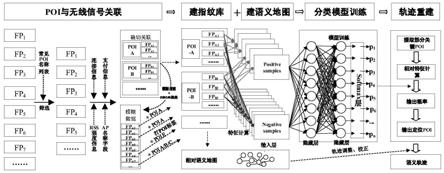
1.本发明实施例涉及人员定位与语义轨迹重建技术领域,尤其涉及一种基于无线众包数据的人员室内语义轨迹重建方法。
背景技术:
2.疫情期间确诊人员活动轨迹调查、精准营销等等都对人员轨迹重建技术研究都有着强烈的需求。由于室外gnss技术的日趋成熟,室外人员轨迹重建技术实施上难度不是很大,并且往往可以恢复出完整的绝对运动轨迹。相较于室外,室内恢复绝对轨迹需要更多的硬件辅助以及面临更加复杂的环境,而实际应用中“概略位置 语义信息”的组合完全可以支撑起各类应用需求。
3.当前室内人员轨迹重建方法大多借助各种室内定位技术确定人员的绝对位置(wifi、蓝牙、uwb、惯导等),在确定行人绝对位置基础上,再将相应的绝对位置同某些邻近poi关联起来,从而实现人员的语义轨迹重建。而这其中使用的各类定位技术往往需要复杂的硬件设备支持,其中还掺杂着复杂的实地安装、量测工作,同时还对有地图等各方面的需求。无论是从成本还是实际实施落地都存在极大的困难。实际应用中,gnss或者移动基站提供的概略位置加上一些语义信息足以描述行人的语义轨迹,也足以支撑起比如流行病调查中活动轨迹重建、精准营销中基于语义轨迹的人物画像等应用,因此有必要提出一种弱依赖、低成本的语义轨迹重建方法。
技术实现要素:
4.为了解决现有技术中存在的问题,本发明提供一种基于无线众包数据的人员室内语义轨迹重建方法,以实现无地图、无额外设备安装布设、无额外量测情况下的人员室内语义轨迹重建。
5.本发明的技术方案为:一种基于无线众包数据的人员室内语义轨迹重建方法,包括如下步骤:首先对以下符号进行定义;ap表示接入点,rss表示信号接收强度,poi表示兴趣点,gnss表示全球卫星导航定位系统,uwb表示超宽带;无线扫描列表内一般包括ap的名称、mac(物理地址)和rss(信号强度)。然后进行以下操作:
6.步骤1,众包数据清洗,以筛选出内含poi信息的无线扫描列表,以及辅助判断的支付信息、无线连接信息、惯性传感器信息;
7.步骤2,将无线信号与poi进行关联,为无线信号数据打位置标签,从而生成poi指纹库,所述poi指纹库包括扫描无线扫描列表和对应的poi名称;步骤3,根据步骤2中建立的关联指纹数据中rss关系反推出poi间的相对位置关系,得到相对语义地图;
8.步骤4,构建指纹匹配模型,并通过建立的poi指纹库训练指纹匹配模型,模型输出匹配结果和该结果的置信度;
9.步骤5,通过步骤4中的指纹匹配模型确定行人经过的poi,并通过相对语义地图纠正误匹配。
10.进一步的,步骤1中众包数据清洗的具体实现方式如下;
11.step11,建立定位场景下的poi列表,该列表需包含尽量多的字段;
12.step12,通过模糊搜索手段,并制定的匹配规则与step11中列表进行匹配,将众包无线数据中含有列表中相关常见poi名称信息的数据筛选出来,所述匹配规则包括中英文、大小写、缩写简称、部分字段;
13.step13,对众包数据中辅助判断的信息进行保留。
14.进一步的,步骤2的具体实现方式如下;
15.step21,针对步骤1中筛选出来的辅助判断信息,将部分无线扫描列表和某一确定的poi关联起来,具有相同名称的poi可以通过关联的ap的mac进行区分;如两个poi都是kfc,两个poi内的ap名称都相同都是“ap
‑
kfc”,这时可以通过两个ap的物理地址(mac)对这两个ap进行区分,即对这两个poi进行区分;
