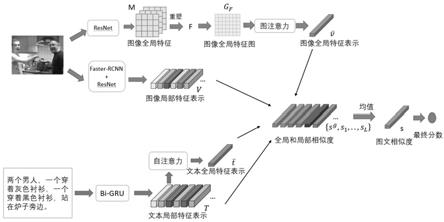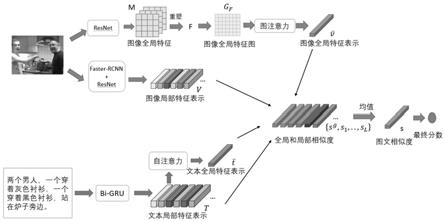
1.本发明属于计算机多模态技术领域,具体涉及一种基于全局和局部对齐的多模态特征对齐方法。
背景技术:
2.随着移动互联网使用的持续深化,以及即时通讯工具,社交网络,网络视频等互联网应用程序的普及,人们的上网自由度也得到很大的提升,越来越多的互联网用户随时随地接入互联网,并且上传大量的照片、语音和文字等不同模态的多媒体数据。如何在海量的不同模态的数据中快速准确地检索出自己所需要的信息具有很重要的现实意义。
3.一方面,由于多媒体数据的爆发式增长,如何高效且准确地检索内容相关的多模态数据逐渐成为一个极具挑战的问题。传统的信息检索方法,大多是以单一模态检索方法为基础的,如关键字检索,以图搜图等。现如今,传统的单一模态的检索已经不能满足人们的日常需要,多模态之间的检索正成为未来的热门方向。以图像和文本这两个模态为例,人们经常会输入一张图片来找到图片所描述的新闻信息,或者输入一段文字来找到最能描述这段文字的图片,这也就促进多模态特征对齐问题的研究。传统的特征对齐方法往往利用手工提取的特征,将图像和文本映射到共同表示空间中,在该空间中求相似度分数进行特征对齐。近年来,由于深度学习的快速发展,越来越多的方法开始使用神经网络提取图像和文本的高层特征,并加上一些注意力模块实现多模态对齐来解决不同模态间的“异构鸿沟”和“语义鸿沟”问题,这些方法均去取得了不错的效果。但是现有方法往往只考虑了多模态间的局部对齐或者全局对齐,只有少数同时进行了局部对齐和全局对齐,但是这些方法的全局特征提取的较为简单且对齐方式不够准确,只是简单的计算两个特征间的相似度值。
技术实现要素:
4.本发明解决的技术问题:提供了一种利用经典网络在大型数据集上的预训练模型来提取出更好的全局特征和局部特征,并且通过计算相似度向量而不是简单的数值进行多模态对齐,基于全局和局部对齐的多模态特征对齐方法。
5.技术方案:为了解决上述技术问题,本发明采用的技术方案如下:一种基于全局和局部对齐的多模态特征对齐方法,其特征在于,包括:采用卷积神经网络和图注意力网络得到图像全局特征表示;通过区域检测网络将图像分为若干区域,再利用卷积神经网络得到所有区域的特征向量和标签概率向量,将两个向量聚合最终的得到图像局部特征表示;通过双向gru网络提取文本中每个单词的特征表示,得到文本局部特征;对于文本局部特征,利用自注意力计算得到文本的全局特征;进行多模态间的全局对齐和局部对齐,得到全局和局部相似度向量,最后将全局和局部相似度向量的平均向量输入到全连接层从而得到最终的相似度分数;具体包括以下步骤:步骤a:图像全局特征的提取:使用resnet152在imagenet上的预训练模型,将resnet152的输出高层特征m重塑为一组特征集f,然后将特征集f经过一个全连接层得到初
步全局特征v
f
,使用初步全局特征v
f
构建视觉图卷积神经网络g
f
,最后经过图注意力模块的计算得到最终的图像全局特征表示;步骤b:图像局部特征的提取:使用faster
‑
rcnn在visual
‑
genome数据集上的预训练模型,检测出图像的关键区域,然后用resnet101提取图像关键区域的特征向量r以及标签概率向量c,将区域特征向量和区域标签概率向量融合起来组成图像局部特征表示v={v1, v2,
…
v
100
};步骤c:文本全局特征和局部特征的提取:对于给定的文本,将其划分为l个单词,然后依次将单词输入到双向gru网络中得到每个单词的特征表示,为文本的局部特征表示t={t1,
…
t
l
},再通过自注意力方法计算得到文本的全局特征表示;步骤d:多模态间的全局和局部对齐:使用相似度函数计算图像全局特征和文本全局特征间的相似度向量,使用多模态注意力模块优化图像特征,得到新的视觉特征a
v
={a
v1
, a
v2
,
…
a
vl
},最后求出a
v
