1.本发明属于水中目标识别与人工智能技术领域,主要是一种基于多深度学习模型联合判决体制的水中目标识别方法。
背景技术:
2.水中目标辐射噪声识别主要利用声纳接收的目标辐射噪声以及其它传感器信息判别目标类型,并提供目标特征信息,为声纳员综合决策提供依据。随着精确制导武器的大量应用,对目标识别能力的依赖性愈发突出。同时,声纳检测技术的发展,使得发现的目标数量大幅度增加,也对目标识别提出了更多考验。
3.传统声纳目标识别主要通过信号处理手段提取具有可分性的物理特征来实现分类。由于海洋环境和水声信道十分复杂,目标固有可分性特征提取难度大,识别泛化能力差。
4.近年来,深度学习技术快速发展,目前已经在语音、图像等领域得到了广泛应用。针对水声目标识别,也有不少学者开展了深度学习应用方法研究,但一般所用模型较为单一。鉴于水声目标辐射噪声的复杂性,其特征可能在不同维度具备独立的特性,为充分利用不同维度上的特征凸显性,本发明提出了基于多深度学习模型融合判决的水中目标识别方法,通过对多维多域别目标数据进行智能化处理与联合判决,充分利用了目标噪声在多维度上的特性,有助于提升水中目标辐射噪声识别的宽容性。
技术实现要素:
5.本发明的目的在于克服现有技术存在的不足,而提供一种基于多深度学习模型联合判决体制的水中目标识别方法。
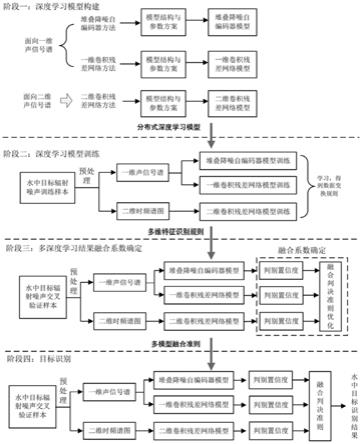
6.本发明的目的是通过如下技术方案来完成的。本发明提出一种基于多深度学习模型联合判决体制的水中目标识别方法,首先针对水中目标辐射噪声数据特点,从频域和时频域出发,生成一维声信号谱和二维时频谱图作为深度学习处理对象,其次针对一维声信号谱,构建堆叠降噪自编码器和一维卷积神经网络模型进行处理,输出各类目标识别置信度,针对二维声信号时频谱图,构建二维卷积神经网络模型进行处理,输出置信度;接着对多模型置信度结果进行加权融合判决,基于遗传算法对各模型输出结果的加权系数进行优化。最后基于上述模型和准则实现未知目标噪声数据识别。
7.本发明的有益效果为:本发明使用多种深度学习算法从不同域别对高维水声目标噪声进行特征提取与融合识别,与传统基于物理机理的特征提取与识别方法相比,具有更强的非线性数据处理能力,而与基于单一深度学习模型的识别方法相比,能够从多维度挖掘目标可分性特征,能够更有效识别水中目标。
附图说明
8.图1所示为信号处理流程图。
9.图2所示为堆叠降噪自编码器建模示意图。
10.图3所示为二维卷积神经网络模型构建时所用的2种基本模块示意图。
11.图4所示为一维卷积残差网络模型构建时所用的2种基本模块示意图。
具体实施方式
12.下面将结合附图对本发明做详细的介绍:
13.本发明提出一种基于多深度学习模型联合判决体制的水中目标识别方法,首先针对水中目标辐射噪声数据特点,从频域和时频域出发,生成一维声信号谱和二维时频谱图作为深度学习处理对象,其次针对一维声信号谱,构建堆叠降噪自编码器和一维卷积神经网络模型进行处理,输出各类目标识别置信度,针对二维声信号时频谱图,构建二维卷积神经网络模型进行处理,输出置信度;接着对多模型置信度结果进行加权融合判决,基于遗传算法对各模型输出结果的加权系数进行优化。最后基于上述模型和准则实现未知目标噪声数据识别。该方法基于深度学习对多维度数值特征进行深度挖掘,实现了不同维度可分性数值特征的优势互补,有助于提高目标识别稳健性,是人工智能算法在水声信号处理领域应用的创新方法。
14.具体实施方式如下:
15.(1)基于tensorflow框架构建用于目标特征提取与识别的多深度学习模型,基本过程如下:
16.(1.1)构建堆叠降噪自编码器模型,具体构建方式如下。
17.(1.1.1)构建隐藏计算层1,节点数量为500,输入数据加入10%比例的随机噪声,激活函数设置为relu函数。
18.(1.1.2)构建隐藏计算层2,节点数量为200,激活函数设置为relu函数。
19.(1.1.3)基于softmax函数构建输出分类器。
20.(1.2)构建二维卷积残差网络模型,具体构建方式如下。