16.step22,针对某些无线扫描列表没有关联的辅助信息,此时使用数据中某一ap的rss在扫描列表中的排序始终靠前,并且这一ap的名称中含有步骤1中poi名称列表某一poi字段,同样做关联操作;
17.step23,当某些已经能够与无线扫描数据确切关联的poi上出现新的扫描数据时,使用dbscan,即具有噪声的基于密度的聚类方法确定是否将新的扫描数据与之关联,将筛选出来的数据和该poi下确定的数据分为两类:即同一poi上的数据和不是同一poi上的数据,当该poi下确定数据有多条时,每条与筛选出来的数据合并聚类,最后依据结果投票确定数据是否可以和poi关联,模糊结果均不予关联;
18.step24,上述操作结束后,便建立起无线poi指纹库,包括扫描无线扫描列表和对应的poi名称;定义指纹点即一个poi,通过众包数据找出一些在poi上扫描的无线数据,即这一指纹点上的指纹信息,也就是一个无线扫描的列表,这个列表里包括扫到的ap名称、mac和对应的接收信号强度rss,然后对每条指纹数据中rss做归一化处理;
[0019][0020]
其中rss
std
分别表示rss列表的均值和方差,表示扫描列表中第i个ap的接收信号强度。
[0021]
进一步的,步骤4中训练指纹匹配模型的具体实现方式如下;
[0022]
step41,将步骤2中的无线指纹库中的指纹信息两两配对,如果两条信息来自同一poi,这样的一对信息用于后续计算生成正样本;如果两条信息来自不同poi,这样的一对信息用于后续计算生成负样本;
[0023]
step42,利用step41组成的配对来计算新的相对特征,包括相似度特征、排序特征、移位特征和重合数特征,从而得到新的特征向量,该特征向量就是后续模型训练的正、负样本;
[0024]
step43,通过整理的正负样本,利用神经网络来训练指纹匹配模型,神经网络结构设计中将网络最后一层设计为softmax层,这样使得指纹匹配模型输出的是正样本概率,即匹配上该poi指纹数据的概率,并通过验证集获得阈值pro_threshold。
[0025]
进一步的,步骤5的具体实现方式如下;
[0026]
step51,待进行轨迹重建的数据依据扫描周期在某些时间点上有扫描列表,若某
些扫描列表中排序靠前的ap未出现在步骤1中poi名称列表中,则这一扫描列表时间点定位匹配的poi为none,反之则进入step52;
[0027]
step52,对这一时间点的扫描列表scan_list的rss做归一化处理,在无线poi指纹库中筛选出出现scan_list中的ap的所有指纹点;
[0028]
step53,将筛选出的指纹点数据和scan_list做相对特征,计算得到多条特征向量;
[0029]
step54,将step53中生成的特征向量输入步骤4中训练的指纹匹配模型,输出每一筛出指纹点的匹配概率,提取出概率最高的指纹点;
[0030]
step55,先将概率最高的指纹点的概率同阈值pro_threshold进行比较,大于pro_threshold则将此poi名称和其对应的概略gnss位置作为一条结果输出,反之,则输出none;
[0031]
step56,每一个扫描列表均对应一个时间戳,借助步骤3中生成的相对语义地图对重建的轨迹中时间与相对关系不匹配的结果进行调整、校正;
[0032]
step57,最终恢复出一条语义轨迹,利用圆表示匹配的poi,圆的大小对应匹配的置信度,箭头表示先后关系,各个poi间连接的线段长度表示从上一poi到下一poi经历的时长。
[0033]
与现有技术相比,本发明的创新点和优势如下:
[0034]