和t的相似度,得到l个局部相似度向量;步骤e:计算最终图像文本匹配分数:对于全局相似度向量和局部相似度向量共l 1个向量求出平均相似度向量s,最后将s经过一个输出维度为1全连接层和sigmoid函数,就得到了最终的图像文本匹配分数。
6.进一步的,图像全局特征的提取具体包含以下步骤:步骤a01,对于输入图像,使用resnet152在imagenet上的预训练模型,且去掉最后一个全连接层,图像经过resnet网络得到一组高层特征m,为了后续视觉图卷积神经网络的构建,将m重塑为长度为64的特征集f={f1, f2,
…
f
64
},再经过一个全连接层,将f中每个向量映射到1024维的空间中,得到初步的全局特征集v
f
;步骤a02,对于步骤a01得到的特征v
f
,构建全局视觉图卷积神经网络g
f
=(v
f
,e
f
),图的顶点由v
f
的特征构成,图的边集e
f
被定义为顶点间特征的内积;步骤a03,对于步骤a02得到的全局视觉图卷积神经网络g
f
=(v
f
,e
f
),计算所有顶点间的注意力系数,并用softmax函数归一化,然后利用注意力系数加权得到图注意力模块更新后的全局特征集v
*f
,最后对特征集v
*f
取平均值,得到了最终的1024维的图像全局特征。
7.进一步的,步骤a03中,图注意力模块的具体计算方法为:先计算顶点间的注意力系数,对于顶点v
f
中任意两个顶点v
i
和v
j
,系数e
ij
的计算公式为:其中,w
q
和w
k
都为网络学习的参数,t表示矩阵的转置,d是特征维度,得到所有系数后,用softmax函数处理得到最终的图注意力系数a
ij
,再加权求和得到图注意力模块的输出v
*f
,具体计算方式如下:,具体计算方式如下:其中,n
i
表示顶点v
i
的所有邻居。
8.进一步的,图像局部特征的提取具体包含以下步骤:步骤b01,对于输入图像,使用faster
‑
rcnn在visual
‑
genome数据集上的预训练模
型,检测出图像的100个关键区域,再将这100个关键区域输入同样在visual
‑
genome数据集预训练的resnet101模型,得到输入图像中关键区域的特征表示r={r1, r2,
…
r
100
}和标签概率向量c={c1, c2,
…
c
100
};步骤b02,对于步骤b01得到的输入图像关键区域的特征r和标签概率c,分别输入到全连接层fc1和fc2,将r和c映射到1024维空间中得到到全连接层fc1和fc2,将r和c映射到1024维空间中得到到全连接层fc1和fc2,将r和c映射到1024维空间中得到其中,w
fc1
和w
fc2
分别是全连接层fc1和fc2的权重,最后将r'和c'直接按元素相加得到最终的图像局部特征v={v1, v2,
…
v
100
}。
9.进一步的,文本局部特征和全局特征的提取具体包含以下步骤:步骤c01,对于输入文本,其分为l个单词,再根据词汇表的对应关系将每个单词转换为对应的数字,再将每个单词嵌入到300维的向量空间中,得到初步的文本局部特征然后将t'输入到1层双向gru网络中,得到了文本局部特征t={t1, t2,
…
t
l
},其中每个单词的特征维度也是1024维;步骤c02,对于步骤c01得到的文本局部特征t,使用l个单词的平均特征作为自注意力机制中的query,求出每个单词的注意力系数后进行加权求和,最终得到1024维文本全局特征。
10.进一步的,文本全局特征的计算方法如下:取l个单词的平均值作为查询q然后计算q和所有局部特征t间的点积得到l个初步权重,同样经过softmax函数后得到最终的注意力权重所以文本全局特征的计算公式为:。
11.进一步的,多模态间的全局和局部对齐具体包含以下步骤:步骤d01:使用相似度表示函数计算图像全局特征和文本全局特征的相似度向量,得到256维的全局相似度向量s
g
;采用的相似度函数为:其中,x,y是需要计算相似度的两个向量,w为网络学习的参数。
12.步骤d02:使用多模态注意力模块得到每个图像区域关于每个单词的注意力系数
β,i,j分别表示第i个区域和第j个单词,i=1,2,
…
,100;j=1,2,
…
,l;然后加权求和得到所有区域关于每个单词的视觉特征a
