1.本发明涉及处理多语言的语音的装置,特别涉及识别所输入的语音信号为哪种语言的语言识别装置以及使用该语言识别装置的语音处理装置。该申请主张基于2019年3月28日申请的日本技术第2019
‑
062346号的优先权,并通过参照将前述日本技术所记载的全部记载内容援引于此。
背景技术:
2.最近,对多种语言的语音进行语音识别、自动翻译以及语音合成,帮助彼此的使用语言不同的人之间的对话的装置正在普及。期待能够使用的语言的数量也变多,若使用该装置,则使得使用各种各样的语言的人能够相互交流。
3.为了高精度地进行这样的多语言的语音识别,需要知道语音信号表示的语音是哪种语言。因此,通常预先指定所使用的语言来启动语音识别。
4.但是,在使用语言相互不同,而且不知道对方的语言是什么的两个人想要利用一台多语言语音处理装置进行对话的情况下,存在难以指定所使用的语言的问题。如果是该装置的持有者,则由于基本上进行了使用语言(例如日语)的设定,因此没有问题,但在假设对方完全不知道日语的情况下,该语言的设定并不容易。由于装置的显示等基本上是日语,因此即使对方看到也无法理解操作方法。装置的持有者即使知道装置的操作,由于不知道对方的语言,因此也不知道进行怎样的设定好。
5.这样,在使用进行多语言的语音处理的装置的情况下,存在难以顺畅地开始对话的问题。
6.在后述的专利文献1中提出了用于解决这样的问题的一个方案。在专利文献1所记载的技术中,对所输入的语音信号进行多种语言下的语音识别。作为语音识别的结果,得到语音识别的可靠度。在专利文献1所公开的技术中,采用该语音识别的可靠度最高的语言作为语音信号所表示的语音的语言。
7.在先技术文献
8.专利文献
9.专利文献1:日本特开2019
‑
23690
技术实现要素:
10.发明要解决的课题
11.但是,在专利文献1所记载的技术中,存在如下的问题,即,由于进行针对全部语音的语音识别,因此计算量大,若依次进行则花费时间。假设并行地执行它们,则由于消耗计算资源,因此例如在服务器中处理多个请求那样的情况下,若请求重叠,则服务器中的处理量过大,存在语音识别变慢的问题。
12.因此,在通过以往的多语言的语音处理装置进行语言识别的情况下,存在在开始实际的语音处理之前所需的时间变长的问题。特别是在被来自外国的旅游者问到什么的情
况下,期望在短时间内开始用于对话的语音处理并尽可能快速得到其结果。
13.因此,本发明的目的在于,提供一种即使在不知道语音信号所表示的语音的语言的情况下,也能够快速得到语音处理的结果那样的语言识别装置以及语音处理装置。
14.用于解决课题的手段
15.本发明的第1方式所涉及的语言识别装置是识别所输入的语音信号是否为第1多个语言中的任意一个语言的语音的信号的语言识别装置,包含:分数输出单元,其用于响应于语音信号的输入,针对第1多个语言的每一个,输出表示语音信号所表示的语音为该语言的语音的分数;选择单元,其用于从由分数输出单元输出的分数中,选择从第1多个语言中预先指定的比第1多个少的第2多个语言的分数;标准化单元,其用于对由选择单元选择的分数的每一个,以第2多个语言的分数的合计为基准进行标准化;判定单元,其判定由标准化单元标准化后的分数的最大值是否为阈值以上;以及语言确定单元,其响应于基于判定单元的判定是否为肯定,选择性地进行将与分数的最大值对应的语言确定为语音信号所表示的语音的语言的处理和舍弃分数选择单元的输出的处理。
16.优选地,分数输出单元包含:神经网络,其被预先训练为响应于根据语音信号计算的声音特征量的时间序列,输出语音信号表示的语音的语言的分数。
17.更优选地,神经网络输出的分数均相对于该分数的合计而被标准化。
18.本发明的第2方式所涉及的计算机程序使计算机作为上述的任一装置的各单元而发挥功能。
