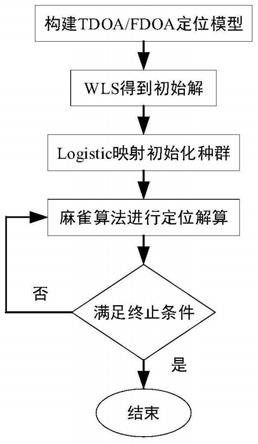
1.本发明涉及一种基于混沌麻雀算法的时差/频差定位方法,是一种可以有效解决低站址误差情况下定位精度差的问题,属于无源定位领域。
背景技术:
2.近十几年来,无源定位技术一直在不断的发展和完善,在雷达和声纳等领域都有广泛的应用。其中,基于时差(time difference of arrival,tdoa)和频差(time difference of arrival,fdoa)测量的定位技术因其具有良好的实时性以及较广的侦测范围等优点,受到国内外学者的广泛关注。然而,现有算法多是针对静态接收站的定位,即接收站状态信息是准确已知的,这在实际场景中是不现实的。研究表明,即使在站址误差很小的情况下,也会严重降低目标的定位精度。因此,在实际应用中,将站址误差引入到tdoa/fdoa定位模型中,是很有必要的。
3.将麻雀搜索算法(sparrow search algorithm,ssa)应用到tdoa/fdoa定位中,但该算法在站址误差较小的情况下,定位性能较差。为了解决上述问题,将logistic混沌映射引入到ssa中来对目标进行定位跟踪,logistic混沌映射可以使麻雀种群在搜索区域内均匀分布,降低算法收敛到局部最优的风险。同时,由于实际定位场景中,目标源的位置信息不可知,本方法利用加权最小二乘法(weighted least squares,wls)得到目标源位置信息的粗略估计,以限制cssa算法的搜索区域。
技术实现要素:
4.本技术发明针对麻雀搜索算法在低站址误差情况下定位精度差的问题,提出基于logistic混沌映射的麻雀搜素算法(chaotic sparrow search algorithm,cssa)。本发明首先建立tdoa/fdoa定位模型,然后利用混沌麻雀搜索算法对tdoa/fdoa模型进行定位解算。
5.本发明的具体实现步骤如下:
6.步骤一:建立站址误差情况下的tdoa/fdoa定位模型;
7.步骤二:利用加权最小二乘法得到目标源位置信息的粗略估计;
8.步骤三:利用ligostic混沌序列初始化种群;
9.步骤四:采用麻雀搜索算法对tdoa/fdoa模型进行定位解算;
10.步骤五:判断算法是否达到最大迭代次数itera。如果是,停止迭代并输出目标的位置和速度,否则返回步骤四继续迭代。
11.本发明主要涉及到以下特征:
12.1.步骤一中的tdoa/fdoa定位模型为:
[0013][0014]
其中,τ
i1
为目标源到第i个接收站和第1个接收站之间的tdoa信息,为目标源到第i个接收站和第1个接收站之间的fdoa信息,c为电磁波传播速度,f0为载波频率,m为接收站个数。
[0015]
2.步骤二具体为:
[0016]
将时差方程和频差方程组合成矩阵形式为:
[0017]
ε=h
‑
gθ
[0018]
然后,wls目标函数可以表示为:
[0019]
j
wls
(θ)=(h
‑
gθ)
t
w(h
‑
gθ)
[0020]
我们的目标是找到最小化目标函数j
wls
(θ)的线性闭式解,可得
[0021][0022]
3.步骤三具体为:
[0023]
logistic混沌映射可以使种群在搜索区域内均匀分布,降低算法陷入局部最优的风险,其表达式为:
[0024]
α
t 1
=α
t
×
σ(1
‑
α
t
)
[0025]
其中,σ∈[0,4]为logistic映射函数参数,是一个控制参数。α
t
∈[0,1]为logistic映射函数在第t次迭代时的函数值。
[0026]
4.步骤四具体为:
[0027]
假设在d维搜索空间中有n只麻雀,则第i只麻雀在d维搜索空间中的位置为x
i
=[x
i1
,x
i2
,...,x
id
],其中i=1,2,...,n,x
id
表示第i只麻雀在第d维的位置。
[0028]
生产者一般占到种群的10%~20%,位置更新公式如下:
[0029][0030]