1.除了需要场景下收集的无线众包数据(无线数据内需要有与poi关联起来的信息),无需其他任何先验数据,包括基站位置、地图、路网等等。
[0035]
2.使用gnss或者移动基站提供的概略位置加上一些语义信息来描述人员室内轨迹,而非绝对精确位置,这就对场景无任何额外设备铺设的需求,仅依赖场景下现有的ap。
[0036]
3.通过部分含有用户支付信息、连接信息、rss强度信息以及无线中隐含poi信息的众包数据建立起众包数据中无线信号同poi关联,这也免去poi与确定性位置的关联工作(实际中可能是现场勘查等)。
[0037]
4.无线信号和poi关联结束后,依据此关联关系建立的相对语义地图既可以反映场景下各个poi间相对位置关系,同时可以对重建的语义轨迹进行校正。
[0038]
5.将指纹定位中原本使用的绝对特征转化成各类相对特征,将原本多分类问题转成二分类问题,避免小样本学习问题和模型无法迁移的问题,通过神经网络完成模型训练,输出的结果既可以表达是匹配邻近点的概率,也可用于表示匹配结果的置信度。
附图说明
[0039]
图1本发明系统结构组成图;
[0040]
图2本发明相对特征列表;
[0041]
图3本发明相对语义地图构建示意图;
[0042]
图4本发明重建轨迹示意图。
具体实施方式
[0043]
以下结合附图说明和具体实施方式对本发明做进一步详细的说明。
[0044]
首先对本发明中的一些专有名词进行解释:
[0045]
ap(access point),接入点
奈雪”,......},该列表需包含尽量多的字段。
[0061]
step2:通过模糊搜索手段(这其中制定的规则包括中英文、大小写、缩写简称、部分字段等一系列匹配规则,与step1中列表匹配),将众包无线数据中含有列表中相关常见poi名称信息的数据筛选出来。如:
[0062]
扫描列表1:{“kfc_01”:
‑
57dbm;“ap_01”:
‑
66dbm;“ap_11”:
‑
87dbm;......};
[0063]
扫描列表2:{“ap_01”:
‑
57dbm;“nike_office”:
‑
68dbm;“ap_21”:
‑
89dbm;......};
[0064]
扫描列表3:{“ap_05”:
‑
66dbm;“ap_04”:
‑
86dbm;“ap_111”:
‑
97dbm;......};
[0065]
扫描列表4:{“ap_05”:
‑
44dbm;“anta_store”:
‑
46dbm;“huawei_office”:
‑
67dbm;......};
[0066]
......
[0067]
筛选后保留扫描列表1,2,4,其中扫描列表3丢弃。
[0068]
step3:众包数据中一些辅助判断的信息保留,如:
[0069]
eg.1:11:11:30在“kfc”内发生支付行为,此时有无线扫描列表scan_list1【{“kfc_01”:
‑
57dbm;“ap_01”:
‑
66dbm;“ap_11”:
‑
87dbm;......}】,信息保留;
[0070]
eg.2:11:11:30在“nike”内发生扫码行为,此时有无线扫描列表scan_list2【{“ap_01”:
‑
57dbm;“nike_office”:
‑
68dbm;“ap_21”:
‑
89dbm;......}】,信息保留;
[0071]
eg.3:11:11:30—12:00:21时间段内终端始终连接“kfc_01”这一ap,rss始终在扫描列表内排序靠前,信息保留;
[0072]
......
