一种rgb
‑
d图像显著性目标检测方法
技术领域
1.本发明属于图像目标检测技术领域,涉及一种rgb
‑
d图像显著性目标检测方法。
背景技术:
2.受人类视觉注意机制的启发,显著对象检测任务旨在检测给定场景中最有吸引力的对象或区域,该方法已成功广泛应用于目标检测、图像编辑和视频浓缩等研究领域,以及智能拍照、推荐系统和自动驾驶等工程领域,具有重要的研究价值和广阔的市场前景。事实上,除了颜色外观、纹理细节和物理尺寸,人们还可以感知景深,从而通过双目视觉系统产生立体感知。近年来,得益于微软kinect等消费级深度相机的快速发展,可以方便地获取深度图来描绘场景。与提供丰富颜色和纹理信息的rgb图像相比,深度图可以表现出几何结构、内部一致性和光照不变性。借助深度图,显著对象检测模型可以更好地应对一些具有挑战性的场景,例如低对比度和复杂背景。因此,近几年来,rgb
‑
d图像显著目标检测的研究受到了广泛关注。众所周知,rgb图像和深度图属于不同的模态,因此需要一些复杂的设计,以便更好地利用两者的优点实现rgb
‑
d图像显著性目标检测。fu等
1.引入了用于联合学习的siamese网络,并设计了一种密集合作融合策略以发现互补特征。pang等
2.通过密集连接结构整合跨模态特征,并利用融合特征建立分层动态过滤网络。huang等
3.提出了一个跨模态细化模块以集成跨模态特征,主要设计了一个多级融合模块来按照自下而上的路径融合每个级别的特征。piao等
4.提出了一种深度蒸馏器以将深度知识从深度流传输到rgb分支。liu等
5.设计了一个残差融合模块,在解码阶段将深度解码特征整合到rgb分支中。chen等
6.考虑到深度图包含的信息比rgb图像少得多,并提出了一个轻量级网络以提取深度流特征。
3.在目前的现有技术中,至少存在以下缺点和不足:
4.(1)对于特征编码中的跨模态交互,现有方法要么不加区别地对待rgb和深度模态,要么只是习惯性地利用深度线索作为rgb分支的辅助信息,而跨模态数据的不一致问题会降低学习得到的特征的判别力;(2)为了突出和恢复特征解码中的空间域信息,现有的方法通过跳连接引入编码特征。然而,它们只是通过直接相加或串联操作来引入相应编码层的信息,并没有充分利用不同层的编码特征。
5.本发明重新考虑了两种模态的状态,并为rgb
‑
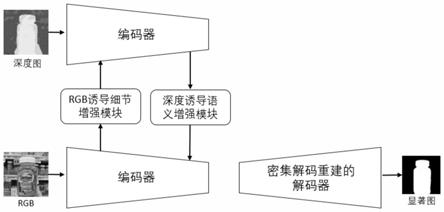
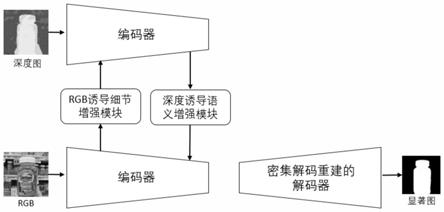
d显著性目标检测提出了一种新的跨模态差异交互网络(cdinet),它根据不同层的特征表示对两种模态的依赖性进行了差异建模。为此,本发明设计了两个组件来实现有效的跨模态交互:1)rgb诱导细节增强(rde)模块利用rgb模态来增强低层级特征编码阶段的深度特征的细节。2)深度诱导语义增强(dse)模块将深度特征的对象定位和内部一致性传输到高层级特征编码阶段的rgb分支。此外,还设计了密集解码重建(ddr)结构,通过结合多层级编码特征来构造语义块,以更新特征解码中的跳连接。
6.关键术语定义列表
7.1、rgb
‑
d图像:是包含彩色和深度两种模态信息的图像。
8.2、rgb
‑
d图像显著性检测:是在rgb
‑
d图像数据中检测出最受关注的目标或区域。
技术实现要素:
9.本发明旨在充分挖掘彩色和深度的跨模态互补信息,降低低质深度图对检测结果的影响,设计一种新的rgb
‑
d图像显著性目标检测的跨模态差异交互网络,该网络根据不同层的特征,对两种模态的依赖性进行了不同的建模,获得更佳的检测性能,具体技术方案如下:
10.一种rgb
‑
d图像显著性目标检测方法,
11.所述rgb
‑
d图像显著性目标检测方法基于跨模态差异交互网络;
12.所述跨模态差异交互网络遵循编码器
‑
解码器架构,实现跨模态信息的差异交互和引导;
13.所述跨模态差异交互网络包括:rgb图像编码器、深度模态编码器、rgb诱导细节增强模块(rde)、深度诱导语义增强模块(dse)和密集解码重建(ddr)结构;
14.所述rgb图像编码器和深度模态编码器均采用vgg主干网络;
15.所述vgg主干网络的前两层为:低层级特征编码阶段;
16.所述vgg主干网络的后三层为:高层级特征编码阶段;
