1.本发明涉及医疗信息处理技术领域,特别涉及一种医疗数据处理方法和系统。
背景技术:
2.患者在就诊时,通常需要进行长时间的问诊,效率较低,而现在的医疗资源十分紧张,长时间的反复问诊也会导致医疗资源浪费,而相同的疾病症状大多相似,如果能够提前获取患者的症状,并根据症状特征获取最接近的疾病信息并发给医生,同时自动为患者挂号,则可以节省大量的诊断时间。
3.因此,如何提供一种快速诊断疾病的方法,是本领域技术人员亟待解决的问题。
技术实现要素:
4.本技术实施例提供了一种医疗数据处理方法和系统,旨在解决医疗诊断时间过长的问题。
5.第一方面,本技术提供了一种医疗数据处理方法,该方法包括:
6.通过预设的第一问答模式,获取患者的发病部位信息,并提取发病部位信息的关键字;
7.通过预设的第二问答模式,获取患者的病症信息,并提取病症信息的关键字;
8.根据发病部位信息的关键字和病症信息的关键字进行病例匹配;
9.将匹配度最高的病例从病例库中取出,作为参考病例发送给医生,并自动为患者挂号。
10.一种实施方式中,提取发病部位信息的关键字之后,还包括:
11.根据发病部位信息的关键字获取患者的发病部位。
12.一种实施方式中,通过预设的第二问答模式,获取患者的病症信息,并提取病症信息的关键字之前,还包括:
13.根据所述患者的发病部位选择对应的第二问答模式。
14.一种实施方式中,根据发病部位信息的关键字和病症信息的关键字进行病例匹配之前,还包括:
15.将病例库中的病例根据发病部位进行分类,并提取发病症状关键字作为病例标签并存储。
16.一种实施方式中,将匹配度最高的病例从病例库中取出,包括:
17.将病症信息的关键字与病例标签进行匹配,并将匹配度最高的病例标签对应的病例从病例库中取出。
18.一种实施方式中,预设的第一问答模式和第二问答模式为医师或专家制定的问答规则。
19.第二方面,本技术还提供了一种医疗数据处理系统,该系统包括:
20.第一问答模块,用于通过预设的第一问答模式,获取患者的发病部位信息,并提取
发病部位信息的关键字;
21.第二问答模块,用于通过预设的第二问答模式,获取患者的病症信息,并提取病症信息的关键字;
22.匹配模块,用于根据发病部位的关键字和病症信息的关键字进行病例匹配;
23.病例获取模块,用于将匹配度最高的病例从病例库中取出,作为参考病例发送给医生,并自动为患者挂号。
24.第三方面,本技术还提供了一种计算机装置,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,其特征在于,所述处理器执行所述计算机程序时,实现如上述第一方面中任一项所述的医疗数据处理方法。
25.第四方面,本技术还提供了一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时执行如上述第一方面中任一项所述的医疗数据处理方法。
26.本技术提出的一种医疗数据处理方法和系统,通过预设的第一问答模式,获取患者的发病部位信息,并提取发病部位信息的关键字,通过预设的第二问答模式,获取患者的病症信息,并提取病症信息的关键字,根据发病部位信息的关键字和病症信息的关键字进行病例匹配,将匹配度最高的病例从病例库中取出,作为参考病例发送给医生,并自动为患者挂号,本技术通过获取患者的患病信息,自动获取病例库中的相似病例,以此作为参考病例发给医生,可节约大量的问诊时间,而且,医生通过参考病例可采取针对性治疗,使得患者治疗效率更高。
附图说明
27.为了更清楚的说明本技术实施例技术方案,下面将对实施例描述中所需要使用的附图作简单的介绍,显而易见的,下面的描述中的附图是本技术的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他附图。
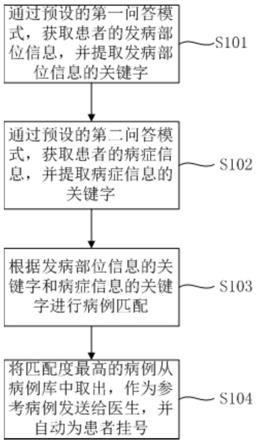
28.图1为本技术实施例提供的一种医疗数据处理方法流程图。
具体实施方式
29.下面结合附图对本发明的具体实施方式作进一步说明。在此需要说明的是,对于这些实施方式的说明用于帮助理解本发明,但并不构成对本发明的限定。此外,下面所描述的本发明各个实施方式中所涉及的技术特征只要彼此之间未构成冲突就可以相互组合。
30.参见图1实施例所示一种医疗数据处理方法流程图,包括:
31.s101、通过预设的第一问答模式,获取患者的发病部位信息,并提取发病部位信息的关键字。
32.在一实施例中,通过预设的第一问答模式,获取患者的发病部位信息,并提取发病部位信息的关键字之后,还包括:
33.根据发病部位信息的关键字获取患者的发病部位。
34.其中,第一问答模式可以是根据医师或专家根据问诊经验设置的问答规则。