19.本发明的第3方式所涉及的语音处理装置包含:语言名存储单元,其存储成为语音处理的对象的默认语言的语言名;语音处理单元,其用于能够针对多个语言的每一个至少进行语音识别,接受语言名的指定,将所提供的语音信号作为该指定的语言的语音进行处理;语言识别单元,其用于响应于语音信号的输入,识别该语音信号所表示的语音为多个语言中的哪一个;第1语音处理启动单元,其响应于语音信号的输入,指定语言名存储单元中存储的默认语言,启动基于语音处理单元的语音信号的处理;一致判定单元,其判定由语言识别单元识别出的语言是否与默认语言一致;以及第2语音处理启动单元,其响应于基于一致判定单元的判定为否定,使基于语音处理单元的对语音信号的处理结束,从语音信号的给定位置指定由语言识别单元识别出的语言,启动基于语音处理单元的对语音信号的处理。
20.优选地,语音处理装置还包含:默认语言决定单元,其用于基于由一致判定单元进行的判定结果和语言名存储单元中存储的默认语言,通过预先确定的算法,决定将语言名存储单元中存储的默认语言的语言名设为多个语言中的哪一个,并使其存储在语言名存储单元。
附图说明
21.图1是示出本发明的第1实施方式中的语言识别的概略的示意图。
22.图2是示出本发明的第1实施方式所涉及的语音处理装置的概略结构的框图。
23.图3是示出本发明的第1实施方式所涉及的用于语言识别的中心部的结构的框图。
24.图4是示出本发明的第1实施方式所涉及的多语言语音处理装置所利用的多语言语音翻译装置的概略结构的框图。
25.图5是示出图4所示的自动翻译装置的一个概略结构的框图。
26.图6是示出实现本发明的第1实施方式所涉及的多语言语音处理装置的计算机系统的外观的图。
27.图7是示出图6所示的计算机的硬件结构的框图。
28.图8是示出使图6所示的计算机作为第1实施方式所涉及的语音处理装置发挥功能的计算机程序的控制构造的流程图。
29.图9是示出在图8中示出控制构造的程序的一部分的控制构造的流程图。
30.图10是示出第1实施方式所涉及的语音处理装置中的逐行方式的语言识别的概略的图。
31.图11是示出基于以往的方法的语音处理的时间经过的示意图。
32.图12是示出在本发明的第1实施方式中、在短时间内得到最终的语音处理结果时的语音处理的时间经过的示意图。
33.图13是示出在本发明的第1实施方式中、得到最终的语音处理结果的时间成为最长的情况下的语音处理的时间经过的示意图。
34.图14是示出本发明的第2实施方式所涉及的语音对话系统的整体结构的概略图。
35.图15是示出在第2实施方式中用作终端的智能手机的概略的硬件结构的框图。
36.图16是示出图15所示的智能手机的功能的结构的框图。
37.图17是示出在图15所示的智能手机中设定语言的画面的示意图。
38.图18是图15所示的服务器侧的多语言语音翻译系统的功能的框图。
39.图19是示出用于使计算机作为图18所示的多语言语音翻译系统而发挥功能的计算机程序的控制构造的流程图。
具体实施方式
40.在以下的说明以及附图中,对相同的部件标注相同的参照编号。因此,不重复对它们的详细的说明。
41.[第1实施方式]
[0042]
<结构>
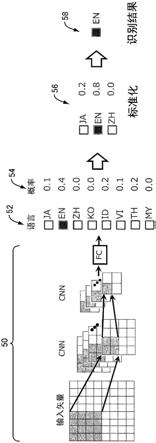
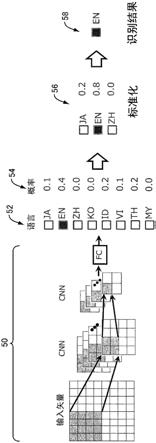
[0043]
图1是示出本发明的第1实施方式中的语言识别的概略的示意图。参照图1,在本实施方式中,利用神经网络50来对所输入的语音信号进行处理,由此针对预先确定的八种语言52的每一个,计算输入语音为该语言的输入语音的概率54。该概率54被标准化为合计成为1。进而,从八种语言52中提取预先由用户指定的多种(在以下的实施方式中为三种)选择语言56的概率,对这些概率进一步进行标准化以使合计成为1。在标准化后的选择语言56中,推定最高概率的语言58为所输入的语音的语言。此时,如果标准化后的概率为预先确定的阈值以上,则采用语言58作为推定结果,否则舍弃推定结果。在舍弃推定结果的情况下,使用语音的后续来再次进行语言的推定。
[0044]
图2是示出本发明的第1实施方式所涉及的、自动识别由输入的语音信号表示的语言并基于其结果进行针对该语音信号的语音处理的多语言语音处理装置100的概略结构的框图。在本实施方式中,多语言语音处理装置100推定语音是八种语言中的哪一种语言并进行语音识别,进行自动翻译,根据翻译结果合成语音并输出。
