明涉及eda硬件加速技术领域,尤其是一种基于banyan网络和多fpga结构的eda硬件加速方法与系统。
背景技术:
2.随着ic设计行业的不断发展和超大规模ic工艺制程技术的不断进度,ic设计的规模、复杂度成倍提高,这对eda软件处理仿真、综合、布局布线、验证等过程的计算能力的要求大大增加。这些eda软件的运算过程往往占据了大量的设计时间。fpga作为一种配置灵活的计算密集型高速运算设备,在处理大规模数据运算和电路仿真时,存在着一定优势,而多fpga系统的提出无疑是锦上添花。
3.在多fpga系统中,其互联结构的实现形式对数据的传输效率影响极大。目前典型的互联结构有:线阵型、网格型、交叉互联型和混合互联型。这些结构存在着高延迟、低效率、实现复杂等问题。本发明所采用的banyan网络结构是一种空分交换网络,应用于并行计算机和atm交换机等领域,具有唯一路径特性和自选路由功能。通过在多fpga块间搭建banyan网络进行数据传输,具有良好的延迟特性,能够有效提升传输效率。
4.使用fpga进行eda算法硬件加速的过程中,需要计算机主机端将所需处理的数据发送给硬件侧。本发明采用了pcie硬件接口,pcie是高速串行计算机i/o总线,采用了高速串行点对点双通道高带宽传输,其第三代的传输速率可以达到8gt/s。此外,常见的硬件加速系统存在通用性不强,需要使用不同的系统来实现算法加速和仿真加速。为了提高设计的通用性,本发明将eda算法加速与仿真加速功能能够结合在一起,并采用了sce-mi标准。sce-mi标准定义了一种连接采用行为描述的软件模型与采用可综合hdl代码描述的被测试系统的接口模型,它通过若干个独立的虚拟通信通道实现这二者的通信。
5.传统的eda算法硬件加速系统具有可移植性不强,加速效果不显著等问题。本发明将eda算法加速与仿真加速相结合,提高了整体的通用性。此外,本发明采用多fpga结构,能够解决单fpga资源较少的问题,充分利用fpga的并行性来提高整体加速效果。
6.常用的fpga互联结构主要是线阵型、网格型、交叉互联型和混合互联型。线阵型结构简单,但存在较大的传输延迟,不适用于大型多fpga系统。网格型结构增强了一定的传输能力,但同样对于跨fpga的传输,存在较大延迟。交叉互联型和混合互联型结构传输效率大大提高,但在fpga块数较多时会占用大量的资源。本发明采用banyan网络来实现多fpga结构,能够以较低的延迟和少量的资源实现高效的跨fpga传输。
7.本发明旨在搭建具有高通用性和高效率的eda算法加速和仿真加速系统,并利用banyan网络特性来实现高效低延迟的跨fpga传输。
技术实现要素:
8.本发明提出了一种基于banyan网络和多fpga结构的eda硬件加速方法与系统,以
解决上文提到的现有技术的缺陷。
9.在一个方面,本发明提出了一种基于banyan网络和多fpga结构的eda硬件加速方法,该方法包括以下步骤:
10.s1:用户选择加速模式,所述加速模式包括eda算法加速模式和eda仿真加速模式;
11.s2:若选择所述eda算法加速模式:启用顶层eda算法控制数据的发送和接收,并对数据进行批次处理再进行基于sce-mi通道的封装处理;
12.若选择所述eda仿真加速模式:根据用户所设计的待测设计结构以及用户输入的仿真数据,对所述仿真数据进行基于sce-mi通道的封装处理;
13.s3:将封装后的数据通过pcie驱动和硬件送入fpga板上的pcie核中,pcie核以dma读取方式将所述封装后的数据通过axi传送协议进行传送,再利用sce-mi进行管理,所述fpga板包括多块fpga;
14.s4:基于sce-mi对所述封装后的数据进行解包处理后再通过对应的sce-mi通道发送至banyan网络的对应节点中,再根据信元调度算法将所述封装后的数据发送到多块fpga的与所述节点相对应的接收通道中;
15.s5:若选择所述eda算法加速模式:基于所述多块fpga的并行计算对所述封装后的数据进行加速,再将加速后的数据回传至所述顶层eda算法进行处理;
