1.本发明涉及一种源代码对抗样本生成技术,具体地说是一种面向源代码分类模型的对抗样本生成方法。
背景技术:
2.为了满足当前工业发展的迫切需求,人们越来越多地将深度学习应用于源代码分类领域,进行相应的处理和分析,如按功能自动标记程序库中的源代码,将有助于开发使用时软件程序的重用。使用深度学习模型来完成程序源代码的自动处理、分析和生成,可以大大降低软件的系统开发、测试、操作以及维护等方面的成本。但是,深度学习模型存在一个非常严重的安全风险,即缺乏鲁棒性。而解决这一风险的方法可以通过研究对抗学习来实现。对抗学习包括对抗攻击和对抗样本生成。
3.起初,对抗样本生成多应用于图像领域和自然语言处理领域。图像领域主要集中在攻击图的结构,认为图的节点是固定的,通过添加或删除边来实现有效攻击,生成对抗样本。自然语言处理领域由于语言空间的离散性,对抗样本的生成较图像领域而言是相当困难的,多采用单词级替换或字符级翻转来生成对抗样本。但是,由于源代码不仅具有离散性特征,还具有很强的结构性,而对抗样本需遵循严格的词法、语法和语法规则的约束。
4.目前源代码分类领域对抗样本的生成方法主要包括对抗样本生成对抗操作和对抗样本生成操作执行策略。
5.对抗样本生成对抗操作就是对源代码执行对抗操作来生成对抗样本,对抗样本主要是对源代码进行一系列操作后,生成与原代码语义一致但会致使目标分类模型产生错误结果输出的样本。目前主要实现了对源代码执行标识符替换、同义表达式替换以及死代码的插入等操作,通过对源代码执行以上类型的对抗操作,来生成对抗样本。但是根据研究发现,目前应用最广泛的和最新的功能分类模型,与传统基于文本或标记的分类方法不同,更多的是基于捕获更多的语法结构信息来对源代码功能进行分类。也有研究结果证明,通常程序代码结构中包含更多的语义信息,目前的生成方式中仍缺乏对程序代码结构信息的处理和干扰。
6.对抗样本生成操作执行策略就是当获取到生成对抗样本所需的对抗操作序列时,需要将其按照设定的策略来有序执行这些操作。目前的对抗样本生成策略主要选择随机方法和枚举方法来完成。随机方法实现起来较为容易,但具有较强的随机性,通常无法在短时间内实现更有效的对抗。枚举方法在执行操作时覆盖比较全面,但同时其计算量也会增加。因此,无目的无指引的进行枚举,会带来较大的时间和资源的消耗。
7.因此,现有的源代码分类领域对抗样本生成方法存在的主要缺点,一是针对现有的最新的和应用最广泛的源代码分类模型工作原理,代码的高度离散性和结构化的特征,现有方法中对抗样本生成执行的对抗操作过于简单单一;二是在实现对抗样本生成的过程中,现有法中对抗样本生成操作执行策略效率低,时间和资源消耗大。
技术实现要素:
8.本发明的目的就是提供一种面向源代码分类模型的对抗样本生成方法,以解决现有生成方法存在的对抗操作过于单一以及操作执行策略效率低和消耗大的问题。
9.本发明是这样实现的:一种面向源代码分类模型的对抗样本生成方法,包括以下步骤:a、数据预处理:对于原始代码以及所选的目标分类模型,先进行代码片段预处理,即将源代码处理成token序列,或是使用srcml工具将源代码处理成为xml格式;b、代码转换方式的提取:从测试集中提取一对源代码样本<x,y>,将其初始状态记为s0;提取每个源代码样本的转换特征,得到对应的可执行转换序列a,限制当前源代码整个迭代攻击过程中的转换操作,并建立属于当前可执行转换序列a的转换操作价值表q(a),用于记录每个转换操作ai(ai∈a,1≤i≤k)的对应价值,以指导各操作的选择执行;c、候选转换方式的选择:参照转换操作价值表q(a),使用
ϵ
‑
