1.本发明涉及一种凝聚聚类无监督算法的流体类型识别方法,属于油气勘探开采领域。
背景技术:
2.流体识别、划分流体类型是油气开采领域中一项重要的基础工作,为油气开采提供着最为直接有利的证据,目前随着各项分析化验技术的不断进步,新型实验设备的不断出现,带来了众多表征流体特征的目标参数,如何利用已有的目标参数数据划分流体类型是油气开采领域所关注的问题,实际工作中,对储层目标井所在区域的流体划分有很多类型,但是最有意义的是判断此区域是以油气为主的层位还是以水层为主的层位,据此本文采取多次筛选对油气层和水层进行划分,初次筛选过程以目标参数特征自动分类划分目标区域出油气层和水层,复式筛选过程以剩余数据和数据的分布情况为前提,以专家经验知识为基础,以实际开采经济效益、开采难度、开采安全性为底线,细致将模糊层段的数据样本点划分油气层和水层。
3.现有利用化验资料、实验资料、测井资料、地震数据资料,对储层目标井所在区域的目的层段进行分析评价。流体类型的划分通过不同的目标参数组合计算来划分的,例如,申请号cn201811573972.4提供一种流体识别方法及装置,该方法通过获取目标参数,包括孔隙度、岩石密度、地层水矿化度、岩石氯化盐含量和含水饱和度阈值等五项数据,给定指定目标区域参数值,完全靠计算得到水层和油气层分类结果。申请号cn201910653044.7提供一种基于随机森林算法的智能化地震流体识别方法,该方法首先基于测井数据进行大量的机器学习实践,通过建立前期大量的流体类型
‑
弹性属性并且带有真实标签的样本数据,利用样本数据训练出一个有泛化性能的随机森林分类器,进而实现预测流体类型的空间部分。该方法的实现依赖带有大量标签的样本数据,这与实际情况可能会有不符,收集不到如此体量的数据样本,进一步可能会导致随机森林建立的分类器的效果达不到预期的效果,同时随机森林是否需要进行剪枝,按照怎么样的方式剪枝会不会提高预测准确率。
4.现有技术中,纯理论计算法,即选取满足条件的数据进行筛选识别,存在以下缺点:
5.(1)计算效率低下。
6.(2)忽略那些目标井所在区域模糊层位的数据点位,直接全部划分为水层,划分不客观,考虑不全面。
7.现有技术中,还有随机森林算法,对已有标签的大量样本点进行训练,建立一个具有泛化能力的随机森林分类器,然后实现对未知标签的数据样本点所在层位进行识别。随机森林算法存在的缺点:
8.(1)前期需要建立大量数据的标签,工作量巨大,耗费较多的人力资源,而且所需成本比较高。
9.(2)在已知区域建立的分类器,换个区域,实用性可能不会那么明显。
技术实现要素:
10.本发明的目的是提供一种无监督凝聚聚类学习算法的流体识别方法,用以解决现有流体识别较为复杂、计算效率低下、识别准确度不高,全靠人工识别的问题。通过无监督凝聚聚类学习算法完成流体的逐级判别,使得分类建立标准更加客观、真实、快速,同时对模糊层段采取复式筛选,结合实际情况,专家经验知识,开采安全系数等,使得对模糊层段的判别也具有强有力的说服力和极高的可信度,理论与实际的穿插,使得该方法的应用效果是可观的。
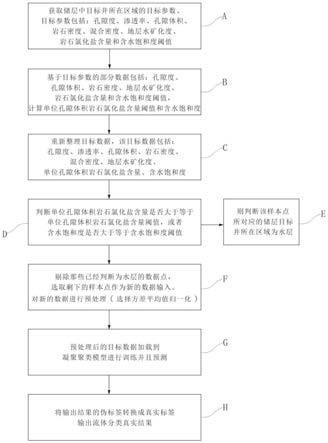
11.为了实现上述目的,本发明提供一种凝聚聚类无监督算法的流体类型识别方法,基本思想为算法假设每个点都是自己的簇,根据空间中的欧式距离相对大小,然后合并两个距离最近的簇,直到满足某种停止准则为止,这里的停止条件即是为聚类的个数。
12.具体的:
13.一种凝聚聚类无监督算法的流体类型识别方法,包括以下步骤:
14.步骤a,获取储层中目标井所在区域的目标参数,目标参数包括:孔隙度、渗透率、孔隙体积、岩石密度、混合密度、地层水矿化度、岩石氯化盐含量和含水饱和度阈值。所述的混合密度为油气水和岩石的混合密度;
