一种基于q学习的auv浮力调节方法
技术领域
1.本发明涉及auv浮力调节技术领域,具体地说是一种基于q学习的auv浮力调节方法。
背景技术:
2.当自主式水下潜器(autonomous underwater vehicle,auv)在水下定深巡航并进入稳态后,会带有一定的攻角(也即纵倾角),同时执行机构也会始终存在一个操控量(下文用舵角代表这个操控量,对于采用不同执行机构的auv,此处的操控量会不同,但其本质是相同的)。攻角和舵角的存在会增加auv的航行阻力,进而消耗能量,降低了auv的有效航程和作业时间。此外,如果由于海水密度发生变化使auv的正浮力超出一定范围,甚至可能造成auv航行失控。因此需要浮力调节系统动态调整浮力和力矩,使auv始终保持以较小的纵倾角和舵角航行。
3.目前,国内外浮力调节系统多采用pd控制、滑模控制等,但由于auv在水下航行时受力较复杂,同时其运动学和动力学模型也存在一定的误差,因此通过其航行时的纵倾角和舵角很难准确分析auv的实际衡重状态,进而也就难于据此得出实际的浮力调节量,这导致传统控制方法的鲁棒性和智能性不高。
技术实现要素:
4.为了克服上述现有技术的不足,本发明提供了一种基于q学习的auv浮力调节方法,解决传统浮力调节方法鲁棒性和智能性不高等问题。
5.本发明解决其技术问题所采用的技术方案是:一种基于q学习的auv浮力调节方法,包括以下步骤:
6.根据不同auv的执行机构构建系统环境状态集,根据浮力调节系统的能力及auv的实际特性构建浮力调节动作集,从而形成初始q表;
7.确定用于更新q表的奖励机制,根据epsilon贪婪策略选择浮力调节动作,根据产生的奖励更新q表;
8.根据更新后的q表选择浮力调节动作,调节auv浮力。
9.所述系统环境状态集为:auv纵倾角状态与执行机构操控量状态不同组合所对应的状态;其中,auv纵倾角状态和执行机构操控量状态分别由纵倾角和执行机构操控量根据纵倾角门限值、执行机构操控量门限值离散化处理得到。
10.所述纵倾角和执行机构操控量进行离散化处理,具体是根据各自的门限值将值域空间划分为3部分:小于门限值相反数部分、处于门限值区间内部分、大于门限值部分;使auv稳态航行时的纵倾角和执行机构操控量调节到绝对值同时小于相应门限值的状态。
11.所述浮力调节动作集包括:浮力调节和力矩调节的多种组合对应的调节动作,浮力调节和力矩调节的每次调节量限定为设定值。
12.所述q表包括:基于系统环境状态集和浮力调节动作集的q表中,行表示状态,列表
示每个状态下可以执行的各个调节动作;各单元格中期望收益值q(i,j)中的i表示状态的编号,j表示调节动作的编号。
13.所述确定用于更新q表的奖励机制,根据epsilon贪婪策略选择浮力调节动作,根据产生的奖励更新q表,包括以下步骤:
14.(1)等待航行稳态的建立,记录航行稳态下的纵倾角和执行机构操控量;当纵倾角的变化量和执行机构操控量的变化量均小于各自变化量阈值且持续设定时间的情况下,认为航行稳态;
15.(2)判断航行稳态下浮力调节系统是否处于理想状态;所述理想状态为纵倾角和执行机构操控量均处于各自门限值区间内部分时的状态;如果不处于理想状态,则执行根据epsilon贪婪策略选取的调节动作,转步骤(3);否则等待;
16.(3)重新等待航行稳态的建立,根据新航行稳态和前一航行稳态下纵倾角和执行机构操控量的变化情况计算奖励值,利用产生的奖励并根据如下bellman公式对q表进行更新:
[0017][0018]
其中,newq(s
i
,a
j
)为更新后的q值;q(s
i
,a
j
)为更新前的q值;,其中,a表示采取动作a
j
后到达的新的状态s
i 1
