1.本发明涉及一种天文学大规模数据处理与高性能计算交叉领域的技术,具体是一种用于处理射电望远镜数据的脉冲星搜索并行优化方法,通过cpu并行加速和负载平衡的方式提升其性能。搜索到的脉冲星可用于航天器导航,原子钟校准等工业领域。
背景技术:
2.基于脉冲星寿命长,脉冲信号周期稳定,辐射范围广以及不受环境和人为因素影响等特点,可用于对铯原子钟进行百纳秒量级甚至更小精度的校准。其中,以毫秒脉冲星的自转周期为基准建立的时间计量系统,在固定观测频率上,以原子时为参考,获得一系列脉冲到达时间,并与脉冲星时间分析模型给出的预报值相比较,从而提升原子时系统的计时稳定性。因此,需要从观测数据中发现更多的脉冲星,从而不断地提升脉冲星时间计量系统的可靠性。
3.随着大规模低频射电望远镜阵列及配套超宽带接收机设备的建设和使用,由射电脉冲星巡天而采集到的观测数据已经达到了pb量级,经过处理后每年将至少产生千万量级的脉冲星候选体。然而,由于受到射频干扰,红移等因素的干扰,真正能够判定具有明确脉冲星信号,且能为工业领域所用的比例往往低于千分之一,其余高达70%的信号为望远镜台站电磁环境干扰所导致的零色散信号,海量的候选体识别和筛选工作量已成为制约脉冲星搜索和发现的主要因素之一。
4.由scott ransom开发的presto是目前使用最广泛的脉冲星搜寻和分析软件,该流程先经过去除射频干扰和消色散,消色散的结果经过离散快速傅里叶变换,去除红噪声,加速搜索,候选体折叠选出常规的脉冲星候选体,同时,消色散的结果会经过单脉冲搜索选出单脉冲和巨脉冲星候选体。
5.目前存在的针对脉冲星搜索流程的性能优化工作,主要是基于gpu和fpga的并行加速。然而,超过95%的工作流是运行在基于x86和arm架构的多核cpu上,当观测数据长度超过3000s时,整体流程的运行需要一至两天才可完成。
技术实现要素:
6.本发明针对现有技术缺少针对去除射频干扰和消色散单条命令的代码级多线程运行,因此,在单节点尺度下,无法很好的平衡多进程运行的负载的缺陷,提出一种用于处理射电望远镜数据的脉冲星搜索并行优化方法,基于x86和arm架构cpu的脉冲星搜索并行优化方法来大幅降低整体流程的运行耗时,同时兼顾了cpu的负载平衡问题,从而能高效利用单节点上的所有cpu资源。
7.本发明是通过以下技术方案实现的:
8.本发明涉及一种用于处理射电望远镜数据的脉冲星搜索并行优化方法,以多线程方式对搜索射频干扰中每个区间的频率通道进行去除射频干扰,并将射频干扰数据记录到观测数据中;根据消色散方案并采用进程线程配置算法,对每个进程需执行的命令以及命
令的线程数进行分配,从而平衡每个进程的负载,从而以多进程并行方式进行消色散,得到消除色散后的时序文件;对消色散的时序文件数据进行离散快速傅里叶变换和去除红噪声,得到频域文件;以频域文件为输入,依次以多进程方式进行频域加速搜索以及以多进程方式进行候选体折叠,得到常规脉冲星候选体数据;以消色散输出的时序文件数据为输入,以多进程方式进行单脉冲搜索,得到单脉冲星和巨脉冲星的候选体数据。技术效果
9.与现有技术相比,本发明在x86和arm的多核cpu单节点上,采用openmp对去除射频干扰和消色散做多线程并行,并使用多进程技术对脉冲星搜索流程,包括:频域加速搜索,候选体折叠以及单脉冲搜索做了并行优化,并提出了进程线程配置算法来解决消色散并行中负载不均衡的问题,从而充分利用单节点的cpu资源。与未优化版本相比,对于整体流程,x86的优化版本取得了10
‑
12倍的加速比,arm的优化版本取得了25
‑
30倍的加速比,都取得了显著的优化效果。
附图说明
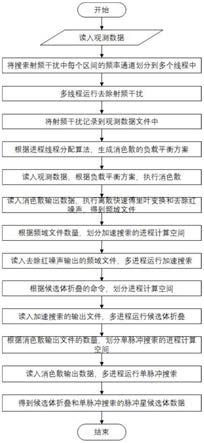
10.图1为脉冲星搜索并行优化运行步骤示意图;
11.图2为消色散多条命令的运行耗时分布示意图;
12.图3为进程线程配置算法运行示意图;
13.图4为去除射频干扰的优化前后性能对比示意图;
14.图5为消色散的优化前后性能对比示意图;
15.图6为频域加速搜索的优化前后性能对比示意图;
16.图7为候选体折叠的优化前后性能对比示意图;
17.图8为单脉冲搜索的优化前后性能对比示意图;
18.图9为脉冲星搜索整体流程的优化前后性能对比示意图。