15.步骤b,基于目标参数的部分数据包括:孔隙度、孔隙体积、岩石密度、地层水矿化度、岩石氯化盐含量和含水饱和度阈值,计算单位孔隙体积岩石氯化盐含量阈值和含水饱和度。
16.计算单位孔隙体积岩石氯化盐含量阈值的公式为:
[0017][0018]
其中,sal
w
为地层水矿化度,λ为孔隙度,s
wt
为含水饱和度阈值,ρ
r
为岩石密度,ν
k
为孔隙体积,rcl
t
为单位孔隙体积岩石氯化盐含量阈值;
[0019]
计算含水饱和度的公式为:
[0020][0021]
其中,sal
w
为地层水矿化度,λ为孔隙度,s
w
为含水饱和度,ρ
r
为岩石密度,ν
k
为孔隙体积,rcl为单位孔隙体积岩石氯化盐含量;
[0022]
步骤c,重新整理目标数据,该目标数据由孔隙度、渗透率、孔隙体积、岩石密度、混合密度、地层水矿化度、单位孔隙体积岩石氯化盐含量、含水饱和度组成;
[0023]
步骤d,判断单位孔隙体积岩石氯化盐含量是否大于单位孔隙体积岩石氯化盐含量阈值,或者含水饱和度是否大于含水饱和度阈值;
[0024]
步骤e,在步骤d的基础上,若单位孔隙体积岩石氯化盐含量大于等于单位孔隙体积岩石氯化盐含量阈值,或者含水饱和度大于等于含水饱和度阈值,则判断该样本点所对应的储层目标井所在区域为水层;
[0025]
若单位孔隙体积岩石氯化盐含量小于单位孔隙体积岩石氯化盐含量阈值,或者含水饱和度小于含水饱和度阈值,则判断该样本点所对应的储层目标井所在区域不为水层,则到步骤f;
[0026]
步骤f,剔除那些已经判断为水层的数据点,选取剩下的样本点作为新的数据输
入。对新的数据进行预处理(选择方差平均值归一化);
[0027]
步骤g,将预处理后的目标数据加载到凝聚聚类模型进行训练并且预测,并设置分类个数为2;
[0028]
步骤h,通过地质工作者的经验和专家知识,只需分析一类数据样本点,将输出结果的伪标签转换成真实标签输出流体分类真实结果。
[0029]
与现在技术相比,本发明对提到的模糊层段的数据样本点进行了详细地划分,综合考虑模糊层段数据本身不确定性,模糊层数据特征,结合专家知识,考虑更多因素包括开采难度、生产效益。另外本发明需要的全是盲目标值也就是无标签的数据样本,依据数据内部特征为驱动,划归出的流体类型,使得划分效果更加符合实际需求、更加客观真实。
[0030]
本发明技术方案带来的有益效果:
[0031]
解决了流体识别问题以及流体识别效率的难题,通过对储层目标井位所在区域采集的数据点,利用无监督学习算法凝聚聚类对采样的数据点进行逐级筛选判断、逐级细分,结合专家知识和经验以及实际效益直至对模糊层样本点进行判断划分,得到最终完整的划分结果,提高了流体识别效率,减少投入成本,为石油开采提供有利的地质依据和理论支撑。
附图说明
[0032]
图1为本发明实施例中凝聚聚类流体识别算法的流程图;
[0033]
图2为本发明实施例中凝聚聚类流体识别算法的效果图;
[0034]
图3为本发明实施例凝聚聚类流体识别算法在x地区应用结果示例图。
具体实施方式
[0035]
结合实施例说明本发明的具体技术方案。
[0036]
图1所示,本发明实施例的无监督凝聚聚类流体识别算法主要包括如下步骤:
[0037]
步骤a,获取储层中目标井所在区域的目标参数,目标参数包括:孔隙度、渗透率、孔隙体积、岩石密度、混合密度(油气水和岩石)、地层水矿化度、岩石氯化盐含量和含水饱和度阈值。
[0038]
步骤b,基于目标参数的部分数据包括:孔隙度、孔隙体积、岩石密度、地层水矿化度、岩石氯化盐含量和含水饱和度阈值,计算单位孔隙体积岩石氯化盐含量阈值和含水饱和度。
[0039]
计算单位孔隙体积岩石氯化盐含量阈值的公式为:
[0040][0041]
其中,sal
w
为地层水矿化度,λ为孔隙度,s
wt
为含水饱和度阈值,ρ
r