16.若选择所述eda仿真加速模式:利用所述多块fpga将所述封装后的数据与所述待测设计结构进行仿真验证后,生成仿真数据,将所述仿真数据与用户提供的标准验证数据进行对比验证仿真结果。
17.以上方法将eda算法加速和仿真加速结合在一个系统内,使用banyan网络来实现多fpga的数据交换,采用多通道sce-mi接口进行软硬件数据协同,采用软硬件协同方式对算法和仿真进行加速。实现了eda算法加速和仿真加速相结合,采用了多通道pipe式sce-mi标准协议接口,具有普适性,同时将banyan网络应用于多fpga数据交换,降低了数据交换延迟,使得系统实现结构简单、功能高效。
18.在具体的实施例中,在banyan网络的调度算法中采用穷尽计算的方法避免阻塞,具体包括:将所有的信元传输按照优先级从大到小的顺序进行排序检查调度,如果优先级低的信元传输路线会与优先级高的信元发生阻塞,则放弃当前传输,选择传输更低一级的信元,直到整个banyan网络没有空余的线路;
19.对banyan网络中的优先级相同的buffer采用随机的方式进行选择,确定每个信元与其他信元产生冲突的路线,根据所述路线确定可能的阻塞结果;
20.将所述可能的阻塞结果计算后存储在fpga板上的bram中。
21.在具体的实施例中,所述多块fpga之中采用时钟树进行时钟同步,所述时钟同步具体包括:当内部时钟驱动不同的寄存器时,采用时钟树的方式使时钟到达不同的寄存器所需的时间不同;同时,在所述多块fpga之间采用所述时钟树的方式以使得所述多块fpga之间的时钟同步。本实施例解决了fpga时钟偏差的问题。
22.在具体的实施例中,所述通过dma方式在所述fpga板上进行pcie数据收发,并利用axi总线结构进行传输。
23.在具体的实施例中,所述sce-mi通道包括对通过所述sce-mi通道的数据进行解包和封装的操作,并建立多个fifo来对通过所述sce-mi通道的数据构建传输通道。
24.在具体的实施例中,所述多块fpga中的数据交换基于banyan网络的数据传输,具体包括:
25.基于banyan网络,将所述多块fpga的数据发送端连接到banyan网络的输入端口,将所述多块fpga的数据接收端连接到banyan网络的输出端口,并控制所述多块fpga的数据按照对应的sce-mi通道分别发送到banyan网络的对应节点中。
26.在具体的实施例中,所述将加速后的数据回传至所述顶层eda算法进行处理,具体包括:
27.将所述多块fpga的数据传回至pcie驱动,pcie驱动收到所述多块fpga回传的数据,对所述回传的数据进行解包再返回给所述顶层eda算法进行处理。
28.在具体的实施例中,所述启用顶层eda算法控制数据的发送和接收,具体包括:
29.利用eda算法控制数据传输从而生成能够被eda算法调度的函数接口,通过所述函数接口控制数据的发送和接收,其中包括将spice软件中的稀疏矩阵运算进行解析,将矩阵数据按照合适的顺序发送给传输单元并且控制矩阵数据传送量的大小。
30.根据本发明的第二方面,提出了一种计算机可读存储介质,其上存储有计算机程序,该计算机程序被计算机处理器执行时实施上述方法。
31.根据本发明的第三方面,提出一种基于banyan网络和多fpga结构的eda硬件加速系统,该系统包括:
32.加速模式选择单元:配置用于用户选择加速模式,所述加速模式包括eda算法加速模式和eda仿真加速模式;
33.数据收发单元:配置用于若选择所述eda算法加速模式:启用顶层eda算法控制数据的发送和接收,并对数据进行批次处理再进行基于sce-mi通道的封装处理;
34.若选择所述eda仿真加速模式:根据用户所设计的待测设计结构以及用户输入的仿真数据,对所述仿真数据进行基于sce-mi通道的封装处理;
35.pcie数据传输单元:配置用于将封装后的数据通过pcie驱动和硬件送入fpga板上的pcie核中,pcie核以dma读取方式将所述封装后的数据通过axi传送协议进行传送,再利用sce-mi进行管理,所述fpga板包括多块fpga;
36.banyan网络与fpga数据交换单元:配置用于基于sce-mi对所述封装后的数据进行解包处理后再通过对应的sce-mi通道发送至banyan网络的对应节点中,再根据信元调度算法将所述封装后的数据发送到多块fpga的与所述节点相对应的接收通道中;
