1.本发明涉及一种基于出租车轨迹序列的乘客下客点提取优化方法,属于位置纠偏方法技术领域。
背景技术:
2.随着经济社会的不断发展以及人们生活水平的不断提高,人们开始倾向于选择出租车出行服务,以满足其对便捷性以及舒适度的要求。出租车是我国目前城市交通的主要组成部分之一,出租车轨迹数据能够很好的反应居民的出行行为以及城市交通的营运状况,因此现在有许多学者利用出租车轨迹数据开展研究,如基于出租车轨迹数据的道路拥堵情况研究、城市功能区识别研究、人口流动模式研究以及城市出入口发现研究。以上研究大多需要出租车的下客点提取结果,而现实生活中,出租车司机往往在即将抵达乘客目的地时,习惯性地提前结束订单,一方面是给顾客以好感,有助于提升自身的好评率,另一方面也有助于系统尽快给其安排新订单,从而增加订单数量。这一行为对于司机来说是一举多得的,但对于科研人员来说却造成了诸多不便,导致他们利用出租车轨迹信息提取出的乘客下客点与真实的乘客下客点存在较大的位置偏差,从而很大程度上影响实验结果。因此有必要设计一种出租车下客点提取优化方法,从而提升出租车下客点的提取精度。
技术实现要素:
3.针对上述现有技术存在的问题,本发明提供一种基于出租车轨迹序列的乘客下客点提取优化方法,从而提升出租车下客点的提取精度。
4.为了实现上述目的,本发明采用的技术方案是:一种基于出租车轨迹序列的乘客下客点提取优化方法,具体包含以下步骤;
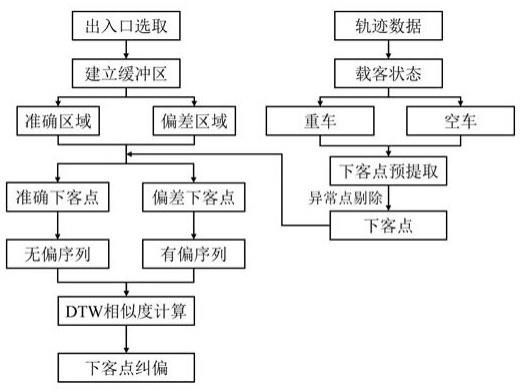
5.s1:获取出租车轨迹数据并根据载客状态字段与时间字段变化情况进行下客点的提取;
6.s2:选取城市中下客点位置较为确定的出入口,在出入口前及通往该出入口的邻接道路上设置缓冲区,分别作为下客点位置准确区域与下客点位置存在偏差区域;
7.s3:筛选出坐落在缓冲区内的下客点,并根据车辆行驶方向与行驶速度进行下客点的清洗;
8.s4.对s3中保留下来的下客点分别进行前后各4个轨迹点的提取,生成长度为9的轨迹序列,经过标准化处理后分别生成下客点位置准确的无偏序列tst与下客点位置存在偏差的有偏序列tsw;
9.s5.使用dtw序列相似度度量方法分别计算tst中轨迹序列与tsw中轨迹序列的相似度;
10.s6.选取tst中与tsw序列相似度最高的轨迹序列tsm作为匹配序列,将tsw中行驶速度与tsm中第5个轨迹点的行驶速度最接近的点作为纠正后的下客点。
11.优选的,所述s1步骤具体为:
12.s11.根据出租车轨迹信息的载客状态字段变化情况进行上客点与下客点的预提取,“重车”变化为“空车”的时刻为下客点,“空车”变化为“重车”的时刻为上客点;
13.s12.根据轨迹数据中的时间字段进行下客点提取结果的清洗,剔除订单执行时间小于5分钟的上下客点。
14.3.根据权利要求1所述的一种基于出租车轨迹序列的乘客下客点提取优化方法,其特征在于,所述s3步骤具体为:
15.s31:根据引射线法判断下客点与s2中所建缓冲区的空间位置关系,即从下客点出发引一条射线,根据射线和多边形所有边的交点数目进行判断,如果有奇数个交点,则下客点在缓冲区内部,如果有偶数个交点,则下客点在缓冲区外部;筛选出交点数目为奇数,即落在缓冲区内的下客点;
16.s32:根据落在缓冲区内车辆的行驶方向与车辆的行驶速度进行下客点的清洗,即剔除邻接道路缓冲区内行驶方向d1与出入口相对于车辆的方向d2的夹角大于45
°
的下客点和行驶速度为0的下客点,以确保s32提取出的下客点的目的地为所选出入口。
17.优选的,所述s4步骤具体为:
18.s41.以s3中提取的下客点为轨迹中心,分别进行该点前后各4个轨迹点行驶速度的提取,生成长度为9的出租车轨迹序列{dp1,dp2,dp3,dp4,dp5,dp6,dp7,dp8,dp9,},其中,dp5为该序列预提取的下客点;
19.s42.为了消除数据变异大小因素的影响,使用0
‑
