1.本技术实施例涉及计算机技术领域,具体涉及用于纠正文本的方法和装置。
背景技术:
2.语音智能应答应用最广泛的场景,就是智能电话客服系统。智能电话客服可以针对用户的语音提问,通过语音应答的方式,为用户解决问题。智能电话客服系统,主要由语音转文字(automatic speech recognition,asr)、自然语言处理(natural language processing,nlp)和文字转语音(text to speech,tts)构成。当用户电话呼入之后发出语音提问,该语音进入智能电话客服系统。智能电话客服系统首先利用asr模块将用户问题转为文字问题;之后,利用nlp模型,对文字问题进行意图识别和答案管理,输出文本答案;最后,利用tts系统,将文本答案转为语音音频,并实时播放给用户。
技术实现要素:
3.本技术实施例提出了用于纠正文本的方法和装置。
4.第一方面,本技术实施例提供了一种用于纠正文本的方法,包括:获取应答文本,对应答文本进行分割,得到多个句子文本;针对多个句子文本中的每个句子文本,将该句子文本转换成语音,基于转换得到的音频,执行如下纠正步骤:确定转换得到的音频的带声调拼音,以及确定带声调拼音的发音时长;基于带声调拼音和预设的拼音无向图,生成目标文本,其中,目标文本为不存在错误声调的文本;确定目标文本中是否存在发音时长大于预设的发音时长阈值的文字,若不存在,则生成该句子文本对应的纠正后的文本;按照多个句子文本在应答文本中由前到后的顺序,合并对应的纠正后的文本,得到纠正后的应答文本。
5.第二方面,本技术实施例提供了一种用于纠正文本的装置,包括:获取单元,被配置成获取应答文本,对应答文本进行分割,得到多个句子文本;纠正单元,被配置成针对多个句子文本中的每个句子文本,将该句子文本转换成语音,基于转换得到的音频,执行如下纠正步骤:确定转换得到的音频的带声调拼音,以及确定带声调拼音的发音时长;基于带声调拼音和预设的拼音无向图,生成目标文本,其中,目标文本为不存在错误声调的文本;确定目标文本中是否存在发音时长大于预设的发音时长阈值的文字,若不存在,则生成该句子文本对应的纠正后的文本;合并单元,被配置成按照多个句子文本在应答文本中由前到后的顺序,合并对应的纠正后的文本,得到纠正后的应答文本。
6.第三方面,本技术实施例提供了一种电子设备,该电子设备包括:一个或多个处理器;存储装置,其上存储有一个或多个程序,当上述一个或多个程序被上述一个或多个处理器执行时,使得上述一个或多个处理器实现如第一方面中任一实现方式描述的方法。
7.第四方面,本技术实施例提供了一种计算机可读介质,其上存储有计算机程序,其中,该计算机程序被处理器执行时实现如第一方面中任一实现方式描述的方法。
8.本技术的上述实施例提供的用于纠正文本的方法和装置,通过获取应答文本,对上述应答文本进行分割,得到多个句子文本;之后,针对上述多个句子文本中的每个句子文
本,将该句子文本转换成语音,基于转换得到的音频,执行如下纠正步骤:确定转换得到的音频的带声调拼音,以及确定带声调拼音的发音时长;基于上述带声调拼音和预设的拼音无向图,生成目标文本;确定上述目标文本中是否存在发音时长大于预设的发音时长阈值的文字,若不存在,则生成该句子文本对应的纠正后的文本;最后,按照上述多个句子文本在上述应答文本中由前到后的顺序,合并对应的纠正后的文本,得到纠正后的应答文本。通过这种方式,可以在文本转语音的过程中,解决发音不正确和错误停顿的问题。
附图说明
9.通过阅读参照以下附图所作的对非限制性实施例所作的详细描述,本技术的其它特征、目的和优点将会变得更明显:
10.图1是本技术的各个实施例可以应用于其中的示例性系统架构图;
11.图2是根据本技术的用于纠正文本的方法的一个实施例的流程图;
12.图3是根据本技术的用于纠正文本的方法的易错组合和易错组合中的错音及修正音之间的对应关系的一个对应关系表;
13.图4是根据本技术的用于纠正文本的方法的易错组合与拼音无向图之间的对应关系的一个对应关系表;
14.图5是根据本技术的用于纠正文本的方法的一个应用场景的示意图;
15.图6是根据本技术的用于纠正文本的方法中确定音频的带声调拼音的一个实施例的流程图;
16.图7是根据本技术的用于纠正文本的方法中生成目标文本的一个实施例的流程图;
17.图8是根据本技术的用于纠正文本的装置的一个实施例的结构示意图;
18.图9是适于用来实现本技术实施例的电子设备的计算机系统的结构示意图。
具体实施方式