17.所述rgb
‑
d图像显著性目标检测方法包括以下步骤:
18.s1、将深度图输入深度模态编码器,将rgb图像输入rgb图像编码器;
19.s2、所述深度模态编码器提供深度模态,所述rgb图像编码器提供rgb模态;
20.s3、在低层级特征编码阶段,所述rgb诱导细节增强模块通过将rgb模态的细节补充信息从rgb模态传输到深度模态,以增强和补充深度模态,实现深度特征增强;
21.s4、在高层级特征编码阶段,所述深度诱导语义增强模块采用注意力级别和特征级别两种交互模式全面进行跨模态特征融合,实现rgb特征增强;
22.s5、在解码阶段,密集解码重建结构通过结合多层级的编码特征构造语义块,以更新特征解码中的跳连接信息,进行密集解码,进而生成预测的显著性图像。
23.在上述技术方案的基础上,所述vgg主干网络为卷积神经网络vgg16。
24.在上述技术方案的基础上,步骤s3的具体步骤如下:
25.s3.1、采用两个级联卷积层融合rgb模态和深度模态的低层级编码特征,生成融合特征池f
pool
,如式(1)所示,
[0026][0027]
其中,i为:低层级编码特征的层级,且i∈{1,2};表示:深度模态的低层级编码特征,表示:rgb模态的低层级rgb特征;表示:对和进行通道连接操作;表示:采用卷积核为1
×
1的卷积层,对进行卷积操作;表示:采用卷积核为3
×
3的卷积层,对进行卷积操作;深度图经过卷积神经网络vgg16的第一层操作得到rgb图像通过卷积神经网
络vgg16的第一层操作得到
[0028]
s3.2、由获得特征如式(2)所示,
[0029][0030]
其中,表示:对沿通道维度进行最大池化操作,表示:采用卷积核为7
×
7的卷积层,对进行卷积操作;表示:采用卷积核为7
×
7的卷积层,对进行卷积操作;表示:对进行sigmoid函数操作;表示:将和进行逐元素相乘;
[0031]
经过卷积神经网络vgg16的第二层操作得到同时,f
r1
通过卷积神经网络vgg16的第二层操作得到f
r2
;进而利用公式(1)和(2)得到特征
[0032]
在上述技术方案的基础上,步骤s4的具体步骤如下:
[0033]
s4.1、由获得空间注意力增强的rgb编码特征如式(3)和式(4)所示,
[0034][0035][0036]
其中,j为:高层级编码特征的层级,且j∈{3,4,5};表示:深度模态的高层级编码特征;表示:rgb模态的高层级rgb特征;表示:对沿通道维度进行最大池化操作;表示:采用卷积核为3
×
3的卷积层,对进行卷积操作;表示:对进行sigmoid函数操作;表示:将s
weight
和进行逐元素相乘;经过卷积神经网络vgg16的第三层操作得到经过卷积神经网络vgg16的第三层操作得到通过卷积神经网络vgg16的第三层操作得到
[0037]
s4.2、由获得注意力级的rgb增强特征如式(5)和式(6)所示,
[0038][0039]
[0040]
其中,表示:通过全局平均池化层对进行操作;表示:通过两个全连接层对进行操作;表示:对进行sigmoid函数操作;c
weight
为:权重向量;表示:将c
weight
和进行逐元素相乘;
[0041]
s4.3、使用级联的通道注意力和空间注意力机制来增强深度特征,并产生特征级的rgb增强特征具体由公式(7)得到,
[0042][0043]
其中,ca为通道注意力,sa为空间注意力;所述通道注意力用于:学习每个特征通道的重要性;所述空间注意力用于:突出显示特征图中的重要位置;
[0044]
s4.4、利用公式(8)计算特征
[0045][0046]
其中,经过卷积神经网络vgg16的第四层操作得到同时,通过卷积神经网络vgg16的第四层操作得到进而利用公式(3)
‑
(8)得到特征(8)得到特征经过卷积神经网络vgg16的第五层操作得到经网络vgg16的第五层操作得到通过卷积神经网络vgg16的第五层操作得到进而利用公式(3)
‑
(8)得到特征
[0047]
在上述技术方案的基础上,步骤s5的具体步骤如下:
[0048]
s5.1、将和构成跳连接特征列表;
[0049]
并引入初始跳跃连接特征其中k∈{1,2,3,4,5};
[0050]
且
[0051]
s5.2、由生成语义块b
