1.本发明涉及混沌时间序列嵌入维数的确定技术,具体涉及一种基于注意力机制的混沌时间序列嵌入维数的确定方法。
背景技术:
2.混沌时间序列存在于天气气象、农业、金融、雷达信号、太阳黑子等等活动中,对这些领域的时间序列进行预测具有非常重大的意义。通过时间序列对混沌进行研究的工作开始于packard等人提出的相空间重构理论,重构基础就是相空间嵌入维数和延迟时间的确定,因此对于嵌入维数和延迟时间的选择具有非常重要的意义。
3.原始的嵌入维数的确定方法有虚假最近邻法(false nearest neighbors,fnn)、奇异值分解法(singular value decomposition,svd)等。对于fnn,在几何形态上,混沌时间序列是高维相空间混沌运动轨迹在时间序列上的一维投影,在高维状态中不相邻的两个点投影到一维会发生轨迹扭曲从而相邻,此即为虚假相邻点,对于嵌入维数的不断由小增大,虚假相邻点也将逐步消失从而使混沌运动的轨迹得到恢复。对于实际的混沌时间序列,从最小嵌入维度开始计算虚假邻点的比例直到达到某一阈值即认为此时混沌轨迹已得到有效的重构,此时的嵌入维度即为混沌时间序列的嵌入维数。对于svd,则是计算混沌时间序列的嵌入空间进行奇异值分解中的最大奇异值。
技术实现要素:
4.本发明的目的在于解决在传统嵌入维数求解上复杂求解的弊端,利用注意力机制可以简易的通过注意力权重的合理分布确定混沌时间序列的嵌入维数,提供一种基于注意力机制的混沌时间序列嵌入维数的确定方法,以步骤较为简化,计算简便的方式求解出合理的混沌时间序列的嵌入维数。
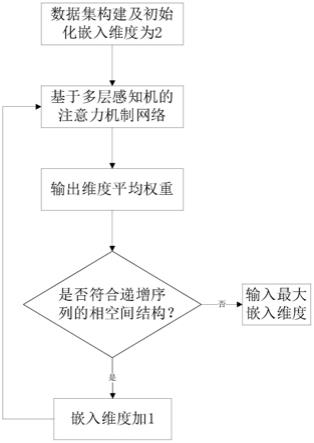
5.本发明是一种基于注意力机制的混沌时间序列嵌入维数的确定方法,如图1所示,包括以下步骤:
6.s1、对于待确定嵌入维数的混沌时间序列x(t),t=1,2,
…
n,n为混沌时间序列长度,设定输入嵌入维数初始值m和延迟时间τ,构建输入数据集和输出标签,输入数据为前m个不同时刻的混沌序列值作为输入,下一时刻混沌序列值作为输出标签:
[0007][0008]
其中data为输入数据集结构,每一行即为一次输入,取对应行数的输出label的数值为输出标签值,其中m=n
‑
(m
‑
1)τ为相点数;
[0009]
所述延迟时间τ的获取方法为:对于待输入的混沌时间序列,获取其自相关函数关于t的图像后,在自相关函数的值为初值的1
‑
1/e时,对应的横坐标t即为重构混沌序列相空
间的延迟τ;e为自然对数函数的底数,约为2.7183;
[0010]
s2、构建基于多层感知机的注意力机制网络,如图2所示:
[0011]
网络的输入为data中的每一行,对输入层权重初始化后,输入数据乘以输入权重后再通过激活函数softmax进行概率归一化输出,具体激活过程为:
[0012][0013]
上式中,x
i
、x
j
表示输入序列x中的第i、j个元素,x
i
对应的softmax值为经过感知机后激活得到的s
i
,经过激活函数的处理后对每个输入维度输出概率值,随后将概率值与输入值进行合并乘积,具体的输出格式如下:
[0014]
[x1,x2,
…
,x
n
][α1,α2,
…
,α
n
]=[x1α1,x2α2,
…
,x
n
α
n
]
[0015]
其中α
i
代表第i个维度的值x
i
的输出概率值;
[0016]
将得到的输出[x1α1,x2α2,
…
,x
n
α
n
]作为新的输入进入一个全连接层,此时输出维度是1,得到输出值y
i
,将输出值与标签值对比计算出损失函数mse,使用adam优化进行梯度下降的训练迭代,mse公式如下:
[0017][0018]
通过输入数据集经过设定的训练次数训练后,得到训练好的网络模型;
[0019]
s3、将输入数据通过训练好的网络模型后得到每行输入数据的不同维度的注意力权重值,对相同维度不同行的权重进行平均后输出,获得对应权重大小;
[0020]
s4、设置混沌序列的m初始值为2,每次递增1进行步骤s1
‑
s3,若到达m=n 1的时候权重不再保持从第0维度到最后维度的依次递增状态,则获得的n为最大嵌入维度。
[0021]
本发明的有益效果为,相对假近邻法、c
‑
c法等传统方法能更简单快速的确定混沌时间序列的嵌入维度,并且构成相空间的每个维度相对标签值是属于有贡献的维度,而传统意义的维度却没有这个意义。
附图说明
[0022]
图1为本发明的流程示意图;
[0023]
图2为本发明的模型训练示意图;