1标准化法对数据进行处理,从而生成下客点位置准确的无偏序列tst与下客点位置存在偏差的有偏序列tsw。标准化公式如下:
[0020][0021]
其中,x
*
为归一化后的序列值,x为当前正在处理的序列值,x
min
为当前序列的最小值,x
max
为当前序列的最大值。
[0022]
优选的,所述s5步骤具体为:
[0023]
s51.使用9*9的矩阵m表示两条轨迹序列a,b之间各个点的距离,两点之间距离:
[0024]
m(i,j)=|a(i)
‑
b(j)|,1≤i,j≤9
[0025]
其中,m(i,j)为序列a的第i个点和序列b的第j个点之间的距离,a(i)为轨迹序列a第i个轨迹点的行驶速度,b(j)为轨迹序列b第j个轨迹点的行驶速度;
[0026]
s52.初始化轨迹序列a与b的最短距离,即:
[0027]
l
min
(1,1)=m(1,1)
[0028]
其中,l
min
(1,1)为序列a中第1个点到序列b中第1个点的最短距离,m(1,1)为序列a中第1个点到序列b中第1个点的距离;
[0029]
s53.根据如下递归规则求解轨迹序列a与轨迹序列b之间的最短距离:
[0030]
l
min
(i,j)=min{l
min
(i,j
‑
1),l
min
(i
‑
l,j),l
min
(i
‑
1,j
‑
1)} m(i,j)
[0031]
其中,l
min
(i,j)为序列a中第i个点到序列b中第j个点的最短距离,m(i,j)为序列a中第i个点到序列b中第j个点的距离;
[0032]
根据此递归算法求得的距离即为轨迹序列a与b之间的最短距离,以此距离表示两
条轨迹序列的相似程度。
[0033]
本发明的有益效果是:本发明通过对出租车轨迹数据进行清洗,消除了系统误差与偶然误差对下客点提取结果的影响;提出了一种基于轨迹序列的下客点位置提取优化方法,构造了以下客点为中心的出租车行驶轨迹序列,通过dtw序列相似度度量方法提取了与有偏轨迹序列相似度最高的无偏轨迹序列,并通过车速匹配的方法提取了纠正后的下客点位置,有效提升了出租车下客点的提取精度。
附图说明
[0034]
图1为本发明的一种基于出租车轨迹序列的下客点位置提取优化方法实施例的流程图;
[0035]
图2为本发明的基于缓冲区的下客点提取图;
[0036]
图3为本发明的基于最高相似度序列的下客点优化示意图;
[0037]
图4为本发明的下客点提取优化结果图。
具体实施方式
[0038]
为使本发明的目的、技术方案和优点更加清楚明了,下面通过附图及实施例,对本发明进行进一步详细说明。但是应该理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限制本发明的范围。
[0039]
除非另有定义,本文所使用的所有的技术术语和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同,本文中在本发明的说明书中所使用的术语只是为了描述具体的实施例的目的,不是旨在于限制本发明。
[0040]
参照图1
‑
图4所示,本发明的一种基于出租车轨迹序列的乘客下客点提取优化方法,包含以下步骤:
[0041]
s1.获取出租车轨迹数据并根据载客状态字段与时间字段变化情况进行下客点的提取;
[0042]
s11.根据出租车轨迹信息的载客状态字段变化情况进行上客点与下客点的预提取,“重车”变化为“空车”的时刻为下客点,“空车”变化为“重车”的时刻为上客点。
[0043]
s12.考虑到轨迹数据中存在系统误差与偶然误差从而导致提取结果中存在噪声点,所以根据轨迹数据中的时间字段进行下客点提取结果的清洗,剔除订单执行时间小于5分钟的上下客点。
[0044]
s2.选取城市中下客点位置较为确定的出入口,在出入口前及通往该出入口的邻接道路上设置缓冲区,分别作为下客点位置准确区域与下客点位置存在偏差区域。
[0045]
s3.筛选出坐落在缓冲区内的下客点,并根据车辆行驶方向与行驶速度进行下客点的清洗;