m
,如式(9)所示,
[0052][0053]
其中,m∈{1,2,3,4};表示:通过双线性插值对进行上采样操作;表示:采用卷积核为1
×
1的卷积层,对进行卷积操作;表示:采用卷积核为3
×
3的卷积层,对进行卷积操作;
[0054]
s5.3、由b
m
生成最终的跳连接特征如式(10)所示,
[0055][0056]
其中,表示:将b
m
和进行逐元素相乘;
[0057]
s5.4、得到的结合解码特征,通过上采样和连续卷积操作逐步恢复图像细节,最后一层的解码特征通过sigmoid函数激活,生成预测的显著性图像。
[0058]
在上述技术方案的基础上,步骤s5.4的具体步骤如下:
[0059]
s5.4.1、按照式(11)和式(12)计算解码特征,
[0060][0061][0062]
其中,t∈{2,3,4,5},和均为解码特征,表示:通过双线性插值对进行上采样操作;表示:采用卷积核为3
×
3的卷积层,对进行反卷积操作;表示:采用卷积核为1
×
1的卷积层,对进行卷积操作;表示:通过双线性插值对进行上采样操作;表示:采用卷积核为3
×
3的卷积层,对进行卷积操作;
[0063]
s5.4.2、由式(11)和式(12)获得解码特征将解码特征通过sigmoid函数激活,生成预测的显著性图像。
[0064]
在上述技术方案的基础上,式(9)的具体表示形式如式(13)所示,
[0065][0066]
在上述技术方案的基础上,所述rgb
‑
d图像显著性目标检测方法的图像处理速度达到42fps。
[0067]
本发明的有益技术效果如下:
[0068]
本发明探索了一种新的跨模态交互模式,并提出了一种跨模态差异交互网络,该网络显式地模拟了不同卷积层中两种模态(即rgb模态和深度模态)的依赖性。为此,设计了两个组件(即rde模块和dse模块)来实现差异化的跨模态引导。此外,本发明还提出了ddr结构,通过利用多个高层级特征来更新跳连接,以生成语义块b
m
。
附图说明
[0069]
本发明有如下附图:
[0070]
图1是本发明所述跨模态差异交互网络的整体架构示意图;
[0071]
图2是本发明所述rgb
‑
d图像显著性目标检测方法的可视化实例示意图。
具体实施方式
[0072]
为了更为具体地描述本发明,下面结合附图及具体实施方式对本发明的技术方案进行更详细的说明。应该强调的是,下述说明仅仅是示例性的,而不是为了限制本发明的范围及其应用。
[0073]
如图1所示为:本发明所述跨模态差异交互网络的整体架构示意图。该网络遵循编码器
‑
解码器架构,在编码阶段实现了跨模态信息的差异交互和引导。该框架主要由三部分组成:1)rgb诱导细节增强模块。它通过将rgb模态的详细补充信息传输到深度模态来实现深度特征增强。2)深度诱导语义增强模块。利用深度特征提供更好的定位和内部一致性来丰富rgb特征的语义信息。3)密集解码重构结构(又称为:密集解码重建结构,即图1中的密集解码重建的解码器)。它对不同层的编码特征进行密集解码,以生成更有价值的跳连接信息。
[0074]
本发明具体通过以下技术方案实现
[0075]
本发明探索了一种跨模态交互模式的rgb
‑
d图像显著性目标检测方法,并提出了一种跨模态差异交互网络,该网络明确地模拟了不同卷积层中两种模态的依赖性。具体实现简述如下:
[0076]
简述技术路线如下:
[0077]
本发明设计的网络由rgb诱导细节增强(rde)模块、深度诱导语义增强(dse)模块和密集解码重建(ddr)结构组成。网络遵循编码器
‑
解码器架构,包括两个关于rgb模态和深度模态的编码器和一个解码器(即密集解码重建结构)。具体来说,两个编码器均采用vgg主干网络,在低层级特征编码阶段(即vgg主干网络的前两层),本发明设计了一个rde模块,将细节补充信息从rgb模态传输到深度模态,从而增强深度特征的可区分性表示。对于高层级特征编码阶段,dse模块利用深度特征的定位精度和内部一致性优势,辅助rgb分支捕捉更清晰和细粒度的语义属性,从而促进对象结构和背景抑制。此外,对于卷积上采样解码基础设施,本发明通过构建ddr结构来更新传统的跳连接方式,即利用更高层级别的跳连接特征作为引导信息,实现更有效的编码器信息传输。解码器最后一个卷积层生成的预测结果将作为最终的显著性输出。