下可能采取的动作,a表示动作集,a∈a;α为学习率,r(s
i
,a
j
)为在状态s
i
执行调节动作a
j
转移至状态s
i 1
所产生的瞬时奖励;γ为折扣率。
[0019]
所述奖励值通过奖励函数获取,如下式所示:
[0020][0021]
其中,r为当前奖励值,p
i
和r
i
为当前稳态下的纵倾角和执行机构操控量,p
i-1
和r
i-1
为上一稳态下的纵倾角和执行机构操控量;
[0022]
当纵倾角和执行机构操控量绝对值均变小时,则说明调节有效,给予正奖励,即 rvalue;当纵倾角和执行机构操控量绝对值均变大时,说明调节起到了反作用,给予负奖励,即-rvalue;其它情况均给予零奖励0。
[0023]
所述根据更新后的q表选择浮力调节动作具体为:
[0024]
所述更新后的q表通过q学习的进行,各状态下最优动作对应的q值增加,某种状态的最大q值所对应的调节动作为选取的浮力调节动作。
[0025]
本发明具有以下有益效果及优点:
[0026]
1.方法简单,普适性好。本浮力调节控制方法能应用于采取不同浮力调节原理的各式浮力调节系统,同时浮力调节系统的性能参数和海洋环境等因素不会对方法的性能产生不良影响,方法具有较好的普适性。
[0027]
2.实时性好,可靠性高。本浮力调节控制方法的实时性能满足应用需求,同时由于其基于机器学习的本质特征,具有良好的鲁棒性和适应性。
附图说明
[0028]
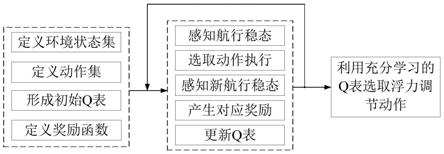
图1是本发明的auv浮力调节方法方案示意图;
[0029]
图2是纵倾角状态离散化示意图;
[0030]
图3是舵角状态离散化示意图;
具体实施方式
[0031]
下面结合实施例对本发明做进一步的详细说明。
[0032]
一种基于q学习的auv浮力调节方法,包括以下步骤:
[0033]
步骤1:根据不同auv的执行机构定义系统环境状态集,根据浮力调节系统的能力及auv的实际特性定义浮力调节动作集,从而由此形成初始q表;
[0034]
步骤2:确定用以更新q表的奖励机制,根据epsilon贪婪策略选择浮力调节动作,根据产生的奖励更新q表;
[0035]
步骤3:根据充分训练的q表选择浮力调节动作。
[0036]
所述定义系统环境状态包括:
[0037]
浮力调节的目的是将auv稳态航行时的纵倾角和执行机构操控量(下文用舵角代表这个操控量,对于采用不同执行机构的auv,此处的操控量会不同,但其本质是相同的)调节到小于一定门限值(下文假设纵倾角的门限值为p
t
,舵角的门限值为r
t
),在此应用场景下,系统状态由纵倾角和舵角的当前值所表征。由于纵倾角和舵角的值域是连续的,为避免强化学习时维数爆炸(也即状态数过多)问题,将纵倾角和舵角离散化处理。
[0038]
所述纵倾角和舵角离散化处理包括:
[0039]
离散化的方法为根据各自的门限值将其值域空间划分为3部分:(1)小于门限值相反数部分;(2)处于门限值区间内部分;(3)大于门限值部分。进行离散化处理之后,浮力调节的目的可重新表述为:将auv稳态航行时的纵倾角和舵角调节到绝对值同时小于相应门限值的状态。
[0040]
所述定义浮力调节动作包括:
[0041]
浮力调节动作为浮力调节和力矩调节的各种组合,由于调节量为连续量,理论上有无数种动作。为解决动作数无限问题,采取将每次的调节量限定为特定值(下文假设每次浮力调节量为f
t
,力矩调节量为m
t
)的方法,这个特定值应具有适度的大小,既要保证单次调节能产生较显著的效果,又不至于太大使auv衡重状态发生过大变化,具体应用时可根据浮力调节系统的能力并结合auv的实际特性进行选取。
[0042]