贪心算法选择对源代码样本的执行转换,转换操作价值表q(a)中存储着当前可执行转换序列a中的所有可执行转换以及不断更新的对应权值,用以衡量当前源代码转换至某状态时,选择何种转换操作可获得最高的期望奖励值;d、执行转换:对源代码样本x,应用执行步骤c中选择的转换操作,生成新的转换后的代码段x
′
;e、攻击测试:将步骤d生成的新的代码段x
′
送入目标分类模型进行攻击测试,如果致使分类结果与原功能标签不同,则表示攻击成功,停止当前迭代;否则为攻击失败,重复步骤c和步骤d;f、奖励机制:每次攻击测试即获取一个奖励值rt并累加,同时更新转换操作价值表q(a),用以指导后续的攻击。
10.进一步的,步骤a中在数据预处理后,使用pandas对数据进行封装。
11.进一步的,步骤c中的选择转换操作的具体方式是:设定一个阈值
ϵ
,每次操作选择之前产生一个随机数,如果该随机数高于阈值
ϵ
,则选择当前状态下执行奖励值最高的转换操作;如果该随机数低于阈值
ϵ
,则随机选择当前可执行转换序列a中的任意操作执行。
12.进一步的,步骤f的具体方式是:在将新的代码段x
′
送入原分类模型进行攻击测试后,得到当前状态下的一个奖励值rt,如果新转换后得到的样本没有得到一个正向的奖励,则放弃当前样本,将下次迭代被攻击样本转换为本次变换前的样本;所有奖励值累加,得到目前样本序列的累计奖励值,并通过奖励值来更新转换操作价值表q(a)。
13.进一步的,所述奖励值是通过计算模型分类概率标签值计算得出。
14.进一步的,所述正向奖励是指有助于误导目标分类模型,其是通过计算目标标签分类概率的降低程度来得到的。
15.本发明针对现有对抗样本生成方法的缺点和不足,针对源代码的结构信息,提取出可执行的对抗操作,并引入了马尔可夫决策过程和时序差分算法的思想,在执行对抗操作的同时,加入操作的影响系数来引导操作的选择执行,通过决策学习来不断完善对抗生成方法,由此实现了一种更为快捷、更为有效的对抗样本生成方法。
16.本发明的整体思路在于,针对源代码的离散化和结构化的特征,并结合现有最新的源代码分类深度学习模型的工作特点,通过提取源代码丰富的结构信息,对源代码执行
结构上的转换来生成对抗样本。引入深度学习的思想,不断学习更有效的转换方式组合,依次来实现更为快捷、更为有效的对抗。
17.本发明面向源代码分类模型的对抗样本生成方法的优点在于:(1)对抗操作的多样化:针对源代码结构化特征以及现有最新的和应用最广泛的模型分类工作特点,以多种针对代码结构的转换作为对抗操作,约定转换后仍满足代码语义和语法的约束,以有效地生成对抗样本,在不改变源代码正确输出的条件下,可以攻击dl模型致使错误结果;(2)操作执行的有限性:使用基于q
‑
learning的马尔可夫决策过程来实现对源代码的对抗攻击,可以有效地解决代码搜索空间爆炸的问题,将搜索次数控制在有限次数范围之内,实现更快更有效的攻击;(3)选择策略的有效性:使用时序差分算法来解决整个实验决策过程的控制问题,加入奖励机制,用转换价值不断更新转换策略,通过不断学习,实现更快更有效的攻击。
18.(4)可扩展性强:本发明在对抗攻击方案上采用有探针的黑盒攻击方式,无需像白盒攻击使用模型架构和内部参数等信息,只需获取模型类别标签概率的值,用来指导对抗示例生成,并且可以来避免无探针的黑盒攻击搜索次数过多的弊端,可以方便有效的应用在多个深度学习模型上,适配性好,可扩展性强。
附图说明
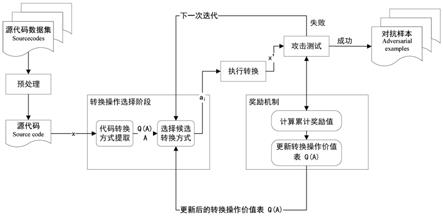
19.图1是对抗样本生成流程图。
20.图2是选择代码转换阶段展开示意图。
21.图3是本发明的一个实例展示图。
具体实施方式