[0078]
简述rgb诱导细节增强模块如下:
[0079]
与rgb图像相比,深度图抛开了复杂的纹理信息,可以直观地描述显著物体的形状和位置。这样,对于包含更详细信息(例如边界和形状)的低层级编码特征,深度特征可以提供比rgb特征更直接和有指导意义的表示,有利于初始特征学习。然而,深度信息并不是万能的。例如,彼此相邻的不同对象实例具有相同的深度值。但是在相应的rgb图像中,这些物体在大多数情况下是可以通过色差来区分的。因此,这些不明确的区域给网络训练带来了负担,之前的模型已经证实了预测此类样本的难度。为了解决这个难题,本发明设计了一个rgb诱导细节增强模块,通过低层级中的rgb特征来增强和补充深度模态。通过在早期引入rgb分支的详细指导,可以在特征前馈过程中使用更多信息来处理这些困难情况。
[0080]
具体来说,首先采用两个级联卷积层来融合两种模态的底层视觉特征。第一个卷
积层使用1
×
1的卷积核用于减少特征通道的数量,第二个卷积层使用3
×
3的卷积核实现更全面的特征融合,从而生成融合特征池f
pool
,如式(1)所示,
[0081][0082]
其中,索引i∈{1,2}为低层级编码特征层,[
·
,
·
]表示通道连接操作,conv
n
是卷积核为n
×
n的卷积层。表示深度分支(即深度模态)的低层级编码特征,是来自主干的低层级rgb特征(即rgb模态的低层级rgb特征);生成f
pool
而不是将rgb特征直接转移到深度分支的优点是,在这个过程中可以增强两种模态的共同细节特征,削弱不相关的特征。其中,深度图经过卷积神经网络vgg16的第一层操作得到rgb图像通过卷积神经网络vgg16的第一层操作得到f
r1
;
[0083]
然后,为了有说服力地提供深度特征所需的有用信息,需要从深度的角度进一步过滤rgb特征。具体来说,对深度特征(即)使用一系列操作,包括一个最大池化层、两个卷积层和一个sigmoid函数,以生成空间注意力掩码mask。请注意,对于两个串行卷积层,使用更大的卷积核大小(即7
×
7)来增大感受野以便感知重要细节区域。最后,将空间注意力掩码mask和特征池f
pool
相乘,以减少不相关rgb特征的引入,从而从深度模态的角度获得所需的补充信息。整个过程可以描述为式(2),
[0084][0085]
其中maxpool(
·
)和σ(
·
)分别表示沿通道维度最大池化操作和sigmoid函数,而
⊙⊙
表示逐元素乘法(即对应特征位置相乘)。特征将用作深度分支中下一层的输入,即经过卷积神经网络vgg16的第二层操作得到同时,f
r1
通过卷积神经网络vgg16的第二层操作得到进而利用公式(1)和(2)得到特征需要注意的是,由于深度分支中的细节特征更加直观和清晰,选择它们作为前两层的跳连接特征进行解码。
[0086]
简述深度诱导语义增强模块如下:
[0087]
在编码的高层阶段(即高层级特征编码阶段),网络学习到的特征包含更多的语义信息,例如类别和关系。对于rgb图像,由于包含丰富的颜色外观和纹理内容,其语义信息也比深度模态更全面。但是,由于深度图的结构和数据特性比较简单,学习到的高层语义特征具有更好的显著目标定位,尤其是在背景区域的抑制方面,这正是rgb高层语义所需要的。因此,在高层编码阶段设计了深度诱导语义增强模块,以借助深度模态来丰富rgb语义特征。然而,考虑到简单的融合策略(例如直接添加或连接)不能有效地集成跨模态特征。因此,采用两种交互模式来全面进行跨模态特征融合,即注意力级别和特征级别。
[0088][0089][0090]
其中表示深度分支(即深度模态)的高层级编码特征,是来自主干的高层级rgb特征(即rgb模态的高层级rgb特征);
[0091]
表示通过深度特征的空间注意力增强的rgb编码特征,索引j∈{3,4,5}表示高层级编码特征层。经过卷积神经网络vgg16的第三层操作得到经过卷积神经网络vgg16的第三层操作得到通过卷积神经网络vgg16的第三层操作得到此外,高层级特征通常具有丰富的通道,因此使用通道注意力来建模不同通道的重要性关系,并学习更多判别特征。具体来说,通过一个全局平均池化(gap)层、两个全连接层(fc)和一个sigmoid函数来学习权重向量c
