1.本发明属于人工智能技术领域,具体涉及基于强化学习和模型预测控制的多智能体路径规划方法。
背景技术:
2.随着人工智能理论以及相关研究技术的发展与成熟,多智能体系统正在得到越来越广泛的研究与应用。多智能体系统是一种利用信息交互与反馈、激励与响应等交感行为,实现行为协同,适应动态环境,最终共同完成特定任务的自主式智能体系统。
3.多智能体系统是群体智能的一个重要应用研究领域,也是智能体系统未来发展的重要方向之一。路径规划是研究多智能体系统的重点,侧重考虑整个系统全局的最优路径,如系统路径的总路径长度最短或总耗能最少等。只有规划出整个系统最有效的路径,才能提高多智能体系统执行任务的效率与成功率。
4.目前对于多智能体系统路径规划任务来说,往往只是优化单一目标,对于有着多目标优化需求的多智能体路径规划,现有路径规划方法很难实现对多智能体与多个目标之间的路径优化。
技术实现要素:
5.针对现有路径规划方法无法满足多智能体与多个目标之间的路径优化,本发明提供了一种基于强化学习和模型预测控制的多智能体路径规划方法。
6.本发明的基本设计思路是:在多智能体深度确定性策略梯度(maddpg)的基础之上,加入了专家系统(esb)的思想以及模型预测控制(mpc)。首先将多智能体系统中的智能体简化为质点模型,再引入专家系统来平滑maddpg算法规划出的路径以及加快收敛时间;最后将esb
‑
maddpg算法得到的所有路径进行汇总,通过模型预测控制来跟随所有路径,从而使得多智能体系统能够实现满足多目标优化需求的路径规划。
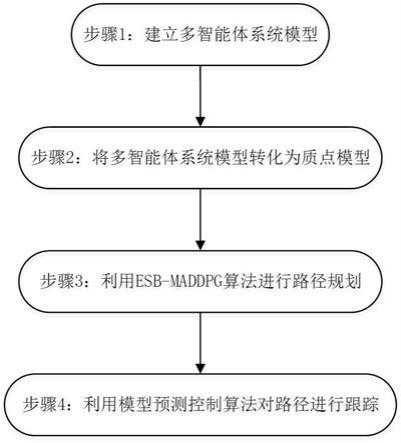
7.本发明的具体技术方案:一种基于强化学习和模型预测控制的多智能体路径规划方法,包括以下步骤:步骤1:建立多智能体系统模型,以及获取多智能体系统模型初始状态信息:初始状态信息包括多智能体系统模型中智能体的数量为n、目标点数量为n、在全局坐标下任意智能体i当前位置坐标为p
i
、每个目标点j位置坐标p
j
,其中,目标点位置坐标根据多智能体路径规划任务需求人为给定;(i,j)∈n;步骤2:将多智能体系统模型转化为质点模型;质点模型包括对应于n个智能体的n个质点,n个质点的起始位坐标为与其对应的智能体当前位置坐标,n个质点的终止位坐标为与其对应的目标点位置坐标;赋予每个质点的起始位坐标一个观测范围,赋予每个质点的终止位坐标一个可被观测范围;
步骤3:利用esb
‑
maddpg算法进行路径规划;步骤3.1:根据公式求解每一时刻奖励值r:根据公式求解每一时刻奖励值r:根据公式求解每一时刻奖励值r:根据公式求解每一时刻奖励值r:表示智能体i与目标点j之间的距离;步骤3.2:根据步骤2中获得任意质点i的起始位坐标和终止位坐标,通过esb
‑
maddpg算法得到该质点i的当前时刻状态o
i
;当前时刻状态o
i
由质点i的当前时刻坐标,以及质点i的当前时刻坐标与其他质点的当前时刻坐标的相对位置构成;步骤3.3:根据动作估计网络来获取在当前时刻状态o
i
下质点i的当前时刻动作,即;其中,由质点i的x、y轴上的速度构成;是在动作估计网络参数下的动作选择策略;代表质点i在当前时刻选择动作中受到的干扰;步骤3.4:在质点i选择完当前时刻动作并执行后,质点i会到达新的状态;步骤3.5:重复执行步骤3.3
‑
3.4共m个时刻,m≤50,得到质点i路径规划一次所有时刻的状态结果,将该次训练得到的所有时刻状态结果中质点i的位置相连,得到质点i的路径集合;步骤3.6:重复执行步骤3.1
‑
3.5获得n个质点的路径集合;步骤3.7:对训练得到的路径集合进行判断;判断标准为所有质点的最终时刻状态中观测范围内都有可被观测范围存在,即与都相接触,若是,认为此时初始路径规划完成,开始执行步骤3.9;若否,则重复执行步骤3.1
‑