21.(1.2.1)构建2个基本模块,具体构建方式如下。
22.(1.2.1.1)构建基本模块1,在数据输入层之后添加3个并行分支。分支1为直接分支,不添加任何操作。分支2包括4个卷积层,卷积层1参数为(1
×
1,x,1),即卷积核尺寸为1
×
1,卷积核数量可根据需求进行设定,卷积步长为1,表示方法下同。卷积层2~4的参数依次为(1
×
3,x,1),(3
×
1,2x,1)和(1
×
1,nx,1或2)。分支2包括3个卷积层,各卷积层参数依次为(1
×
1,x,1),(3
×
3,x,1)和(1
×
1,nx,1或2)。在3个并行分支之后添加网络整合层,实现卷积特征组合。
23.(1.2.1.2)构建基本模块2,在数据输入层之后添加3个并行分支。分支1为直接分支,不添加任何操作。分支2包括4个卷积层,卷积层参数依次为(1
×
1,x,1),(1
×
5,x,1),(5
×
1,2x,1)和(1
×
1,nx,1或2)。分支3包括3个卷积层,各卷积层参数依次为(1
×
1,x,1),(5
×
5,x,1)和(1
×
1,nx,1或2)。在3个并行分支之后添加网络整合层,输出基本模块2的特征提取结果。
24.(1.2.2)构建整个二维卷积神经特征提取网络,其具体构建方式如下。添加数据输入层,输入数据尺寸为256
×
256
×
1;添加卷积层,参数为(7
×
7,32,2);添加模块2,参数为(3,32,2,1),各数字依次为模块数量、x值、n值和最后卷积层步长值,下同;添加模块2,参数
为(1,64,2,2);添加卷积层,参数为(3
×
3,128,2);添加模块1,参数为(5,128,2,1);添加模块1,参数为(2,128,2,2);添加3个卷积层,参数依次为(3
×
3,1024,1)、(3
×
3,1024,2)和(1
×
1,128,1);添加网络展开层;添加dropout层。
25.(1.2.3)添加softmax分类器。
26.(1.3)构建一维卷积残差网络模型,具体构建方式如下。
27.(1.3.1)构建2个基本模块,具体构建方式如下。
28.(1.3.1.1)构建基本模块1,在数据输入层之后添加2个并行分支。分支1为直接分支,不添加任何操作。分支2包括3个卷积层,各卷积层参数依次为(1
×
1,x,1),(3
×
1,2x,1)和(1
×
1,nx,1或2)。在2个并行分支之后添加网络整合层。
29.(1.3.1.2)构建基本模块2,在数据输入层之后添加2个并行分支。分支1为直接分支,不添加任何操作。分支2包括3个卷积层,各卷积层参数依次为(1
×
1,x,1),(5
×
1,2x,1)和(1
×
1,nx,1或2)。在2个并行分支之后添加网络整合层。
30.(1.3.2)构建整个一维卷积神经特征提取网络,其具体构建方式如下。添加数据输入层,输入数据尺寸为3145
×1×
1;添加卷积层,参数为(7
×
1,32,2);添加模块2,参数为(3,32,2,1);添加模块2,参数为(2,64,2,2);添加卷积层,参数为(3
×
1,256,2);添加模块1,参数为(5,256,2,1);添加模块1,参数为(2,512,2,2);添加3个卷积层,参数依次为(3
×
1,2048,2)、(3
×
1,2048,2)和(1
×
1,128,2);添加网络展开层;添加dropout层。
31.(1.3.3)添加softmax分类器。
32.(2)对建立的多深度学习模型进行训练,基本过程如下。
33.(2.1)对堆叠降噪自编码器模型进行训练,基本过程如下。
34.(2.1.1)对用于训练的水中目标辐射噪声信号库中的无标签样本集和带标签样本集进行预处理,得到无标签/带标签声信号谱数据集x
n
和x
l
。
35.(2.1.2)设定训练参数,包括学习率、优化器等,损失函数设置为最小均方误差函数。
36.(2.1.3)采用无标签数据集x
n
对降噪自编码器进行预训练,具体过程如下。
37.(2.1.3.1)对输入样本添加20%比例的随机噪声。
