1.本发明涉及环境质量监测和预测技术领域,尤其涉及一种基于环境不平衡数据的水质预测方法。
背景技术:
2.虽然人工智能技术在环境监测和预报领域中的应用是目前环境领域研究热点之一,但是环境质量预测具有一个共同的特点即就是环境数据集是典型的不平衡数据集,如根据环保部2020年的数据,我国2020年不合格的地表水质和空气质量仅占总情况的17.6%和13%,所以不合格的地表水质和空气质量属于小概率事件,是少数类样本。
3.而目前对小数类的样本预测是人工智能研究领域的难点。集成监督模型能很好的学习特征和标签之间的关系,使用集成监督模型能够在一定程度上预测这些不平衡的环境数据。尽管使用重采样和欠采样能够在一定程度上缓解数据集的不平衡性,但是同样也会产生更多的噪音数据或者造成特征丢失的后果。
4.迄今为止还未有利用不同非监督模型来增强监督集成模型预测环境质量的案例,更未有综合利用非监督模型、监督集成模型和贪心算法来预测环境不平衡数据的先例。
技术实现要素:
5.为了克服现有技术存在的缺陷与不足,本发明提供了一种基于环境不平衡数据的水质预测方法,该方法综合利用了非监督模型来深度提取新的特征信息,进而强化监督模型,接着使用贪心算法来探索最佳预测能力和特征组合,该方法能够进一步提升监督集成模型预测环境不平衡数据能力,具有推广到多种环境质量预测领域的潜力。
6.为了达到上述目的,本发明采用以下技术方案:
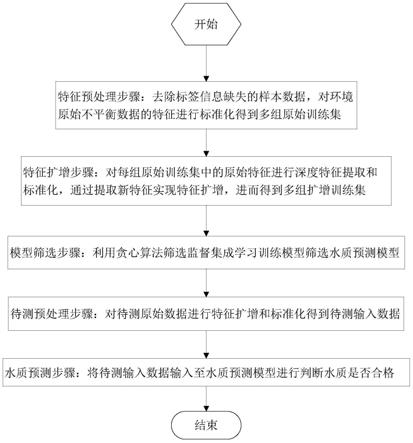
7.一种基于环境不平衡数据的水质预测方法,包括以下步骤:
8.特征预处理步骤:对环境原始不平衡数据集进行去除标签信息缺失的样本数据,对环境原始不平衡数据的特征进行标准化,得到多组原始训练集;
9.特征扩增步骤:对每组原始训练集中的原始特征进行深度特征提取和标准化得到多组扩增训练集;
10.模型筛选步骤:利用贪心算法筛选监督集成学习训练模型,通过贪心算法比较不同特征组合预测结果,选择预测准确度最高的监督集成学习训练模型作为水质预测模型;
11.待测预处理步骤:根据最佳特征组合进行采集输入特征所需的水质数据、大气数据,从而得到待测原始数据,所述最佳特征组合为水质预测模型所对应的特征组合;
12.对待测原始数据进行特征扩增和标准化得到待测输入数据;
13.水质预测步骤:将待测输入数据输入至水质预测模型进行判断水质是否合格。
14.作为优选的技术方案,还包括评价步骤,所述评价步骤具体为执行完水质预测步骤后,利用f1
‑
score对水质预测模型的预测性能进行评价。
15.作为优选的技术方案,所述特征扩增步骤具体步骤为基于特征扩增模型对每组原
始训练集中的原始特征进行深度特征提取和标准化,所述特征扩增模型为非监督模型,所述特征扩增模型具体选择主成分分析模型、局部异常因子检测模型、最小协方差行列式检测模型、基于直方图的离群值检测模型中的一种或任意多种组合的模型。
16.作为优选的技术方案,所述模型筛选步骤,具体步骤包括:
17.基于原始数据的特征划分多组特征组合,依次选择每组特征组合调整扩增训练集中的数据得到多个特征组合训练集;
18.根据每个特征组合训练集建立多个监督集成学习训练模型,对每个监督集成学习训练模型,以特征组合中的特征元素作为输入数据,以水质合格信息作为标签信息,所述水质合格信息用于判断水质是否合格;
19.多个监督集成学习训练模型训练完后,选择预测准确度最高的监督集成学习训练模型作为水质预测模型,选择该水质预测模型所对应的特征组合作为输入特征。
20.作为优选的技术方案,所述多个监督集成学习训练模型采用随机森林、完全收敛随机森林、深度级联森林中的一种或任意多种组合形式。
21.作为优选的技术方案,所述通过贪心算法比较不同特征组合预测结果,具体包括:
22.初始化步骤:
23.输入样本矩阵x,设置循环轮次数值t为0,初始化第0轮的已选择特征集设置第0轮的未选择特征集s0={x1,x2,...,x
p
},其中特征采样矩阵x=x1,x2,
…
,x
p
,第i个特征x
i
=(x
i1
,x
i2
,
…
,x
n
)
y
,i=1,2,
…
