1.本发明涉及图像处理领域,具体为视频图像多目标跟踪方法、系统、存储介质及设备。
背景技术:
2.本部分的陈述仅仅是提供了与本发明相关的背景技术信息,不必然构成在先技术。
3.目标跟踪是指对视频图像中的目标进行检测,提取,识别,预测和跟踪的过程,通过其目标的运动位置的变化,使人们更好的掌握和了解目标的运动情况。目前应用到的领域越来越广泛。例如:
4.汽车安全驾驶领域中,以车辆前方道路上的行人和车辆作为目标,通过目标跟踪获取行人和车辆的位置以及速度进行预估和判断,从而提高驾驶安全性;
5.在一些安防领域,需要实时根据监控视频图像确认特殊目标(人、车辆或物体)的运行轨迹以及特定区域人员的流动变化情况(例如人员聚集的路口、学校等路段的监控);
6.在医疗分析领域,可以通过多目标跟踪对人体内的目标细胞运动情况进行监控。
7.在多目标跟踪中容易发生目标间的相互遮挡和交叉,以及目标在视频中突然消失和重新出现的现象,例如视频图像中,作为目标的人或车辆会受到环境以及其他车辆和行人的遮挡,因此会导致目标丢失,从而出现漏检、误检以及错误的目标id切换等问题。
技术实现要素:
8.为了解决上述背景技术中存在的技术问题,本发明提供视频图像多目标跟踪方法、系统、存储介质及设备,多目标检测部分选用cen ternet(中心网络)作为检测网络,与传统算法中faster r
‑
cnn检测算法相比提高了检测精度。特征提取部分提出将rfbnet与deepso rt算法中行人重识别网络reid相结合来加强特征提取能力。目标跟踪部分,主要采用deepsort算法中的跟踪算法进行跟踪,由于多目标之间易出现目标间的遮挡,利用遮挡轨迹预测机制来减少误检和漏检。
9.为了实现上述目的,本发明采用如下技术方案:
10.本发明的第一个方面提供视频图像多目标跟踪方法,包括以下步骤:
11.基于目标检测模型获取视频图像中目标的中心点位置,依据中心点位置和目标的尺寸信息获得目标的位置信息;
12.利用提取到的目标中心点位置获取目标的预测位置,利用两个目标预测位置的重叠区域判断目标是否被遮挡;
13.基于特征提取网络获取视频图像中目标的外观信息,关联目标的外观信息和位置信息实现跟踪。
14.目标检测模型以视频图像的特征图为输入,利用中心点热力图和中心点偏移量提取目标中心点位置。
15.判断目标是否被遮挡的过程包括,当两个目标的预测位置有重叠时,标记产生重叠的两个目标;跟踪目标时判断没有关联到的目标是否被标记,如果被标记,则该目标的预测位置作为目标的真实位置。
16.特征提取网络包括依次连接的rfb模块、至少两组卷积层、池化层和残差块。输入的视频图像经过rfb模块,再进入卷积层和池化层来降低向量维度,最后经残差块输出提取到的目标外观特征。
17.rfb模块包括分别连接的至少三个卷积层和三个空洞卷积层,图像经卷积层和空洞卷积层实现特征融合,融合的特征通过激活函数输出特征图像。
18.本发明的第二个方面提供视网膜病变图像分类模型训练系统,包括:
19.目标位置检测模块,被配置为:基于目标检测模型获取视频图像中目标的中心点位置,依据中心点位置和目标的尺寸信息获得目标的位置信息;
20.遮挡轨迹预测模块,被配置为:利用提取到的目标中心点位置获取目标的预测位置,利用两个目标预测位置的重叠区域判断目标是否被遮挡;
21.关联追踪模块,被配置为:基于特征提取网络获取视频图像中目标的外观信息,关联目标的外观信息和位置信息实现跟踪。
22.本发明的第三个方面提供一种计算机可读存储介质。
23.一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现如上述所述的视频图像多目标跟踪方法中的步骤。
24.本发明的第四个方面提供一种计算机设备。
25.一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上述所述的视频图像多目标跟踪方法中的步骤。
26.与现有技术相比,以上一个或多个技术方案存在以下有益效果:
