1.本发明属于核电材料数据处理技术领域,具体涉及一种核电结构材料数据文件自动化提取系统及方法。
背景技术:
2.随着当代计算机技术的不断进步,越来越多行业选择将纸质文档或电子文档中企业数据信息化提取,再进行存储分析等操作。核电结构材料数据也是如此,如何高效地进行数据提取,影响着核电结构材料数据库建设进度,与新材料的研发周期。
3.在核电结构材料数据提取过程中,需要将不同来源(文本、表格、纸质文档、电子文档等)数据信息化,提取为计算机可以存储识别的结构化数据并入库保存。由于核电结构材料数据种类复杂,不同的实验,不同的期刊,不同的文献,不同的数据都有不同的文档记录方式,有价值的数据往往隐藏在结构繁杂文档中,现有自动提取很难在复杂的核电结构材料数据中找的有价值的数据并提取出来,导致了核电结构材料数据价值在信息化过程中大打折扣。
4.现有的提取过程多靠纯人工录入,将核电结构材料数据纸质文档或电子文档中的信息,根据录入要求,手动录入到数据库中。录入人员必须同时具备核电结构材料知识和数据整理提取能力两方面知识,一篇一篇文档依次逐行阅读、提取、录入,学习成本非常高,存在效率低下,容易出错,影响数据应用的问题。
技术实现要素:
5.针对现有技术的不足,本发明的目的在于提供一种核电结构材料数据文件自动化提取系统及方法,解决了现有技术中存在的上述技术问题。
6.本发明的目的可以通过以下技术方案实现:
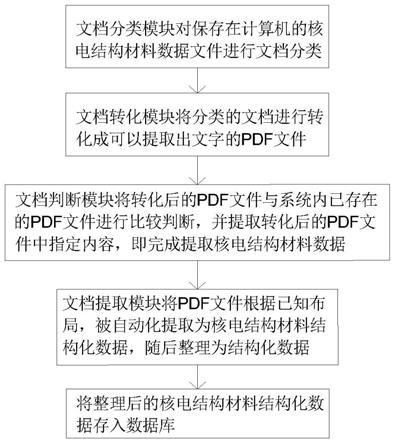
7.一种核电结构材料数据文件自动化提取系统,包括文档分类模块、文档转化模块、文档判断模块、文档提取模块,其中:
8.所述文档分类模块对保存在计算机的核电结构材料数据文件进行文档分类;
9.所述文档转化模块将分类的文档进行转化成可以提取出文字的pdf文件;
10.所述文档判断模块将转化后的pdf文件与系统内已存在的pdf文件进行比较判断,并提取转化后的pdf文件中指定内容,即完成提取核电结构材料数据;
11.所述文档提取模块将pdf文件根据已知布局,被自动化提取为核电结构材料结构化数据,随后整理为结构化数据。
12.进一步的,所述核电结构材料数据文件分类模块中文档分类为pdf文件、图片文档、纸质文档。
13.进一步的,所述纸质文档采用手动整理方式整理。
14.进一步的,所述pdf文件使用java语言pdfbox框架来测试pdf文件能否正常提取文本图片内容,如果可以,则认为该pdf文件不需要转化,如果不可以,那么保留pdf等待转化;
对于图片文档,则进行转化。
15.进一步的,所述文档转化模块中对于不存在文字的图片文档时,将其判断该图片文档中的数据核电结构材料为分子结构图片。
16.进一步的,所述文档判断模块中判断提取pdf文件中的指定内容时,采用了位置解析提取指定内容、逻辑解析、模糊匹配提取核电结构材料数据。
17.所述的核电结构材料数据文件自动化提取系统的方法,包括以下步骤:
18.s1、保存在计算机的核电结构材料数据文件,计算机根据文件扩展名来将文档进行分类,对于以纸质文档采用手动整理分类;
19.s2、对于pdf文件,使用java语言pdfbox框架来测试pdf文件能否正常提取文本图片内容,如果可以,则认为该pdf文件不需要转化,如果不可以,那么保留pdf等待转化;对于图片文档,需要进行转化,生成可识别的pdf文件。
20.s3、将s2中转化的可识别pdf文件进行文档布局判断,当系统内已经存在的pdf文件与可视别pdf存在相同的文档布局时,采用java解析,并准确提取pdf文件中的指定内容,即获得位置解析、逻辑解析、模糊匹配的提取核电结构材料数据;
21.s4、对于未知的核电结构材料数据pdf文件布局时,对该pdf文件分解为文本数据、图片数据,并在文本数据上根据布局和表格容忍度策略,还原出pdf文件的表格数据;
22.s5、将s3中可识别pdf文件的文档布局根据已知布局,被自动化提取为核电结构材料结构化数据,随后整理为结构化数据;
23.s6、将整理后的结构化数据存储在核电结构材料数据库中。
24.进一步的,所述s3中核电结构材料数据文档布局扩充,开发人员可以使用java语言,为核电结构材料数据文档布局扩充新的模板。
25.本发明的有益效果:
26.1、本发明提供的自动化提取系统中能够支持处理核电结构材料领域所有数据的信息化、数字化,不仅可以对已知格式文档进行全自动提取归档。
27.2、本发明通过开发人员使用java语言,为核电结构材料数据文档布局扩充新的模板,实现对解析能力进行扩展,不断自我完善。
28.3、本发明提供的提取方法提高了核电结构材料数据数字化效率和准确度,降低了录入人员工作难度和投入成本。
附图说明
29.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
30.图1是本发明实施例的自动化提取系统整体示意图;
31.图2是本发明实施例的自动化提取方法流程示意图。
具体实施方式
32.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于
本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