[0046]
s31.根据引射线法判断下客点与s2中所建缓冲区的空间位置关系,即从下客点出发引一条射线,根据射线和多边形所有边的交点数目进行判断,如果有奇数个交点,则下客点在缓冲区内部,如果有偶数个交点,则下客点在缓冲区外部。筛选出交点数目为奇数,即落在缓冲区内的下客点。
[0047]
s32:根据落在缓冲区内车辆的行驶方向与车辆的行驶速度进行下客点的清洗,即
剔除邻接道路缓冲区内行驶方向d1与出入口相对于车辆的方向d2的夹角大于45
°
的下客点和行驶速度为0的下客点,以确保s32提取出的下客点的目的地为所选出入口。
[0048]
s4.对s3中保留下来的下客点分别进行前后各4个轨迹点的提取,生成长度为9的轨迹序列,经过标准化处理后分别生成下客点位置准确的无偏序列tst与下客点位置存在偏差的有偏序列tsw;
[0049]
s41.以s3中提取的下客点为轨迹中心,分别进行该点前后各4个轨迹点行驶速度的提取,生成长度为9的出租车轨迹序列{dp1,dp2,dp3,dp4,dp5,dp6,dp7,dp8,dp9,},其中,dp5为该序列的下客点。
[0050]
s42.为了消除数据变异大小因素的影响,使用0
‑
1标准化法对数据进行处理,从而生成下客点位置准确的轨迹序列tst与下客点位置存在偏差的轨迹序列tsw。标准化公式如下:
[0051][0052]
其中,x
*
为归一化后的序列值,x为当前正在处理的序列值,x
min
为当前序列的最小值,x
max
为当前序列的最大值。
[0053]
s5.使用dtw序列相似度度量方法分别计算tst中轨迹序列与tsw中轨迹序列的相似度。
[0054]
s51.使用9*9的矩阵m表示两条轨迹序列a,b之间各个点的距离,两点之间距离:
[0055]
m(i,j)=|a(i)
‑
b(j)|,1≤i,j≤9
[0056]
其中,m(i,j)为序列a的第i个点和序列b的第j个点之间的距离,a(i)为轨迹序列a第i个轨迹点的行驶速度,b(j)为轨迹序列b第j个轨迹点的行驶速度。
[0057]
s52.初始化轨迹序列a与b的最短距离,即:
[0058]
l
min
(1,1)=m(1,1)
[0059]
其中,l
min
(1,1)为序列a中第1个点到序列b中第1个点的最短距离,m(1,1)为序列a中第1个点到序列b中第1个点的距离。
[0060]
s53.根据如下递归规则求解轨迹序列a与轨迹序列b之间的最短距离:
[0061]
l
min
(i,j)=min{l
min
(i,j
‑
1),l
min
(i
‑
1,j),l
min
(i
‑
1,j
‑
1)} m(i,j)
[0062]
其中,l
min
(i,j)为序列a中第i个点到序列b中第j个点的最短距离,m(i,j)为序列a中第i个点到序列b中第j个点的距离。
[0063]
根据此递归算法求得的距离即为轨迹序列a与b之间的最短距离,以此距离表示两条轨迹序列的相似程度。
[0064]
s6.选取tst中与tsw序列相似度最高的轨迹序列tsm作为匹配序列,将tsw中行驶速度与tsm中第5个轨迹点的行驶速度最接近的点作为纠正后的下客点。
[0065]
本发明首先通过对出租车轨迹数据进行清洗,消除了系统误差与偶然误差对下客点提取结果的影响;提出了一种基于轨迹序列的下客点位置提取优化方法,构造了以下客点为中心的出租车行驶轨迹序列,通过dtw序列相似度度量方法提取了与有偏轨迹序列相似度最高的无偏轨迹序列,并通过车速匹配的方法提取了纠正后的下客点位置,有效提升了出租车下客点的提取精度。
[0066]
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精
神和原则之内所作的任何修改、等同替换或改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。