一种基于去噪任务辅助的sar图像目标识别方法
技术领域
1.本发明属于合成孔径雷达(synthetic aperture radar,sar)图像解译领域,具体涉及一种基于去噪任务辅助的深度注意分类网络,用以实现sar图像目标识别。
背景技术:
2.合成孔径雷达因其具有全天时、全天候、作用距离远,且能在距离向和方位向上获取较高的分辨率等优势,已成为作战场景的情报信息获取的重要工具。sar图像解译是合成孔径雷达图像信号处理的核心问题。自动目标识别(automatic target recognition,atr)是sar图像解译的重要应用之一。一般地,一个标准的sar atr系统可分为三个阶段:检测、鉴别、分类。检测与鉴别主要完成复杂地物场景中的目标分割,而分类阶段是完成目标特征提取与类别判定。在当今研究中,atr技术的研究主要集中在分类阶段。
3.随着作战环境的复杂化,sar图像解译技术的发展已成为限制sar图像实际应用的瓶颈。由于目标的粗糙表面、环境的电磁反射、sar图像的相干成像原理以及敌方的电子干扰,sar传感器在信息捕获过程中难免会受到噪声影响。这对后续的目标特征提取带来了一定难度,进而影响了目标的检测、识别性能。基于深度学习理论的atr模型已成为现阶段sar atr的主流。然而,深度学习模型噪声鲁棒性较差,这就无法满足复杂真实场景应用需求。解决这一问题最常见的方法是利用传统的去噪技术对图像做预处理,然后将预处理后的图像用于目标特征提取与分类。但这些传统的去噪方法通常存在降低sar图像的空间分辨率、计算量大、对参数敏感、需要先验知识或统计特性等缺点。近年来,各种基于深度学习思想的sar图像去噪算法被相继提出,并取得令人满意的效果。与传统的去噪方法相比,基于深度学习网络的去噪方法无需通过先验知识构建噪声模型,并且可以直接用训练数据集去更新网络参数。
4.为了改善在强散斑噪声条件下的sar图像目标识别性能,本发明提出了一种基于去噪任务辅助的深度注意分类网络,用于实现sar图像自动目标识别。
技术实现要素:
5.本发明针对上述sar图像目标识别中存在的问题,提出了一种基于去噪任务辅助的深度注意分类网络的sar图像目标识别方法,通过去噪子网络可完成图像去噪预处理,为分类子网络的稳健特征的提取提供保障。
6.本发明为解决上述技术问题所采用的技术方案为:将采集到的噪声污染图像首先通过去噪子网络完成图像去噪预处理。具体来说,在去噪子网络中设计基于空洞卷积的多尺度特征提取层,从而可通过联系图像上下文实现噪声平滑效果。另外,考虑到噪声的稀疏属性,采用残差学习思想学习噪声,相比于直接学习原始图像具有更高的学习效率。然后,将经过去噪网络预处理的sar图像输入到深度注意分类网络进行自主特征提取与目标分类。具体来讲,在深度注意分类网络中,通过嵌入注意力思想来指导模型在特征空间以及通道与空间交互上完成sar图像目标特征提取与自适应加权,进而改善自动目标识别精度。
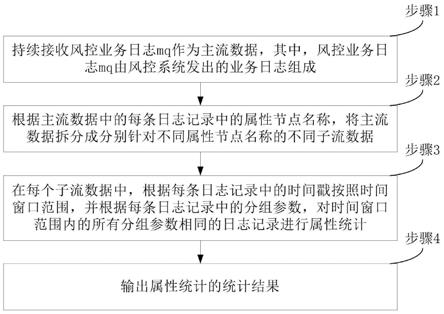
7.本发明技术方案为一种基于去噪任务辅助的sar图像目标识别方法,该方法步骤如下:
8.步骤1:采集训练sar图像样本对{x,y}={(x1,y1),(x2,y2)......(x
n
,y
n
)},其中x表示相对于y干净的图像,y表示受散斑噪声污染的图像,n是图像样本数量;sar图像中的散斑噪声是一种乘性噪声;受乘性噪声污染后的sar图像描述为:
9.y=x
·
n
s
10.其中,n
s
是散斑噪声;
11.因为sar切片图像大小不一且不便于噪声学习,因此对sar图像进行裁剪;
12.步骤2:建立去噪子网络,通过该子网络对受散斑噪声污染的sar图像进行去噪预处理;