38.(2.1.3.2)通过隐层1对含噪输入样本进行映射转换,得到隐层1特征。
39.(2.1.3.3)将隐层1特征逆向映射回原维度空间,得到重构向量。
40.(2.1.3.4)基于梯度下降算法最小化重构向量与原始不含噪样本之间的误差。
41.(2.1.3.5)按相同方法对隐层2进行预训练。
42.(2.1.4)采用带标签数据集x
l
对降噪自编码器进行有监督训练,具体过程如下。
43.(2.1.4.1)针对输入样本,通过前向计算得到最后分类结果。
44.(2.1.4.2)基于梯度下降算法最小化分类结果与对应样本标签之间的误差。
45.(2.2)对二维卷积神经网络模型进行训练,基本过程如下。
46.(2.2.1)对用于训练的水中目标辐射噪声信号库中的带标签样本集进行预处理,得到声信号时频谱图数据集s
l
。
47.(2.2.2)设定训练参数,包括学习率、优化器等,损失函数设置为交叉熵函数。
48.(2.2.3)对用于训练的水中目标辐射噪声信号库中的带标签样本集进行预处理,得到声信号时频谱图数据集s
l
。
49.(2.2.4)对二维卷积神经网络模型进行有监督训练,具体过程如下。
50.(2.2.4.1)针对输入样本,通过前向计算得到最后分类结果。
51.(2.2.4.2)基于梯度下降算法最小化分类结果与对应样本标签之间的误差。
52.(2.3)对一维卷积神经网络模型进行训练,基本过程如下。
53.(2.2.1)对用于训练的水中目标辐射噪声信号库中的带标签样本集进行预处理,得到声信号谱数据集s
l
。
54.(2.2.2)设定训练参数,包括学习率、优化器等,损失函数设置为交叉熵函数。
55.(2.2.3)对用于训练的水中目标辐射噪声信号库中的带标签样本集进行预处理,得到声信号时频谱图数据集x
l
。
56.(2.2.4)对一维卷积神经网络模型进行有监督训练,具体过程如下。
57.(2.2.4.1)针对输入样本,通过前向计算得到最后分类结果。
58.(2.2.4.2)基于梯度下降算法最小化分类结果与对应样本标签之间的误差。
59.(3)计算多深度学习模型融合判决系数,基本过程如下。
60.(3.1)对用于交叉验证的水中目标辐射噪声信号库中的带标签样本集进行预处理,基于相同长度原始数据生成一维声信号谱样本集和二维时频谱图样本集。
61.(3.2)基于堆叠降噪自编码器模型对一维声信号谱样本集中的样本数据按次序进行处理,输出置信度,得到集合c
encoder
(c
encoder,1
,c
encoder,2
,...,c
encoder,n
),其中c
encoder,n
表示第n类结果的置信度,下同。
62.(3.3)基于二维卷积神经网络模型对声信号时频谱图样本集中的样本数据按次序进行处理,输出置信度,得到集合c
resnet2d
(c
resnet2d,1
,c
resnet2d,2
,...,c
resnet2d,n
),其中c
resnet2d,n
表示第n类结果的置信度。
63.(3.3)基于二维卷积神经网络模型对声信号时频谱图样本集中的样本数据按次序进行处理,输出置信度,得到集合c
resnet2d
(c
resnet2d,1
,c
resnet2d,2
,...,c
resnet2d,n
)。
64.(3.4)基于一维卷积神经网络模型对声信号时频谱图样本集中的样本数据按次序进行处理,输出置信度,得到集合c
resnet1d
(c
resnet1d,1
,c
resnet1d,2
,...,c
resnet1d,n
)。
65.(3.5)构建融合判决置信度计算函数,针对某数据,多模型综合置信度计算结果表示为c
class
={c
class,1
,c
class,2
,...,c
class,n
},具体如下所示。
[0066][0067]
其中,α
n
,β
n
,γ
n
分别为堆叠降噪自编码器模型、二维卷积神经网络模型和一维卷积神经网络模型对第n类目标分类置信度的加权系数。
[0068]
(3.6)针对c
class
