一种基于gan和yolo
‑
v5的目标分割检测方法
技术领域
1.本发明属于图像处理技术领域,具体涉及一种基于gan和yolo
‑
v5的目标分割检测方法。
背景技术:
2.近年来,随着深度学习的快速发展,目标检测算法也取得了重大突破,现有目标检测算法可以分为两类,一类是two
‑
stage,需要先产生目标候选框,也就是目标位置,然后再对候选框做分类与回归,如基于region proposal的r
‑
cnn系算法(r
‑
cnn、fast r
‑
cnn、faster r
‑
cnn等)。另一类是one
‑
stage算法,如yolo,ssd等,仅仅使用一个卷积神经网络cnn直接预测不同目标的类别与位置。
3.但现有目标检测算法依赖于大量高清晰度、高信息量的数据集训练,如果数据集不够清晰、信息量不足,很容易造成训练模型精度低、欠拟合。例如,对于海洋来说,作为一个国家的重要国土资源,富含大量的生物资源、化石能源、矿产资源、动力资源等,因而经常面临来自其他国家船舶的干扰甚至攻击,通过利用无人机、无人艇等无人设备对目标进行实时监测可以大幅度增加海洋安全性,因此如何提高目标检测准确度显得越来越重要。目前大部分目标数据集,如海洋目标,数据不多、清晰度不够高而且海洋和陆地混合,应用现有的目标检测算法对目标进行检测的效果并不理想,往往造成陆地误识别为目标,且通过非极大值抑制算法(non
‑
maximum suppression,简称nms算法)自适应计算不同训练集中的最佳锚框值,只会根据置信度得分选择一个锚框,不会考虑其他锚框的影响,获得的最佳锚框值的检测准确度不高。因此,提出一种具有高目标检测精度及泛化能力的目标检测方法。
技术实现要素:
4.本发明的目的在于针对上述问题,提出一种基于gan和yolo
‑
v5的目标分割检测方法,可获得检测目标的全部信息,大大提高目标检测精度,具有较好的泛化能力。
5.为实现上述目的,本发明所采取的技术方案为:
6.本发明提出的一种基于gan和yolo
‑
v5的目标分割检测方法,包括如下步骤:
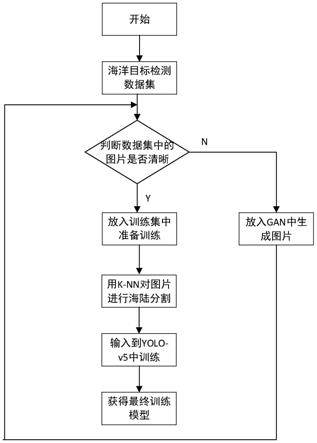
7.s1、获取目标检测数据集并标注目标的真实框;
8.s2、筛选目标检测数据集中的图片,将符合训练要求的图片归为训练集中准备训练,将不符合训练要求的图片采用生成对抗网络进行训练,直到符合训练要求后归为训练集中准备训练;
9.s3、采用k
‑
nn算法对训练集中的图片进行分割;
10.s4、将分割后的训练集中的图片输入yolo
‑
v5模型进行训练,yolo
‑
v5模型包括输入端、backbone网络、neck网络和prediction模块,并执行如下步骤:
11.s41、将输入端预处理后的图片输入backbone网络以获得不同尺度的特征图;
12.s42、将不同尺度的特征图输入neck网络进行特征提取;
13.s43、采用prediction模块对提取特征进行预测并输出多个预测框和对应预测框
的置信度;
14.s44、通过锚框融合算法获得最终预测框和最终预测框的置信度,锚框融合算法计算如下:
[0015][0016][0017]
其中,(x
a
,y
a
)为最终预测框的左上顶点的坐标,(x
b
,y
b
)为最终预测框的右下顶点的坐标,μ为最终预测框的置信度,为第i个预测框的左上顶点的坐标,为第i个预测框的右下顶点的坐标,μ
i
为第i个预测框的置信度,n为预测框的个数;
[0018]
s45、采用giou_loss作为训练损失函数进行反向传播调节权重参数,获得最终训练模型。
[0019]
优选地,步骤s2中,目标检测数据集中的图片的筛选包括如下步骤:
[0020]
s21、获取图片的灰度值并计算灰度方差,灰度方差计算公式如下:
[0021][0022][0023]
其中,f(x,y)为图片像素点(x,y)的灰度值,μ为图片的灰度平均值,n
x
为图片x方向上的像素点个数,n
y
为图片y方向上的像素点个数;
[0024]
s22、判断图片是否符合训练要求,若灰度方差大于第二预设阈值,则符合训练要求,否则,不符合训练要求。
[0025]
优选地,步骤s3中,k
‑
nn算法具体如下:
[0026]
s31、计算预测点与各个点之间的欧氏距离,并根据距离大小排序;
[0027]
s32、选择距离最小的k个点统计类别,以统计频率最高的类别作为预测点的类别。
[0028]
优选地,k
‑