19.下面结合附图和实施例对本技术作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅仅用于解释相关发明,而非对该发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与有关发明相关的部分。
20.需要说明的是,在不冲突的情况下,本技术中的实施例及实施例中的特征可以相互组合。下面将参考附图并结合实施例来详细说明本技术。
21.图1示出了可以应用本技术的用于纠正文本的方法的实施例的示例性系统架构100。
22.如图1所示,系统架构100可以包括终端设备1011、1012、1013,网络102和服务器103。网络102用以在终端设备1011、1012、1013和服务器103之间提供通信链路的介质。网络102可以包括各种连接类型,例如有线、无线通信链路或者光纤电缆等等。
23.运营人员可以使用终端设备1011、1012、1013通过网络102与服务器103交互,以发送或接收消息等,例如,运营人员可以利用终端设备1011、1012、1013将应答文本发送给服务器103。终端设备1011、1012、1013上可以安装有各种通讯客户端应用,例如文本编辑类应用、客服类应用、语音处理类应用等。
24.终端设备1011、1012、1013可以是硬件,也可以是软件。当终端设备1011、1012、1013为硬件时,可以是具有扬声器并且支持信息交互的各种电子设备,包括但不限于智能手机、平板电脑、膝上型便携计算机等。当终端设备1011、1012、1013为软件时,可以安装在上述所列举的电子设备中。其可以实现成多个软件或软件模块(例如用来提供分布式服务的多个软件或软件模块),也可以实现成单个软件或软件模块。在此不做具体限定。
25.服务器103可以是提供各种服务的服务器。例如,可以从终端设备1011、1012、1013中获取应答文本,将上述应答文本进行分割,得到多个句子文本;之后,针对上述多个句子文本中的每个句子文本,可以将该句子文本转换成语音,基于转换得到的音频,执行如下纠正步骤:确定转换得到的音频的带声调拼音,以及确定带声调拼音的发音时长;基于上述带声调拼音和预设的拼音无向图,生成不存在错误声调的目标文本;确定上述目标文本中是否存在发音时长大于预设的发音时长阈值的文字,若不存在,则生成该句子文本对应的纠正后的文本;最后,可以按照上述多个句子文本在上述应答文本中由前到后的顺序,合并对应的纠正后的文本,得到纠正后的应答文本。
26.需要说明的是,服务器103可以是硬件,也可以是软件。当服务器103为硬件时,可以实现成多个服务器组成的分布式服务器集群,也可以实现成单个服务器。当服务器103为软件时,可以实现成多个软件或软件模块(例如用来提供分布式服务),也可以实现成单个软件或软件模块。在此不做具体限定。
27.需要说明的是,本技术实施例所提供的用于纠正文本的方法通常由服务器103执行。
28.还需要说明的是,服务器103的本地也可以存储有应答文本,服务器103可以从本地获取应答文本。此时示例性系统架构100可以不存在网络102和终端设备1011、1012、1013。
29.应该理解,图1中的终端设备、网络和服务器的数目仅仅是示意性的。根据实现需要,可以具有任意数目的终端设备、网络和服务器。
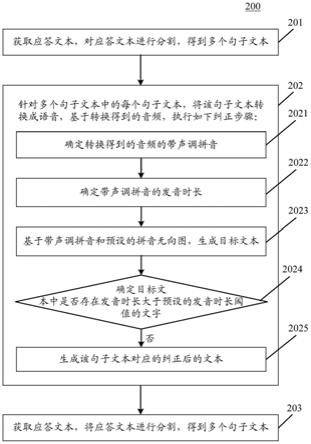
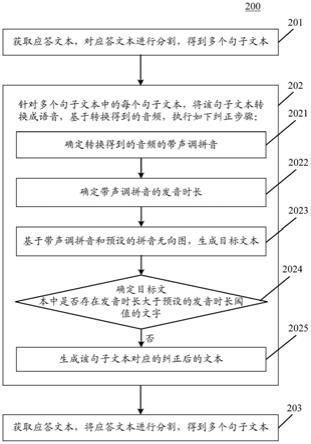
30.继续参考图2,示出了根据本技术的用于纠正文本的方法的一个实施例的流程200。该用于纠正文本的方法,包括以下步骤:
31.步骤201,获取应答文本,对应答文本进行分割,得到多个句子文本。
32.在本实施例中,用于纠正文本的方法的执行主体(例如图1所示的服务器)可以获取应答文本。在语音应答系统中,为了快速对用户提出的用户进行回答,通常会预先存储应答文本。在一些情况下,响应于检测到运营人员执行应答文本保存操作,上述执行主体可以获取保存的应答文本。
33.之后,上述执行主体可以对上述应答文本进行分割,得到多个句子文本。在这里,上述执行主体可以以应答文本的停顿标点(例如,逗号、句号、顿号、感叹号和问号等)作为分割标点,对上述应答文本进行分割。
34.步骤202,针对多个句子文本中的每个句子文本,将该句子文本转换成语音,基于转换得到的音频,执行如下纠正步骤:确定转换得到的音频的带声调拼音,以及确定带声调拼音的发音时长;基于带声调拼音和预设的拼音无向图,生成目标文本,其中,目标文本为不存在错误声调的文本;确定目标文本中是否存在发音时长大于预设的发音时长阈值的文字,若不存在,则生成该句子文本对应的纠正后的文本。