37.数据加速单元:配置用于若选择所述eda算法加速模式:基于所述多块fpga的并行计算对所述封装后的数据进行加速,再将加速后的数据回传至所述顶层eda算法进行处理;
38.若选择所述eda仿真加速模式:利用所述多块fpga将所述封装后的数据与所述待测设计结构进行仿真验证后,生成仿真数据,将所述仿真数据与用户提供的标准验证数据进行对比验证仿真结果。
39.本发明将eda算法加速和仿真加速结合在一个系统内,eda算法加速时启用顶层eda算法控制数据的发送和接收,eda仿真加速时根据用户所设计的待测设计结构以及用户输入的仿真数据;同时采用多通道sce-mi接口进行软硬件数据协同,再使用banyan网络来实现多fpga的数据交换;最后将加速后的数据回传进行处理,将验证数据与仿真数据进行对比获取仿真结果。本方法采用软硬件协同方式对算法和仿真进行加速,实现了eda算法加
速和仿真加速相结合,采用了多通道pipe式sce-mi标准协议接口,具有普适性,同时将banyan网络应用于多fpga数据交换,降低了数据交换延迟,使得系统实现结构简单、功能高效。
附图说明
40.包括附图以提供对实施例的进一步理解并且附图被并入本说明书中并且构成本说明书的一部分。附图图示了实施例并且与描述一起用于解释本发明的原理。将容易认识到其它实施例和实施例的很多预期优点,因为通过引用以下详细描述,它们变得被更好地理解。通过阅读参照以下附图所作的对非限制性实施例所作的详细描述,本技术的其它特征、目的和优点将会变得更明显:
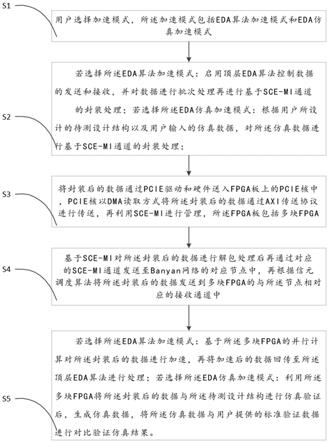
41.图1是本发明的一个实施例的一种基于banyan网络和多fpga结构的eda硬件加速方法的流程图;
42.图2是本发明的一个具体的实施例的eda算法加速模式的架构图;
43.图3是本发明的一个具体的实施例的eda仿真加速模式的架构图;
44.图4是本发明的一个具体的实施例的banyan网络结构图;
45.图5是本发明的一个实施例的一种基于banyan网络和多fpga结构的eda硬件加速系统的框架图。
具体实施方式
46.下面结合附图和实施例对本技术作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅仅用于解释相关发明,而非对该发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与有关发明相关的部分。
47.需要说明的是,在不冲突的情况下,本技术中的实施例及实施例中的特征可以相互组合。下面将参考附图并结合实施例来详细说明本技术。
48.根据本发明的一个实施例的一种基于banyan网络和多fpga结构的eda硬件加速方法,图1示出了根据本发明的实施例的一种基于banyan网络和多fpga结构的eda硬件加速方法的流程图。如图1所示,该方法包括以下步骤:
49.s1:用户选择加速模式,所述加速模式包括eda算法加速模式和eda仿真加速模式;
50.s2:若选择所述eda算法加速模式:启用顶层eda算法控制数据的发送和接收,并对数据进行批次处理再进行基于sce-mi通道的封装处理;
51.若选择所述eda仿真加速模式:根据用户所设计的待测设计结构以及用户输入的仿真数据,对所述仿真数据进行基于sce-mi通道的封装处理;
52.s3:将封装后的数据通过pcie驱动和硬件送入fpga板上的pcie核中,pcie核以dma读取方式将所述封装后的数据通过axi传送协议进行传送,再利用sce-mi进行管理,所述fpga板包括多块fpga;
53.s4:基于sce-mi对所述封装后的数据进行解包处理后再通过对应的sce-mi通道发送至banyan网络的对应节点中,再根据信元调度算法将所述封装后的数据发送到多块fpga的与所述节点相对应的接收通道中;
54.s5:若选择所述eda算法加速模式:基于所述多块fpga的并行计算对所述封装后的
数据进行加速,再将加速后的数据回传至所述顶层eda算法进行处理;