nn算法通过交叉验证获得k值。
[0029]
优选地,步骤s41中,预处理为将图片缩放并进行归一化后依次进行mosaic数据增强、自适应锚框计算、自适应图片缩放操作。
[0030]
优选地,步骤s45中,giou_loss计算如下:
[0031][0032][0033]
其中,a为真实框,b为最终预测框,c为真实框和最终预测框的闭包,即包围真实框和最终预测框的平行于坐标轴的最小矩形。
[0034]
与现有技术相比,本发明的有益效果为:
[0035]
1)该方法通过生成对抗网络将不符合训练要求的图片生成比原数据集更加清晰准确的图片,可充分利用目标数据集,并采用k
‑
nn算法对图片进行分割避免误识别,将处理后的数据集输入yolo
‑
v5模型进行训练后用于目标检测,能有效提高目标检测精度,并具有较好的泛化能力;
[0036]
2)通过锚框融合算法获得最终预测框和最终预测框的置信度,经过融合锚框算法获得的最终预测框包含真实框,进而包含检测目标的全部信息,检测准确度高,尤其在检测目标重合度较高且目标较多时可避免出现漏标少标的情况。
附图说明
[0037]
图1为本发明的目标分割检测方法流程图;
[0038]
图2为本发明的yolo
‑
v5模型结构框图;
[0039]
图3为本发明的yolo
‑
v5模型训练流程图;
[0040]
图4为现有nms算法和本发明的锚框融合算法输出结果比较图。
具体实施方式
[0041]
下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本技术一部分实施例,而不是全部的实施例。基于本技术中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。
[0042]
需要说明的是,除非另有定义,本文所使用的所有的技术和科学术语与属于本技术的技术领域的技术人员通常理解的含义相同。本文中在本技术的说明书中所使用的术语只是为了描述具体的实施例的目的,不是在于限制本技术。
[0043]
如图1
‑
4所示,一种基于gan和yolo
‑
v5的目标分割检测方法,包括如下步骤:
[0044]
s1、获取目标检测数据集并标注目标的真实框。如本实施例用于海洋目标检测,目标可设为船舶,或根据实际需求调整目标。
[0045]
s2、筛选目标检测数据集中的图片,将符合训练要求的图片归为训练集中准备训练,将不符合训练要求的图片采用生成对抗网络进行训练,直到符合训练要求后归为训练集中准备训练。
[0046]
在一实施例中,步骤s2中,目标检测数据集中的图片的筛选包括如下步骤:
[0047]
s21、获取图片的灰度值并计算灰度方差,
[0048]
1)灰度值计算如下:
[0049]
gray=r*0.3 g*0.59 b*0.11
[0050]
通过上述方法求得gray后,然后将原来的rgb(r,g,b)中的r,g,b统一用gray替换,形成新的颜色rgb(gray,gray,gray),即用rgb(gray,gray,gray)替换原来的rgb(r,g,b)就得到了灰度图。其中r,g,b是原图像的rgb值。
[0051]
2)灰度方差计算公式如下:
[0052][0053][0054]
其中,f(x,y)为图片像素点(x,y)的灰度值,μ为图片的灰度平均值,n
x
为图片x方向上的像素点个数,n
y
为图片y方向上的像素点个数;
[0055]
s22、判断图片是否符合训练要求,若灰度方差大于第二预设阈值,则符合训练要求,否则,不符合训练要求。
[0056]
其中,生成对抗网络(简称gan)是通过让两个神经网络相互博弈的方式进行学习。首先,生成器输入一个分布的数据并通过神经网络模仿生成出一个输出(如假图片),将假图片与真图片的信息共同输入到判别器中。然后,判别器通过神经网络学习分辨两者的差异,做一个分类判断出这张图片是真图片还是假图片。
[0057]
通过生成器与判别器的不断学习训练。最终,生成器能生成与真实图片一模一样的图片,判别器无法判断其真假。gan实际上是在完成一个优化任务:
[0058][0059]
其中,g为生成器;d为判别器;v表示定义的价值函数,代表了判别器的判别性能;p
data
(x)为真实的数据分布;p
z
(z)为生成器的输入数据分布;e为期望。是根据真实数据的对数函数损失建立的,希望判别器d能基于真实数据的分布给出1的判断。因此,通过最大化判别器d可以使d(x)=1。x服从p