27.1、将视频图像中的被跟踪目标当做一个中心点处理,使获得的目标位置更加精确,并且算法过程更加简单迅速,有利于避免传统方式中目标因被遮挡而出现目标丢失,目标身份id切换、漏检和误检的问题。
28.2、识别目标的网络结构上融合了rfb模块,rfb通过模拟rf的大小和偏心率之间的关系,增强了对目标外观的特征提取能力,在保持相同数量参数的情况下,进行更大的图像区域特征提取,保证了特征提取的最大化,有助于后续跟踪关联匹配的准确性提升。
29.3、利用提取到的目标中心点来对可能存在遮挡的目标进行预测,从而减轻目标之间因存在遮挡导致的漏检对后续跟踪过程的影响。
附图说明
30.构成本发明的一部分的说明书附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。
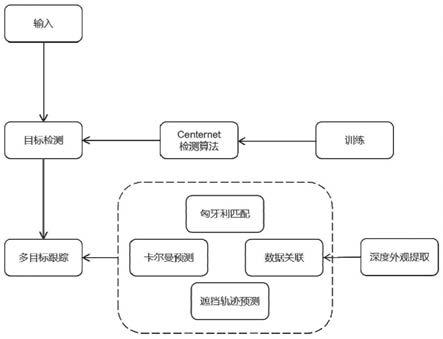
31.图1是本发明一个或多个实施例提供的多目标跟踪流程示意图;
32.图2是本发明一个或多个实施例提供的中心网络体系结构示意图;
33.图3是本发明一个或多个实施例提供的特征提取网络结构示意图;
34.图4是本发明一个或多个实施例提供的rfb网络结构示意图;
35.图5(a)是本发明一个或多个实施例提供的跟踪目标被遮挡导致跟踪失败的示意图;
36.图5(b)是本发明一个或多个实施例提供的跟踪目标被遮挡成功完成目标跟踪的示意图;
37.图6(a)是本发明一个或多个实施例提供的静态拍摄的目标跟踪效果示意图;
38.图6(b)是本发明一个或多个实施例提供的动态拍摄的目标跟踪效果。
具体实施方式
39.下面结合附图与实施例对本发明作进一步说明。
40.应该指出,以下详细说明都是示例性的,旨在对本发明提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本发明所属技术领域的普通技术人员通常理解的相同含义。
41.需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本发明的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,当在本说明书中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作、器件、组件和/或它们的组合。
42.正如背景技术中描述的,在多目标跟踪中容易发生目标间的相互遮挡和交叉,以及目标在视频中突然消失和重新出现的现象,例如视频图像中,作为目标的人或车辆会受到环境以及其他车辆和行人的遮挡,因此会导致目标丢失,从而出现漏检、误检以及错误的目标id切换等问题。
43.现有技术的多目标跟踪方法可以分为model
‑
free的方法和trackingby detection的方法,其中model
‑
free的方法核心思想是在视频图像的第一帧针对目标给定初始的检测框,在后续帧中跟踪这些框,这种方法是早期的算法,缺点是如果一些目标在后续的视频帧中才出现,那么这些目标并不会被跟踪。而基于tracking by detection(检测跟踪)方法又分为在线方法和离线方法,离线方法的缺点是无法实时的处理视频,而对于在线模式方法,所跟踪的目标轨迹是仅使用过去和现在的轨迹检测而不使用未来的轨迹来在线构建的,因此这种模式对于实时应用来说是很好的,但是它更容易受到目标周围环境的遮挡以及与其他目标轨迹交互的影响。
44.因此以下实施例给出的视频图像多目标跟踪方法、系统、存储介质及设备中,涉及的视频图像多目标跟踪方法是一种基于改进deeps ort的多目标跟踪算法,该算法主要分为三个部分,多目标检测,特征提取和目标跟踪。多目标检测部分选用centernet(中心网络)作为检测网络,与原算法中faster r
‑
cnn检测算法相比提高了检测精度。特征提取部分提出将rfbnet与deepsort算法中行人重识别网络rei d相结合来加强特征提取能力。目标跟踪部分,主要采用deepsort算法中的跟踪算法进行跟踪,由于多目标之间易出现目标间的遮挡,因此利用遮挡轨迹预测机制来减少误检和漏检。
45.实施例一:
46.如图1
‑