v
={a
v1
, a
v2
,
…
a
vl
};其中,第j个单词的视觉特征计算公式为最后对每个单词的视觉特征a
v
和局部特征t中的l对向量用相似度函数s求相似度表示,得到的局部相似度向量s={s1, s2,
…
s
l
},其中,βij表示注意力权重,v
i
是步骤b中得到的图像局部特征表示,且每个向量的维度均为256。
13.进一步的,步骤d02中,多模态注意力模块的计算方法如下:对于第i个区域和第j个单词,余弦相似度为然后标准化得到,最后求出注意力权重:进而得到视觉特征a
v
,其中,t
j
是步骤c中的得到的第j个文本局部特征。
14.进一步的,计算最终图像文本匹配分数的具体过程如下:将步骤d01和d02得到的全局相似度向量和局部相似度向量共l 1个向量按元素相加求均值,得到图像文本的最终256维相似度向量s,然后将s输入到输出维度是1的全连接层fc3,得到初步相似度分数score, score=w
fc3
*s,w
fc3
是fc3的权重,最后使用sigmoid函数归一化得到最终的多模态匹配分数。
15.有益效果:与现有技术相比,本发明具有以下优点:本发明的基于全局和局部对齐的多模态特征对齐方法,利用了经典网络在大型数据集上的预训练模型以及相似度向量而不是简单的相似度值进行特征对齐。本发明图像全局特征的计算是在传统深度网络提取到的高层语义特征基础上增加了图注意力模块,这一模块通过像素间的语义关系来决定特征的权重,最终得到语义关系增强后的图像全局特征;此外图像局部特征的计算融合了局部的特征向量和局部的标签概率向量,得到了标签信息增强的图像局部特征;同样的在得到文本的局部特征表示后,使用了更优秀自注意力模块求出文本全局特征而不是简单的求均值。最后通过相似度向量进行多模态全局和局部对齐。通过实验对比,该方法性能优于其他同类方法。
附图说明
16.图1是基于全局和局部对齐的多模态特征对齐方法结构示意图;图2是本发明试验所采用的ms
‑
coco的部分数据,包括图2a和图2b;图3是本发明试验所采用的flickr30k的部分数据,包括图3a和图3b。
具体实施方式
17.下面结合具体实施例,进一步阐明本发明,实施例在以本发明技术方案为前提下进行实施,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围。
18.本技术的基于全局和局部对齐的多模态特征对齐方法,用卷积神经网络和图注意力网络得到图像全局特征表示;通过区域检测网络将图像分为若干区域,再利用卷积神经网络得到所有区域的特征向量和标签概率向量,将两个向量聚合最终的得到图像局部特征表示;通过双向gru网络提取文本中每个单词的特征表示,即为文本局部特征;对于文本局部特征,利用自注意力计算得到文本的全局特征;进行多模态间的全局对齐和局部对齐,得到全局和局部相似度向量,最后将全局和局部相似度向量的平均向量输入到全连接层从而得到最终的相似度分数。
19.本发明的方法具体步骤包括:图像全局特征的提取,图像局部特征的提取;文本全局特征和局部特征的提取,多模态间的全局和局部对齐和计算最终图像文本匹配分数。下面分别对上述四个步骤进行详细描述:a:图像全局特征的提取:使用resnet152在imagenet上的预训练模型,且去掉了最后一个全连接层。将resnet152的输出高层特征m重塑为一组特征集f。然后将f经过一个全连接层得到初步全局特征v
f
,使用v
f
构建视觉图网络g
f
。最后经过图注意力模块的计算得到最终的图像全局特征表示,图像全局特征的提取具体包含以下步骤:步骤a01,对于输入图像,本发明使用resnet152在imagenet上的预训练模型,且去掉了最后一个全连接层。图像经过resnet网络得到一组高层特征m,为了后续图网络的构建,将一组高层特征重塑为长度为64的特征集f={f1, f2,
…
f
64
}。再经过一个全连接层,将f中每个向量映射到1024维的空间中,得到初步的全局特征集v
f
。
20.步骤a02,对于步骤a01得到的特征v
f
,构建全局视觉图网络g
f
=(v
f
,e