浮力调节系统包括对浮力的调节和对力矩的调节。对浮力的调节一般包括吸排水式和吸排油式两种,其本质特征均是通过改变auv的重力或浮力进而去改变auv的正浮力,本方法均可以直接应用;对auv静力矩的改变有两种方式,一种是提供直接手段的相对复杂的系统,例如通过前后油箱互相传油产生附加抬艏或低艏力矩,另一种是不提供直接手段的相对简单的浮力调节系统,对于前者,本方法可以直接应用,而后者由于不提供直接改变静力矩的手段,浮力调节动作定义方法会有所不同但原理是一样的,且动作数更少,从而q表规模更小,进而学习过程会更快速。
[0043]
所述形成初始q表包括:
[0044]
基于前述状态集和动作集定义的q表中行表示状态,列表示每个状态下可以执行的各个调节动作,各单元格中期望收益值q(i,j)中的i表示状态的编号,j表示行动的编号,例如q(1,1)表示在状态s1下执行行动a1的期望收益值。学习开始时将q表各项赋一个较小的
随机数作为初值,随着学习的深入进行,各状态下最优动作对应的q值会不断增加,这样该动作被选取的概率也会相应增加。
[0045]
所述用以更新q表的奖励机制包括:
[0046]
采取监视纵倾角和舵角的变化量是否持续小于一定门限的方法来感知新航行稳态的建立。基于此方法,确定的奖励机制如下:(1)等待航行稳态的建立,记录航行稳态下的纵倾角和舵角;(2)判断航行稳态下系统是否处于理想状态,如果不处于理想状态,则执行根据前述epsilon贪婪策略选取的调节动作,转步骤3;否则什么也不做;(3)重新等待航行稳态的建立,根据新航行稳态和前一航行稳态下纵倾角和舵角的变化情况计算奖励值,利用产生的奖励并根据如下bellman公式对q表进行更新。
[0047][0048]
其中,newq(s
i
,a
j
)为更新后的q值;q(s
i
,a
j
)为更新前的q值;maxq(s
i 1
,a)表示采取动作a
j
后到达的新的状态s
i 1
下可能采取的各动作对应的q值中的最大值,a表示采取动作a
j
后到达的新的状态s
i 1
下可能采取的动作,a表示动作集,a∈aα为学习率,是控制学习速度的参数,α越大学习的收敛速度越快,但α过大会导致学习过程震荡,达不到预期学习效果;r(s
i
,a
j
)为在状态s
i
执行动作a
j
转移至状态s
i 1
所产生的瞬时奖励;γ为折扣率,取值在0到1之间,如果γ越接近于0,智能体更趋向于仅仅考虑即时奖励,如果γ更接近于1,智能体将以更大的权重考虑未来的奖励。
[0049]
奖励函数如下式所示:
[0050][0051]
其中r为当前奖励值,p
i
和r
i
为当前稳态下的纵倾角和舵角,p
i-1
和r
i-1
为上一稳态下的纵倾角和舵角。也即当纵倾角和舵角绝对值均变小时,则说明调节有效,给予正奖励( rvalue);当纵倾角和舵角绝对值均变大时,说明调节起到了反作用,给予负奖励(-rvalue);其它情况均给予零奖励(0)。
[0052]
如图1所示是本发明的auv浮力调节方法实现流程图。
[0053]
根据auv执行机构的不同定义系统环境状态集、根据浮力调节系统的能力及auv的实际特性定义浮力调节动作集,从而由此形成初始q表,定义奖励函数;确定用以更新q表的奖励机制,根据epsilon贪婪策略选择浮力调节动作,根据产生的奖励更新q表;学习过程中q表各状态下最优动作对应的q值会不断增加,依据充分学习的q表可选取最优浮力调节动作。
[0054]
表1.系统状态集定义表
[0055]
[0056]
本实施方式中auv执行机构操作量以舵角为例,对于采用不同执行机构的auv,此处的操控量会不同,但其本质是相同的。如图2和图3所示为纵倾角和舵角离散化处理的示意图,当纵倾角小于-p
t
度时,状态记作p0,当纵倾角大于等于-p
t