6所示,本实施例的目的是提供视频图像多目标跟踪方法,包括以下步骤:
47.基于目标检测模型获取视频图像中目标的中心点位置,依据中心点位置和目标的尺寸信息获得目标的位置信息;
48.利用提取到的目标中心点位置获取目标的预测位置,利用两个目标预测位置的重叠区域判断目标是否被遮挡;
49.基于特征提取网络获取视频图像中目标的外观信息,关联目标的外观信息和位置信息实现跟踪。
50.具体过程如下:
51.1、多目标跟踪的流程;
52.本实施例中多目标跟踪的流程图如图1所示,视频图像输入后,使用经过训练的目标检测模型centernet,并通过检测获取到目标的位置,改进后的reid身份特征提取器来获取深度外观特征,视频中的多目标检测结果作为deepsort跟踪器的实时输入,连接框形成多条轨迹,再利用卡尔曼滤波和匈牙利算法实现连接轨迹的任务,对于遮挡的目标采用轨迹预测机制。
53.2、centernet目标检测网络
54.目前,常见检测算法都是将图像上的目标由多个重叠检测矩形框框出,经过分类处理后选出得分最高的矩形框来确定目标的真实位置从而获取到所需的人、车辆或是物体;该方法大大增加了运算速度,但会花费更多的时间。
55.本实施例中,将目标当作一个中心点来处理,根据中心点回归出目标的位置属性,采取的centernet方法相比较于基于矩形框的检测器,算法更简单迅速,实现了速度和精确的最好权衡。
56.如图2所示,centernet(中心网络)的工作体系是输入图像后经过一个backbone(骨干网络),得到一个分辨率降低的特征图像后进行采样,然后通过中心点热力图、中心点偏移量来提取目标中心点的位置,通过目标的宽高尺寸再确定目标的大小,最终可以准确的得到目标的位置信息。
57.3、改进的新型行人重识别网络;
58.deepsort是利用提取到的表观特征,实现行人重识别的网络结构,该网络存在提取特征不够全面的问题,会导致跟踪的错误匹配和身份id切换,行人被识别后回一个身份id的方式标记,当行人受到环境(例如树木)、车辆、物体或其他行人的遮挡时,该网络结构会因为丢失目标而重新为识别到的行人生成一个身份id,这会导致多个身份id实质上可能是一位或多位行人,进而出现身份id的错误匹配和频繁切换。
59.因此本实施例在该网络结构上融合了rfb模块,rfb通过模拟rf的大小和偏心率之间的关系,增强了对目标外观的特征提取能力,在保持相同数量参数的情况下,进行更大的区域特征提取,保证了特征提取的最大化,从而有助于提高后期跟踪关联匹配的准确性。
60.rfb模块通过模拟人类视觉的感受野从而加强网络的特征提取能力,在结构上rfb借鉴了inception的思想,在inception的基础上加入了空洞卷积,从而有效增大了感受野,增强了网络的特征提取能力,便于后期追踪时目标间的数据关联,从而提高多目标追踪的准确性。
61.改进后的特征提取网络架构如图3所示,输入的图像首先经过rf b模块,增大特征提取感受野,然后进入两个3
×
3卷积和一个池化层来降低向量维度,避免过拟合,最后经过六个残差块,输出所提取到的外观特征。
62.rfb网络结构如图4所示,采用空洞卷积扩大感受野,有助于检测不同尺寸的目标
信息。该模块主要包括以下几个部分:三个1x1的卷积,用于减少运算量和进行跨通道的信息融合;三个3
×
3的空洞卷积层,扩大网络的感受野;然后三个不同尺寸的特征相加,达到融合不同特征的目的;最后将融合的特征送入1
×
1卷积,并将其输出与shortcut(为了解决深度网络中梯度发散的一种跨越方式)的输出相加在一起,通过激活函数,输出特征图像。
63.特征图像产生的是目标人物的身高,外形,体态,以及衣服的颜色等,特征图像产生的作用是提取目标的外观特征,后期进行同一目标前后数据关联时,辨别比对是否是同一个目标。
64.4、数据关联;
65.目标跟踪过程中数据关联是必不可少的关键步骤,deepsort跟踪算法利用运动信息和外观信息来进行数据关联,如下:
66.运动信息关联:使用检测框和跟踪框之间的马氏距离来描述运动关联程度。
[0067][0068]
公式(1)表示第j个检测结果和第i条轨迹之间的运动匹配度。其中,s
