1.本技术涉及但不限于语音识别技术,尤指一种直播字幕生成方法及装置和服务端、直播客户端及直播系统。
背景技术:
2.直播经常会有字幕需求,甚至还会有字幕翻译(外文字幕)需求。
3.为了保证字幕的准确度,需要速记员和同声传译这样的全人工实时字幕如中英文字幕输入来实现直播中字幕的生成。这种方式虽然能更好地保证生成的字幕的准确性,但是实时性不能满足直播的需求。
4.在一些相关技术中,也可以使用语音识别技术自动为用户的视频生成字幕,但是,不能保证生成的字幕的准确度,特别是对于直播场景,机器语音识别技术的准确率还有待提高。
技术实现要素:
5.本技术提供一种直播字幕生成方法及装置和服务端、直播客户端及直播系统,能够保证生成的字幕的准确度和实时性。
6.本发明实施例提供了一种直播字幕生成方法,包括:
7.服务端将采集到的直播视频推送给接收端,并对采集到的直播音频进行语音识别获得语音识别结果;
8.根据语音识别结果生成直播视频的字幕;
9.将生成的字幕推送给接收端,以使所述接收端对所述直播视频和所述字幕进行组合得到带字幕的直播视频。
10.在一种示例性实例中,所述将采集到的直播视频推送给接收端,包括:
11.通过内容分发网络cdn将所述采集到的直播视频推送给所述接收端。
12.在一种示例性实例中,所述将生成的字幕推送给接收端之前,还包括:
13.根据预先设置的重要词语或历史校准结果,对所述生成的直播视频的字幕进行校准。
14.在一种示例性实例中,所述语音识别结果的每个音节包括一个或多个识别结果;
15.所述根据语音识别结果生成直播视频的字幕,包括:
16.对于包括一个识别结果的音节,将该识别结果作为该音节的语音识别结果;
17.对于包括多个识别结果的音节,将概率最大的识别结果作为该音节的语音识别结果,或者,手动选择一个识别结果作为该音节的语音识别结果;
18.将确定的语音识别结果组成所述直播视频的字幕。
19.在一种示例性实例中,所述方法还包括:
20.将所述采集到的直播音频翻译成所需外文字幕;
21.对生成的直播视频的外文字幕进行校准;
22.所述将生成的字幕推送给接收端还包括:将生成的外文字幕推送给所述接收端。
23.在一种示例性实例中,所述将采集到的直播音频翻译成所需外文字幕,包括:
24.基于所述直播音频的语音,翻译成所述所需外文;
25.或者,基于所述语音识别结果翻译成所述所需外文。
26.本技术还提供了一种计算机可读存储介质,存储有计算机可执行指令,所述计算机可执行指令用于执行上述任一项所述的直播字幕生成方法。
27.本技术又提供了一种实现直播字幕生成的设备,包括存储器和处理器,其中,存储器中存储有以下可被处理器执行的指令:用于执行上述任一项所述的直播字幕生成方法的步骤。
28.本技术再提供了一种直播字幕生成方法,包括:
29.接收端接收来自服务端的直播视频和字幕;
30.基于时间戳同步接收到的直播视频和字幕,合并同步后的直播视频和字幕得到带字幕的视频;
31.将得到的带字幕的视频展示给用户。
32.在一种示例性实例中,当所述字幕晚于所述直播视频到达所述接收端,还包括:
33.所述接收端根据预先配置信息对接收到的字幕进行处理;
34.其中,所述预先配置信息包括:丢弃所述字幕,或显示延迟到达的所述字幕。
35.本技术又提供了一种计算机可读存储介质,存储有计算机可执行指令,所述计算机可执行指令用于执行上述的直播字幕生成方法。
36.本技术再提供了一种实现直播字幕生成的设备,包括存储器和处理器,其中,存储器中存储有以下可被处理器执行的指令:用于执行上述的直播字幕生成方法的步骤。
37.本技术还提供了一种服务端,包括:直播视频处理模块、语音识别模块、字幕生成模块、字幕推送模块;其中,
38.直播视频处理模块,设置为将采集到的直播视频推送给接收端;
39.语音识别模块,设置为对采集到的直播音频进行语音识别获得语音识别结果;
40.字幕生成模块,设置为根据语音识别结果生成直播视频的字幕;
41.字幕推送模块,设置为将生成的字幕推送给接收端,以使所述接收端对所述直播视频和所述字幕进行组合得到带字幕的直播视频。
42.在一种示例性实例中,还包括:第一校准模块,设置为根据预先设置的重要词语或历史校准结果,对所述生成的直播视频的字幕进行校准。