data
(x)分布。
[0060]
是根据生成器的生成数据而定的,最理想的情况下,当判别器的输入数据为生成器的生成数据时,判别器输出为0。通过最大化判别器d可以使d(g(z))=0。其中,z服从p
z
分布。这样,生成器与判别器不断对抗训练,通过优化g能在中迷惑判别器,使d(g(z))=1。
[0061]
1)为衡量真实数据与生成器生成的数据之前的差异,引入kl散度:
[0062][0063]
其中,p和q是两种输入数据,当p和q都是离散型变量且分布相同时,有p(x)=q(x),d
kl
(p||q)=0。kl散度具有非负性,衡量了两个数据分布的差异程度,经常被用作表示
两种分布之间的距离,注意d
kl
(p||q)≠d
kl
(q||p)。
[0064]
2)最优化判别器
[0065]
固定价值函数中的生成器,用积分形式表示期望:
[0066]
v(d)=∫
x
p
data
(x)log(d(x)) p
g
(x)log(1
‑
d(x))dx
[0067]
上式只有一个变量d,令y=d(x),a=p
data
(x),b=p
g
(x),a,b均为常数,那么,上式变为:
[0068]
f(y)=alog(y) blog(1
‑
y)
[0069]
对上式求一阶导数,在a b≠0时有:
[0070][0071]
不难得出f
″
(y)<0,则为极大值点,证明了存在最优判别器的可能性。虽然实践中并不知道a=p
data
(x),但可以利用深度学习训练判别器,使d逐渐逼近目标。
[0072]
3)最优化生成器;
[0073]
如最优判别器为:
[0074][0075]
代入v(g,d):
[0076][0077]
通过变换,得到:
[0078][0079]
根据对数基本变换可知:
[0080][0081]
代入v(g,d)得:
[0082][0083][0084]
由kl散度的非负性可得
‑
log4为v(g)的最小值,当且仅当pdata(x)=pg(x)时取
得,即从理论上证明了生成器生成数据分布可以等于真实数据分布。
[0085]
s3、采用k
‑
nn算法对训练集中的图片进行分割。
[0086]
在一实施例中,步骤s3中,k
‑
nn算法具体如下:
[0087]
s31、计算预测点与各个点之间的欧氏距离,并根据距离大小排序;
[0088]
s32、选择距离最小的k个点统计类别,以统计频率最高的类别作为预测点的类别。
[0089]
在一实施例中,k
‑
nn算法通过交叉验证获得k值。
[0090]
本实施例中用于海洋目标检测,采用k
‑
nn算法进行海陆分割,即将图片分为海洋和陆地两部分,可避免把海洋中部分大型船舶识别为陆地的情况,有助于提高检测精度和计算速度。
[0091]
其中,k
‑
nn算法可以根据距离预测点的距离最近的k个点的类别来判断预测点属于哪个类别。二维空间两个点的欧式距离d计算公式为:
[0092][0093]
计算出欧氏距离后然后按照距离从小到大排序。选择距离最小的k个点,统计这些点的类别,出现频率最高的点的类别就是预测点的类别。k值通过交叉验证选择,为本领域技术人员熟知的现有技术,在此不再赘述。
[0094]
s4、将分割后的训练集中的图片输入yolo
‑
v5模型进行训练,yolo
‑
v5模型包括输入端、backbone网络、neck网络和prediction模块,并执行如下步骤:
[0095]
s41、将输入端预处理后的图片输入backbone网络以获得不同尺度的特征图;
[0096]
s42、将不同尺度的特征图输入neck网络进行特征提取;
[0097]
s43、采用prediction模块对提取特征进行预测并输出多个预测框和对应预测框的置信度;
[0098]
s44、通过锚框融合算法获得最终预测框和最终预测框的置信度,锚框融合算法计算如下:
[0099][0100][0101]
其中,(x
a
,y
a
)为最终预测框的左上顶点的坐标,(x
b
,y
b
)为最终预测框的右下顶点的坐标,μ为最终预测框的置信度,为第i个预测框的左上顶点的坐标,为第i个预测框的右下顶点的坐标,μ
i
为第i个预测框的置信度,n为预测框的个数;
[0102]
s45、采用giou_loss作为训练损失函数进行反向传播调节权重参数,获得最终训练模型。
[0103]
在一实施例中,步骤s41中,预处理为将图片缩放并进行归一化后依次进行mosaic