weight
,即:c
weight
的维度为:c
×1×
1,c为通道数)。最终的注意力级指导公式如式(5)和(6)所示,
[0092][0093][0094]
其中,表示注意力级的rgb增强特征。
[0095]
对于特征层面的引导,使用逐像素相加操作直接融合两种模态的特征,可以加强显著对象的内部响应,获得更好的内部一致性。需要注意的是,使用级联的通道注意力和空间注意力机制来增强深度特征,并产生特征级的rgb增强特征具体由公式(7)得到,
[0096][0097]
其中,ca为通道注意力,sa为空间注意力;所述通道注意力用于:学习每个特征通道的重要性;所述空间注意力用于:突出显示特征图中的重要位置;
[0098]
因此,最终流入rgb分支下一层的特征可以表示为式(8),
[0099][0100]
经过卷积神经网络vgg16的第四层操作得到同时,通过卷积神经网络vgg16的第四层操作得到进而利用公式(3)
‑
(8)得到特征(8)得到特征经过卷积神经网络vgg16的第五层操作得到vgg16的第五层操作得到通过卷积神经网络vgg16的第五层操作得到f
r5
;进而利用公式(3)
‑
(8)得到特征
[0101]
同样,rgb分支的增强特征将被引入解码阶段,以实现显著性解码重建。
[0102]
简述密集解码重建结构如下:
[0103]
在特征编码阶段,通过不一致的引导和交互来学习多层级判别特征。解码器致力于学习与显著性相关的特征,并预测全分辨率显著性图像。在特征解码过程中,将编码特征引入解码的跳连接在现有的sod模型中得到了广泛的应用。然而,这些方法只是建立了相应的编码层和解码层之间的关系,而忽略了不同编码层特征的不同积极影响。例如,顶层编码特征(即高层级编码特征)可以为每个解码层提供语义指导。因此,设计了一种密集解码重
建结构,以更全面地引入跳连接指导。
[0104]
具体来说,编码阶段每一层的和构成了一个跳连接特征列表。为了便于区分,将它们记为初始跳跃连接特征区分,将它们记为初始跳跃连接特征然后,在结合每一层的解码特征和跳连接特征之前,密集连接更高层的编码特征,生成一个语义块b
m
,用于约束当前对应编码层的跳连接信息的引入。语义块b
m
如式(9)所示,
[0105][0106]
其中,up(
·
)表示通过双线性插值进行的上采样操作,它将重塑为与相同的分辨率,k∈{1,2,3,4,5}。
[0107]
然后,结合语义块采用逐元素乘法来消除冗余信息,并采用残差连接来保留原始信息,从而生成最终的跳连接特征如式(10)所示,:
[0108][0109]
其中表示当前对应的跳连接特征。通过这种密集的方式,更高层级的编码特征作为语义过滤器来实现更有效的跳连接特征的信息选择,从而有效地抑制可能导致最终显著性预测异常的冗余信息。得到的结合解码特征,通过上采样和连续卷积操作逐步恢复图像细节;最后,最后一层的解码特征通过sigmoid函数激活,生成预测的显著性图像,具体操作如式(11)和式(12)所示,
[0110][0111][0112]
其中,t∈{2,3,4,5},和均为解码特征,表示:通过双线性插值对进行上采样操作;表示:采用卷积核为3
×
3的卷积层,对进行反卷积操作;表示:采用卷积核为1
×
1的卷积层,对进行卷积操作;表示:通过双线性插值对进行上采样操作;表示:采用卷积核为3
×
3的卷积层,对进行卷积操作;
[0113]
由式(11)和式(12)获得解码特征将解码特征通过sigmoid函数激活,生成预测的显著性图像。
[0114]
本发明的方法在多个公开基准数据集上均达到了具有竞争力的性能。图2给出了本发明技术的可视化实例。第一列为彩色图像(即rgb图像),第二列为深度图像,第三列为rgb
‑
d显著性目标检测的真值图(即显著性检测真图),第四列为本发明预测的显著性图(即显著性检测结果)。从结果可以看出,本发明方法在许多具有挑战性的场景中实现了更好的
视觉效果,对于质量不好的深度图(例如,第二张图像)本发明可以有效地抑制这些模糊区域。
[0115]
本发明的关键点和欲保护点如下:
[0116]
(1)本发明提出了一个端到端的跨模态差异交互网络(cdinet),根据不同层的特征表示对两种模态的依赖性进行差异建模,以提升rgb
‑