43.在一种示例性实例中,所述语音识别结果的每个音节包括一个或多个识别结果;
44.所述字幕生成模块设置为:对于包括一个识别结果的音节,将该识别结果作为该音节的所述语音识别结果;对于包括多个识别结果的音节,将概率最大的识别结果作为该音节的语音识别结果,或者,手动选择一个识别结果作为该音节的语音识别结果;将确定的语音识别结果组成所述直播视频的字幕。
45.在一种示例性实例中,还包括:翻译模块、第二校准模块;其中,
46.翻译模块,设置为将所述采集到的直播音频翻译成所需外文字幕;
47.第二校准模块,设置为对所述生成的直播视频的外文字幕进行校准;相应地,所述字幕推送模块还设置为:将外文字幕推送给所述接收端。
48.本技术又提供了一种直播客户端,包括:接收模块、合并处理模块、显示模块;其中,
49.接收模块,设置为接收来自服务端的直播视频和字幕;
50.合并处理模块,设置为基于时间戳同步接收到的直播视频和字幕,合并同步后的直播视频和字幕得到带字幕的视频;
51.显示模块,设置为将得到的带字幕的视频展示给用户。
52.在一种示例性实例中,当所述字幕晚于所述直播视频到达所述接收端;所述显示模块,设置为:
53.根据预先配置信息对接收到的字幕进行处理;
54.其中,所述预先配置信息包括:丢弃所述字幕,或显示延迟到达的所述字幕。
55.本技术还提供了一种直播系统,包括:用于获取直播现场的直播视频和直播音频的采集端、处理服务器、一个以上接收端;其中,
56.处理服务器包括上述任一项所述的服务端,接收端包括上述的直播客户端。
57.本技术实施例巧妙地利用直播本身的时间差,利用直播视频的传输过程,同时对直播音频进行处理以快速生成对应的字幕,保证了生成的字幕的准确度和实时性。
58.进一步地,通过对生成的直播视频的字幕的校准,进一步提高了校准的准确度。
59.本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在说明书、权利要求书以及附图中所特别指出的结构来实现和获得。
附图说明
60.附图用来提供对本技术技术方案的进一步理解,并且构成说明书的一部分,与本技术的实施例一起用于解释本技术的技术方案,并不构成对本技术技术方案的限制。
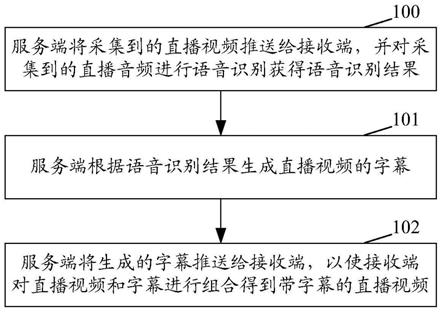
61.图1为本技术一种实施例中直播字幕生成方法的流程示意图;
62.图2为本技术另一种实施例中直播字幕生成方法的流程示意图;
63.图3为本技术实施例中服务端的组成结构示意图;
64.图4为本技术实施例中直播客户端的组成结构示意图;
65.图5为本技术实施例中直播系统的组成架构示意图。
具体实施方式
66.为使本技术的目的、技术方案和优点更加清楚明白,下文中将结合附图对本技术的实施例进行详细说明。需要说明的是,在不冲突的情况下,本技术中的实施例及实施例中的特征可以相互任意组合。
67.在本技术一个典型的配置中,计算设备包括一个或多个处理器(cpu)、输入/输出接口、网络接口和内存。
68.内存可能包括计算机可读介质中的非永久性存储器,随机存取存储器(ram)和/或非易失性内存等形式,如只读存储器(rom)或闪存(flash ram)。内存是计算机可读介质的示例。
69.计算机可读介质包括永久性和非永久性、可移动和非可移动媒体可以由任何方法
或技术来实现信息存储。信息可以是计算机可读指令、数据结构、程序的模块或其他数据。计算机的存储介质的例子包括,但不限于相变内存(pram)、静态随机存取存储器(sram)、动态随机存取存储器(dram)、其他类型的随机存取存储器(ram)、只读存储器(rom)、电可擦除可编程只读存储器(eeprom)、快闪记忆体或其他内存技术、只读光盘只读存储器(cd-rom)、数字多功能光盘(dvd)或其他光学存储、磁盒式磁带,磁带磁盘存储或其他磁性存储设备或任何其他非传输介质,可用于存储可以被计算设备访问的信息。按照本文中的界定,计算机可读介质不包括非暂存电脑可读媒体(transitory media),如调制的数据信号和载波。
70.在附图的流程图示出的步骤可以在诸如一组计算机可执行指令的计算机系统中执行。并且,虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。