13.步骤2.1:通过多尺度特征提取层完成sar图像噪声平滑;考虑到网络宽度的增加会导致模型的参数量增大,采用空洞卷积来实现多尺度特征提取,空洞卷积的卷积核尺寸计算公式为:
14.k'=k (k
‑
1)(d
‑
1)
15.其中,k为标准卷积核的大小,d为空洞率,谓空洞率表示相邻两元素间的间隔;
16.步骤2.2:采用深度特征融合技术进行多尺度特征融合,融合后的特征为:
17.f
new
=con(f
scale1
f
scale2
)
18.其中,f
scale1
和f
scale2
表示多尺度特征,con(
·
)表示特征图沿通道维融合;
19.步骤2.3:将融合后的特征图连续输入到两个基本残差结构单元中完成剩余散斑噪声提取,通过此结构学习噪声信息为:
20.f
noise
=f
x
f
x_f
21.其中,f
x
表示未通过残差结构的sar图像目标特征,f
x_f
表示通过残差结构后的sar图像目标特征;
22.步骤2.4:将特征图输入到嵌入的注意力单元来进一步实现噪声特征提取;
23.步骤2.5:采用均方差损失函数来训练去噪任务网络模型,损失函数定义如下:
[0024][0025]
其中,w
×
h表示sar图像的大小,net(
·
)表示网络映射函数,上标w,h表示图像中对应的位置,y
w,h
,x
w,h
表示对应图像中位置为w,h的像素值;
[0026]
步骤2.6:从受噪声污染的sar图像中减去学习的噪声信息,可得到去噪后的sar图像;
[0027]
步骤3:建立深度注意分类网络,基于该深度注意分类网络的目标特征提取与类别判定;
[0028]
步骤3.1:将通过去噪子网络后的sar图像输入到卷积神经网络中完成特征提取;
[0029]
步骤3.2:有些特征信息冗余或甚至对识别不利,传统的卷积神经网络在卷积过程中并不能区分特征的重要性;因此,对目标特征进行自适应加权,方法如下:
[0030]
在特征加权处理过程中最大池化与平均池化分别表述如下:
[0031]
[0032][0033]
其中,p1和p2分别表示池化窗的长和宽,α(i,j)表示特征图中第i行第j列的元素;
[0034]
步骤3.3:为了对sar图像特征进行自适应增强与抑制,首先将提取的目标特征输入到第一个特征注意分支,以实现特征图的空间注意;
[0035]
步骤3.4:空间注意力在于寻找特征图中最重要的部分,没有考虑空间与通道的依赖性,从而限制了提取目标鉴别特征的能力;将提取的目标特征输入到第二个特征注意分支,运用维度旋转、维度压缩、卷积操作,实现通道c与空间w的跨维度交互;
[0036]
步骤3.5:将提取的目标特征输入到第三个特征注意分支,同样运用维度旋转、维度压缩、卷积操作,实现通道c与空间h的跨维度交互;
[0037]
步骤3.6:通过对步骤3.3、步骤3.4及步骤3.5所得的特征进行平均运算,可实现特征图融合;
[0038]
步骤3.7:采用交叉熵损失函数来训练分类网络模型,损失函数定义如下:
[0039][0040]
其中,x
(i)
表示训练集中第i个张量,l
(i)
表示第i个标签值,ω表示网络参数权值,p(l
(i)
|x
(i)
;ω)表示第i个张量被判定为标签l
(i)
的概率;
[0041]
步骤4:sar图像目标识别;
[0042]
步骤4.1:采集sar目标测试图像,并完成图像裁剪预处理;
[0043]
步骤4.2:将sar测试图像通过去噪子网络完成图像去噪处理;
[0044]
步骤4.3:将经过去噪子网络去噪后的sar测试图像输入到深度注意分类网络中实现目标特征提取与类别判定。
[0045]
综上所述,本发明的有益效果是:
[0046]