为岩石密度,ν
k
为孔隙体积,rcl
t
为单位孔隙体积岩石氯化盐含量阈值。
[0042]
计算含水饱和度的公式为:
[0043]
其中,sal
w
为地层水矿化度,λ为孔隙度,s
w
为含水饱和度,ρ
r
为岩石密度,ν
k
为孔隙体积,rcl为单位孔隙体积岩石氯化盐含量。
[0044]
上述两个公式均是由以下公式推导得出:
[0045][0046][0047][0048]
其中,λ
w
为含水孔隙度,ν
k
为孔隙体积,ν
r
为岩石体积,ν
w
为岩石中水的体积,s
w
为含水饱和度,ν
w1
为单位质量岩石中水的体积,ρ
r
为岩石密度,rcl为单位孔隙体积岩石氯化盐含量,m为岩石质量。本文计算岩石氯化盐含量采取的是计算单位孔隙体积岩石氯化盐含量,这是由于这样量化出来的岩石氯化盐含量基本上不受岩石孔隙大小、形状、岩石渗透性以及岩石骨架矿物性质的影响,只与孔隙中的流体性质以及流体饱和度有关。
[0049]
步骤c,重新整理目标数据,该目标数据由孔隙度、渗透率、孔隙体积、岩石密度、混合密度、地层水矿化度、单位孔隙体积岩石氯化盐含量、含水饱和度组成。
[0050]
步骤d,判断单位孔隙体积岩石氯化盐含量是否大于单位孔隙体积岩石氯化盐含量阈值,或者含水饱和度是否大于含水饱和度阈值。
[0051]
步骤e,在步骤d的基础上,若单位孔隙体积岩石氯化盐含量大于等于单位孔隙体积岩石氯化盐含量阈值,或者含水饱和度大于等于含水饱和度阈值,则判断该样本点所对应的储层目标井所在区域为水层。
[0052]
若单位孔隙体积岩石氯化盐含量小于单位孔隙体积岩石氯化盐含量阈值,或者含水饱和度小于含水饱和度阈值,则判断该样本点所对应的储层目标井所在区域不为水层,则到步骤f。
[0053]
步骤f,剔除那些已经判断为水层的数据点,选取剩下的样本点作为新的数据输入。对新的数据进行预处理,选择方差平均值归一化。
[0054]
步骤g,将预处理后的目标数据加载到凝聚聚类模型进行训练并且预测,并设置分类个数为2。
[0055]
步骤h,通过地质工作者的经验和专家知识,只需分析一类数据样本点,将输出结果的伪标签转换成真实标签输出流体分类真实结果。
[0056]
如图2所示,本发明实施例的凝聚聚类流体识别算法的效果图。
[0057]
将高维数据样本点以二维平面图形形式进行展示,选取单位孔隙体积岩石氯化盐含量和含水饱和度两个显著特征作为图形展示的横向和纵向。
[0058]
水层:通过第一次判断筛选,单位孔隙体积岩石氯化盐含量大于等于单位孔隙体积岩石氯化盐含量阈值,或者含水饱和度大于等于含水饱和度阈值,直接将储层目标井所在区域划归为水层。
[0059]
模糊层和油气层:一次筛选没有判断得出流体类型,通过二次判断以数据特征为驱动,以凝聚聚类算法为基础,剔除第一次已经判断过的数据样本点,对剩余数据进行再次筛选分类,划分出了油气层和模糊层。
[0060]
模糊层:模糊层为输出的伪标签,实际工作中模糊层的数据样本点的所在区域具
有很大的不确定性,此时需要地质工作者的经验和专家知识,结合实际开采效益,开采难度以及其他油气勘探开发影响因素,分析模糊层数据样本点,把这些模糊层的区域划归为水层或者是油气层,最终将输出结果的伪标签转换成真实标签,真实标签即是流体真实分类类别。
[0061]
图3为本发明实施例凝聚聚类流体识别算法在x地区应用结果示例图;本发明实施例应用x地区y地层,得到x地区y地层储层流体识别结果示例图,得到水层,油气层以及模糊层,模糊层需要进一步根据实际工作需要,实际效益,开采难度决定将模糊层数据样本点储层目标井所在区域是否划分为油气层。无监督凝聚聚类流体识别算法在x地区y地层应用结果与实际结果非常吻合。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。