[0073]
part b:无线信号与poi关联,poi指纹库生成
[0074]
1.目的:为无线信号数据打位置标签,并非绝对位置标签,而是poi名称。
[0075]
2.步骤:
[0076]
step1:在part a中的step 3中筛出的辅助判断信息,可以将部分扫描列表和某一poi确定性的关联起来,如part a中的step 3中举例的eg.1和eg.2,其中的scan_list1和scan_list2就可以同“kfc”和“nike”这两个poi确定性关联起来。具有相同名称的poi可以通过关联的ap的mac进行区分;如两个poi都是kfc,两个poi内的ap名称都相同都是“ap
‑
kfc”,这时可以通过两个ap的物理地址(mac)对这两个ap进行区分,即对这两个poi进行区分;
[0077]
step2:某些扫描列表没有关联的辅助信息,此时使用数据中某一ap的rss在扫描列表中的排序始终靠前,并且这一ap的名称中含有part a中poi名称列表某一poi字段,同样可以做关联操作。
[0078]
step3:某些已经能够与无线数据确切关联的poi上出现新的扫描数据时,使用dbscan聚类方法确定是否将新的数据与之关联:将筛选出来的数据和该poi下确定的数据分为两类(当该poi下确定数据有多条时,每条与将筛选出来的数据合并聚类,最后依据结果投票确定每数据是否可以和poi关联,模糊结果均不予关联)。
[0079]
step4:上述操作结束后,便建立起无线poi指纹库,包括扫描无线扫描列表和对应的poi名称,本发明中的指纹点即一个poi,通过众包数据可以找出一些在这些poi上扫描的无线数据,即这一指纹点上的指纹信息,也就是一个无线扫描的列表,这个列表里包括扫到
的ap名称、mac和对应的信号强度(rss),对每条指纹数据中rss做归一化处理。
[0080][0081]
其中rss
std
分别表示rss列表的均值和方差,表示扫描列表中第i个ap的信号强度。
[0082]
part c:相对语义地图
[0083]
1.目的:通过part b中建立的关联和指纹数据中rss关系反推出poi间一个大致的相对关系。
[0084]
2.步骤:
[0085]
step1:依据b中建立的指纹库,每个poi中任一一条指纹数据的ap列表中可能包括许多其他poi名称,结合对应的rss大小,可以建立起该poi同这些poi的相对位置关系。如:
[0086]“kfc”:
[0087]
scan_list1—{“kfc_01”:
‑
57dbm;“nike_office”:
‑
66dbm;“anta_store”:
‑
74dbm;......}
[0088]
scan_list2—{“kfc_01”:
‑
53dbm;“anta_store”:
‑
71dbm;“nike_office”:
‑
73dbm;......}
[0089]
scan_list3—{“kfc_01”:
‑
55dbm;“nike_office”:
‑
68dbm;“anta_store”:
‑
77dbm;......}
[0090]
......
[0091]“nike”:
[0092]
scan_list1—{“nike_office”:
‑
66dbm;“kfc_01”:
‑
69dbm;“anta_store”:
‑
78dbm;......}
[0093]
scan_list2—{“nike_office”:
‑
66dbm;“kfc_01”:
‑
70dbm;“anta_store”:
‑
76dbm;......}
[0094]
scan_list3—{“kfc_01”:
‑
67dbm;“nike_office”:
‑
69dbm;“anta_store”:
‑
79dbm;......}
[0095]
......
[0096]“anta”:
[0097]
scan_list1—{“anta_store”:
‑
48dbm;“ap_01”:
‑
66dbm;“ap_01”:
‑
76dbm;“ap_01”:
‑
86dbm;“ap_01”:
‑
88dbm;“kfc_01”:
‑
99dbm;......}
[0098]
......