[0024]
图3为仿真示意图,其中(a)为duffing混沌序列最大嵌入维数注意力权重分布图,(b)为lorenz混沌序列最大嵌入维数注意力权重分布图,(c)为mackey
‑
glass混沌序列最大嵌入维数注意力权重分布图;
具体实施方式
[0025]
下面将结合附图和实施例,对本发明的技术方案进行进一步说明。
[0026]
实施例:选择lorenz混沌序列进行嵌入维数的确定。
[0027]
s1、首先利用自相关方法确定lorenz序列的延迟时间为10,初始化嵌入维数t=2,
[0028]
s2、利用延迟时间和t重构相空间。
[0029]
s3、将s2重构好的数据集代入注意力机制网络中进行训练后得出每一维度的注意力权重值。
[0030]
s4判断是否符合从第0维度到最高维度是递增的情况。如果是,则令t加1。重返s2。如果不是则输出t值为最佳嵌入维数。
[0031]
本发明基于多层感知机的注意力机制网络对混沌时间序列的当前嵌入维数进行注意力求取,若注意力权重大小符合维度从低到高依次递增,则当前由延迟时间和嵌入维数确定的相空间合理,依次将嵌入维度增大代入网络中求取注意力权重直到不符合递增规律即达到比最大嵌入维数多1的值。本发明避开了复杂的关联维数计算和奇异值分解,利用注意力权重可以较为简洁明了的判断嵌入维数。通过如图3所示的仿真对比,可看出本发明的方法是有效且实用的。
技术特征:
1.一种基于注意力机制的混沌时间序列嵌入维数的确定方法,其特征在于,包括以下步骤:s1、对于待确定嵌入维数的混沌时间序列x(t),t=1,2,...n,设定输入嵌入维数初始值m和延迟时间τ,构建输入数据集和输出标签,输入数据为前m个不同时刻的混沌序列值作为输入,下一时刻混沌序列值作为输出标签:其中data为输入数据集结构,每一行即为一次输入,取对应行数的输出label的数值为输出标签值,其中m=n
‑
(m
‑
1)τ为相点数;所述延迟时间τ的获取方法为:对于待输入的混沌时间序列,获取其自相关函数关于t的图像后,在自相关函数的值为初值的1
‑
1/e时,对应的横坐标t即为重构混沌序列相空间的延迟τ;s2、构建基于多层感知机的注意力机制网络;网络的输入为data中的每一行,对输入层权重初始化后,输入数据乘以输入权重后再通过激活函数softmax进行概率归一化输出,具体激活过程为:上式中,x
i
、x
j
表示输入序列x中的第i、j个元素,x
i
对应的soffmax值为经过感知机后激活得到的s
i
,经过激活函数的处理后对每个输入维度输出概率值,随后将概率值与输入值进行合并乘积,具体的输出格式如下:[x1,x2,...,x
n
][α1,α2,...,α
n
]=[x1α1,x2α2,
…
,x
n
α
n
]其中α
i
代表第i个维度的值x
i
的输出概率值;将得到的输出[x1α1,x2α2,...,x
n
α
n
]作为新的输入进入一个全连接层,此时输出维度是1,得到输出值y
i
,将输出值与标签值对比计算出损失函数mse,使用adam优化进行梯度下降的训练迭代,mse公式如下:通过输入数据集经过设定的训练次数训练后,得到训练好的网络模型;s3、将输入数据通过训练好的网络模型后得到每行输入数据的不同维度的注意力权重值,对相同维度不同行的权重进行平均后输出,获得对应权重大小;s4、设置混沌序列的m初始值为2,每次递增1进行步骤s1
‑
s3,若到达m=n 1的时候权重不再保持从第0维度到最后维度的依次递增状态,则获得的n为最大嵌入维度。
技术总结
本发明属于混沌时间序列嵌入维数的确定技术,具体涉及一种基于注意力机制的混沌时间序列嵌入维数的确定方法。包括以下步骤:自相关法确定延迟时间τ并初始化最小嵌入维数m,利用延迟时间和嵌入维数重构数据集,将数据集导入基于多层感知机的注意力机制网络进行训练,输出每个维度的权重大小,判断是否符合维度的注意力权重值从低维度到高维度依次递增,若是则令m加1继续重构数据集再次导入网络训练并输出维度注意力权重值,直到维度注意力权重值不符合递增情况时输出最大嵌入维数,此时最大嵌入维数为使得维度注意力权重分布递增的最大嵌入维数。的最大嵌入维数。的最大嵌入维数。
技术研发人员:鲁晓倩 田军 廖强 徐政五 甘露
受保护的技术使用者:电子科技大学
技术研发日:2021.09.18
技术公布日:2021/12/16
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。