,p,其中,p为初始特征维度,n为样本个数;
24.循环步骤:
25.设置模型最佳预测能力比较参数δ=0,δ用于表示模型最佳预测能力之差;
26.计算第t
‑
1轮时最佳特征其中q(*)为模型预测能力值,*用于表示输入参数;
27.设置第t轮时最佳特征集合a
t
=a
t
‑1∪{x
best
};
28.设置第t轮时除去最佳特征集合以外的剩余特征s
t
=s
t
‑1/{x
best
};
29.计算第t轮与第t
‑
1轮的模型最佳预测能力比较参数δ=q(a
t
)
‑
q(a
t
‑1),
30.q(a
t
)为第t轮模型预测能力值,q(a
t
‑1)为第t
‑
1轮模型预测能力值;
31.当δ≤0时,退出循环步骤,输出q值最高的已选择特征集作为特征组合。
32.本发明与现有技术相比,具有如下优点和有益效果:
33.(1)本发明提出的基于环境不平衡数据的水质预测方法通过综合利用非监督模型来深度提取新的特征信息来强化监督模型,并利用贪心算法来探索最佳预测能力和特征组合,该方法通过特征扩增和特征选择来提升监督集成模型对环境不平衡数据的预测能力,进而进一步提高监督集成模型的预测能力,具有推广到多种环境质量预测领域的潜力。
34.(2)与传统学习模型lr、svm、svm等相比,本发明提出的基于环境不平衡数据的水质预测方法通过贪心算法能够显著提升寻找最佳预测能力和最佳特征组合的效率,能够显著提升对环境污染等突发事件的准确性,该方法的这一优势对环境质量预测极为重要,特别对于环境突发事件中的应用具有较高的参考价值;在本发明中,非监督模型能在最佳特征的基础上进一步挖掘少数类和多数类样本特征信息,具有进一步提高集成监督模型预测环境不平衡数据能力。
35.(3)本发明提出的基于环境不平衡数据的水质预测方法通过深度挖掘新的特征,
能够节省在新的环境质量因子和参数的检测费用,本领域技术人员基于该方法可以建立一个高度灵敏的环境介质预警系统,以供环保监测和管理部门应用于水质预警,从而保障生态环境安全。
附图说明
36.图1为本发明实施例1中一种基于环境不平衡数据的水质预测方法的步骤流程图;
37.图2为本发明实施例1中采用的深度级联森林模型的结构示意图。
具体实施方式
38.在本公开的描述中,需要说明的是,术语“中心”、“上”、“下”、“左”、“右”、“竖直”、“水平”、“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本公开和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本公开的限制。
39.此外,术语“第一”、“第二”、“第三”仅用于描述目的,而不能理解为指示或暗示相对重要性。同样,“一个”、“一”或者“该”等类似词语也不表示数量限制,而是表示存在至少一个。“包括”或者“包含”等类似的词语意指出现在该词前面的元素或者物件涵盖出现在该词后面列举的元素或者物件及其等同,而不排除其他元素或者物件。“连接”或者“相连”等类似的词语并非限定于物理的或者机械的连接,而是可以包括电性的连接,不管是直接的还是间接的。
40.在本公开的描述中,需要说明的是,除非另有明确的规定和限定,否则术语“安装”、“相连”、“连接”应做广义理解。例如,可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通。对于本领域的普通技术人员而言,可以具体情况理解上述术语在本公开中的具体含义。此外,下面所描述的本公开不同实施方式中所涉及的技术特征只要彼此之间未构成冲突就可以相互结合。
41.为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
42.实施例
43.实施例1
44.如图1所示,本实施例提供了一种基于环境不平衡数据的水质预测方法,该方法包括以下步骤:
45.特征预处理步骤:对所有环境原始不平衡数据集进行去除标签信息缺失的样本数据,对环境原始不平衡数据的特征进行标准化,进而得到多组原始训练集。实际应用时,环境原始不平衡数据为水质参数、大气质量参数中的一种或任意多种参数进行组合的特征数据,其中水质参数具体包括ph、温度、浊度、电导率、重金属、氯化物、硫酸盐、溶解性氧,大气质量参数具体包括pm2.5、pm10、臭氧、二氧化硫、二氧化氮;