其中,t=1,2,...,itera为迭代次数,α∈(0,1]、q为随机数,l为1
×
d的矩阵,其中每个元素都是1;r2∈[0,1]和st∈[0.5,1]分别表示预警值和安全值。
[0031]
除了生产者,剩余的麻雀均作为乞讨者,并根据下式进行位置更新:
[0032][0033]
其中,表示种群在第d维的最差位置,表示种群在第d维的最好位置。
[0034]
侦察预警的麻雀一般占到种群的10%~20%,位置更新如下:
[0035][0036]
其中,β为服从标准正态分布的随机数,k∈[
‑
1,1]。e的目的是为了避免分母为0的情况出现,是一个很小的常数。f
i
为第i只麻雀的适应度值,f
g
和f
w
分别是当前麻雀种群的全局最佳和最差适应度值。
[0037]
本发明的核心技术在于:首先构建站址误差情况下的tdoa/fdoa定位模型;然后利用加权最小二乘法得到目标源的粗略估计,以限制目标区域;最后利用混沌麻雀算法搜索最优解。该方法可以有效解决麻雀算法在低站址误差下定位精度差的问题,能够有效提高算法的寻优能力。
[0038]
本发明主要研究了站址误差情况下的tdoa/fdoa定位问题,所述方法包括:利用加权最小二乘法为后续算法提供粗略的目标源估计,以限制混沌麻雀算法的搜索算法,达到降低运算复杂度的目的;为使麻雀种群能够均匀分布在目标区域,将logistic混沌映射引入种群进行初始化,降低算法陷入到局部最优的风险;用改进的麻雀搜索算法来实现tdoa/fdoa定位跟踪。本技术方法能够降低运算复杂度,有效解决低站址误差下定位精度差的问题。
附图说明
[0039]
图1是混沌麻雀搜索算法的原理框图;
[0040]
图2是站址误差条件下的定位模型图;
[0041]
图3a
‑
b是σ=4和σ=2.5时logistic映射函数迭代图;
[0042]
图4a
‑
b是α
t
随σ和α0数值变化的分布情况;
[0043]
图5是麻雀算法和混沌麻雀算法的收敛曲线对比;
[0044]
图6a
‑
d是本方法与ssa、fa、ga、aco算法在近场源的定位性能对比;
[0045]
图7a
‑
d是本方法与ssa、fa、ga、aco算法在远场源的定位性能对比。
具体实施方式
[0046]
下面结合附图与具体实施方式对本发明作进一步详细描述。
[0047]
本发明是一种基于混沌麻雀搜索算法的tdoa/fdoa定位方法,具体包括:
[0048]
(1.1)利用加权最小二乘法得到目标源的初始估计,以限制混沌麻雀算法的搜索区域,减少运算量;
[0049]
(1.2)引入logistic混沌映射,可以使麻雀种群均匀分布在整个搜索区域,以避免
麻雀算法陷入到局部最优。
[0050]
所述方法特征(1.1)包括:
[0051]
(2.1)假设在三维空间中有m≥3个接收站和1个目标源,目标源的位置和速度坐标分别为u
o
=[x
o
,y
o
,z
o
]
t
、m≥3个接收站的位置和速度坐标为s
i
=[x
i
,y
i
,z
i
]
t
,在测量得到tdoa和fdoa信息后,就可以利用目标源到达接收站之间的tdoa信息构造tdoa方程,即得到若干条tdoa双曲面。同理,利用目标源到达接收站之间的fdoa信息就可以构造fdoa方程,得到若干条fdoa复杂曲面。tdoa/fdoa定位模型可以总结为:
[0052][0053]
其中,τ
i1
为目标源到第i个接收站和第1个接收站之间的tdoa信息,为目标源到第i个接收站和第1个接收站之间的fdoa信息,c为电磁波传播速度,f0为载波频率,m为接收站个数。
[0054]
(2.2)由于在实际定位场景中,目标源的位置信息是不确定的。所以本发明首先利用加权最小二乘法得到目标源的初始估计,同时可以限制麻雀算法的搜索区域,减少计算量。
[0055]
将时差方程和频差方程组合成矩阵形式为:
[0056]
ε=h
‑
gθ
[0057]
式中
[0058]
[0059][0060][0061]
其中,δα为tdoa和fdoa测量误差矢量,δβ为接收站运动状态的误差矢量。