35.s102、通过预设的第二问答模式,获取患者的病症信息,并提取病症信息的关键字。
36.在一实施例中,通过预设的第二问答模式,获取患者的病症信息,并提取病症信息的关键字之前,还包括:
37.根据所述患者的发病部位选择对应的第二问答模式。
38.其中,不同的第二问答模式对应不同的关键字提取模型,获取患者的发病部位后,可根据发病部位,选择对应的病情问答模式和关键字提取模型,获取对应的症状关键字,每一种问答模式对应一种关键字提取模型,保证了症状信息提取的精确性。
39.由于不同病情的发病症状不同,为了针对性的获取患者的病情,需要先确定患者的发病部位,并根据发病部位来选择对应的第二问答模式,第二问答模式可以为预设的问答模式中的一种,其中,预设的第二问答模式可以是根据医师或专家根据问诊经验设置的问答规则,例如:
40.若发病部位是头部,则自动选择头部疾病问答模式,具体询问的问题包括:发病状况、发病程度和发病频率。
41.通过预设的问答模式对患者进行病情询问,可以快速确定患者的疾病类型,还可以避免用户挂号时选择错误科室,造成医疗资源和金钱的浪费。
42.s103、根据发病部位信息的关键字和病症信息的关键字进行病例匹配。
43.根据获取的发病部位信息的关键字进行病例分类,确定患者的发病部位,然后根据症状关键字与病例库中的病例进行匹配。
44.在一实施例中,在根据病症关键字进行病例匹配之前,还包括:
45.对现有的病例库中的病例按照发病部位进行分类。
46.在对现有的病例库中的病例按照发病部位进行分类之后,还包括:
47.获取不同病例的关键字,并将关键字作为病例的标签进行存储。
48.在根据发病部位信息的关键字和病症信息的关键字进行病例匹配时,只需要查询病例的标签信息,就可以得到匹配结果,节约了大量的时间和资源,关键字匹配最多的标签对应的病例,则可以认定为匹配度最高的病例。
49.在一实施例中,病症信息的关键字包括病症状态关键字和病症程度关键字。
50.其中,提取病症信息中的关键字,包括:
51.a.将病症信息转化为文本信息,采用句子为单位,利用语句分隔符对文本进行一次切割,即t=[v1,v2,v3,
…
,v
n
],其中t为文本信息集合,v1‑
v
n
为对文本信息集合t进行一次切割后得到的句子。
[0052]
b.对每个句子v
i
∈t,对其进行一次分词和一次词性标注处理,并剔除一次分词和一次词性标注处理后的无关语义的词汇和重复词汇,保留其中的病症状态词汇,即v
i
=[v
i1
,v
i2
,
…
,
in
],其中,v
ij
为句子v
i
中保留下来的病症状态关键字,t为文本信息集合,v
i
为文本信息集合t中的第i个句子。
[0053]
在一实施例中,剔除一次分词和一次词性标注处理后的重复词汇,包括:
[0054]
(1)对现有的病症状态词汇进行语义划分,得到词汇语义集合。
[0055]
如患者的发病部位为头部,则病症状态相关词汇一般有“头晕”、“头痛”等,而“头痛”或“头晕”虽然有多种表达方式,但是都可以归结为这两种形式,而对于两种形式之间的状态,即,轻微的头痛或头晕,或者头痛伴随着头晕,患者有时无法确认究竟是哪一种症状,因此,可以将病症状态划分为“头痛状态”、“头晕状态”和“中间状态”。
[0056]
(2)判断句子中每个词汇与其他词汇的相似度,其中,相似度计算公式为:
[0057][0058]
v
im
为句子中第m个词汇,v
in
为句子中第n个词汇,p为v
im
与v
in
的关联度,s
d
为v
im
与v
in
在词汇语义集合中的距离,s
c
为调节参数,s
min
为判定两个词汇相似的最小相似度。
[0059]
(3)将得到的相似度与相似度阈值进行对比,若小于相似度阈值,就表示两个词汇不相似,若大于相似度阈值,就表示两个词汇相似,则剔除其中一个词汇。
[0060]
本技术通过对现有病症状态词汇进行语义划分,得到词汇语义集合,再利用句子中每个词汇与其他词汇在词汇语义集合中的距离,以及两个词汇相似的最小相似度,来判断句子中每个词汇与其他词汇的相似度,从而剔除相似度过高的词汇,相比于一般的重复词汇剔除方法,利用最小相似度作为参数,可以降低词汇相似度的误判,另外,若两个词汇不相似,则s
min
=1,从而计算得到的sim(v
im
,v
in
)=0,减少了计算复杂度。
[0061]
c.将病症信息转化为文本信息,采用句子为单位,利用语句分隔符对文本进行二次切割,即t=[s1,s2,s3,...,s
n
],其中t为文本信息集合,s1‑
s
n
为对文本信息集合t进行二次切割后得到的句子。
[0062]
d.对每个句子s
i