35.在本实施例中,针对在步骤201中得到的多个句子文本中的每个句子文本,上述执行主体可以利用tts技术将该句子文本转换成语音。而后,可以基于转换得到的音频,执行纠正步骤。
36.在本实施例中,步骤202可以包括子步骤2021、2022、2023。其中:
37.步骤2021,确定转换得到的音频的带声调拼音。
38.在这里,上述执行主体可以确定转换得到的音频的带声调拼音。带声调拼音通常包括拼音和拼音声调。作为示例,上述执行主体可以将转换得到的音频输入预先训练的拼音识别模型中,得到转换得到的音频的带声调拼音。上述拼音识别模型可以用于表征音频与音频的带声调拼音之间的对应关系。
39.步骤2022,确定带声调拼音的发音时长。
40.在这里,上述执行主体可以确定在步骤2021中得到的带声调拼音中每个拼音的发音时长。针对带声调拼音中的每个拼音,上述执行主体可以将该拼音输入预先训练的发音时长识别模型中,得到该拼音的发音时长。上述发音时长识别模型可以用于表征拼音与拼音的发音时长之间的对应关系。
41.步骤2023,基于带声调拼音和预设的拼音无向图,生成目标文本。
42.在这里,上述执行主体可以基于在步骤2021中确定出的带声调拼音和预设的拼音无向图,生成目标文本。上述拼音无向图也可以称为错音无向图,通常是由运营人员在不同业务场景下,总结出来的易错组合和其对应的修正拼音(在当前场景下的正确读音)。拼音无向图中的节点可以用于表征易错组合中的文字的拼音,无向图中的边可以用于连接表征两个相邻文字的拼音的节点。上述执行主体可以在预设的拼音无向图中查找是否存在与带声调拼音相匹配的字符串,若不存在,则将该句子文本作为目标文本。若存在,则可以在预设的单音字字典中查找匹配到的字符串中的纠正的拼音所对应的单音字,将该句子文本中对应于匹配到的字符串中的纠正的拼音所指示的文字替换成该单音字,得到目标文本。
43.如图3所示,图3示出了易错组合和易错组合中的错音及修正音之间的对应关系的对应关系表。在图3中,以易错组合“客服专员”为例,“客服专员”中的“专”在文字转语音过程中出现错误的概率通常较大,“专”字所对应的错音为“zhu
à
n”,“专”字所对应的修正音为“zhu
ā
n”,通常放在括号中。“客”、“服”、“员”这三个字通常不易出现错误,在图3中,括号中通常可以放入相应的文字,在放入每个文字的括号之前可以显示对应的正确拼音。如图3所示,易错组合“客服专员”对应的错音及修正音为“k
è
(客)f
ú
(服)zhu
à
n(zhu
ā
n)yu
á
n(员)”。
44.如图4所示,图4示出了易错组合与拼音无向图之间的对应关系的对应关系表。在图4中,无向图中的节点用于表征易错组合中的文字的拼音,无向图中的边用于连接表征两个相邻文字的拼音的节点。
45.在这里,上述目标文本通常为不存在错误声调的文本。这里的错误声调通常与语音问答场景相关联。例如,在视频直播场景中,“弹幕”中的“弹”的声调为四声。
46.步骤2024,确定目标文本中是否存在发音时长大于预设的发音时长阈值的文字。
47.在这里,上述执行主体可以确定上述目标文本中是否存在发音时长大于预设的发音时长阈值(例如,0.5秒)的文字。若不存在,则上述执行主体可以执行步骤2025。
48.步骤2025,若不存在发音时长大于发音时长阈值的文字,则生成该句子文本对应的纠正后的文本。
49.在这里,若在步骤2024中确定出不存在发音时长大于上述发音时长阈值的文字,则上述执行主体可以生成该句子文本对应的纠正后的文本。具体地,上述执行主体可以将上述目标文本确定为该句子文本对应的纠正后的文本。
50.步骤203,按照多个句子文本在应答文本中由前到后的顺序,合并对应的纠正后的文本,得到纠正后的应答文本。
51.在本实施例中,上述执行主体可以按照上述多个句子文本在应答文本中由前到后的顺序,合并对应的纠正后的文本,得到纠正后的应答文本。作为示例,若将应答文本进行分割,得到由前到后的多个句子文本:句子文本a、句子文本b和句子文本c。若句子文本a对应于纠正后的文本a1、句子文本b对应于纠正后的文本b1、句子文本c对应于纠正后的文本c1,则合并得到的纠正后的应答文本为a1b1c1。
52.在这里,上述执行主体可以将纠正后的应答文本保存为用于播放的答案文本,如用于输出到tts模块进行文本转语音播放应答。而原应答文本(获取到的应答文本)可以用于答案配置界面显示给运营人员作为参考。