度且小于等于p
t
度时,状态记作p1,当纵倾角大于p
t
度时,状态记作p2;同理舵角状态也分为r0、r1和r2。离散化处理后的系统状态集如表1所示,共包括9个状态,s1~s9。例如当纵倾角大于p
t
度(处于p2)且舵角小于-r
t
度(处于r0)时,此时系统状态记作s3。需要说明的是,上述离散化处理相关变量的门限值可根据实际需要进行调整,其原理都是一样的。
[0057]
表2.动作集定义表
[0058][0059]
浮力调节动作为浮力调节和力矩调节的各种组合,浮力增大f
t
升记为动作f0,浮力不变记为动作f1,浮力减小f
t
升记为动作f2;力矩增大m
t
升记为动作m0,力矩不变记为动作m1,力矩减小m
t
升记为动作m2。离散化处理后的动作集如表2所示,共包括9个动作,a1~a9。例如保持浮力不变(动作f1)且力矩减小m
t
升(动作m2)的动作记作a8。需要说明的是,这里所说的浮力增大f
t
升和力矩增大m
t
升等为简化说法,因为实际产生的附加浮力和力矩与油的密度、海水的密度和储油器的相对位置关系均相关,但具体数值跟方法研究无关,因此采取了这种简化说法。
[0060]
表3.由状态集和动作集确定的q表
[0061][0062]
基于前述状态集和动作集定义的q表如表3所示,其中行表示状态,列表示每个状态下可以执行的各个调节动作,表中各单元格中期望收益值q(i,j)中的i表示状态的编号,j表示行动的编号,例如q(1,1)表示在状态s1下执行行动a1的期望收益值。学习开始时将q表各项赋一个较小的随机数作为初值,随着学习的深入进行,各状态下最优动作对应的q值会不断增加,这样该动作被选取的概率也会相应增加。
[0063]
动作选择遵从epsilon贪婪策略,即每次以ε的概率选取随机动作,以1-ε概率选取最优动作。ε值开始时设定为0.1,之后随着智能体对q值较有把握后逐渐减小。
[0064]
上述动作选择策略如下式所示,先生成一个随机数rand,若其值大于ε则根据现有q表信息选择当前状态下的最优动作,若其值小于ε则从当前状态下动作集中随机选取1个
动作,以进行探索。
[0065][0066]
其中a
s
为遵从epsilon贪婪策略选择的动作,a
r
为从动作集中随机选取的动作,a
q
为利用当前q表信息选取的最优动作,rand为生成的随机数。
[0067]
当按照epsilon贪婪策略选取一个浮力调节动作并执行后,由于auv的正浮力和(或)静力矩发生了变化(除执行了浮力和力矩均不变化的行动a5外),因此其将重新进入新的航行稳态。由于重新进入航行稳态需要一定的时间且不固定,可采取监视纵倾角和舵角的变化量是否持续小于一定门限的方法来感知新航行稳态的建立。基于此方法,确定的奖励机制如下:(1)等待航行稳态的建立,记录航行稳态下的纵倾角和舵角;(2)判断航行稳态下系统是否处于状态s5,如果不处于状态s5,则执行根据前述epsilon贪婪策略选取的调节动作,转步骤3;否则什么也不做;(3)重新等待航行稳态的建立,根据新航行稳态和前一航行稳态下纵倾角和舵角的变化情况计算奖励值,利用产生的奖励并根据bellman公式对q表进行更新。
[0068]
奖励函数如下式所示:
[0069][0070]
其中r为当前奖励值,p
i
和r
i
为当前稳态下的纵倾角和舵角,p
i-1
和r
i-1
为上一稳态下的纵倾角和舵角。也即当纵倾角和舵角绝对值均变小时,则说明调节有效,给予正奖励( 100);当纵倾角和舵角绝对值均变大时,说明调节起到了反作用,给予负奖励(-100);其它情况均给予零奖励(0)。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。