71.本技术发明人在对直播处理的研究中发现,直播视频流通常采用的内容分发网络(cdn,content delivery network)来做分发,和实时流量相比,不同的直播方案到达用户端会有10~30秒以上的时间差。本技术发明人提出,如果能在这个时间窗口内使用语音识别技术对语音流进行处理来生成字幕,那么,能够保证生成的字幕的准确度和实时性。
72.图1为本技术一种实施例中直播字幕生成方法的流程示意图,如图1所示,在的同时,包括:
73.步骤100:服务端将采集到的直播视频推送给接收端,并对采集到的直播音频进行语音识别获得语音识别结果。
74.在一种示例性实例中,可以通过cdn将采集到的直播视频推送给接收端。服务端为可以用于处理接收到的实时音视频信号的服务器如流媒体服务器,接收端为可以用于播放带字幕实时音视频的直播客户端。
75.在一种示例性实例中,步骤100之前,还可以包括:
76.记录(如采用作为采集端的高清摄像机)直播现场的视频信息;采集(如采用作为采集端的高清麦克风)直播现场的音频信息。进一步地,还可以对采集到的音频信息进行处理以去除杂音。
77.需要说明的是,步骤100中的直播视频中包括有音频信息。
78.在一种示例性实例中,对采集到的直播音频进行语音识别获得语音识别结果,可以包括:
79.基于语音识别技术,对采集到的音频进行语音识别得到语音识别结果,其中,语音识别出的语音识别结果的每个音节可以包括一个或多个识别结果。
80.在一种示例性实例中,获得的语音识别结果为:超过预设置信区间的识别结果。
81.通过步骤100可以看出,本技术实施例巧妙地利用直播本身的时间差,利用直播视频的传输过程,同时对直播音频进行处理以快速生成对应的字幕。
82.步骤101:服务端根据语音识别结果生成直播视频的字幕。
83.在一种示例性实例中,步骤101可以包括:
84.对于包括一个识别结果的语音识别结果的音节,将该识别结果作为该音节的语音识别结果;对于包括多个识别结果的语音识别结果的音节,将可能性即概率最大的识别结果作为该音节的语音识别结果,或者,手动选择一个识别结果作为该音节的默认的语音识别结果;
85.将确定的语音识别结果组成直播视频的字幕。
86.通过步骤101对语音识别后的识别结果进行了校准,纠正了识别的错误或确定了更准确的识别结果,保证了生成的字幕的高质量,也就是说提升了生成的字幕的准确度。
87.在实际应用场景中,以完成对一句话的语音识别为例,采用相关技术中语音识别技术可以保障大约90%以上的准确率,再通过本技术实施例的纠正识别错误或确定更准确识别结果的步骤,完成了对语音识别结果的快速校准,可以将准确率提升到99%以上。以直播视频流到达用户端大概有10~30秒以上的时间差为例,那么,如果本技术实施例预留出10秒的处理时间窗口来实现对语音识别结果的校准是足够的。在实际应用中,处理时间窗口的大小可以通过网络测试给出。
88.步骤102:服务端将生成的字幕推送给接收端,以使接收端对直播视频和字幕进行组合得到带字幕的直播视频。
89.在一种示例性实例中,服务端立即将生成的字幕即校准完成后字幕推送给接收端,以使接收端基于时间戳同步后合并接收到的直播视频和字幕,得到带字幕的视频。
90.在一种示例性实例中,本技术实施例中直播字幕生成方法,在将生成的字幕推送给接收端之前,还可以进一步包括:
91.根据预先设置的重要词语或历史校准结果,对生成的直播视频的字幕进行校准。这样,进一步提高了校准的准确度,也提升了校准速度。举个例子来看,对于新词或者普通话不标准的人,对语音表达出的某些词语会一直存在识别错误,比如语音包括“马老师刚提出五新”,其中的“五新”这个词不太常见,很大可能会被识别成“五星”,那么,通过本技术实施例中手动输入正确的语音识别结果即“五新”,这样,后续的校准就都可以将该手动输入的重要词语作为可选项,以快速完成校准过程。或者,预先设置的重要词语,即提前输入“五新”,这样,“五新”的权重在这次直播中就会高于“五星”,这样也达到了提高准确性的作用。
92.在一种示例性实例中,本技术实施例的直播字幕生成方法,还可以包括:
93.服务端将采集到的直播音频翻译成所需外文字幕;
94.对生成的直播视频的外文字幕进行校准;