53.本技术的上述实施例提供的方法通过识别带声调拼音及发音时长,然后使用无向图匹配的方式替换错音字,然后判断发音时长是否超过阈值来替换错误停顿的字,最终实现文本转语音过程中的发音纠错和停顿纠错,提升用户语音交互体验。
54.在本实施例的一些可选的实现方式中,若在步骤2024中确定出存在发音时长大于上述发音时长阈值的文字,则上述执行主体可以将发音时长大于上述发音时长阈值的文字替换为其它单音字。tts音频的发音应该是匀速的,但是会有转换得到的语音在某个固定短语的表达上出现停顿,只要将停顿出现的字换为其他字,就能避免停顿。上述其它单音字通常与被替换的文字对应于相同的带声调拼音。作为示例,若文本“客服专员会在24小时内联系您”中的“会”字的发音时长0.6秒大于发音时长阈值0.5秒,则上述执行主体可以在预设的单音字字典中查找“hu
ì”
对应的单音字,例如,“汇”。上述执行主体可以将“会”子替换为“汇”字,得到替换后的文本“客服专员汇在24小时内联系您”。而后,上述执行主体可以将替换后的文本进行文本转语音操作,继续执行上述纠正步骤,即步骤2021-2025。通过这种方式可以在发音时长超过阈值的情况下,对文字进行替换,针对替换后的文本继续执行纠正步骤,直到文本不存在错误发音和错误停顿的问题。
55.在本实施例的一些可选的实现方式中,上述执行主体可以通过如下方式确定带声调拼音的发音时长:针对带声调拼音中的每个拼音,上述执行主体可以确定该拼音所对应的音频帧的个数。之后,可以将该拼音所对应的音频帧的个数与音频帧的时长的乘积确定为该拼音的发音时长。作为示例,若音频帧的时长为20ms,拼音k
è
对应12个音频帧,即拼音k
è
由12个音频帧所组成,则该拼音的发音时长为12与20的乘积240ms。
56.继续参见图5,图5是根据本实施例的用于纠正文本的方法的一个应用场景的示意图。在图5的应用场景中,服务器501首先获取应答文本,在这里,应答文本为“请您耐心等待,客服专员会在24小时内联系您”,如图标502所示。服务器501对应答文本进行分割,得到两个句子文本“请您耐心等待”和“客服专员会在24小时内联系您”,如图标503所示。而后,以句子文本“客服专员会在24小时内联系您”作为示例,服务器501将“客服专员会在24小时内联系您”转换成语音,基于转换得到的语音,执行如下纠正步骤:服务器501确定转换得到的音频的带声调拼音以及确定带声调拼音的发音时长。在这里,音频的带声调拼音以及发
activity detection,vad),从而可以将转换得到的音频的首尾两端的静音和干扰切除。静音抑制也可以称为语音活动检测、语音端点检测和语音边界检测。之后,可以对静音抑制后的音频进行分帧,得到多帧音频。例如,可以以预设分割时长对转换得到的音频进行切分,切分的得到的每一段为一个音频帧。例如,可以以移动窗函数实现音频的切分。
69.进一步参考图7,其示出了用于纠正文本的方法中生成目标文本的一个实施例的流程700。该生成目标文本的流程700,包括以下步骤:
70.步骤701,利用双向匹配算法,对预设的拼音无向图进行遍历,确定预设的拼音无向图中是否存在与音频的带声调拼音相匹配的匹配结果。
71.在本实施例中,用于纠正文本的方法的执行主体(例如图1所示的服务器)可以利用双向匹配算法,对预设的拼音无向图进行遍历,确定上述拼音无向图中是否存在与上述音频的带声调拼音相匹配的匹配结果。双向匹配算法包含了正向最大匹配算法和逆向最大匹配算法,正向最大匹配算法是从左往右进行匹配,而逆向最大匹配算法是从右往左进行匹配,因此,双向匹配算法既从左往右进行匹配,又从右往左进行匹配。双向匹配算法的性能和效率通常高于单向匹配算法。上述拼音无向图也可以称为错音无向图,通常是由运营人员在不同业务场景下,总结出来的易错组合和其对应的修正拼音(在当前场景下的正确读音)。拼音无向图中的节点用于表征易错组合中的文字的拼音,无向图中的边用于连接表征两个相邻文字的拼音的节点。在这里,上述执行主体可以对上述拼音无向图进行从左往右以及从右往左的双向匹配,从而确定上述拼音无向图中是否存在与上述音频的带声调拼音相匹配的匹配结果。在这里,匹配结果可以包括纠正结果,匹配结果还可以包括带声调拼音对应的文字。纠正结果可以包括纠正的拼音,即正确的拼音。
72.作为示例,若音频的带声调拼音为“k
èꢀ
f
úꢀ
zhu
à
n yu
á
n”,上述执行主体可以确定出匹配结果为“客服zhu
ā
n员”,其中,“zhu
ā
n”为纠正的拼音。
73.若确定出存在与上述音频的带声调拼音相匹配的匹配结果,则上述执行主体可以执行步骤702。
