1.本发明属于模型训练领域,具体涉及一种模型训练方法及装置。
背景技术:
2.现有技术中,为了提高模型推理的效率,通常采用多个子模型融合推理的方法,具体是将多个异构模型按照预设规则转换成标准子模型,每个子模型的结构和权重字典与总模型的每条分支相互对应,基于每个子模型的结构和权重字典将每个标准子模型融合成总模型,将总模型加载至gpu中,并对融合后的总模型进行推理验证;定义总模型的输出为每个子模型的输出组成的列表,通过列表索引将总模型的推理结果映射回子模型。
3.上述方法虽然能提升模型融合推理的效率,但是对于优化数据质量问题以及模型结构从而优化预测效果没有提出解决方案,无法解决数据不确定性和模型学习不确定性的技术问题。
技术实现要素:
4.本发明提供一种模型训练方法及装置,能够解决现有的训练方法存在的数据不确定性和模型学习不确定性的技术问题。
5.本发明解决上述技术问题的技术方案如下:
6.第一方面,本发明提供一种模型训练方法,包括:
7.通过半监督方法对训练数据进行扩充;
8.基于扩充后的训练数据训练得到多个不同模型结构的模型;
9.使用训练得到的多个模型分别对待预测数据进行预测,通过投票的方式选择预测结果。
10.进一步,所述通过半监督方法对训练数据进行扩充,具体包括:
11.将训练数据中的标注数据采用k折数据交叉法划分出k个数据集,将所述k个数据集均采用同一种模型结构训练出k个模型,使用k个模型分别对测试数据进行预测,基于投票的方式获得最终结果,采用以上方法分别训练获得n个不同模型结构的基础模型;
12.采用所述n个基础模型分别对所述训练数据中的未标注数据进行标注,将预测的伪标签数据加入训练集。
13.进一步,所述基于扩充后的训练数据训练得到多个不同模型结构的模型,具体包括:
14.基于扩充后的训练数据,采用对抗算法训练得到多个不同模型结构的模型。
15.进一步,所述对抗训练的公式如下:
[0016][0017]
其中d表示训练集,x表示输入,y表示标签,θ表示模型参数,l(θ,x r
adv
,y)表示单个样本loss,r
adv
表示对抗扰动,s表示扰动空间,表示期望。
[0018]
进一步,所述对抗算法采用快速梯度法fgm。
[0019]
第二方面,本发明提供一种模型训练装置,包括:
[0020]
半监督训练模块,用于通过半监督方法对训练数据进行扩充;
[0021]
模型训练模块,用于基于扩充后的训练数据训练得到多个不同模型结构的模型;
[0022]
投票模块,用于使用训练得到的多个模型分别对待预测数据进行预测,通过投票的方式选择预测结果。
[0023]
进一步,所述半监督训练模块,具体包括:
[0024]
基础模型训练单元,用于将训练数据中的标注数据采用k折数据交叉法划分出k个数据集,将所述k个数据集均采用同一种模型结构训练出k个模型,使用k个模型分别对测试数据进行预测,基于投票的方式获得最终结果,采用以上方法分别训练获得n个不同模型结构的基础模型;
[0025]
伪数据生成单元,用于采用所述n个基础模型分别对所述训练数据中的未标注数据进行标注,将预测的伪标签数据加入训练集。
[0026]
进一步,所述模型训练模块,具体用于:
[0027]
基于扩充后的训练数据,采用对抗算法训练得到多个不同模型结构的模型。
[0028]
进一步,所述对抗训练的公式如下:
[0029][0030]
其中d表示训练集,x表示输入,y表示标签,θ表示模型参数,l(θ,x r
adv
,y)表示单个样本loss,r
adv
表示对抗扰动,s表示扰动空间,表示期望。
[0031]
进一步,所述对抗算法采用快速梯度法fgm。
[0032]
本发明的有益效果是:
[0033]
一方面,本发明训练多个模型从不同的维度模拟数据的分布,让模型更全面学习到数据的特征;并通过半监督方法扩充训练数据,优化训练数据数量的限制,从而解决了数据不确定性问题;
[0034]