∈t,对其进行二次分词和二次词性标注处理,剔除二次分词和二次词性标注处理之后的无关语义的词汇和重复词汇,保留其中的病症程度词汇,即s
i
=[t
i1
,t
i2
,...,t
in
],其中,t
ij
为句子s
i
中保留下来的病症程度关键字,s
i
为文本信息集合中的第i个句子。
[0063]
由于获取的病症信息相同,因此,对文本信息进行一次切割和二次切割的方法和原理相同,但是,由于病症状态和病症程度对应的关键字不同,因此,对句子进行分词和词性标注的方式不同,例如:在表述病症状态时,其用词往往比较复杂,因此可采用长字节进行一次分词,并着重对其中与时间相关的词汇进行一次词性标注;而在表述病症程度时,用词往往比较简短,则可采用短字节来划分,并着重对其中与程度相关的词汇进行二次词性标注。
[0064]
在一实施例中,获取不同病例的关键字,并将关键字作为病例的标签进行存储,还包括:
[0065]
按照病症程度对病例的标签进行顺序存储。
[0066]
为保证对病症程度的认定精确性,可建立病症程度同义词库,将用来描述相同病症程度的多种同义词,采用固定的描述方式,以应对患者对病症程度的不同表述,其中,病症程度同义词库中的词汇与病例标签的词汇一致,且按照病症程度的顺序存储,其中,无关词汇即为与同义词库中的词汇语义不相同或者不相近的词汇。
[0067]
例如:病人对于头痛的程度,常见的病症程度的表述一般有:“很严重”、“很厉害”、“无法忍受”等,都可以使用“严重”来表示,从而减少对病例进行划分或识别的工作量。
[0068]
在一实施例中,所述剔除二次分词和二次词性标注处理之后的无关语义的词汇和重复词汇,保留其中的病症程度词汇,包括:
[0069]
(1)根据预先设定的语句分隔符,将每个句子划分成多个词汇,判断句子中每个词汇与病症程度同义词库中的词汇的关联度,其中,关联度采用下列公式计算:
[0070]
[0071]
其中,t(a
i
)表示句子中第i个词汇的关联度,w
i
表示第i个词汇与病例程度同义词库中的词汇语义近似程度,w
ij
表示第i个词汇的近似词汇在同义词库中的位置为j,n为与第i个词汇语义近似的词汇的同义词汇个数,α为调节参数。
[0072]
(2)将t(a
i
)与设定的关联度阈值进行对比,若小于关联度第一阈值,就表示该词汇为无关语义的词汇,则将该词汇进行剔除,若关联度大于关联度第二阈值,就表示该词汇为重复词汇,同样将该词汇剔除,并保留关联度处于关联度第一阈值和关联度第二阈值之间的词汇。
[0073]
本技术通过将每个词汇与同义词库的词汇进行关联度比较,考虑到患者在描述病症程度时的表述不清楚,本技术利用预先建立同义词库,来对患者的病症程度进行判断,由于同义词库中的词汇是按照病症程度来进行排序的,因此,病症程度词汇在同义词库中的位置,以及同义词汇的个数,也代表了病症程度的严重性,本技术充分考虑了上述要素,并以此来计算句子中每个词汇与病症程度同义词库中的词汇的关联度,从而降低了患者在描述病情时表述不清楚,导致病情误判的几率,另外,通过词汇关联度来剔除无关语义的词汇,也降低了后续词汇筛选的复杂度,减少了工作量。
[0074]
e.将v
i
和s
i
中的病症状态关键字和病症程度关键字按顺序进行匹配,得到病症状态和程度集合,然后与病例库中已有病例标签进行匹配。
[0075]
传统的关键字筛选技术,都是筛选出频率最高的词汇作为关键词,其显然不适用与本技术的方案,若同时对病症状态和病症程度进行筛选,可能会导致病情判定不合理,例如:病人对于病症状态或者程度的反复描述,会导致提取的关键字在重新组合时,出现词汇混乱的现象,因此,本技术通过将患者的语音信号转化成文本信息,并通过二次切割,分别提取病症状态关键字和病症程度关键字,再通过重新匹配组合,得到患者的病症状态信息和程度信息,可以减少病症判定的误差。
[0076]
s104、将匹配度最高的病例从病例库中取出,作为参考病例发送给医生,并自动为患者挂号。
[0077]
将与患者病症关键字匹配度最高的标签对应的病例从病例库中提取出来,作为参考病例发给对应科室的医生,并自动为患者挂号,医生根据参考病例对患者进行诊断,可节省大量的时间,医生还可以根据参考病例的用药和治疗情况,针对性的对患者进行治疗,而且,在将病例发送给医生后,自动为患者挂号,可以避免患者由于判断错病情而挂错号,造成金钱和时间的浪费。
[0078]
以上结合附图对本发明的实施方式作了详细说明,但本发明不限于所描述的实施方式。对于本领域的技术人员而言,在不脱离本发明原理和精神的情况下,对这些实施方式进行多种变化、修改、替换和变型,仍落入本发明的保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。