74.步骤702,响应于确定出存在与音频的带声调拼音相匹配的匹配结果,确定存在的匹配结果中的纠正结果是否包括纠正的拼音。
75.在本实施例中,若在步骤701中确定出存在与上述音频的带声调拼音相匹配的匹配结果,则上述执行主体可以确定存在的匹配结果中的纠正结果是否包括纠正的拼音。作为示例,若匹配结果为“客服zhu
ā
n员”,则匹配结果“客服zhu
ā
n员”中的“zhu
ā
n”为纠正的拼音,可以确定出纠正结果包括纠正的拼音。
76.若确定出存在的匹配结果中的纠正结果包括纠正的拼音,则上述执行主体可以执行步骤703。
77.步骤703,响应于确定出存在的匹配结果中的纠正结果包括纠正的拼音,利用预设的单音字映射表,查找与纠正的拼音相对应的单音字对纠正的拼音进行替换,生成纠正后的文本。
78.在本实施例中,若在步骤702中确定出存在的匹配结果中的纠正结果包括纠正的拼音,则上述执行主体可以利用预设的单音字映射表,查找与上述纠正的拼音相对应的单音字对纠正的拼音进行替换,生成纠正后的文本。上述纠正后的文本包括纠正标识(如,adjust),上述纠正标识用于指示替换后的单音字。
79.在这里,只有一个读音的字为单音字。上述单音字映射表可以为预先从预设的字库(例如,新华字典)中挖掘出的、用于表征单音字与单音字的拼音之间的对应关系的对应关系表。
80.作为示例,可以从单音字映射表中查找到与“zhu
ā
n”对应的单音字“砖”,之后,利用“砖”对“客服zhu
ā
n员”中的“zhu
ā
n”进行替换,得到“客服砖(adjust)员”,其中,纠正标识adjust用于指示“砖”为替换后的单音字。
81.步骤704,利用纠正后的文本,对该句子文本进行纠正,得到目标文本。
82.在本实施例中,上述执行主体可以利用上述纠正后的文本,对该句子文本进行纠正,得到目标文本。具体地,上述执行主体可以以上述纠正后的文本中未被纠正的文字作为基准文字,确定上述纠正后的文本中在该基准文字之前的字符的数量以及在该基准文字之后的字符的数量,之后,从该句子文本中查找出上述基准文字,以该基准文字为基准,可以查找出待纠正的字符串,将该句子文本中的待纠正的字符串替换成上述纠正后的文本,得到目标文本。
83.本技术的上述实施例提供的方法通过利用双向匹配算法,对预设的拼音无向图进行遍历,若拼音无向图中存在与音频的带声调拼音相匹配的匹配结果,且匹配结果中的纠正结果包括纠正的拼音,则可以利用预设的单音字映射表,查找与纠正的拼音相对应的单音字对纠正的拼音进行替换,生成纠正后的文本,而后可以利用上述纠正后的文本,对该句子文本进行纠正,从而提供了一种文本纠正方法,提高了文本纠正的效果和效率。
84.在本实施例的一些可选的实现方式中,上述执行主体可以通过如下方式利用上述纠正后的文本,对该句子文本进行纠正:上述执行主体可以将上述纠正后的文本中对应于纠正标识的文字替换为通配符,得到待匹配文本。通配符是一种特殊语句,主要有星号(*)和问号(?),用来模糊搜索文件。当不知道真正字符或者懒得输入完整名字时,常常可以使用通配符代替一个或多个真正的字符。之后,可以利用字符串匹配算法,在该句子文本中查找上述待匹配文本所在的位置,将查找到的位置上的字符串替换为上述纠正后的文本。上述字符串匹配算法可以包括kmp(the knuth-morris-pratt algorithm)算法,kmp算法的核心是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。具体实现就是通过一个next()函数实现,函数本身包含了模式串的局部匹配信息。作为示例,可以将“客服砖(adjust)员”中对应于纠正标识adjust的文字“砖”替换为通配符*,得到“客服*员”;之后,可以在句子文本“客服专员会在24小时内联系您”中查找到“客服*员”所在的位置,并利用“客服砖员”进行替换,得到“客服砖员会在24小时内联系您”。
85.进一步参考图8,作为对上述各图所示方法的实现,本技术提供了一种用于纠正文本的装置的一个实施例,该装置实施例与图2所示的方法实施例相对应,该装置具体可以应用于各种电子设备中。
86.如图8所示,本实施例的用于纠正文本的装置800包括:获取单元801、纠正单元802和合并单元803。其中,获取单元801被配置成获取应答文本,对应答文本进行分割,得到多个句子文本;纠正单元802被配置成针对多个句子文本中的每个句子文本,将该句子文本转换成语音,基于转换得到的音频,执行如下纠正步骤:确定转换得到的音频的带声调拼音,以及确定带声调拼音的发音时长;基于带声调拼音和预设的拼音无向图,生成目标文本,其中,目标文本为不存在错误声调的文本;确定目标文本中是否存在发音时长大于预设的发