f
)。图的顶点由v
f
的特征构成,图的边集e
f
被定义为顶点间特征的内积。比如对于顶点v
if
和v
jf
,边的长度为t表示矩阵转置。
21.步骤a03,对于步骤a02得到的全局视觉图网络g
f
=(v
f
,e
f
),计算所有顶点间的注意力系数,并用softmax函数归一化。然后利用注意力系数加权得到图注意力模块更新后的全局特征集v
*f
。最后对特征集v
*f
取平均值,得到了最终的1024维的图像全局特征。
22.图注意力模块的具体计算过程为:先计算顶点间的注意力系数,对于顶点v
f
中任意两个顶点v
i
和v
j
,系数e
ij
的计算公式为:
其中,w
q
和w
k
都为网络学习的参数,t表示矩阵转置,d是特征维度,在本发明中为1024。得到所有系数后,用softmax函数处理得到最终的图注意力系数a
ij
,再加权求和得到图注意力模块的输出v
*f
,具体计算方式如下:计算方式如下:其中,n
i
表示顶点v
i
的所有邻居。
23.b:图像局部特征的提取;使用faster
‑
rcnn在visual
‑
genome数据集上的预训练模型,检测出图像的100个关键区域。然后用resnet101提取图像100个区域的特征向量r以及标签概率向量c。将区域特征向量和区域标签概率向量融合起来组成图像局部特征表示v={v1, v2,
…
v
100
},图像局部特征的提取具体包含以下步骤:步骤b01,对于输入图像,使用faster
‑
rcnn在visual
‑
genome数据集上的预训练模型,检测出图像的100个关键区域,再将这100个关键区域输入同样在visual
‑
genome数据集预训练的resnet101模型,就可以得到输入图像中100个关键区域的特征表示r={r1, r2,
…
r
100
}和标签概率向量c={c1, c2,
…
c
100
};步骤b02,对于步骤b01得到的输入图像关键区域的特征r和标签概率c,分别输入到全连接层fc1和fc2,将r和c映射到1024维空间中得到到全连接层fc1和fc2,将r和c映射到1024维空间中得到,即,r'=w
fc1
r,c'=w
fc2
c其中,w
fc1
和w
fc2
分别是全连接层fc1和fc2的权重,最后将r'和c'直接按元素相加得到最终的图像局部特征v={v1, v2,
…
v
100
}。
24.c:文本全局特征和局部特征的提取:对于给定的文本,将其划分为l个单词,然后依次将单词输入到双向gru网络中得到每个单词的特征表示,即为文本的局部特征表示t={t1, t2,
…
t
l
}。再通过自注意力方法计算得到文本的全局特征表示。结合图1,文本局部特征和全局特征的提取具体包含以下步骤:步骤c01,对于输入文本,其分为l个单词,再根据词汇表的对应关系将每个单词转换为对应的数字,再将每个单词嵌入到300维的向量空间中,得到初步的文本局部特征然后将t'输入到1层双向gru网络中,得到了文本局部特征t={t1, t2,
…
t
l
},其中每个单词的特征维度也是1024维;步骤c02,对于步骤c01得到的文本局部特征t,使用l个单词的平均特征作为自注意力机制中的query,求出每个单词的注意力系数后进行加权求和,最终得到1024维文本全局特征。
25.文本全局特征的计算过程如下:取l个单词的平均值作为查询q
然后计算q和所有局部特征t间的点积得到l个初步权重,同样经过softmax函数后得到最终的注意力权重:,所以文本全局特征的计算公式为:;d:多模态间的全局和局部对齐:使用相似度函数计算图像全局特征和文本全局特征间的相似度向量。使用多模态注意力模块优化图像特征,得到新的视觉特征a
v
={a
v1
, a
v2
,
…
a
vl
}。最后求出a
v
和t的相似度,得到l个局部相似度向量。多模态间的全局和局部对齐具体包含以下步骤:步骤d01:使用相似度表示函数计算图像全局特征和文本全局特征的相似度向量,得到256维的全局相似度向量s
g
,相似度函数为:其中,x,y是需要计算相似度的两个向量,w为网络学习的参数。