另一方面,本发明通过多个不同模型结构的模型对同一份数据进行预测,能够降低模型参数本身的随机性对预测结果的影响,并通过投票的方式选择预测结果,从而解决了模型学习不确定性问题。
附图说明
[0035]
图1为本发明实施例提供的一种模型训练方法的流程示意图;
[0036]
图2为本发明实施例提供的一种模型训练方法的原理示意图;
[0037]
图3为本发明实施例提供的一种模型训练装置的结构示意图。
具体实施方式
[0038]
以下结合附图对本发明的原理和特征进行描述,所举实例只用于解释本发明,并非用于限定本发明的范围。
[0039]
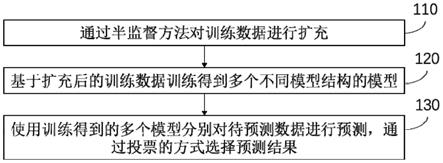
本发明实施例提供的一种模型训练方法,图1为该方法的流程示意图,如图1所示,该方法包括:
[0040]
110、通过半监督方法对训练数据进行扩充;
[0041]
具体的,训练数据中包含标注数据n和未标注数据m,训练数据一般存在不确定性问题,体现在数据标注不一致等质量问题,以及数据标注数量有限,不能有效反映真实世界数据的原貌,该步骤使用半监督方法对训练数据进行扩充,提升泛化能力,从而能够降低标注数据不确定性。
[0042]
120、基于扩充后的训练数据训练得到多个不同模型结构的模型;
[0043]
130、使用训练得到的多个模型分别对待预测数据进行预测,通过投票的方式选择预测结果。
[0044]
具体的,该步骤用于降低模型学习不确定性,具体是采用具有不同模型结构的模型对同一份数据进行预测,降低模型参数本身的随机性对预测结果的影响,并通过投票的方式选择预测结果。
[0045]
本发明实施例提供的一种模型训练方法,具有以下两方面的有益效果:
[0046]
一方面,本发明训练多个模型从不同的维度模拟数据的分布,让模型更全面学习到数据的特征;并通过半监督方法扩充训练数据,优化训练数据数量的限制,从而解决了数据不确定性问题;
[0047]
另一方面,本发明通过多个不同模型结构的模型对同一份数据进行预测,能够降低模型参数本身的随机性对预测结果的影响,并通过投票的方式选择预测结果,从而解决了模型学习不确定性问题。
[0048]
可选地,在该实施例中,步骤110具体包括以下两个子步骤,分别用于针对以上两方面的数据不确定性问题进行优化:
[0049]
1101、将训练数据中的标注数据采用k折数据交叉法划分出k个数据集,将所述k个数据集均采用同一种模型结构训练出k个模型,使用k个模型分别对测试数据进行预测,基于投票的方式获得最终结果,采用以上方法分别训练获得n个不同模型结构的基础模型;
[0050]
该步骤用于解决数据不确定性问题中数据标注不一致的质量问题,具体的,该步骤中,将标注数据n采用k折数据交叉法划分出k个数据集,这样,使得每个数据集体现了数据不同的分布,从而降低原始标注数据不一致对预测的影响。进一步,每个数据集采用同一种模型结构训练出k个模型,再使用k个模型分别对测试数据进行预测,基于投票的方式获得最终结果,从而训练得到了一种模型结构的基础模型。采用上述方法分别训练获得n个不同模型结构的基础模型。
[0051]
1102、采用所述n个基础模型分别对所述训练数据中的未标注数据进行标注,将预测的伪标签数据加入训练集。
[0052]
该步骤用于解决数据不确定性问题中标注数据有限导致模型泛化能力不强的问题,具体的,该步骤中,采用步骤1101中训练得到的n个基础模型分别对训练数据中的未标注数据m进行标注,将预测的伪标签数据加入训练集,如图2所示。
[0053]
可选地,在该实施例中,步骤120具体包括:
[0054]
基于扩充后的训练数据,采用对抗算法训练得到多个不同模型结构的模型。
[0055]
具体的,采用对抗训练的方法同时降低数据和模型学习不确定性。如图2所示,对抗训练将对抗样本加入源数据中,模拟噪音数据,增强模型对噪音数据的鲁棒性。对抗训练将对抗算法(如fgm)加入到模型结构中。对抗训练的公式如下:
[0056]
[0057]
其中d表示训练集,x表示输入,y表示标签,θ表示模型参数,l(θ,x r