33.如图1所示,本发明实施例提供一种核电结构材料数据文件自动化提取系统,包括文档分类模块、文档转化模块、文档判断模块、文档提取模块,其中:
34.文档分类模块:对保存在计算机的核电结构材料数据文件进行文档分类;其中文档分类为pdf文件(扩展名为.pdf)、图片文档(扩展名为.jpg,.jpeg,.png,.bmp,tif等)、office文档(扩展名为.doc,docx,.xls,xlsx等)、纸质文档,同时对于纸质文档(多为生产研发过程中手工记录或设备打印的文档,以书籍或表单等形式保存在纸质档案中)保存的核电结构材料数据文件,由工作人员手动整理分类,图片文件多为生产研发过程中拍照或机器产生的文档,以纸质照片或计算机图片文件等方式存储。
35.文档转化模块:将分类的文档进行转化成可以提取出文字的pdf文件,具体操作为:对于pdf文件,方法会使用java语言pdfbox框架来测试pdf文件能否正常提取文本图片内容,如果可以,则认为该pdf文件不需要转化,如果不可以,那么保留pdf等待转化;对于图片文档,一律需要进行转化;对于office文档,方法一律认为只需要简单转化。
36.接下来是转化步骤,方法使用abbyy frengine作为ocr手段,使用pdfbox作为office文档转化为pdf文件的手段。abbyy frengine将pdf文件、图片文档转化成可以提取出文字的pdf文件,如果转化图片过程中没有提取到任何文字,方法则会判断该图片数据核电结构材料的分子结构图片等。pdfbox将office文档直接转化为可以提取出文字的pdf文件。
37.文档判断模块:将转化后的pdf文件与系统内已存在的pdf文件进行比较判断,由操作人员判断是否已经存在该文档布局,文档布局解析逻辑使用java语言编写,对于系统中已存在的pdf文件布局,该解析逻辑可以高效率,高准确度提取pdf文件中的指定内容。逻辑采用了位置解析(根据待提取内容大概出现的位置)提取指定内容、逻辑解析(根据待提取内容的上下文)、模糊匹配(根据待提取内容的关键词)提取核电结构材料数据。
38.同时核电结构材料数据文档布局扩充,开发人员可以使用java语言,为核电结构材料数据文档布局扩充新的模板。
39.文档提取模块:将pdf文件根据已知布局,被自动化提取为核电结构材料结构化数据,随后整理为结构化数据;当系统中不存在的核电结构材料数据文档布局,核电结构材料数据会被方法自动分解,将pdf分解为为文本(数字)数据、图片数据两种元数据,在文本(数字)元数据基础上,根据布局和表格容忍度策略,还原出pdf文件的表格数据。
40.pdf文件使用java语言pdfbox框架来测试pdf文件能否正常提取文本图片内容,如果可以,则认为该pdf文件不需要转化,如果不可以,那么保留pdf等待转化;对于图片文档,则进行转化。
41.如图2所示,核电结构材料数据文件自动化提取系统的方法,包括以下步骤:
42.s1、保存在计算机的核电结构材料数据文件,计算机根据文件扩展名来将文档进行分类,即计算机根据文件扩展名(pdf文件:.pdf,图片文档:.jpg,.jpeg,.png,.bmp,tif等,office文档:.doc,docx,.xls,xlsx等)来将文档进行分类。对于以纸质文档采用手动整理分类;
43.s2、对于pdf文件,使用java语言pdfbox框架来测试pdf文件能否正常提取文本图
片内容,如果可以,则认为该pdf文件不需要转化,如果不可以,那么保留pdf等待转化;对于图片文档,需要进行转化(判断该图片数据核电结构材料的分子结构图片等),生成可识别的pdf文件。
44.s3、将s2中转化的可识别pdf文件进行文档布局判断,当系统内已经存在的pdf文件与可视别pdf存在相同的文档布局时,采用java解析,并准确提取pdf文件中的指定内容,即逻辑采用了位置解析(根据待提取内容大概出现的位置)提取指定内容、逻辑解析(根据待提取内容的上下文)、模糊匹配(根据待提取内容的关键词)提取核电结构材料数据
45.同时核电结构材料数据文档布局扩充,开发人员可以使用java语言,为核电结构材料数据文档布局扩充新的模板。
46.s4、对于未知的核电结构材料数据pdf文件布局时,对该pdf文件分解为文本数据、图片数据,并在文本数据上根据布局和表格容忍度策略,还原出pdf文件的表格数据;
47.s5、将s3中可识别pdf文件的文档布局根据已知布局,被自动化提取为核电结构材料结构化数据,随后整理为结构化数据;
48.s6、核电结构材料数据文件实现自动化提取,将整理后的结构化数据存储在核电结构材料数据库中。
49.本发明提供的提取方法通过一套完整严谨的核电结构材料处理逻辑,能够支持处理核电结构材料领域所有数据的信息化、数字化,不仅可以对已知格式文档进行全自动提取归档,更可以对解析能力进行扩展,不断自我完善。提高了核电结构材料数据数字化效率和准确度,降低了录入人员工作难度和投入成本。
50.以上显示和描述了本发明的基本原理、主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。