音时长阈值的文字,若不存在,则生成该句子文本对应的纠正后的文本;合并单元803被配置成按照多个句子文本在应答文本中由前到后的顺序,合并对应的纠正后的文本,得到纠正后的应答文本。
87.在本实施例中,用于纠正文本的装置800的获取单元801、纠正单元802和合并单元803的具体处理可以参考图2对应实施例中的步骤201、步骤202和步骤203。
88.在本实施例的一些可选的实现方式中,上述用于纠正文本的装置800还可以包括反馈单元(图中未示出)。若确定出存在发音时长大于上述发音时长阈值的文字,则上述反馈单元可以将发音时长大于上述发音时长阈值的文字替换为其它单音字。tts音频的发音应该是匀速的,但是会有转换得到的语音在某个固定短语的表达上出现停顿,只要将停顿出现的字换为其他字,就能避免停顿。上述其它单音字通常与被替换的文字对应于相同的带声调拼音。作为示例,若文本“客服专员会在24小时内联系您”中的“会”字的发音时长0.6秒大于发音时长阈值0.5秒,则上述反馈单元可以在预设的单音字字典中查找“hu
ì”
对应的单音字,例如,“汇”。上述反馈单元可以将“会”子替换为“汇”字,得到替换后的文本“客服专员汇在24小时内联系您”。而后,上述反馈单元可以将替换后的文本进行文本转语音操作,继续执行上述纠正步骤,即步骤2021-2025。
89.在本实施例的一些可选的实现方式中,上述纠正单元802可以通过如下方式确定转换得到的音频的带声调拼音:上述纠正单元802可以基于转换得到的音频,生成多帧音频。上述纠正单元802可以以预设分割时长对转换得到的音频进行切分,切分的得到的每一段为一个音频帧。例如,可以以移动窗函数实现音频的切分。上述纠正单元802可以提取上述多帧音频中每帧音频的音频特征向量。作为示例,可以选择线性预测倒谱系数或者梅尔频率倒谱系数进行特征提取,从而把每一帧音频从模拟波形转换为数字的音频多维向量。之后,上述纠正单元802可以将上述音频特征向量输入预设的声学模型中,得到多帧音频的音素数据。上述声学模型可以对音频数据进行音素识别提供给后续模型使用。音素是根据语音的自然属性划分出来的最小语音单位,依据音节里的发音动作来分析,一个动作构成一个音素。上述纠正单元802可以利用预设的音素字典,获取与上述音素数据对应的带声调拼音。在这里,上述音素字典可以用于表征音素数据与带声调拼音之间的对应关系。
90.在本实施例的一些可选的实现方式中,上述纠正单元802可以通过如下方式确定带声调拼音的发音时长:针对带声调拼音中的每个拼音,上述纠正单元802可以确定该拼音所对应的音频帧的个数。之后,可以将该拼音所对应的音频帧的个数与音频帧的时长的乘积确定为该拼音的发音时长。作为示例,若音频帧的时长为20ms,拼音k
è
对应12个音频帧,即拼音k
è
由12个音频帧所组成,则该拼音的发音时长为12与20的乘积240ms。
91.在本实施例的一些可选的实现方式中,上述纠正单元802可以基于上述带声调拼音和预设的拼音无向图,生成目标文本:上述纠正单元802可以利用双向匹配算法,对预设的拼音无向图进行遍历,确定上述拼音无向图中是否存在与上述音频的带声调拼音相匹配的匹配结果。双向匹配算法包含了正向最大匹配算法和逆向最大匹配算法,正向最大匹配算法是从左往右进行匹配,而逆向最大匹配算法是从右往左进行匹配,因此,双向匹配算法既从左往右进行匹配,又从右往左进行匹配。在这里,上述纠正单元802可以对上述拼音无向图进行从左往右以及从右往左的双向匹配,从而确定上述拼音无向图中是否存在与上述音频的带声调拼音相匹配的匹配结果。在这里,匹配结果可以包括纠正结果,匹配结果还可
以包括带声调拼音对应的文字。纠正结果可以包括纠正的拼音,即正确的拼音。
92.若确定出存在与上述音频的带声调拼音相匹配的匹配结果,则上述纠正单元802可以确定存在的匹配结果中的纠正结果是否包括纠正的拼音。作为示例,若匹配结果为“客服zhu
ā
n员”,则匹配结果“客服zhu
ā
n员”中的“zhu
ā
n”为纠正的拼音,可以确定出纠正结果包括纠正的拼音。
93.若确定出存在的匹配结果中的纠正结果包括纠正的拼音,则上述纠正单元802可以利用预设的单音字映射表,查找与上述纠正的拼音相对应的单音字对纠正的拼音进行替换,生成纠正后的文本。上述纠正后的文本包括纠正标识(如,adjust),上述纠正标识用于指示替换后的单音字。