i
是卡尔曼滤波器当前时刻观测空间的协方差矩阵,y
i
是当前时刻的预测观测量,d
j
表示第j个检测的观测量。
[0069]
外观信息关联:视频图像由详细或摄像头获取,如果相机运动会使马氏距离度量方法失效,因此引入第二种关联方法,使用改进后的reid网络提取出单位范数的特征向量r,然后将第i个跟踪器与当前帧第j个检测结果的特征向量之间的最小余弦距离作为表观匹配度,公式如下:
[0070][0071]
用上述两种度量的线性加权作为最终度量:
[0072]
c
i,j
=λd(1)(i,j) (1
‑
λ)d(2)(i,j)
ꢀꢀ
(3)
[0073]
只有当c
i,j
位于两种度量阈值的交集内时,才认为实现了正确的关联。
[0074]
5、遮挡轨迹预测机制;
[0075]
利用遮挡轨迹预测方法来补偿漏检,以减轻目标之间遮挡导致的漏检对后续跟踪过程的影响。遮挡轨迹预测机制利用上述目标识别检测过程中的中心点位置,对可能存在遮挡的目标进行预测。当两个目标的预测位置有重叠部分时,对这两个目标标记,以便后续处理时能够快速找到该目标并判断其是否被遮挡。在检测和跟踪目标时,首先确定没有得到匹配的目标是否已经被标记,如果其被标记了,将该目标的预测位置就作为目标的真实位置。为了减小目标遮挡导致的预测误差,将标记目标位置的最大预测次数设置为两次。所提出的遮挡预测方法对目标间遮挡导致的漏检具有一定的提升,且在目标间遮挡情况下仍能跟踪目标。
[0076]
如图5(a)所示,当不使用该预测方法时,箭头所指的目标由于被其他目标遮挡而导致跟踪失败没有出现检测框。如图5(b)所示,在该遮挡预测方法下完成了目标跟踪重新获取了检测框(这里的检测框由目标中心点位置和目标宽高尺寸形成)。
[0077]
上述方法将视频图像中的被跟踪目标当做一个中心点处理,使获得的目标位置更加精确,并且算法过程更加简单迅速,有利于避免传统方式中目标因被遮挡而出现目标丢
失,目标身份id切换、漏检和误检的问题。
[0078]
识别目标的网络结构上融合了rfb模块,rfb通过模拟rf的大小和偏心率之间的关系,增强了对目标外观的特征提取能力,在保持相同数量参数的情况下,进行更大的图像区域特征提取,保证了特征提取的最大化,有助于后续跟踪关联匹配的准确性提升。
[0079]
利用提取到的目标中心点来对可能存在遮挡的目标进行预测,从而减轻目标之间因存在遮挡导致的漏检对后续跟踪过程的影响。
[0080]
6、验证;
[0081]
对yolov3目标检测算法、ssd目标检测算法、faster r
‑
cnn目标检测算法和本实施例的centernet目标检测算法对比实验。
[0082]
在目标检测评价中,利用voc2007和voc2012数据集进行训练。本实施例使用voc2007trainval数据集和voc2012trainval数据集,共16551张图片进行训练。常用的评价指标为map,表示平均精度均值,本实施例采用map、模型大小及单张图片检测时间指标对目标检测模型进行评估,评价结果如表1所示,可以看出本实施例所采用的检测算法更准确。
[0083]
表1目标检测算法性能对比结果
[0084][0085]
在mot基准数据库提供的序列集上评估跟踪性能,以mot chall enge标准对多目标跟踪算法进行评估。为了验证算法的有效性,选取现有的2种经典方法进行对比,还采取了2种类似于本实施例总体框架的融合算法进行对比,yolov3
‑
deepsort和centernet
‑
deepsort都是在deepsort基础上更换了检测算法。
[0086]
实验评价指标结果如表2所示,实验结果表明本实施例的算法更具有效性。
[0087]
表2多目标跟踪算法评价指标对比
[0088] mota
↑
motp
↑
mt
↑
ml
↓
id
↓
fp
↓
fn
↓
runtime
↑
sort59.879.625.4%22.7%142386986324560hzdeepsort61.479.132.8%18.2%781128525666820hzyolov3
‑