数据增强、自适应锚框计算、自适应图片缩放操作。
[0104]
其中,输入图片首先进行图像预处理,不同图片的长宽都是不一样的,因此经常将原始图片统一缩放到一个标准尺寸,再送入到网络中进行训练,如常用的416*416、608*608等尺寸,本实施例中把图片缩放到608*608并进行归一化后进行mosaic数据增强、自适应锚框计算、自适应图片缩放。mosaic数据增强主要采用随即缩放、随即裁剪、随机排布等方式进行拼接,可以增强小目标的检测效果。
[0105]
yolo
‑
v5模型对原始图片自适应的添加最少的黑边,避免存在信息冗余。图片垂直方向(即y方向)上两端的黑边变少,推理时的计算量也就减少了,因此提高了目标检测速度。yolo
‑
v5模型中针对不同的数据集都会有初始设定长宽的锚框。在网络训练中,网络在初始锚框的基础上输出预测框,进而将获得的最佳锚框和真实框进行比较,计算两者差距,再反向更新,迭代网络参数,以获得最终训练模型。
[0106]
如图2
‑
3所示,yolo
‑
v5模型主要由输入端、backbone、neck和prediction四个部分组成:其中backbone网络采用cspdarknet53结构和focus结构,包含focus结构、cbl结构、spp结构和残差模块,cbl结构由卷积、bn层和relu激活函数组成,focus结构由四组切片、concat和cbl组成,spp结构由cbl和最大池化层组成;neck网络为fpn pan结构,主要由残差模块和cbl结构进行上采样和下采样组成;prediction网络为卷积和预测,均为现有技术中的网络结构,在此不再赘述。prediction模块、锚框融合算法、giou_loss均为输出端操作。
[0107]
如图4所示,一般经过网络训练后,会产生数个大小不等、权值不同的预测框,图中左侧视图中灰色框为预测框,黑色框为真实框,图中右(a)视图为现有技术中采用nms处理获得的结果示意图,灰色框为最终预测框,黑色框为真实框,图中右(b)视图为本技术方法获得的结果示意图,灰色框为最终预测框,黑色框为真实框。现有技术中采用nms处理后,只会留下一个置信度最高的预测框,但是往往仍和真实框有一定差距,尤其在检测目标重合度较高且目标较多时(如海洋目标检测数据集中往往会出现多个船舶重合的图片),采用nms算法会出现漏标少标的情况。本技术在为每个船舶边界锚框找到预测框后,根据每个预测框及其置信度生成融合锚框,即获得最终预测框和最终预测框的置信度,经过融合锚框算法后,会产生一个可以包含真实框的最终预测框,进而包含检测目标的全部信息,检测准确度高。
[0108]
在一实施例中,步骤s45中,giou_loss计算如下:
[0109][0110][0111]
其中,a为真实框,b为最终预测框,c为真实框和最终预测框的闭包,即包围真实框和最终预测框的平行于坐标轴的最小矩形。
[0112]
容易理解的是,采用损失函数进行反向传播调节权重参数为本领域技术人员熟知的技术,在此不再赘述。且本技术还通过测试集验证获得的最终训练模型的识别结果的准确性,并通过不断调整权重参数达到最优结果,以提高目标检测的准确性和泛化能力。将待检测的图片输入最终训练模型即可对待检测的图片进行目标识别,输出检测结果。
[0113]
该方法通过生成对抗网络将不符合训练要求的图片生成比原数据集更加清晰准确的图片,可充分利用现有的目标数据集,并采用k
‑
nn算法对图片进行分割避免误识别,将处理后的数据集输入yolo
‑
v5模型进行训练,通过锚框融合算法获得最终预测框和最终预测框的置信度,经过融合锚框算法获得的最终预测框包含真实框,进而包含检测目标的全部信息,检测准确度高,尤其在检测目标重合度较高且目标较多时可避免出现漏标少标的情况,能有效提高目标检测精度,并具有较好的泛化能力。
[0114]
以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
[0115]
以上所述实施例仅表达了本技术描述较为具体和详细的实施例,但并不能因此而理解为对申请专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本技术构思的前提下,还可以做出若干变形和改进,这些都属于本技术的保护范围。因此,本技术专利的保护范围应以所附权利要求为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。