具体实施方式
19.如图1所示,为本实施例涉及一种用于处理射电望远镜数据的脉冲星搜索并行优化方法,包括以下步骤:
20.步骤一:将搜索射频干扰中每个区间的频率通道划分到多个线程中,随后多线程运行去除射频干扰,并将射频干扰数据记录到观测数据中。
21.步骤二:根据消色散方案,采用进程线程配置算法,平衡每个进程的负载,随后读入观测数据,多进程运行消色散,得到时序文件。
22.步骤三:读入时序文件,运行离散快速傅里叶变换和去除红噪声,得到频域文件。
23.步骤四:根据频域文件的数量,划分频域加速搜索的进程计算空间,并多进程运行频域加速搜索。
24.步骤五:根据候选体折叠的命令数量,划分后选题折叠的进程计算空间,并读入频域加速搜素的输出文件,多进程执行候选体折叠,得到常规脉冲星的候选体数据。
25.步骤六:根据时序文件的数量,划分单脉冲搜索的进程计算空间,多进程运行单脉冲搜索,得到单脉冲和巨脉冲候选体数据。
26.步骤七:得到候选体折叠和单脉冲搜索输出的脉冲星候选体数据,结束流程。
27.在步骤一中,所述的多线程并行方式是指:去除射频干扰会将输入的时间序列分割成多个12秒的区间,它的主要部分是一个循环,在循环的每个轮次中,先对每一个区间的观测数据做射频干扰搜索,这个操作是主要耗时部分,再将搜索到的射频干扰写入标记文件中,该操作需要用到前一轮已经搜索到的射频干扰数据,因此这个循环体不能直接并行。本发明将上述循环体拆分为二,第一个循环体为:对每个区间的观测数据做射频干扰搜索,并存储在数组中,该循环体使用openmp多线程并行。第二个循环体:将存储的射频干扰,写入到标记文件中,该循环体串行执行。同时,为了减少第一个循环体中用于存储数据的内存空间,上述两个循环体的循环次数应设定为并行数,并在外部再设置一个循环,用于循环运行上述两轮循环。
28.在步骤二中,所述的多进程并行方式是指:首先使用多线程框架(openmp)对消色散的代码做多线程并行优化,随后根据消色散方案,对消色散命令多线程运行的耗时做出预测,通过进程线程配置算法,对每个进程需执行的命令以及命令的线程数进行分配,从而平衡进程的负载。
29.所述的消色散方案是指:
30.在步骤二中,首先使用openmp对消色散的c代码做多线程并行。对于单个消色散命令,其主要耗时部分是一个循环,负责对观测数据做消除色散操作。在每个循环的轮次中,首先读取一块去除射频干扰后的观测数据,并生成预处理数据,随后使用上一轮和本轮的预处理数据,对观测数据进行消色散。该循环中,存在数据依赖,不能直接并行,但可以将循环体一分为二,分别并行。拆分后,第一个循环体为:对每块观测数据生成预处理数据并存储起来。第二个循环体为:读取一块观测数据和之前存储的两个预处理数据,进行消色散操作。为了减少用于存储预处理数据的内存空间,上述两个循环体的循环次数应设定为并行数,并在外部再设置一个循环,用于循环运行上述两轮循环。
31.在步骤二中,随后预测消色散命令的耗时。根据多条消色散命令的单线程运行的耗时分布,如附图2,发现:1.消色散多条命令在不同cpu架构和不同观测数据下的耗时分布比较相似。2.在单线程情况下,消色散命令的子通道划分数越大,命令的运算量就越大,耗时就更久。3.当其他参数相同时,命令的耗时与步数成正比。因此,本发明根据消色散方案中的命令参数并设置单条命令多线程运行的并行效率为80%,预测出在不同的子通道划分数和线程数的情况下每条命令的耗时,如下表所示:
32.在步骤二中,随后根据命令耗时的预测值,使用进程线程配置算法,生成最佳的进程线程配置方案,该配置方法包括:总体的进程数,每个进程包含的命令以及相应的线程数(一个进程包含当干命令,命令之间串行执行且使用相同的线程数),从而达到平衡进程负载的目的。该算法流程如附图3,具体步骤如下:
33.步骤a:根据消色散方案,设置需要执行的命令数量为x,则初始化x个进程,每个进程包含一条消色散命令,且每个进程中所有命令的线程数为1。
34.步骤b:设消色散总耗时为t,根据命令耗时的预测值,t表示所有进程耗时的最大值。
35.步骤c:如果当前使用的线程数小于等于节点上cpu核心数,找出最耗时的进程,使进程中每个命令的线程数加1。否则,找出两个耗时最短的进程,将这两个进程中的命令合并为一个进程,并将其线程数设置为原来两个进程中线程数的较大值。