55.若选择所述eda仿真加速模式:利用所述多块fpga将所述封装后的数据与所述待测设计结构进行仿真验证后,生成仿真数据,将所述仿真数据与用户提供的标准验证数据进行对比验证仿真结果。
56.在具体的实施例中,在banyan网络的调度算法中采用穷尽计算的方法避免阻塞,具体包括:将所有的信元传输按照优先级从大到小的顺序进行排序检查调度,如果优先级低的信元传输路线会与优先级高的信元发生阻塞,则放弃当前传输,选择传输更低一级的信元,直到整个banyan网络没有空余的线路;
57.对banyan网络中的优先级相同的buffer采用随机的方式进行选择,确定每个信元与其他信元产生冲突的路线,根据所述路线确定可能的阻塞结果;
58.将所述可能的阻塞结果计算后存储在fpga板上的bram中。
59.在具体的实施例中,所述多块fpga之中采用时钟树进行时钟同步,所述时钟同步具体包括:当内部时钟驱动不同的寄存器时,采用时钟树的方式使时钟到达不同的寄存器所需的时间不同;同时,在所述多块fpga之间采用所述时钟树的方式以使得所述多块fpga之间的时钟同步。本实施例解决了fpga时钟偏差的问题。
60.在具体的实施例中,所述通过dma方式在所述fpga板上进行pcie数据收发,并利用axi总线结构进行传输。
61.在具体的实施例中,所述sce-mi通道包括对通过所述sce-mi通道的数据进行解包和封装的操作,并建立多个fifo来对通过所述sce-mi通道的数据构建传输通道。
62.在具体的实施例中,所述多块fpga中的数据交换基于banyan网络的数据传输,具体包括:
63.基于banyan网络,将所述多块fpga的数据发送端连接到banyan网络的输入端口,将所述多块fpga的数据接收端连接到banyan网络的输出端口,并控制所述多块fpga的数据按照对应的sce-mi通道分别发送到banyan网络的对应节点中。
64.在具体的实施例中,所述将加速后的数据回传至所述顶层eda算法进行处理,具体包括:
65.将所述多块fpga的数据传回至pcie驱动,pcie驱动收到所述多块fpga回传的数据,对所述回传的数据进行解包再返回给所述顶层eda算法进行处理。
66.在具体的实施例中,所述启用顶层eda算法控制数据的发送和接收,具体包括:
67.利用eda算法控制数据传输从而生成能够被eda算法调度的函数接口,通过所述函数接口控制数据的发送和接收,其中包括将spice软件中的稀疏矩阵运算进行解析,将矩阵数据按照合适的顺序发送给传输单元并且控制矩阵数据传送量的大小。
68.在具体的实施例中,本发明的方法所构建的系统主要包含软件侧和硬件侧,软件侧在计算机主机上实现,硬件侧通过多块fpga互联系统实现,两者通过pcie物理接口进行高速通讯。下面利用图2和图3说明本实施例的eda硬件加速系统:
69.图2示出了本发明的一个具体的实施例的eda算法加速模式的架构图;图3示出了本发明的一个具体的实施例的eda仿真加速模式的架构图;本发明包含eda算法加速和仿真加速两个模式,在不同模式下,启用的内部模块不同;
70.软件侧主要包括顶层eda算法控制模块、仿真数据生成和验证模块、sce-mi通道模
块以及pcie驱动。硬件侧主要包括pcie数据收发模块、sce-mi管理模块、banyan网络管理模块、多fpga时钟控制模块以及测试模块;
71.在算法加速模式下,顶层eda算法控制模块被启用,主要功能是通过控制数据传输来生成一个能够被eda算法调度的函数接口;譬如将spice软件中的稀疏矩阵运算进行解析,一是将矩阵数据按照合适的顺序发送给传输模块,二是控制数据传送量的大小;
72.在仿真加速模式下,仿真数据生成和验证模块被启用,该模块作用是根据被测仿真设计,生成对应的测试数据,并接收验证返回数据;
73.软件侧sce-mi通道模块采用了sce-mi2.0协议中的pipe模式,该模块将上级模块传输的数据按照sce-mi协议格式进行打包,并通过多个pipe通道传至pcie驱动模块;此外根据硬件回传的数据,需要将其解包返回给上级处理模块;