26.步骤d02:使用多模态注意力模块得到每个图像区域关于每个单词的注意力系数β,i,j分别表示第i个区域和第j个单词,i=1,2,
…
,100;j=1,2,
…
,l;然后加权求和得到所有区域关于每个单词的视觉特征a
v
={a
v1
, a
v2
,
…
a
vl
};其中,第j个单词的视觉特征计算公式为最后对每个单词的视觉特征a
v
和局部特征t中的l对向量用相似度函数s求相似度表示,得到的局部相似度向量s={s1, s2,
…
s
l
},其中,βij表示注意力权重,v
i
是步骤b中得到的图像局部特征表示,且每个向量的维度均为256。
27.多模态注意力模块的计算过程如下:对于第i个区域和第j个单词,余弦相似度为然后标准化得到,最后求出注意力权重:进而得到视觉特征a
v
,其中,t
j
是步骤c中的得到的第j个文本局部特征。
28.e:计算最终图像文本匹配分数:对于全局相似度向量和局部相似度向量共l 1个
向量求出平均相似度向量s。最后将s经过一个输出维度为1全连接层和sigmoid函数,就得到了最终的图像文本匹配分数。
29.计算最终图像文本匹配分数的具体过程如下:将步骤d01和d02得到的全局相似度向量和局部相似度向量共l 1个向量按元素相加求均值,得到图像文本的最终256维相似度向量s,然后将s输入到输出维度是1的全连接层fc3,得到初步相似度分数score, score=w
fc3
*s, w
fc3
是fc3的权重,最后使用sigmoid函数归一化得到最终的多模态匹配分数。
30.采用以下方式对本发明的方法进行验证:ms
‑
coco数据集: ms
‑
coco数据集是十分经典的多模态图文数据集,共包括123287张图片,其中每张图片都有人工生成的5个文本描述。我们使用了113287张图片和566435个文本作为训练集,5000张图片和25000个文本为验证集,5000张图片和25000个文本为测试集。如图2所示是本发明试验所采用的ms
‑
coco的部分数据,其中图2a的文本描述为:1、一个配有现代木桌椅的餐厅;2、一张带藤条圆形靠背椅的长餐桌;3、一张长桌,上面有一棵植物,周围环绕着木椅;4、一张长桌,中间插花,适合开会;5、一张桌子上装饰着蓝色调的木椅;其中图2b的文本描述为:1、一个男人在覆盖着糖霜的厨房里准备甜点;2、一位厨师正在准备和装饰许多小糕点;3、面包师准备各种类型的烘焙食品;4、一个人在盒子中抓取糕点的特写;5、一个接触各种糕点的手。
31.flickr30k数据集:flickr30k数据集也是十分经典的多模态图文数据集,共包括31783张图片,其中每张图片都有人工生成的5个文本描述。我们使用了93827张图片和469135个文本作为训练集,1000张图片和5000个文本为验证集,1000张图片和5000个文本为测试集。图3是本发明试验所采用的flickr30k的部分数据,其中图3a的文本描述为:1、两个头发蓬乱的年轻人在院子里闲逛时看着自己的手;2、两个年轻的白人男性在许多灌木丛附近;3、两个穿绿色衬衫的男人站在院子里;4、一个穿着蓝色衬衫的男人站在花园里;5、两个朋友享受在一起度过的时光。其中图3b的文本描述为:1、几个戴着安全帽的人正在操作一个巨大的滑轮系统;2、工人从上面俯视一件设备;3、两个戴着安全帽在机器上工作的男人;4、四个人站在一座高大的建筑物上;5、三个人在一个大钻机上。
32.实验结果对于图像
‑
文本检索任务,采用recall at k(r@k)作为评价指标,r@k表示查询数据的真实返回在前k个返回数据中所占的比例。
33.实验结果如下表所示:表1 本发明的方法在ms
‑
coco数据集和 flickr30k数据集上的实验结果
从实验结果可以看出,本发明提出的方法再两个数据集上均取得了很好的检索效果,由其当返回数目k为10时,召回率已经接近百分之百。同样也能发现ms
‑
coco数据集更大,所以该方法的性能也更好,即训练的样本越多,网络学习到的模型才更好。
34.以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。