[0045]
参照图2,在多语言语音处理装置100连接有话筒(以下称为“麦克风”。)102、监视器104、扬声器106。多语言语音处理装置100包含:语音处理装置130,其从麦克风102接收语音信号,进行数字化、帧化并变换为表示各语音的语音数据矢量的时间序列;语言识别神经网络132,其接受语音处理装置130输出的、给定长度的语音数据矢量列的输入,针对这些语言的每一个输出所输入的语音信号所表示的语音为前述的八种语言的概率;以及语言判定部134,其基于语言识别神经网络132输出的八种概率,判定输入语音的语言。
[0046]
在本实施方式中,如图1所示,判定对象的语言是日语(简称为“ja”。以下,括号内表示各语言的简称。)、英语(en)、中文(zh)、韩语(ko)、印度尼西亚语(id)、越南语(vi)、泰语(th)、以及缅甸语(my)。
[0047]
多语言语音处理装置100还包含:基本信息设定部120,其用于通过对话型处理来设定包含使用多语言语音处理装置100时的与用户的接口中使用的语言的基本信息;对方语言存储部122,其用于存储与处理中的针对讲话的讲话者的对方的语言相关的信息;语言设定部124,其用于通过对话型处理来设定与作为语言识别神经网络132的处理对象的八种语言、用户在其中选择的三种语言、以及用户进一步在其中作为最初的输入语音的语言而预先指定的语言相关的信息;选择语言存储部128,其用于存储在语言设定部124中设定的信息;以及默认语言存储部126,其用于将被推定为下一个语音的语言的语言存储为默认值。默认语言存储部126以及对方语言存储部122中存储的值伴随着多语言语音处理装置100的动作,伴随着识别出的语言的变化,通过给定的算法进行更新。
[0048]
另外,在默认语言存储部126中存储的语言是在对于用户来说的语言不明时,暂且推测出的语言、或者作为对话的对方的默认的语言而由用户从以前开始设定的语言。假设明确知道对话的对方的语言的情况下,使用语言设定部124将该语言设定于默认语言存储部126即可。但是,在该情况下,变得不需要原本基于语言识别神经网络132的语言的判定。在本实施方式中,不进行针对这样的情况的结构以及说明,始终设想对话的对方的语言不明的情况。
[0049]
多语言语音处理装置100还包含:语言变化判定部136,其判定针对所输入的语音信号由语言判定部134判定出的语言是否从存储于默认语言存储部126的默认语言进行了变化,并输出表示其结果的判定信号;以及语言选择部138,其具有与默认语言存储部126和语言判定部134的输出分别连接的两个输入,用于根据语言变化判定部136的输出来选择任意一个并输出。
[0050]
多语言语音处理装置100还包含:fifo的缓冲器140,其存储语音处理装置130输出的语音数据矢量列的与一定时间对应的量;语音数据选择部142,其具有与语音处理装置130的输出以及缓冲器140的输出连接的两个输入,用于根据语言变化判定部136的输出来选择任意一个并输出;以及多语言语音翻译装置144,其具有与语音数据选择部142的输出连接的输入,用于针对所输入的语音数据矢量列,设想该语音的语言是由语言选择部138的输出指定的语音来进行语音翻译处理。如以下说明的那样,缓冲器140在以默认的语言开始了针对语音数据的语音翻译处理之后,在明确了实际的语言是默认的语言以外时,为了以正确的语言从头开始执行针对语音数据的语音翻译而需要。
[0051]
在本实施方式中,多语言语音翻译装置144进行以下处理,即,针对所输入的语音数据矢量列执行语音识别处理,将其结果自动翻译为存储在对方语言存储部122的语言,进
而输出作为自动翻译的结果的文本和用于语音合成的参数。
[0052]
多语言语音处理装置100还包含:语音信号合成装置146,其用于基于多语言语音翻译装置144输出的用于语音合成的参数和存储在对方语言存储部122的信息来合成语音信号,并提供给扬声器106来使其产生语音;以及显示控制装置148,其用于基于多语言语音翻译装置144输出的文本信息来控制监视器104并使其显示该文本。