本发明设计了一种基于去噪子任务辅助的深度注意力分类网络,用于sar图像目标识别。与目前广泛应用的sar目标识别模型相比,通过去噪子网络模型可以对噪声进行预处理,进而为目标识别的稳健特征提取提供保障。与单一的残差网络相比,本发明的去噪子网络可以通过不同的感受野来联系上下文信息,并在sar图像噪声估计中引入注意力机制,从而具有更好的噪声估计能力。在分类模型中,通过在特征空间以及通道与空间的交互层面上嵌入注意力思想实现对sar图像鉴别特征的自适应加权,进而改善目标识别性能。
附图说明
[0047]
图1为本发明的结构图;
[0048]
图2为跨维度交互的结构图;
[0049]
图3为不同算法的去噪效果对比图;
[0050]
表1为mstar标准数据集十类目标数据的详细情况;
[0051]
表2为本发明的去噪算法与其他两种去噪算法的性能比较;
[0052]
表3为去噪前后识别率的比较;
[0053]
表4为不同识别网络在噪声环境下的性能比较。
具体实施方式
[0054]
以下将针对本文的发明内容结合附图和具体实施步骤进行详细阐述,以便于更好地体现出本发明的技术要点。本发明是一种基于去噪任务辅助的深度注意分类网络的sar图像目标识别方法,实施步骤流程如图1所示,各步骤具体按照以下方式实施:
[0055]
步骤1:采集训练sar图像样本对{x,y}={(x1,y1),(x2,y2)......(x
n
,y
n
)},其中x表示相对干净的图像,y表示受散斑噪声污染的图像,n表示sar图像样本数。sar图像中的散斑噪声是一种乘性噪声。因此,受乘性噪声污染后的sar图像可描述为:
[0056]
y=x
·
n
s
[0057]
其中,n
s
是散斑噪声。而sar图像中的散斑噪声一般被认为是服从均值为1,方差为1/l的gamma分布,当l越小时,噪声方差越大,sar图像受污染越严重,其概率密度函数为:
[0058][0059]
其中,l≥1表示等效视数,n≥0,γ(
·
)表示gamma函数;
[0060]
步骤1.1:为了统一图像的大小且便于学习背景噪声,将所有sar图像裁剪为100
×
100像素的感兴趣区域;
[0061]
步骤2:对受散斑噪声污染的sar图像进行去噪预处理;
[0062]
步骤2.1:采用基于空洞卷积的多尺度特征提取层实现噪声平滑,其中采用了两个分支结构(上面为分支1,下面为分支2),分支1和分支2都设置了两层卷积层,标准卷积核的尺寸为3
×
3,分支1中的空洞率分别为1、2,分支2中的空洞率分别为3、4。空洞卷积的卷积核尺寸计算公式为:
[0063]
k'=k (k
‑
1)(d
‑
1)
[0064]
其中,k为标准卷积核的大小,d为空洞率;
[0065]
步骤2.2:在通道层进行特征拼接以完成多尺度特征融合,融合后的特征为:
[0066]
f
new
=con(f
scale1
f
scale2
)
[0067]
其中,f
scale1
和f
scale2
表示多尺度特征,con(
·
)表示特征图沿通道维融合;
[0068]
步骤2.3:将步骤2.2中提取的多尺度特征连续输入到两个基本的残差结构单元中以学习散斑噪声信息。最近有研究表明,使用较小的卷积核(如3
×
3或5
×
5)且步长设置为1的网络具有较好的表现效果。因此,将一个残差单元中的卷积核都设置为3
×
3大小,另一个残差单元还添加了一层卷积核为1
×
1的卷积层,用于平滑特征。通过残差结构单元可学习的噪声信息如下:
[0069]
f
noise
=f
x
f
x_f
[0070]
其中,f
x
表示未通过残差结构的sar图像目标特征,f
x_f
表示通过残差结构后的sar图像目标特征;
[0071]
步骤2.4:将学习的噪声特征输入到嵌入的注意力单元,可生成特征注意力权重,将产生的通道注意力权重与提取的噪声特征相乘,可以进一步有效地估计出噪声特征;
[0072]
步骤2.5:以上所提出的去噪子网络是一种从受噪声污染的图像到噪声估计图像的映射,因此,采用了均方差(mse)损失函数训练模型,其定义如下:
[0073]
[0074]
其中,w
×
h表示sar图像的大小,net(
·
)表示网络映射函数;
[0075]
步骤2.6:从受噪声污染的sar图像中减去估计噪声信息,可得到去噪后的sar图像;
[0076]
步骤3:基于深度注意分类网络的目标特征提取与类别判定;
[0077]
步骤3.1:将经过去噪子网络处理后的sar图像输入到卷积神经网络中完成特征提取;
[0078]
步骤3.2:通常目标只会在图像中占据一部分区域,而在传统的卷积操作中卷积核并不知道图像哪块区域最重要。这也就是说,传统卷积核提取特征能力有限且所提取的特征中包含冗余信息或甚至对识别不利。因此,对特征进行自适应加权是有意义的。在特征加权处理过程中,最大池化与平均池化是最重要的操作,二者可分别表述如下:
[0079][0080][0081]
其中,p1和p2分别表示池化窗的长和宽,α(i,j)表示特征图中第i行第j列的元素;
[0082]
步骤3.3:对特征进行自适应加权的结构图如图2所示。首先,将提取的目标特征输入到第一个特征注意分支,为了保证另外两维所形成特征图的信息,运用最大池化和平均池化在通道维度上进行压缩后的特征图大小为2
×
h
×
w,并运用卷积层提取注意力权重以实现特征图的空间注意;
[0083]
步骤3.4:将提取的目标特征输入到第二个特征注意分支。先将三维特征图沿w轴逆时针旋转90
°
后得到维度为h
×
c
×
w的χ2,为了保证另外两维所形成特征图的信息,运用最大池化和平均池化在第一维度上进行压缩后的特征图大小为2
×
c
×
w,运用卷积层提取注意力权重以实现通道c与空间w的跨维度交互,最后沿w轴顺时针旋转90
°
以恢复成原始维度;
[0084]
步骤3.5:将提取的目标特征输入到第三个特征注意分支。先将三维特征图沿h轴逆时针旋转90
°
后得到维度为w
×
h
×
c的χ3,为了保证另外两维所形成特征图的信息,运用最大池化和平均池化在第一维度上进行压缩后的特征图大小为2
×
h
×
c,运用卷积层提取注意力权重以实现通道c与空间h的跨维度交互,最后沿h轴顺时针旋转90
°
以恢复成原始维度;
[0085]
步骤3.6:通过对步骤3.3、步骤3.4及步骤3.5所得的特征进行平均运算,可实现特征图融合;
[0086]
步骤3.7:采用交叉熵损失函数来训练分类网络模型,损失函数定义如下:
[0087][0088]
其中,x
(i)
表示训练集中第i个张量,l
(i)
表示第i个标签值;
[0089]
步骤4:sar图像目标识别;
[0090]
步骤4.1:采集sar目标测试图像,并完成图像裁剪预处理;
[0091]
步骤4.2:将sar测试图像通过去噪子网络完成图像去噪处理;
[0092]
步骤4.3:将经过去噪子网络去噪后的sar测试图像输入到深度注意分类网络中实现目标特征提取与类别判定。
[0093]
1.仿真条件:
[0094]
本仿真实验使用实测的mstar标准数据集,该数据集中包含了在15
°
和17
°
俯仰角下采集的十类地面军事目标,每类目标的类别编号及样本数如表1所示。实验平台为win10 64位计算机系统,16gb内存,gpu型号为nvidia geforce rtx 2060,pycharm软件环境,并使用基于pytorch框架的python语言进行实现。
[0095]
为了评价去噪的效果,仿真验证时使用了峰值信噪比psnr和结构相似性ssim对sar图像的质量进行评价。psnr的计算公式为:
[0096][0097]
其中,max
o
为sar图像的峰值,mse为去噪后图像与参考图像的均方误差。一般情况下,mse越小或psnr越大,算法的去噪性能就越好。ssim反映的是两幅图像的相似度,其取值在0
‑