[0062][0063][0064][0065]
然后,wls目标函数可以表示为:
[0066]
j
wls
(θ)=(h
‑
gθ)
t
w(h
‑
gθ)
[0067]
我们的目标是找到最小化目标函数j
wls
(θ)的线性闭式解,可得
[0068][0069]
(2.3)假设wls算法获得的初始结果是则可以用下式来限制麻雀算法的搜索区域:
[0070]
newx=lb (ub
‑
lb)
·
x
[0071]
其中,lb、ub为搜索区域的上界向量和下界向量。
[0072]
所述方法特征(1.2)包括:
[0073]
(3.1)假设在d维搜索空间中有n只麻雀,则第i只麻雀在d维搜索空间中的位置为x
i
=[x
i1
,x
i2
,...,x
id
],其中i=1,2,...,n,x
id
表示第i只麻雀在第d维的位置。
[0074]
生产者一般占到种群的10%~20%,位置更新公式如下:
[0075]
[0076]
其中,t=1,2,...,itera为迭代次数,α∈(0,1]、q为随机数,l为1
×
d的矩阵,其中每个元素都是1;r2∈[0,1]和st∈[0.5,1]分别表示预警值和安全值。
[0077]
除了生产者,剩余的麻雀均作为乞讨者,并根据下式进行位置更新:
[0078][0079]
其中,表示种群在第d维的最差位置,表示种群在第d维的最好位置。
[0080]
侦察预警的麻雀一般占到种群的10%~20%,位置更新如下:
[0081][0082]
其中,β为服从标准正态分布的随机数,k∈[
‑
1,1]。e的目的是为了避免分母为0的情况出现,是一个很小的常数。f
i
为第i只麻雀的适应度值,f
g
和f
w
分别是当前麻雀种群的全局最佳和最差适应度值。
[0083]
(3.2)为了使麻雀种群均匀分布在整个搜索区域,降低算法陷入局部最优的风险,在初始化麻雀种群时引入logistic混沌映射。
[0084]
α
t 1
=α
t
×
σ(1
‑
α
t
)
[0085]
其中,σ∈[0,4]为logistic映射函数参数,是一个控制参数。α
t
∈[0,1]为logistic映射函数在第t次迭代时的函数值。
[0086]
本技术实施例根据麻雀算法的全局搜索特性,提出了一种基于混沌麻雀搜索算法的tdoa/fdoa定位方法。所申请方法通过引入logistic混沌映射对麻雀种群进行初始化,使麻雀种群均匀分布在整个搜索区域,然后采用麻雀算法对麻雀位置进行更新,利用适应度函数进行评估,以实现对目标的定位。所申请方法可以通过限制搜索范围,降低算法运算量,然后在初始化时引入logistic混沌映射,降低麻雀算法陷入局部最优的可能性。
[0087]
为更加清晰的说明申请方法,本技术实施例通过仿真实验进行流程说明以及效果展示,但不限制本技术实施例的范围。实验条件为:利用m=5个接收站对目标源进行近场源和远场源定位,麻雀种群数量设置为n=100,迭代次数设置为itera=100,蒙特卡洛仿真次数为l=1000。
[0088]
图1是本发明所述方法的原理框图,该方法包括:
[0089]
s110 tdoa/fdoa定位模型如图2所示,其表达式为
[0090][0091]
其中,τ
i1
为目标源到第i个接收站和第1个接收站之间的tdoa信息,为目标源到第i个接收站和第1个接收站之间的fdoa信息,c为电磁波传播速度,f0为载波频率,m为接收站个数。
[0092]
s111将时差方程和频差方程组合成矩阵形式为:
[0093]
ε=h
‑
gθ
[0094]
然后,wls目标函数可以表示为:
[0095]
j
wls
(θ)=(h
‑
gθ)
t
w(h
‑
gθ)
[0096]
我们的目标是找到最小化目标函数j
wls
(θ)的线性闭式解,可得
[0097][0098]
s112假设wls算法获得的初始结果是则可以用下式来限制麻雀算法的搜索区域:
[0099]
newx=lb (ub
‑
lb)
·
x
[0100]
其中,lb、ub为搜索区域的上界向量和下界向量。