74.pcie驱动与硬件侧的pcie收发模块的主要功能是将上级模块的数据打包成pcie tlp数据包的格式,通过物理硬件传送给fpga板,并通过板上的pcie数据收发ip对数据进行解析后通过dma方式在板上进行数据收发,并采用了axi总线结构;
75.硬件侧的sce-mi通道与软件侧通道分别对应,该模块负责在硬件侧对数据进行解包和封装的操作,并通过建立多个fifo来实现数据传输通道。该模块与banyan网络管理模块相连接,由banyan网络管理模块控制各通道的sce-mi数据分别发送到网络的对应节点中。
76.在具体的实施例中,本发明采用时钟树来解决fpga时钟偏差问题,即当内部时钟驱动不同的寄存器时,时钟到达不同的寄存器所需的时间不同。同样地,为确保多片fpga时钟同步,在多fpga之间同样采用时钟树设计。
77.在具体的实施例中,本发明采用banyan网络实现多fpga之间的数据交换。该网络由多个2
×
2交换单元组成一个多级的n输入n输出交换结构。每个2
×
2交换单元内部存在横向连接和交叉连接两种模式,可根据需要切换。本发明将多块fpga的数据发送端连接到banyan网络的输入端口,将多块fpga的数据接收端连接到banyan网络的输出端口。
78.图4示出了本发明的一个具体的实施例的banyan网络结构图,本实施例以8
×
8的banyan网络为例,若fpga1需要将数据发送给fpga7,则第一级第一个交换单元启动横向连接模式,第二级第二个交换单元启动交叉连接模式,第三级第四个交换单元启动交叉连接模式,fpga1发送端到fpga7接收端的发送通道即被打通,完成一次信元传输。
79.banyan网络虽然结构简单,易于拓展,但是内部存在严重阻塞,需要通过合理的算法对信元进行调度。在信元传输过程中,所有的信元同时传输会引起严重阻塞,只有在内部传输中不发生阻塞的信元才能同时传输,为了避免信元丢失,需要在输入口增加buffer。在优选的实施例中,对于n
×
n的banyan架构,将一个输入口的buffer拆分为n个,对应n个输出口,那所有的输入口buffer就有n
×
n个。
80.在优选的实施例中,由于buffer长度有限,为防止数据丢失以及数据的延迟问题,需要给每个buffer队列增加优先级。具体包括:高优先级buffer可以不考虑阻塞情况优先安排传送,低优先级buffer应该考虑到前面所有已决定调度的信元传输路线的阻塞情况;如果会发生阻塞,当前情况应该不考虑传送;每个队列中等待队列长度,以及头信元等待时长将会被作为优先级计算的参数;等待队列长度越长,头信元等待时长越长,则该buffer的传输优先级越高。
81.在优选的实施例中,本发明采用穷尽计算的方法避免阻塞,所有的信元传输优先级大到小顺序进行排序检查调度,如果优先级低的信元传输路线会与优先级高的信元发生阻塞,则放弃当前传输,考虑更低一级的信元,直到整个banyan网络没有空余的线路。同优先级的buffer采用随机选择。在banyan网络结构固定后,每个信元会与其他信元产生冲突的路线也一并确定。
82.下面以图4中确定的banyan网络结构为例,来说明上述采用穷尽计算来避免阻塞的方法:
83.根据输入口和输出口,每个信元传输阻塞可以按照下列公式来确定:
84.[输入口][输出口]={阻塞buffer1,阻塞buffer2,
…
,阻塞buffern}。
[0085]
在图4所示的结构中,如[1][7]buffer的信元,其阻塞buffer分别为:
[0086]
[1][7]={[0][4],[0][5],[0][6],[0][7],[1][0],[1][1],[1][2],[1][3],[1][4],[1][5],[1][6],[2][6],[2][7],[3][6],[3][7],[4][7],[5][7],[6][7],[7][7]}
[0087]
在网络结构确定后,将所有可能的阻塞结果计算后存储在fpga板上的bram中。在信元调度过程中,通过匹配检查对应的阻塞buffer来做相应的调度工作。
[0088]
在具体的实施例中,banyan网络的数据传输时刻存在于多个fpga间的数据交换时。
[0089]