1之间。ssim的计算公式为:
[0098][0099]
其中,图像x和y分别表示去噪后图像和参考图像,变量c1=(k1l)2,c2=(k2l)2,c3=c2/2,一般k1取0.01,k2取0.03,l取255。μ和σ2分别表示图像的均值和方差,σ
xy
表示图像x、y的协方差。当ssim的值越大,两幅图像的相似度越高,反之,两幅图像的相似度越低。
[0100]
2.仿真内容和结果:
[0101]
仿真一:验证去噪任务子网络的有效性。
[0102]
在本仿真中,采用两种基于深度学习的sar图像去噪算法作为比较方法。一种是基于普通cnn的噪声估计方法,另一种是基于残差结构的噪声估计方法。由于实测数据集msatr中图像噪声等级较低,并且不包含在各种噪声污染下的sar图像目标识别数据。因此,本实验将基于mstar标准数据集,采用仿真方法生成噪声等级为l=1,2,3,4,5的噪声污染的sar图像。实验结果比较了这三种方法去噪后的psnr和ssim值以及去噪效果对比图,详见表2和图3,结果证明了本文提出的去噪方法的有效性。另外,为了验证在噪声环境下,去噪网络对sar图像目标识别的必要性,本仿真还比较了噪声sar图像和去噪后sar图像的识别性能,详见表3,结果显示在l=1时去噪后的识别率提升了8.37%。由此可见,在强噪声条件下的sar图像目标识别中,去噪任务可以辅助改善分类任务的识别性能。
[0103]
仿真二:评估和比较本发明的基于去噪任务辅助的深度注意分类网络的有效性与优越性。
[0104]
在本仿真中,三种基于深度学习的sar图像目标识别方法被作为比较方法,其中两种是基于单任务的,而dcc
‑
cnns和本文的方法是基于双任务的,即去噪和分类任务。由于在实际应用中难以估计噪声的强度,因此用某一特定噪声强度(l=3)来模拟环境中的噪声,在其他噪声等级下进行测试,结果详见表4。结果表明,若在某一特定噪声强度(l=3)环境中采集到sar图像的训练集和测试集,本文方法可达到98.02%的识别率,该条件下的识别精度要优于其他方法;若采集到的测试集在不同噪声等级下,除了在l=1时的识别率稍微
较低但可以接受,其他情况下都优于其他算法的识别精度,本文的方法总体具有适用性。
[0105]
仿真三:验证分类网络中注意力机制在sar图像目标识别的有效性。
[0106]
在本仿真中,模型1表示具有注意力机制的分类网络,模型2表示不具有注意力机制的分类网络。将msatr标准数据集中17
°
俯仰角下的原始图像用于训练模型,15
°
俯仰角下的原始图像用于测试模型。为了避免实验结果的偶然性,所有实验重复执行5次。结果表明,模型1的平均识别率为99.03%,模型2的平均识别率为98.59%,总体提升了0.44%,这证明了注意力机制对sar图像目标识别性能具有一定的提升效果。
[0107]
表1 mstar标准数据集十类目标数据的详细情况
[0108][0109]
表2本发明的去噪算法与其他两种去噪算法的性能比较(psnr/db)
[0110][0111]
表3去噪前后识别率的比较(%)
[0112]
参数l=1l=2l=3l=4l=5噪声图像83.7192.0495.0596.4997.03去噪后图像92.0896.1697.0797.9097.77
[0113]
表4不同识别网络在噪声环境下的性能比较(%)
[0114]
噪声等级(l)mfcnndcnndcc
‑
cnns本文188.6690.7690.4789.77296.0093.2093.1597.77395.3093.3293.8198.02494.5293.4493.8198.19593.5393.0794.0698.10
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。