[0101]
s120在d维搜索空间中有n只麻雀,则第i只麻雀在d维搜索空间中的位置为x
i
=[x
i1
,x
i2
,...,x
id
],其中i=1,2,...,n,x
id
表示第i只麻雀在第d维的位置。
[0102]
生产者一般占到种群的10%~20%,位置更新公式如下:
[0103][0104]
其中,t=1,2,...,itera为迭代次数,α∈(0,1]、q为随机数,l为1
×
d的矩阵,其中每个元素都是1;r2∈[0,1]和st∈[0.5,1]分别表示预警值和安全值。
[0105]
除了生产者,剩余的麻雀均作为乞讨者,并根据下式进行位置更新:
[0106][0107]
其中,表示种群在第d维的最差位置,表示种群在第d维的最好位置。
[0108]
侦察预警的麻雀一般占到种群的10%~20%,位置更新如下:
[0109][0110]
其中,β为服从标准正态分布的随机数,k∈[
‑
1,1]。e的目的是为了避免分母为0的情况出现,是一个很小的常数。f
i
为第i只麻雀的适应度值,f
g
和f
w
分别是当前麻雀种群的全局最佳和最差适应度值。
[0111]
s121为了使麻雀种群均匀分布在整个搜索区域,降低算法陷入局部最优的风险,在初始化麻雀种群时引入logistic混沌映射。
[0112]
α
t 1
=α
t
×
σ(1
‑
α
t
)
[0113]
其中,σ∈[0,4]为logistic映射函数参数,是一个控制参数。α
t
∈[0,1]为logistic映射函数在第t次迭代时的函数值。
[0114]
s130若使求得的的目标位置最好,其适应度函数可表示为:
[0115]
fitness(x)=||h
‑
gθ||2[0116]
其中
[0117][0118][0119][0120]
令接收站的数量为m=5,经过若干次迭代后,就可以优化得到目标源的位置和速度。图3为σ=4和σ=2.5时的logistic映射函数迭代图。图4为α
t
随σ和α0数值变化的分布情况。图5为混沌麻雀搜索算法和麻雀搜索算法的收敛曲线对比,可知,混沌麻雀搜索算法能
更快的收敛到全局最优解。为了说明该方法的优越性,将其与麻雀搜索算法(sparrow search algorithm,ssa)、萤火虫算法(firefly algorithm,fa)、遗传算法(genetic algorithm,ga)、蚁群算法(ant colony optimization,aco)进行了对比,结果如图6和图7所示。其中,图6为近场源;图7为远场源。可以发现本发明所提方法的均方根误差(root mean square error,rmse)更贴近克拉美罗下界(cramer
‑
rao lower bound,crlb),定位偏差(bias)更小,所以本发明能够保证站址误差较小的情况下,定位性能更优。
[0121]
综上,本实施例的方法根据麻雀算法的全局搜索特性,提出了一种基于混沌麻雀搜索算法的tdoa/fdoa定位方法。所申请方法通过引入logistic混沌映射对麻雀种群进行初始化,使麻雀种群均匀分布在整个搜索区域,然后采用麻雀算法对麻雀位置进行更新,利用适应度函数进行评估,以实现对目标的定位。所申请方法可以通过限制搜索范围,降低算法运算量,然后在初始化时引入logistic混沌映射,降低麻雀算法陷入局部最优的可能性。
[0122]
本领域技术人员可以理解,在本技术具体实施方式的上述方法中,各步骤的序号大小并不意味着执行顺序的先后,各步骤的执行顺序应以其功能和内在逻辑确定,而不应对本技术具体实施方式的实施过程构成任何限定。
[0123]
最后应说明的是,以上实施例仅用以描述本发明的技术方案而不是对本技术方法进行限制,本发明在应用上可以延伸为其他的修改、变化、应用和实施例,并且因此认为所有这样的修改、变化、应用、实施例都在本发明的精神和教导范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。