22.下面结合附图和实例对本发明做进一步详述。应当理解,此处所描述的具体实例仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互结合。
23.如图1所示,本发明面向源代码分类模型的对抗样本生成方法包括以下步骤:步骤1. 数据预处理:对于原始代码,在执行之后的所有操作之前,先进行代码片段预处理。针对所选的目标分类模型,对源代码可进行以下两种处理:一种是序列化源代码,将源代码处理成token序列;另一种是使用srcml工具,将源代码处理为xml格式,以方便进行对抗和还原。数据预处理后,使用pandas对数据进行封装。
24.如图2所示,本发明的步骤2和步骤3组成了代码转换操作和选择阶段。
25.步骤2. 代码转换方式的提取:如图2中的第(1)部分所示,从测试集中提取一对源代码样本<x,y>,将其初始状态记为s0。通过对其中每个源代码样本进行转换特征的提取,得到对应的可执行转换序列a,限制当前源代码整个迭代攻击过程中的转换操作,并建立属于当前可执行转换序列a的转换操作价值表q(a),用于记录每个转换操作ai(ai∈a,1≤i≤k)的对应价值,以指导各转换操作的选择执行。
26.步骤3. 候选转换方式的选择:参照转换操作价值表q(a),使用
ϵ
‑
贪心算法选择对源代码样本的执行转换,转换操作价值表q(a)中存储着当前可执行转换序列a中的所有可
执行转换以及不断更新的对应权值,用以衡量当前源代码转换至某状态时,选择何种转换操作可获得最高的期望奖励值。
27.选择转换操作的具体方式是:设定一个阈值
ϵ
,每次操作选择之前产生一个随机数,如果该随机数高于阈值
ϵ
,则选择当前状态下执行奖励值最高的转换操作;如果该随机数低于阈值
ϵ
,则随机选择当前可执行转换序列a中的任意操作执行。
28.步骤4. 执行转换:如图3所示,对于源代码样本x,将步骤3中选择的候选转换方式应用执行,生成新的转换后的代码段x
′
。
29.步骤5. 攻击测试:将步骤4生成的新的代码段x
′
送入目标分类模型进行攻击测试,如果致使分类结果与原功能标签不同,则表示攻击成功,停止当前迭代;否则判为攻击失败,重复步骤3和步骤4。
30.步骤6. 奖励机制:每次攻击测试即获取一个奖励值rt并累加,同时更新转换操作价值表q(a),用以指导后续的攻击。其具体方式是:在将新的代码段x
′
送入原目标分类模型进行攻击测试后,得到当前状态下的一个奖励值rt,该奖励值rt是通过计算模型分类概率标签值计算得出,通过使用增量式计算平均奖赏的方式,可以得到新状态下每种转换操作对应的平均奖励值,这个平均奖励值与执行的转换操作和转换操作执行的次数均相关,因此可以有效的实现发明目的。如果新转换后得到的样本没有得到一个正向的奖励,则放弃当前样本,将下次迭代被攻击样本转换为本次变换前的样本。所有奖励值累加,得到目前样本序列的累计奖励值,并通过奖励值来更新转换操作价值表q(a)。
31.所述正向奖励是指有助于误导目标分类模型,正向奖励是通过计算目标标签分类概率的降低程度来得到的。
32.每攻击成功一次或达到设置迭代次数时,即结束当前迭代。一个样本通过在不断更新学习到的操作价值中,重复迭代获取多条价值序列。
33.本发明中的对抗样本生成,主要是依靠对源代码执行结构转换,本发明可以应用控制转换、声明转换和api转换这三大类型的转换。以图3的实例展示图为例,通过对源代码样本结构信息的提取,并采用本方法中的选择策略,有选择的对代码进行结构上的转换来实施对抗。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。