[0099]“huawei”:
[0100]
scan_list1—{“huawei”:
‑
48dbm;“ap_01”:
‑
66dbm;“ap_01”:
‑
76dbm;“ap_01”:
‑
86dbm;“ap_01”:
‑
88dbm;.....}
[0101]
step2:step1中每条指纹数据都可建立一组相对关系,如图3中上栏中的各个子图,结合各个子图结果,如step1中“kfc”中scan_list3的结果和scan_list1、scan_list2的结果不一致,可由scan_list1和scan_list2纠正scan_list3的结果,并将组合结果作为输出的最终相对语义地图。
[0102]
step3:同样地,不同poi间的数据也可进行检校,如:step1中“kfc”中的scan_
list1、scan_list2可以用于检校、修正“anta”中的scan_list1的结果。
[0103]
step4:最终得到场景下各个poi上的相对位置关系图谱,即相对语义地图。
[0104]
part d:指纹匹配模型训练
[0105]
1.目的:发挥神经网络对非线性关系的表达能力,利用神经网络训练指纹匹配模型。
[0106]
2.步骤:
[0107]
step1:将part b中的无线指纹库中的指纹信息两两配对,如果两条信息来自同一poi,这样的一对信息用于后续计算生成正样本。如果两条信息来自不同poi,这样的一对信息用于后续计算生成负样本。如:part c中“kfc”的scan_list1和scan_list2配对用于计算正样本特征,“kfc”的scan_list1和“huawei”的scan_list1配对用于计算负样本特征。
[0108]
step2:利用step1组成的配对来计算新的相对特征,这里包括相似度特征、排序特征、移位特征和重合数特征,即配对中的两个rss扫描列表做一些比较、运算得到新的一条特征向量,这条特征向量就是后续模型训练的正、负样本(具体使用特征见图2,特征主要分为四大类,各个大类中又包括一些具体的特征)。如:part c中“kfc”的scan_list1和scan_list2两个列表中ap的重合个数、两个列表的rss的相似度(具体使用相似度见图2)、scan_list1中rss最强的ap在scan_list2中的排序(具体使用排序特征见图2)、scan_list1中某一ap需要移动位数使得该ap位置和scan_list2相同(具体使用移位特征见图2)等等。
[0109]
step3:整理的正负样本来利用神经网络来训练指纹匹配模型,神经网络结构设计中将网络最后一层设计为softmax层,这样使得模型输出就可以是正样本概率,即匹配上该poi指纹数据的概率。并通过验证集数据搜寻出正确匹配上概率阈值pro_threshold。
[0110]
part e:语义轨迹重建与校正
[0111]
1.目的:通过指纹匹配方式确定行人经过的poi,并通过相对语义地图纠正一些误匹配。
[0112]
2.步骤:
[0113]
step1:待进行轨迹重建的数据依据扫描周期在某些时间点上有扫描列表,若某些扫描列表中排序靠前的ap未出现在part a中poi名称列表中(同样使用模糊搜索来进行匹配),这一扫描列表时间点定位匹配的poi为none,反之则进入step2.
[0114]
step2:对这一时间点的扫描列表scan_list的rss做归一化处理,同part b中step4。在无线poi指纹库中筛选出出现scan_list中的ap的所有指纹点。
[0115]
step3:将筛选出指纹点数据和scan_list做相对特征计算,计算方法同part d中step2,计算得到多条特征向量(筛选出的指纹点均对应一条特征向量)。
[0116]
step4:将step3中生成的特征向量输入part d中step3训练的指纹匹配模型,输出每一筛出指纹点的匹配概率,提取出概率最高的指纹点。
[0117]
step5:先将概率最高的指纹点的概率同part d中得到的阈值pro_threshold比较,大于pro_threshold则将此poi名称和其对应的概略gnss位置作为一条结果输出,反之,则输出none。
[0118]
step6:每一个扫描列表均对应一个时间戳,借助part c中生成的相对语义地图可以对重建的轨迹中时间与相对关系不匹配的结果进行调整、校正。如:part c中生成的语义地图中显示“kfc”和“nike”处于邻近位置,但是生成轨迹中“kfc”到“nike”经历时长非常
大,则表明此处存在误匹配,转而验证此次匹配中概率排第二的指纹点,以此类推。
[0119]
step7:最终可以恢复出一条语义轨迹,如:{“kfc”—>(**min)“anta”—>(**min)“nike”—>(**min)“adidas”—>(**min)“fla”—>(**min)“huawei”—>(**min)“meizu”—>(**min)“贤和庄”—>(**min)......},箭头表示先后关系,“**min”表示某一poi到下一poi经历的时长(图4对生成的语义轨迹做了一个简单的举例说明,图中圆表示匹配的poi,圆的大小对应匹配的置信度,各个poi间连接的线段长度表示从上一poi到下一poi经历的时长)。
[0120]
以上所述仅为发明的较佳实例,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。