图5示出了本发明的一个实施例的一种基于banyan网络和多fpga结构的eda硬件加速系统的框架图。该系统包括加速模式选择单元501、数据收发单元502、pcie数据传输单元503、banyan网络与fpga数据交换单元504和数据加速单元505。
[0090]
在具体的实施例中,加速模式选择单元501配置用于用户选择加速模式,所述加速模式包括eda算法加速模式和eda仿真加速模式;
[0091]
数据收发单元502配置用于若选择所述eda算法加速模式:启用顶层eda算法控制数据的发送和接收,并对数据进行批次处理再进行基于sce-mi通道的封装处理;
[0092]
若选择所述eda仿真加速模式:根据用户所设计的待测设计结构以及用户输入的仿真数据,对所述仿真数据进行基于sce-mi通道的封装处理;
[0093]
pcie数据传输单元503配置用于将封装后的数据通过pcie驱动和硬件送入fpga板上的pcie核中,pcie核以dma读取方式将所述封装后的数据通过axi传送协议进行传送,再利用sce-mi进行管理,所述fpga板包括多块fpga;
[0094]
banyan网络与fpga数据交换单元504配置用于基于sce-mi对所述封装后的数据进行解包处理后再通过对应的sce-mi通道发送至banyan网络的对应节点中,再根据信元调度算法将所述封装后的数据发送到多块fpga的与所述节点相对应的接收通道中;
[0095]
数据加速单元505配置用于若选择所述eda算法加速模式:基于所述多块fpga的并行计算对所述封装后的数据进行加速,再将加速后的数据回传至所述顶层eda算法进行处理;
[0096]
若选择所述eda仿真加速模式:利用所述多块fpga将所述封装后的数据与所述待测设计结构进行仿真验证后,生成仿真数据,将所述仿真数据与用户提供的标准验证数据进行对比验证仿真结果。
[0097]
本系统将eda算法加速和仿真加速结合在一个系统内,eda算法加速时启用顶层eda算法控制数据的发送和接收,eda仿真加速时根据用户所设计的待测设计结构以及用户
输入的仿真数据;同时采用多通道sce-mi接口进行软硬件数据协同,再使用banyan网络来实现多fpga的数据交换;最后将加速后的数据回传进行处理,将验证数据与仿真数据进行对比获取仿真结果。本系统采用软硬件协同方式对算法和仿真进行加速,实现了eda算法加速和仿真加速相结合,采用了多通道pipe式sce-mi标准协议接口,具有普适性,同时将banyan网络应用于多fpga数据交换,降低了数据交换延迟,使得系统实现结构简单、功能高效。
[0098]
本发明的实施例还涉及一种计算机可读存储介质,其上存储有计算机程序,该计算机程序被计算机处理器执行时实施上文中的方法。该计算机程序包含用于执行流程图所示的方法的程序代码。需要说明的是,本技术的计算机可读介质可以是计算机可读信号介质或者计算机可读介质或者是上述两者的任意组合。
[0099]
本发明将eda算法加速和仿真加速结合在一个系统内,eda算法加速时启用顶层eda算法控制数据的发送和接收,eda仿真加速时根据用户所设计的待测设计结构以及用户输入的仿真数据;同时采用多通道sce-mi接口进行软硬件数据协同,再使用banyan网络来实现多fpga的数据交换;最后将加速后的数据回传进行处理,将验证数据与仿真数据进行对比获取仿真结果。本方法采用软硬件协同方式对算法和仿真进行加速,实现了eda算法加速和仿真加速相结合,采用了多通道pipe式sce-mi标准协议接口,具有普适性,同时将banyan网络应用于多fpga数据交换,降低了数据交换延迟,使得系统实现结构简单、功能高效。
[0100]
以上描述仅为本技术的较佳实施例以及对所运用技术原理的说明。本领域技术人员应当理解,本技术中所涉及的发明范围,并不限于上述技术特征的特定组合而成的技术方案,同时也应涵盖在不脱离上述发明构思的情况下,由上述技术特征或其等同特征进行任意组合而形成的其它技术方案。例如上述特征与本技术中公开的(但不限于)具有类似功能的技术特征进行互相替换而形成的技术方案。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