,取综合置信度最大值为识别类别。
[0069]
(3.7)按上述方法依次计算交叉验证数据集各样本的识别结果,得到目标识别结果交叉验证集r
class
={r
class,1
,r
class,2
,...,r
class,n
},其中r
class,n
表示第n个样本数据对应识别结果。
[0070]
(3.8)基于遗传算法对加权系数进行优化,设置目标函数为max{r
class
},决策变量
为所有决策变量上界和下界均分别设置为1和0,种群规模为100,最大进化代数为500,重组概率为0.7。
[0071]
(3.9)对建立的遗传算法模型进行迭代寻优,得到最佳加权系统组合。
[0072]
(4)对未知水中目标辐射噪声数据进行识别,基本过程如下:
[0073]
(4.1)对水中目标辐射噪声数据进行预处理,生成声信号谱和时频谱图样本。
[0074]
(4.2)基于堆叠降噪自编码器模型和一维卷积神经网络模型对声信号谱进行处理,基于二维卷积神经网络对声信号时频谱图进行处理,生成各深度学习对各类目标的置信度列表。
[0075]
(4.3)通过对置信度列表进行加权融合判决,得到最后识别结果。
[0076]
图1所示为信号处理流程图,其中包括深度学习模型构建、深度学习模型训练、多深度学习结果融合系数确定和目标识别四个阶段,在“具体实现方法”中详细描述了整个信号处理过程。
[0077]
图2所示为堆叠降噪自编码器建模示意图,共包含两个隐藏计算机,顶层添加分类器,输出识别结果。
[0078]
图3所示为本发明中二维卷积神经网络模型构建时所用的2种基本模块,两个基本模块均包含了多个并行分支结构,通过配置不同的卷积操作过程参数,能够增强对不同尺度的适应性,从而提高对数据动态的洞察能力和精细特征的捕捉时机,最后基于网络整合层将这些卷积特征在通道数量维度进行集成,输出该基本模块的卷积特征。各卷积层使用的激活函数均设置为relu函数。
[0079]
表1所示为二维卷积神经模型构建方案,包含了多个卷积层、池化层和各基本模块,输入原始时频图像尺寸为256
×
256
×
1,在最后一个输出层之后添加开展整合层,将卷积操作输出的4
×4×
128个特征逐个首尾连接,变为长度为1024的一维特征序列,最后添加softmax分类器,输出分类置信度。
[0080]
图4所示为本发明中一维卷积残差网络模型构建时所用的2种基本模块,两个基本模块均包含两个并行分支结构,其中一个为直连分支,另一个为卷积运算分支,通过3
×
1或5
×
1尺寸的一维卷积算子实现特征提取,最后基于网络整合层在通道数量维度集成提取的卷积特征。各卷积层使用的激活函数同样均设置为relu函数。
[0081]
表2所示为一维卷积残差模型构建方案,包含了多个卷积层、池化层和各基本模块,输入原始时频图像尺寸为3145
×1×
1,在最后一个输出层之后添加开展整合层,将卷积操作输出的4
×4×
128个特征逐个首尾连接,变为长度为1024的一维特征序列,最后添加softmax分类器,输出分类置信度。
[0082]
将各深度学习模型输出类型判别置信度进行加权融合,对各模型加权系数进行优化,该问题为给定约束条件下的最优化问题,目标函数为最大化综合识别正确率,约束为各加权系统的取值区间。遗传算法是一种通过模拟自然进化过程搜索最优解的方法,十分适合应用于该问题,因此,基于遗传算法实现加权系数优化。最后,输出各模型加权判决结果。
[0083]
针对两类水中目标噪声识别,基于以上三种深度学习方法进行融合识别,结果如
表3所示,可以看到,三种深度学习方法均可以有效分辨两类目标,而融合识别模型的总体识别效果最好,验证了上述方法的有效性。
[0084]
表1
[0085][0086]
表2
[0087][0088]
表3
[0089][0090]
可以理解的是,对本领域技术人员来说,对本发明的技术方案及发明构思加以等同替换或改变都应属于本发明所附的权利要求的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。