3.6共计m次,使得充满经验池d,执行步骤3.8;m≥100;其中,o为的集合;为的集合;为的集合;步骤3.8:从经验池d中随机取样一小部分样本,通过状态估计网络计算q值;q值用于评价动作估计网络输出的动作好坏;同时,将样本输入到动作估计网络中,通过策略梯度公式对动作估计网络参数进行更新,更新后的动作估计网络参数输入到动作估计网络中,返回步骤3.1;步骤3.9:对符合要求的初始路径进行平滑处理并输出;步骤4:利用模型预测控制算法对路径进行跟踪;步骤4.1:建立智能体跟踪模型;设定质点i为虚拟领导者,其初始时刻位置为质点i的初始时刻位置,参考轨迹为平滑后质点i的路径;设定与质点i对应的智能体为跟随者,其初始时刻位置为步骤1中
智能体i的位置;设定跟随者和虚拟领导者之间的理想控制关系为; l1代表虚拟领导者和跟随者之间的距离;代表虚拟领导者和跟随者之间的相对方位;代表虚拟领导者和跟随者之间的朝向偏差,且的初始值均为0;步骤4.2:依据虚拟领导者和跟随者在全局坐标系下各自的速度、角速度以及两者之间的距离,获取虚拟领导者和跟随者之间控制关系的表达式,并结合智能体的运动学公式,建立跟踪控制模型;步骤4.3:根据跟随者初始时刻的位置和初始速度,以及跟踪控制模型来预测出t时刻跟随者和虚拟领导者之间的控制关系;步骤4.4:将步骤4.3预测的与步骤4.1设定的对比,计算出两者的误差e
t
并校正;步骤4.5:采用粒子群算法对误差e
t
进行优化校正,通过t 1时刻速度输入,计算出t 1时刻跟随者和虚拟领导者的控制关系;步骤4.6:判断是否到达控制终止时间,若是,则输出跟踪的路径,否则返回步骤4.4;所述控制终止时间为步骤4.1中参考轨迹的时长;步骤4.7:按照步骤4.1
‑
4.6对其余质点的初始路径进行跟踪,最终完成所有智能体的路径规划。
8.进一步地,上述步骤4.2中跟踪控制模型的表达式为:所述虚拟领导者和跟随者之间的关系的表达式为:所述智能体运动学公式为:其中,是跟随者的速度,是跟随者的角速度,是虚拟领导者的速度,是虚拟领导者的角速度,代表跟随者的速度输入。
9.进一步地,上述步骤3.2中o
i
的表达式为:;相对位置p
ij
求解公式为: ,且。
10.进一步地,上述步骤3.8中q的表达式为:其中:为衰减因子,为在新的时刻得到的新的时刻奖励值。
11.进一步地,上述步骤3.8中通过策略梯度公式对动作估计网络参数进行更新的策
略梯度公式为:其中:s代表采样的样本个数,代表对其所更新参数采用策略梯度法,。
12.本发明的有益效果在于:1、本发明针对多智能体的路径规划问题,利用一种结合esb
‑
madppg及mpc算法的路径规划跟踪算法,能够快速实现对多智能体系统的路径规划,为大规模多智能体系统执行任务奠定基础。
13.2、本发明通过设计esb
‑
maddpg算法中的奖励值以及算法中的神经网络,从而避免了每个质点系统的路径之间互相干扰,且到达目标点位置的路径距离最短;通过mpc算法引入智能体质点的运动学模型,能够对智能体跟踪路径中的速度进行优化,得到优化后的多智能体路径。
附图说明
14.图1为本发明的基本实现流程图;图2为采用esb
‑
maddpg进行路径规划的流程图;图3为基于pso的模型预测对路径进行跟踪的流程图;图4为质点模型的示意图;图5为平滑后的多智能体轨迹图;图6为智能体跟踪模型示意图;图7为智能体的路径跟踪误差曲线图,其中(a)
‑
(f)分别代表质点a、b、c、d、e、f对应的智能体作为跟随者的路径跟踪误差曲线图。
具体实施方式
15.下面结合附图,对本发明的具体实施方式进行详细说明。
16.本实施例提供了一种基于强化学习和模型预测控制的多智能体路径规划方法,本实施例中,智能体均为机器人,其实现流程如图1所示,具体包含以下步骤:步骤1:建立多智能体系统模型,以及获取多智能体系统模型初始状态信息:初始状态信息包括多智能体系统模型中智能体的数量为n、目标点数量为n、在全局坐标下任意智能体i当前位置坐标为p
i
、每个目标点j位置坐标p
j
,其中,目标点位置坐标根据多智能体路径规划任务需求人为给定;(i,j)∈n;步骤2:将多智能体系统模型转化为质点模型;质点模型包括对应于n个智能体的n个质点,n个质点的起始位坐标为与其对应的智能体当前位置坐标,n个质点的终止位坐标为与其对应的目标点位置坐标;赋予每个质点的起始位坐标一个观测范围,赋予每个质点的终止位坐标一个可被观测范围,如图4所示,本实施例中有六个智能体,即有六个质点(即a、b、c、d、e、f),白色区域为六个质点的起始坐标观测范围,黑色区域为六个质点的终止坐标可被观测范围;步骤3:利用esb