deepsort62.379.030.6%20.8%693120585591112hzcenternet
‑
deepsort62.679.229.8%20.4%626119675552218hzours64.879.533.6%18.1%525103145327015hz
[0089]
本实施例实际应用时,图像中目标框上的数字代表每个目标(人)被分配的id编号,实际应用中不同目标具有不同颜色的目标框。
[0090]
如图6(a)所示,mot16
‑
03为静态相机拍摄,其场景复杂,光线相对较暗,且人员流动量大,跟踪效果相对稳定。mot16
‑
06中标记的目标在视频中消失后又重新出现,该情况下仍能被重新识别。mot16
‑
07中被标记的目标再被树枝遮挡后,本实施例的算法仍能对其的
位置进行预测,遮挡预测后的目标被成功检测而且得到了跟踪,本实施例的算法很好的处理了物体遮挡的问题。
[0091]
如图6(b)所示,mot16
‑
08中标记的目标逐渐被另一标记的目标遮挡,本实施例的算法中遮挡轨迹预测机制对该目标进行轨迹预测,在遮挡完成后,目标被继续跟踪且该目标没有发生id切换。mo t16
‑
12、mot16
‑
14是移动相机拍摄,视频中目标被频繁遮挡,但该算法追踪结果较稳定。实验证明,本实施例的方法在一定程度上解决了跟踪中存在的目标遮挡问题,降低了目标id切换频率。
[0092]
实施例二:
[0093]
本实施例的目的是提供实现实施例一的系统,包括:
[0094]
目标位置检测模块,被配置为:基于目标检测模型获取视频图像中目标的中心点位置,依据中心点位置和目标的尺寸信息获得目标的位置信息;
[0095]
遮挡轨迹预测模块,被配置为:利用提取到的目标中心点位置获取目标的预测位置,利用两个目标预测位置的重叠区域判断目标是否被遮挡;
[0096]
关联追踪模块,被配置为:基于特征提取网络获取视频图像中目标的外观信息,关联目标的外观信息和位置信息实现跟踪。
[0097]
多目标检测部分选用centernet(中心网络)作为检测网络,与原算法中faster r
‑
cnn检测算法相比提高了检测精度。特征提取部分提出将rfbnet与deepsort算法中行人重识别网络reid相结合来加强特征提取能力。目标跟踪部分,主要采用deepsort算法中的跟踪算法进行跟踪,由于多目标之间易出现目标间的遮挡,利用遮挡轨迹预测机制来减少误检和漏检。
[0098]
实施例三:
[0099]
本实施例提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现如上述实施例一所述的视频图像多目标跟踪方法中的步骤。
[0100]
多目标检测部分选用centernet(中心网络)作为检测网络,与原算法中faster r
‑
cnn检测算法相比提高了检测精度。特征提取部分提出将rfbnet与deepsort算法中行人重识别网络reid相结合来加强特征提取能力。目标跟踪部分,主要采用deepsort算法中的跟踪算法进行跟踪,由于多目标之间易出现目标间的遮挡,利用遮挡轨迹预测机制来减少误检和漏检。
[0101]
实施例四:
[0102]
本实施例提供了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上述实施例一所述的视频图像多目标跟踪方法中的步骤。
[0103]
多目标检测部分选用centernet(中心网络)作为检测网络,与原算法中faster r
‑
cnn检测算法相比提高了检测精度。特征提取部分提出将rfbnet与deepsort算法中行人重识别网络reid相结合来加强特征提取能力。目标跟踪部分,主要采用deepsort算法中的跟踪算法进行跟踪,由于多目标之间易出现目标间的遮挡,利用遮挡轨迹预测机制来减少误检和漏检。
[0104]
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修
改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。