95.相应地,步骤102还包括:将生成的外文字幕推送给接收端。
96.在一种示例性示例中,服务端将采集到的直播音频翻译成所需外文字幕,可以包括:
97.直接基于直播音频的语音,翻译成所需外文;或者,基于语音识别结果翻译成所需外文。
98.在一种示例性实例中,外文可以包括但不限于:中文、英文、日文、法文、德文等。
99.通过本技术直播字幕生成方法,保证了生成的字幕的准确度和实时性。
100.本技术还提供一种计算机可读存储介质,存储有计算机可执行指令,所述计算机可执行指令用于执行上述任一项的直播字幕生成方法。
101.本技术再提供一种实现直播字幕生成的设备,包括存储器和处理器,其中,存储器中存储有以下可被处理器执行的指令:用于执行上述任一项所述的直播字幕生成方法的步骤。
102.图2为本技术另一种实施例中直播字幕生成方法的流程示意图,如图2所示,包括:
103.步骤200:接收端接收来自服务端的直播视频和字幕。
104.步骤201:接收端基于时间戳同步接收到的直播视频和字幕,合并同步后的直播视频和字幕得到带字幕的视频;
105.步骤202:将得到的带字幕的视频展示给用户。
106.通过本技术直播字幕生成方法,保证了生成的字幕的准确度和实时性。
107.在一种示例性实例中,如果字幕晚于直播视频到达接收端,比如由于在服务端花费了过长的校准时间,那么,直播字幕生成方法还可以包括:
108.接收端根据预先配置信息对接收到的字幕进行处理,在一种示例性实例中,预先配置信息可以包括如:丢弃字幕即不显示延迟到达的字幕,或直接显示延迟到达的字幕等。
109.本技术还提供一种计算机可读存储介质,存储有计算机可执行指令,所述计算机可执行指令用于执行图2所示任一项的直播字幕生成方法。
110.本技术再提供一种实现直播字幕生成的设备,包括存储器和处理器,其中,存储器中存储有以下可被处理器执行的指令:用于执行图2所示任一项所述的直播字幕生成方法的步骤。
111.在一种示例性实例中,对于带字幕的视频内容,可以根据用户的设置对某些信息进行特别的显示,比如:特别显示与视频主题或内容关系紧密的关键字,如高亮显示、花体字显示等。
112.在一种示例性实例中,字幕的展现形式、语言等是可以由用户来选择的,从而建立了用户与系统之间的反馈机制。
113.图3为本技术一种实施例中服务端的组成结构示意图,如图3所示,至少包括:直播视频处理模块、语音识别模块、字幕生成模块、字幕推送模块;其中,
114.直播视频处理模块,设置为将采集到的直播视频推送给接收端;
115.语音识别模块,设置为对采集到的直播音频进行语音识别获得语音识别结果;
116.字幕生成模块,设置为根据语音识别结果生成直播视频的字幕;
117.字幕推送模块,设置为将生成的字幕推送给接收端,以使所述接收端对所述直播视频和所述字幕进行组合得到带字幕的直播视频。
118.在一种示例性实例中,直播视频处理模块可以设置为:通过cdn将采集到的直播视频推送给接收端。服务端为可以用于处理接收到的实时音视频信号的服务器如流媒体服务器。
119.在一种示例性实例中,对采集到的音频进行语音识别得到语音识别结果;其中,语音识别结果的每个音节,包括一个或多个识别结果。
120.本技术实施例中,服务端巧妙地利用直播本身的时间差,利用直播视频的传输过程,同时对直播音频进行处理以快速生成对应的字幕。
121.在一种示例性实例中,字幕生成模块可以设置为:对于包括一个识别结果的语音识别结果的音节,将该识别结果作为该音节的语音识别结果;对于包括多个识别结果的语音识别结果的音节,将概率最大的识别结果作为该音节的语音识别结果,或者,手动选择一个识别结果作为该音节的默认的语音识别结果;将确定的语音识别结果组成直播视频的字幕。
122.本技术实施例中,服务端对语音识别后的识别结果进行了校准,纠正了识别的错误或确定了更准确的识别结果,保证了生成的字幕的高质量,也就是说提升了生成的字幕
的准确度。
123.在一种示例性实例中,服务端还可以包括:第一校准模块;
124.第一校准模块,设置为根据预先设置的重要词语或历史校准结果,对生成的直播视频的字幕进行校准。
125.在一种示例性实例中,服务端还可以包括:翻译模块;