36.步骤d:计算消色散总耗时t新值与旧值的误差δt,验证是否满足收敛条件:当满足收敛条件且当前使用的线程数大于等于节点上cpu核心数,则进程线程配置算法结束,并输出消色散的配置方案,否则,继续步骤c。
37.在步骤四中,加速搜索命令的输入是离散快速傅里叶变换输出的一个频域序列文件,共需要处理两千多个频域序列文件,且不同文件的处理是独立且没有数据依赖的。因此,本发明把所有待处理的文件均分成n份,并设置总体文件数量为m,则在每个进程内部,串行执行m/n个文件。
38.在步骤五中,候选体折叠需要执行多条参数不同但运算量相同的命令,命令数量在50
‑
120之间,且命令之间没有数据依赖。因此,本发明采用多进程功能并行,令进程数为n,命令数量为m,则在每个进程内部,串行执行m/n条命令。
39.在步骤六中,单脉冲搜索的输入是消色散输出的一个时域序列文件,共需要处理两千多个时域序列文件,且不同文件的处理是独立且没有数据依赖的。该步骤的运算情况与步骤四中加速搜索相类似,因此本发明对单脉冲搜索的并行方法同加速搜索相同。
40.经过具体实际实验,使用mwa在中心频率185mhz观测的非相干叠加数据作为测试数据,具体选择了如下4种数据集进行并行测试:数据集观测数据idr.a.(j2000)dec.(j2000)观测时间(s)脉冲星1108885056013:20:07.200
‑
26:37:12.00003535jxxxx
2114536787211:34:17.295
‑
33:25:06.97063613j1116
‑
41223111538107210:10:08.122 10:39:45.93774868jxxxx4113141523214:39:27.431
‑
71:09:36.8236594jxxxx
41.本实施例的具体操作平台分别是intel x86和kunpeng920 arm服务器上的cpu单节点,具体的软硬件型号与版本如下表:
42.如图1所示,经上述实施例方法运行基于openmp多线程优化的去除射频干扰,运行多进程并行且平衡负载的消色散,运行未优化的离散傅里叶变换和去除红噪声,最后依次运行多进程并行版本的频域加速搜索,候选体折叠和单脉冲搜索。在本实施例的基础上通过候选体折叠的输出文件candslist.txt,验证了并行优化后结果的正确性。
43.如附图4,对于去除射频干扰,使用上述优化方法,将openmp线程数设置为cpu的核心数,在x86和arm上分别取得了10
‑
12和10
‑
18倍左右的加速比。
44.如附图5,对于负载平衡后的消色散,通过进程线程配置算法,在x86和arm上分别取得了12
‑
14和18
‑
22倍的加速比。
45.如附图6,7,8,将进程数设置为cpu的核心数,在x86和arm上,频域加速搜索分取得23
‑
25和70
‑
80倍的加速比;候选体折叠取得了8
‑
10和30
‑
40倍的加速比;单脉冲搜索取得了25
‑
30和70
‑
80倍的加速比。
46.如附图9,对于整体流程,x86的优化版本取得了10
‑
12倍的加速比,arm的优化版本取得了25
‑
30倍的加速比。arm平台取得了更高的加速比,归因于脉冲星搜索有很高的可并行性,因此arm平台能充分发挥其更多cpu核心的优势。
47.综上,本发明使用多线程框架(openmp)和多进程功能对热点步骤:去除射频干扰,消色散,频域加速搜索,候选体折叠和单脉冲搜索并行优化,通过cpu并行加速和负载平衡的方式提升其性能。搜索到的脉冲星可用于航天器导航,原子钟校准等工业领域。在x86和arm的多核cpu单节点上,采用多线程与多进程技术对脉冲星搜索流程做了并行优化,在两个平台上都取得了显著的加速效果,并提出了配置算法来解决并行中负载不均衡的问题,从而充分利用单节点的cpu资源。
48.上述具体实施可由本领域技术人员在不背离本发明原理和宗旨的前提下以不同的方式对其进行局部调整,本发明的保护范围以权利要求书为准且不由上述具体实施所限,在其范围内的各个实现方案均受本发明之约束。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。