94.作为示例,可以从单音字映射表中查找到与“zhu
ā
n”对应的单音字“砖”,之后,利用“砖”对“客服zhu
ā
n员”中的“zhu
ā
n”进行替换,得到“客服砖(adjust)员”,其中,纠正标识adjust用于指示“砖”为替换后的单音字。
95.最后,上述纠正单元802可以利用上述纠正后的文本,对该句子文本进行纠正,得到目标文本。具体地,上述纠正单元802可以以上述纠正后的文本中未被纠正的文字作为基准文字,确定上述纠正后的文本中在该基准文字之前的字符的数量以及在该基准文字之后的字符的数量,之后,从该句子文本中查找出上述基准文字,以该基准文字为基准,可以查找出待纠正的字符串,将该句子文本中的待纠正的字符串替换成上述纠正后的文本,得到目标文本。
96.在本实施例的一些可选的实现方式中,上述纠正单元802可以通过如下方式利用上述纠正后的文本,对该句子文本进行纠正:上述纠正单元802可以将上述纠正后的文本中对应于纠正标识的文字替换为通配符,得到待匹配文本。通配符是一种特殊语句,主要有星号(*)和问号(?),用来模糊搜索文件。当不知道真正字符或者懒得输入完整名字时,常常可以使用通配符代替一个或多个真正的字符。之后,可以利用字符串匹配算法,在该句子文本中查找上述待匹配文本所在的位置,将查找到的位置上的字符串替换为上述纠正后的文本。上述字符串匹配算法可以包括kmp算法,kmp算法的核心是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。具体实现就是通过一个next()函数实现,函数本身包含了模式串的局部匹配信息。作为示例,可以将“客服砖(adjust)员”中对应于纠正标识adjust的文字“砖”替换为通配符*,得到“客服*员”;之后,可以在句子文本“客服专员会在24小时内联系您”中查找到“客服*员”所在的位置,并利用“客服砖员”进行替换,得到“客服砖员会在24小时内联系您”。
97.在本实施例的一些可选的实现方式中,上述纠正单元802可以通过如下方式基于转换得到的音频,生成多帧音频:上述纠正单元802可以对转换得到的音频进行静音抑制,从而可以将转换得到的音频的首尾两端的静音和干扰切除。静音抑制也可以称为语音活动检测、语音端点检测和语音边界检测。之后,上述纠正单元802可以对静音抑制后的音频进行分帧,得到多帧音频。例如,可以以预设分割时长对转换得到的音频进行切分,切分的得到的每一段为一个音频帧。例如,可以以移动窗函数实现音频的切分。
98.下面参考图9,其示出了适于用来实现本公开的实施例的电子设备(例如图1中的服务器)900的结构示意图。图9示出的服务器仅仅是一个示例,不应对本公开的实施例的功能和使用范围带来任何限制。
99.如图9所示,电子设备900可以包括处理装置(例如中央处理器、图形处理器等)901,其可以根据存储在只读存储器(rom)902中的程序或者从存储装置908加载到随机访问存储器(ram)903中的程序而执行各种适当的动作和处理。在ram 903中,还存储有电子设备900操作所需的各种程序和数据。处理装置901、rom 902以及ram903通过总线904彼此相连。输入/输出(i/o)接口905也连接至总线904。
100.通常,以下装置可以连接至i/o接口905:包括例如触摸屏、触摸板、键盘、鼠标、摄像头、麦克风、加速度计、陀螺仪等的输入装置906;包括例如液晶显示器(lcd)、扬声器、振动器等的输出装置907;包括例如磁带、硬盘等的存储装置908;以及通信装置909。通信装置909可以允许电子设备900与其他设备进行无线或有线通信以交换数据。虽然图9示出了具有各种装置的电子设备900,但是应理解的是,并不要求实施或具备所有示出的装置。可以替代地实施或具备更多或更少的装置。图9中示出的每个方框可以代表一个装置,也可以根据需要代表多个装置。