126.翻译模块,设置为将采集到的直播音频翻译成所需外文字幕;服务端还可以包括:第二校准模块,设置为对生成的直播视频的外文字幕进行校准;相应地,字幕推送模块,还设置为将外文字幕推送给接收端。
127.在一种示例性实例中,将采集到的直播音频翻译成所需外文字幕包括:基于直播音频的语音,翻译成所需外文;或者,基于语音识别结果翻译成所需外文。
128.通过本技术服务端,保证了生成的字幕的准确度和实时性。
129.图4为本技术另一种实施例中直播客户端的组成结构示意图,如图4所示,至少包括:接收模块、合并处理模块、显示模块;其中,
130.接收模块,设置为接收来自服务端的直播视频和字幕;
131.合并处理模块,设置为基于时间戳同步接收到的直播视频和字幕,合并同步后的直播视频和字幕得到带字幕的视频;
132.显示模块,设置为将得到的带字幕的视频展示给用户。
133.在一种示例性实例中,如果字幕晚于直播视频到达接收端,比如由于在服务端花费了过长的校准时间,那么,显示模块设置为:
134.根据预先配置信息对接收到的字幕进行处理,在一种示例性实例中,预先配置信息可以包括如:丢弃字幕即不显示延迟到达的字幕(即仅显示视频),或直接显示延迟到达的字幕等。
135.通过本技术直播客户端,保证了生成的字幕的准确度和实时性。
136.本技术还提供一种直播系统,包括:用于获取直播现场的直播视频和直播音频的采集端、处理服务器、一个以上接收端;其中,处理服务器包括上述任一项所述的服务端,接收端包括上述任一项所述的直播客户端。
137.图5为本技术一个实施例中直播系统的组成架构示意图,如图5所示,本实施例中,直播系统包括采集端、处理服务器、接收端(图5中仅示出一个接收端);其中,
138.采集端,用于获取直播现场的直播视频和直播音频;
139.处理服务器包括直播视频处理模块,直播视频处理模块包括:视频分发模块、cdn;其中,视频分发模块,设置为通过cdn将采集到的直播视频推送给接收端。
140.本实施例中,网络直播通过cdn分发过程,由于存在网络延迟,相比于实时流量有10~30秒以上的延迟。
141.处理服务器还包括:语音识别模块、字幕生成模块、第一校准模块、翻译模块、第二校准模块、字幕推送模块;其中,
142.语音识别模块,设置为对采集到的直播音频进行语音识别获得语音识别结果,更具体地,对采集到的音频进行语音识别得到语音识别结果,对于语音识别出的每个音节,可以包括一个或多个识别结果;
143.字幕生成模块,设置为根据语音识别结果生成直播视频的字幕,更具体地,对于包
括一个识别结果的语音识别结果的音节,将该识别结果作为该音节的语音识别结果;对于包括多个识别结果的语音识别结果的音节,将可能性最大的识别结果或者手动选择一个识别结果作为该音节的默认的语音识别结果;将确定的语音识别结果组成直播视频的字幕;
144.第一校准模块,设置为根据预先设置的重要词语或历史校准结果,对生成的直播视频的字幕进行校准;
145.翻译模块,将基于直播音频的语音,翻译成所需外文字幕;
146.第二校准模块,对生成的直播视频的外文字幕进行校准;
147.字幕推送模块,设置为将校准后的字幕和外文字幕推送给接收端。
148.本实施例中,对直播音频流的处理需要9~29秒编辑时间,推送得到的字幕和外文字幕大概有1秒网络延迟。
149.本实施例中的直播系统,利用了网络直播通过cdn分发过程,由于存在网络延迟,相比于实时流量有10~30秒以上的延迟,利用这个时间差,本技术实施例结合语音识别和校准,实现了在直播视频传播的同时完成字幕的获取,从而保证在视频到达接收端之前(至少是同时)字幕也达到接收端,让接收端的用户支撑了直播实时字幕的需求;同时,再结合机器翻译过程,让有一定外文基础的人支持直播外文同传字幕,极大降低了国际化直播的门槛。通过本技术直播系统,保证了生成的字幕的准确度和实时性。
150.虽然本技术所揭露的实施方式如上,但所述的内容仅为便于理解本技术而采用的实施方式,并非用以限定本技术。任何本技术所属领域内的技术人员,在不脱离本技术所揭露的精神和范围的前提下,可以在实施的形式及细节上进行任何的修改与变化,但本技术的专利保护范围,仍须以所附的权利要求书所界定的范围为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