d显著性检测的性能。此外,本发明的图像处理速度达到42fps。
[0117]
(2)本发明设计了一个rgb诱导细节增强(rde)模块,将细节补充信息从rgb模态传输到低层级编码阶段的深度模态,以及一个深度诱导语义增强(dse)模块,通过利用高层深度特征的定位精度和内部一致性优势,帮助rgb分支捕获更清晰和细粒度的语义属性。本发明在特征解码阶段设计了一个密集解码重建(ddr)结构,该结构利用多个高层级编码特征功能来更新特征解码中的跳连接来生成语义块。
[0118]
参考文献(如专利/论文/标准)如下所列:
[0119]
[1]keren fu,deng
‑
ping fan,ge
‑
peng ji,and qijun zhao.2020.jl
‑
dcf:joint learning and densely
‑
cooperative fusion framework for rgb
‑
d salient object detection.in proceedings of the ieee conference on computer vision and pattern recognition.3052
–
3062.
[0120]
[2]youwei pang,lihe zhang,xiaoqi zhao,and huchuan lu.2020.hierarchical dynamic filtering network for rgb
‑
d salient object detection.in proceedings of the european conference on computer vision.
[0121]
[3]zhou huang,huai
‑
xin chen,tao zhou,yun
‑
zhi yang,and chang
‑
yin wang.2020.multi
‑
level cross
‑
modal interaction network for rgb
‑
d salient object detection.in proceedings of the european conference on computer vision.
[0122]
[4]yongri piao,zhengkun rong,miao zhang,weisong ren,and huchuan lu.2020.a2dele:adaptive and attentive depth distiller for efficient rgb
‑
d salient object detection.in proceedings of the ieee conference on computer vision and pattern recognition.9060
–
9069.
[0123]
[5]nian liu,ni zhang,and junwei han.2020.learning selective self
‑
mutual attention for rgb
‑
d saliency detection.in proceedings of the ieee conference on computer vision and pattern recognition.13756
–
13765.
[0124]
[6]shuhan chen and yun fu.2020.progressively guided alternate refinement network for rgb
‑
d salient object detection.in proceedings of the european conference on computer vision.520
–
538.
[0125]
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求的保护范围为准。
[0126]
本说明书中未做详细描述的内容属于本领域专业技术人员公知的现有技术。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。