101.特别地,根据本公开的实施例,上文参考流程图描述的过程可以被实现为计算机软件程序。例如,本公开的实施例包括一种计算机程序产品,其包括承载在计算机可读介质上的计算机程序,该计算机程序包含用于执行流程图所示的方法的程序代码。在这样的实施例中,该计算机程序可以通过通信装置909从网络上被下载和安装,或者从存储装置908被安装,或者从rom 902被安装。在该计算机程序被处理装置901执行时,执行本公开的实施例的方法中限定的上述功能。需要说明的是,本公开的实施例所述的计算机可读介质可以是计算机可读信号介质或者计算机可读存储介质或者是上述两者的任意组合。计算机可读存储介质例如可以是——但不限于——电、磁、光、电磁、红外线、或半导体的系统、装置或器件,或者任意以上的组合。计算机可读存储介质的更具体的例子可以包括但不限于:具有一个或多个导线的电连接、便携式计算机磁盘、硬盘、随机访问存储器(ram)、只读存储器(rom)、可擦式可编程只读存储器(eprom或闪存)、光纤、便携式紧凑磁盘只读存储器(cd-rom)、光存储器件、磁存储器件、或者上述的任意合适的组合。在本公开的实施例中,计算机可读存储介质可以是任何包含或存储程序的有形介质,该程序可以被指令执行系统、装置或者器件使用或者与其结合使用。而在本公开的实施例中,计算机可读信号介质可以包括在基带中或者作为载波一部分传播的数据信号,其中承载了计算机可读的程序代码。这种传播的数据信号可以采用多种形式,包括但不限于电磁信号、光信号或上述的任意合适的组合。计算机可读信号介质还可以是计算机可读存储介质以外的任何计算机可读介质,该计算机可读信号介质可以发送、传播或者传输用于由指令执行系统、装置或者器件使用或者与其结合使用的程序。计算机可读介质上包含的程序代码可以用任何适当的介质传输,包括但不限于:电线、光缆、rf(射频)等等,或者上述的任意合适的组合。
102.上述计算机可读介质可以是上述电子设备中所包含的;也可以是单独存在,而未装配入该电子设备中。上述计算机可读介质承载有一个或者多个程序,当上述一个或者多个程序被该电子设备执行时,使得该电子设备:获取应答文本,对应答文本进行分割,得到多个句子文本;针对多个句子文本中的每个句子文本,将该句子文本转换成语音,基于转换得到的音频,执行如下纠正步骤:确定转换得到的音频的带声调拼音,以及确定带声调拼音的发音时长;基于带声调拼音和预设的拼音无向图,生成目标文本,其中,目标文本为不存在错误声调的文本;确定目标文本中是否存在发音时长大于预设的发音时长阈值的文字,
若不存在,则生成该句子文本对应的纠正后的文本;按照多个句子文本在应答文本中由前到后的顺序,合并对应的纠正后的文本,得到纠正后的应答文本。
103.可以以一种或多种程序设计语言或其组合来编写用于执行本公开的实施例的操作的计算机程序代码,程序设计语言包括面向对象的程序设计语言—诸如java、smalltalk、c ,还包括常规的过程式程序设计语言—诸如“c”语言或类似的程序设计语言。程序代码可以完全地在用户计算机上执行、部分地在用户计算机上执行、作为一个独立的软件包执行、部分在用户计算机上部分在远程计算机上执行、或者完全在远程计算机或服务器上执行。在涉及远程计算机的情形中,远程计算机可以通过任意种类的网络——包括局域网(lan)或广域网(wan)——连接到用户计算机,或者,可以连接到外部计算机(例如利用因特网服务提供商来通过因特网连接)。
104.附图中的流程图和框图,图示了按照本公开各种实施例的系统、方法和计算机程序产品的可能实现的体系架构、功能和操作。在这点上,流程图或框图中的每个方框可以代表一个模块、程序段、或代码的一部分,该模块、程序段、或代码的一部分包含一个或多个用于实现规定的逻辑功能的可执行指令。也应当注意,在有些作为替换的实现中,方框中所标注的功能也可以以不同于附图中所标注的顺序发生。例如,两个接连地表示的方框实际上可以基本并行地执行,它们有时也可以按相反的顺序执行,这依所涉及的功能而定。也要注意的是,框图和/或流程图中的每个方框、以及框图和/或流程图中的方框的组合,可以用执行规定的功能或操作的专用的基于硬件的系统来实现,或者可以用专用硬件与计算机指令的组合来实现。
105.描述于本公开的实施例中所涉及到的单元可以通过软件的方式实现,也可以通过硬件的方式来实现。所描述的单元也可以设置在处理器中,例如,可以描述为:一种处理器包括获取单元、纠正单元和合并单元。其中,这些单元的名称在某种情况下并不构成对该单元本身的限定,例如,获取单元还可以被描述为“获取应答文本,对应答文本进行分割,得到多个句子文本的单元”。
106.以上描述仅为本公开的较佳实施例以及对所运用技术原理的说明。本领域技术人员应当理解,本公开的实施例中所涉及的发明范围,并不限于上述技术特征的特定组合而成的技术方案,同时也应涵盖在不脱离上述发明构思的情况下,由上述技术特征或其等同特征进行任意组合而形成的其它技术方案。例如上述特征与本公开的实施例中公开的(但不限于)具有类似功能的技术特征进行互相替换而形成的技术方案。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。