adv
,y)表示单个样本loss,r
adv
表示对抗扰动,s表示扰动空间,表示期望。
[0058]
与上述方法实施例相对应地,本发明实施例提供一种模型训练装置,图3为该装置的结构示意图,如图3所示,该装置包括:
[0059]
半监督训练模块,用于通过半监督方法对训练数据进行扩充;
[0060]
具体的,训练数据中包含标注数据n和未标注数据m,训练数据一般存在不确定性问题,体现在数据标注不一致等质量问题,以及数据标注数量有限,不能有效反映真实世界数据的原貌,该步骤使用半监督方法对训练数据进行扩充,提升泛化能力,从而能够降低标注数据不确定性。
[0061]
模型训练模块,用于基于扩充后的训练数据训练得到多个不同模型结构的模型;
[0062]
投票模块,用于使用训练得到的多个模型分别对待预测数据进行预测,通过投票的方式选择预测结果。
[0063]
具体的,该步骤用于降低模型学习不确定性,具体是采用具有不同模型结构的模型对同一份数据进行预测,降低模型参数本身的随机性对预测结果的影响,并通过投票的方式选择预测结果。
[0064]
本发明实施例提供的一种模型训练装置,具有以下两方面的有益效果:
[0065]
一方面,本发明训练多个模型从不同的维度模拟数据的分布,让模型更全面学习到数据的特征;并通过半监督方法扩充训练数据,优化训练数据数量的限制,从而解决了数据不确定性问题;
[0066]
另一方面,本发明通过多个不同模型结构的模型对同一份数据进行预测,能够降低模型参数本身的随机性对预测结果的影响,并通过投票的方式选择预测结果,从而解决了模型学习不确定性问题。
[0067]
可选地,在该实施例中,所述半监督训练模块,具体包括:
[0068]
基础模型训练单元,用于将训练数据中的标注数据采用k折数据交叉法划分出k个数据集,将所述k个数据集均采用同一种模型结构训练出k个模型,使用k个模型分别对测试数据进行预测,基于投票的方式获得最终结果,采用以上方法分别训练获得n个不同模型结构的基础模型;
[0069]
该功能单元用于解决数据不确定性问题中数据标注不一致的质量问题,具体的,该功能单元中,将标注数据n采用k折数据交叉法划分出k个数据集,这样,使得每个数据集体现了数据不同的分布,从而降低原始标注数据不一致对预测的影响。进一步,每个数据集采用同一种模型结构训练出k个模型,再使用k个模型分别对测试数据进行预测,基于投票的方式获得最终结果,从而训练得到了一种模型结构的基础模型。采用上述方法分别训练获得n个不同模型结构的基础模型。
[0070]
伪数据生成单元,用于采用所述n个基础模型分别对所述训练数据中的未标注数据进行标注,将预测的伪标签数据加入训练集;
[0071]
该功能单元用于解决数据不确定性问题中标注数据有限导致模型泛化能力不强的问题,具体的,该步骤中,采用基础模型训练单元中训练得到的n个基础模型分别对训练数据中的未标注数据m进行标注,将预测的伪标签数据加入训练集,如图2所示。
[0072]
可选地,在该实施例中,所述模型训练模块,具体用于:
[0073]
基于扩充后的训练数据,采用对抗算法训练得到多个不同模型结构的模型。
[0074]
具体的,采用对抗训练的方法同时降低数据和模型学习不确定性。如图2所示,对抗训练将对抗样本加入源数据中,模拟噪音数据,增强模型对噪音数据的鲁棒性。对抗训练将对抗算法(如fgm)加入到模型结构中。对抗训练的公式如下:
[0075][0076]
其中d表示训练集,x表示输入,y表示标签,θ表示模型参数,l(θ,x r
adv
,y)表示单个样本loss,r
adv
表示对抗扰动,s表示扰动空间,表示期望。
[0077]
以上,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到各种等效的修改或替换,这些修改或替换都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。