46.特征扩增步骤:对每组原始训练集中的原始特征进行深度特征提取和标准化,通过提取新特征实现特征扩增,进而得到多组扩增训练集。实际应用时,基于特征扩增模型对
每组原始训练集中的原始特征进行深度特征提取和标准化,其中特征扩增模型为非监督模型,具体通过选择主成分分析模型(principal component analysis,pca)、局部异常因子检测模型(local outlier factor,lof)、最小协方差行列式检测模型(minimum covariance determinant,mcd)、基于直方图的离群值检测模型(histogram
‑
based outlier score,hbos)中的一种或任意多种组合的模型实现特征扩增。
47.模型筛选步骤:利用贪心算法筛选监督集成学习训练模型,通过贪心算法比较不同特征组合预测结果,选择预测准确度最高的监督集成学习训练模型作为水质预测模型;
48.待测预处理步骤:根据最佳特征组合进行采集输入特征所需的水质数据、大气数据,从而得到待测原始数据,最佳特征组合为水质预测模型所对应的特征组合;
49.对待测原始数据进行特征扩增和标准化,以提取新特征,进而得到待测输入数据;
50.水质预测步骤:将待测输入数据输入至水质预测模型进行判断水质是否合格;
51.实际应用时,执行完水质预测步骤后,本实施例利用f1
‑
score对水质预测模型的预测性能进行评价。
52.在本实施例中,模型筛选步骤,具体步骤包括:
53.基于原始数据的特征划分多组特征组合,依次选择每组特征组合调整扩增训练集中的数据得到多个特征组合训练集;
54.根据每个特征组合训练集建立多个监督集成学习训练模型,对每个监督集成学习训练模型,以其特征组合中的特征元素作为输入数据,以水质合格信息作为标签信息,水质合格信息用于判断水质是否合格;
55.多个监督集成学习训练模型训练完后,选择预测准确度最高的监督集成学习训练模型作为水质预测模型,选择该水质预测模型所对应的特征组合作为输入特征;
56.多个监督集成学习训练模型采用随机森林、完全收敛随机森林、深度级联森林中的一种或任意多种组合形式的模型。
57.在本实施例中,通过贪心算法比较不同特征组合预测结果,具体包括:
58.初始化步骤:
59.输入样本矩阵x,设置循环轮次数值t为0,初始化第0轮的已选择特征集设置第0轮的未选择特征集s0={x1,x2,...,x
p
},其中特征采样矩阵x=x1,x2,
…
,x
p
,第i个特征x
i
=(x
i1
,x
i2
,
…
,x
n
)
y
,i=1,2,
…
,p,其中,p为初始特征维度,n为样本个数;
60.循环步骤:
61.设置模型最佳预测能力比较参数δ=0,δ用于表示模型最佳预测能力之差;
62.计算第t
‑
1轮时最佳特征其中q(*)为模型预测能力值,*用于表示输入参数。
63.设置第t轮时最佳特征集合a
t
=a
t
‑1∪{x
best
};
64.设置第t轮时除去最佳特征集合以外的剩余特征s
t
=s
t
‑1/{x
best
};
65.计算第t轮与第t
‑
1轮的模型最佳预测能力比较参数δ=q(a
t
)
‑
q(a
t
‑1);
66.当δ≤0时,退出循环步骤,输出q值最高的已选择特征集作为特征组合。
67.如图2所示,本实施例以监督集成学习训练模型中采用深度级联森林模型为例进行说明:该深度级联森林模型由特征预处理模块、n级联森林联结层以及输出处理层构成,特征预处理模块用于对输入的初始特征进行预处理得到输入特征向量,n级联森林联结层
以输入特征向量作为输入并输出预测向量,输出处理层利用1级森林联结层进行平滑处理和筛选预测向量的最大值,进而获得预测结果。其中n级联森林联结层中的每层设有相同数量的估计器,n为联森林联结层的层数,每层设有多个估计器,每个估计器包括多个树。
68.实施例2