‑
maddpg算法进行路径规划,基本流程如图2所示;步骤3.1:根据公式求解每一时刻奖励值r:
表示智能体i与目标点j之间的距离;步骤3.2:根据步骤2中获得质点i的起始位坐标和终止位坐标,通过esb
‑
maddpg算法得到该质点i的当前时刻状态o
i
;当前时刻状态o
i
由质点i的当前时刻坐标,以及质点i的当前时刻坐标与其他质点的当前时刻坐标的相对位置构成;即,相对位置p
ij
求解公式为: ,且;步骤3.3:根据动作估计网络来获取在当前时刻状态o
i
下质点i的当前时刻动作,即;其中,由质点i的x、y轴上的速度构成;是在动作估计网络参数下的动作选择策略;代表质点i在当前时刻选择动作中受到的干扰;步骤3.4:在质点i选择完当前时刻动作并执行后,质点i会到达新的状态;步骤3.5:重复执行步骤3.3
‑
3.4共m个时刻,本实施例为30个时刻,得到质点i路径规划一次所有时刻的状态结果,将该次训练得到的所有时刻状态中质点i的位置相连,得到质点i的路径;步骤3.6:重复执行步骤3.1
‑
3.5获得n个质点的路径集合;步骤3.7:对训练得到的集合进行判断;判断标准为最终时刻状态中所有质点观测范围内都有可被观测范围存在,即与都相接触,若是,认为此时初始路径规划完成,开始执行步骤3.9;若否,则重复执行步骤3.1
‑
3.6共计m次,本实施例为100次,使得充满经验池d,执行步骤3.8;其中,o为的集合;为的集合;为的集合;步骤3.8:从经验池d中随机取样一小部分样本,通过状态估计网络计算q值;q值用于评价动作估计网络输出的动作好坏;其中:为衰减因子,为在新的时刻得到的新的时刻奖励值。
17.同时,根据将上述样本输入到动作估计网络中,通过策略梯度公式进行对网络参数进行更新:更新后的参数输入到动作估计网络中,重新执行步骤3.1;
其中:s代表采样的样本个数,代表对其所更新参数采用策略梯度法,。
18.步骤3.9:对符合要求的初始路径进行平滑处理并输出。由于得到的初始路径是一条不光滑的轨迹,为了让智能体能实时地对轨迹进行跟踪,需要对这些由一系列直线段连接形成的轨迹进行平滑处理,平滑方式采用b样条曲线,图5为平滑后的多智能体路径;步骤4:利用模型预测控制算法对路径进行跟踪,算法的流程图如图3所示;步骤4.1:建立智能体跟踪模型如图6所示,设定质点i为虚拟领导者,其初始时刻位置为质点i的初始时刻位置,参考轨迹为平滑后质点i的路径;设定与质点i对应的智能体为跟随者,其初始时刻位置为步骤1中智能体i的位置;设定跟随者和虚拟领导者之间的理想控制关系为; l1代表虚拟领导者和跟随者之间的距离;代表虚拟领导者和跟随者之间的相对方位;代表虚拟领导者和跟随者之间的朝向偏差,且的初始值均为0;步骤4.2:依据虚拟领导者和跟随者在全局坐标系下各自的速度、角速度以及两者之间的距离,获取虚拟领导者和跟随者之间控制关系的表达式,并结合智能体的运动学公式,建立跟踪控制模型;其中,虚拟领导者和跟随者之间的关系的表达式为:智能体运动学公式为:跟踪控制模型的表达式为:其中,是跟随者的速度,是跟随者的角速度,是领导者的速度,是领导者的角速度,代表跟随者的速度输入。
19.步骤4.3:根据跟随者初始时刻的位置和初始速度,以及跟踪控制模型来预测出下个时刻的跟随者输出;;步骤4.4:将步骤4.3预测的与步骤4.1设定的对比,计算出两者的误差e
t
并校正;如图7中的(a)所示,为质点a对应的智能体作为跟随者的路径跟踪误差,(b)至(f)为其余五个质点(即b、c、d、e、f)对应的智能体作为跟随者的路径跟踪误差;步骤4.5:采用粒子群算法(pso)对误差e
t
进行优化校正,计算出t 1时刻的速度输入,计算出t 1时刻跟随者和虚拟领导者的控制关系;步骤4.6:判断是否到达控制终止时间,控制终止时间为步骤4.1中参考轨迹时长;若是,则输出跟踪的路径,否则再次执行步骤4.4;步骤4.7:按照步骤4.1
‑
4.6对其余5个质点的初始路径进行跟踪,最终完成所有6
个智能体的路径规划。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。