69.下面结合具体案例对本发明作进一步详细说明,但是不作为对本发明的限定。在下面的例子中,模型运行平台为python v.3.6.,模型评价指标为f1
‑
score。实际饮用水水质数据集来自德国某水务集团。
70.实际饮用水数据经过前处理后具有133212条样本,其中不合格水质样本比较仅为0.18%,为极端不平衡数据。每条样本中包含ph,电导率(cond),浊度(turb),光谱吸收系数(sac),温度(tp),和脉冲频率调制值(pfm),其中前四个参数发生变化则为不合格饮用水。
71.首先对原始环境不平衡数据(饮用水水质数据集)中6个特征进行质检并通过计算z值来标准化各特征。
72.选择pca、lof、mcd、hbos四种模型进行深度特征提取,从而达到特征扩增的效果。
73.在本实施例中,pca模型分别进行pca原始特征提取和pca异常值特征提取。通过原始样本矩阵x与投影矩阵w相乘得到pca原始特征矩阵f
pca
,即:
74.f
pca
=x
·
w;
75.令原始样本矩阵x的协方差矩阵为s,(λ1,e1),(λ2,e2),
…
,(λ
p
,e
p
)为协方差矩阵s的特征
‑
特征值向量对,其中λ1≥λ2≥
…
λ
p
≥0,投影矩阵w为根据特征值对应的特征构成,具体根据特征值按数值大小取前k个;原始样本矩阵x的大小是n
×
p维,投影矩阵w的大小是p
×
k维,pca原始特征矩阵f
pca
的大小是n
×
k维。
76.在本实施例中,pca异常值特征矩阵f
odpca
为通过所有样本在对应特征向量方向的偏差构成,pca异常值特征矩阵f
odpca
具体表示为:
[0077][0078]
在本实施例中,特征向量反映了原始数据方差的不同方向,表示第1个样本在第1个特征向量方向的偏差,表示第1个样本在第p个特征向量方向的偏差,表示第n个样本在第p个特征向量方向的偏差。
[0079]
在本实施例中,lof异常值特征矩阵f
lof
为根据所有样本的lof异常值构成,lof异常值特征矩阵f
lof
具体表示为:
[0080]
f
lof
=(lof
k
(x1),lof
k
(x2),
…
,lof
k
(x
n
))
t
[0081]
式中t为转置矩阵的标识,lof
k
(x
i
)为第i个样本的lof异常值,i=1,2,
…
,n。
[0082]
在本实施例中,mcd异常值特征矩阵f
mcd
为根据所有样本分别与mcd参考点的mahalanobis距离值构成,mcd异常值特征矩阵f
mcd
具体表示为:
[0083]
f
mcd
=(d1,d2,
…
,d
n
)
t
[0084]
式中t为转置矩阵的标识,d
i
(i=1,2,
…
,n)表示为第i个样本与mcd参考点t
mcd
的mahalanobi s距离值。
[0085]
在本实施例中,hbos异常值特征f
hbos
为根据各个样本在多维数据中的hbos异常值构成,hbos异常值特征f
hbos
具体表示为:
[0086]
f
hbos
=(hbos(x1),hbos(x2),
…
,hbos(x
n
))
t
[0087]
式中t为转置矩阵的标识,x
i
(i=1,2,
…
,n)表示为第i个样本,hbos(x
i
)表示第i个样本在多维数据中的hbos异常值。
[0088]
实际应用时,hbos异常值具体采用静态跨度的柱状图或动态宽度柱状图进行计算。
[0089]
在本实施例中,以监督集成学习训练模型采用深度级联森林为例进行进一步说明,在深度级联森林中,最大层数为10层,每层有4个估计器,每个估计器有200个树组成。其中主要超参penalty设置为l2,c设置为1,solver设置为l
‑
bfgs,griterion设置为gini。
[0090]
依次输入不同特征和运行贪心算法后,经分析,利用实施例1中基于环境不平衡数据的水质预测方法筛选的深度级联森林的最佳预测f1
‑
socre为95.08
±
1.57%,高于单独使用深度级联森林的预测能力(91.75
±
4.09%)。
[0091]
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。