[0053]
图3是示出本发明的第1实施方式所涉及的用于语言识别的中心部的结构的框图。参照图3,在本实施方式中,语言识别神经网络132包含三个语言识别模型180、182以及184。这些都是神经网络。语言识别模型180是用于将1.5秒的语音数据作为输入来推定该语音的语言的模型。同样地,语言识别模型182将2.0秒的语音数据作为输入,语言识别模型184将3.0秒的语音数据作为输入。
[0054]
例如语言识别模型180包含:卷积层组170,其包含多个卷积块;以及全连接层172,其接受卷积层组170的输出而输出八种语言的概率174。全连接层172包含多个层,最终层成为softmax层。因此,与八种语言对应的输出的合计为1,能够作为概率174来处理。语言识别模型182以及语言识别模型184具有与语言识别模型180大致相同的结构,但是在该结构中存在反映了输入的尺寸不同的情况的差异(输入层的节点数等)。
[0055]
语言识别模型180、182以及184通过8国语言的大量的语音信号和表示该语音信号所表示的语音的语言的正确数据的组合而分别预先训练。语音信号的大小根据各模型而使用不同的大小。在本实施方式中,正确数据具有八个要素,设为与正确的语言对应的要素的值为1、除此以外的要素的值为0的矢量。训练本身能够通过对神经网络的通常的误差逆传播法来进行。训练数据越多则语言识别的精度越高,因此收集足够量的训练数据是重要的。
[0056]
语言判定部134包含:模型选择部190,其分别从语言识别模型180接受概率174的输入,从语言识别模型182接受概率176的输入,从语言识别模型184接受概率178的输入,根据基于三种模型的这三组概率,选择由外部信号指定的一组;语言选择部200,其根据由模型选择部190选择的概率的组所包含的八种概率,提取存储在选择语言存储部128的三种选择语言的概率;以及概率标准化部202,其用于对语言选择部200选择的三种语言的概率进行标准化并作为概率输出。概率标准化部202计算三种概率的合计,将用该值除各概率的语言而得到的值作为各语言的概率。该值合计为1。
[0057]
语言判定部134还包含:最大概率选择部204,其在由概率标准化部202标准化后的三个概率中选择最大的概率并输出;阈值比较部206,其判定由最大概率选择部204选择的概率是否为给定的阈值以上,并输出判定结果;语言决定部208,其用于如下,即,接受概率标准化部202输出的标准化后的概率、最大概率选择部204选择的最大概率以及来自阈值比较部206的比较结果,并基于它们尝试语言的识别,如果能够识别出语言,则将其结果提供给语言变化判定部136,将表示完成了判定的完成信号提供给语言变化判定部136(图2)以及对方语言存储部122(图2),在无法识别出语言时,将此时的各语言的标准化后的概率存放在概率存储部194,将计数器196的值增加1,向语言选择部200提供指示,选择下一个语言识别模型的输出,并执行同样的处理;以及阈值存储部192,其存储阈值比较部206进行比较的阈值。作为阈值,预先通过实验来确定以使能够实现期望的精度以及等待时间(latency)。期望阈值至少为0.5以上,更优选为0.8以上,进一步优选为0.85以上。
[0058]
图4是示出本发明的第1实施方式所涉及的多语言语音处理装置所利用的多语言
语音翻译装置144的概略结构的框图。参照图4,多语言语音翻译装置144包含:八种语言用的语音识别装置220、
…
、224,其与八种语言对应地预先准备;八种多语言翻译装置240、
…
、254,其分别接受这些语音识别装置220、
…
、234输出的语音识别结果的文本,能够将该语音识别装置输出的文本从各语音识别装置的语言翻译为其他七种语言,并且在其中翻译为由对方语言存储部122指定的语言并输出;数据分配部258,其用于接受从图2的语音数据选择部142提供的语音数据矢量列,并将该语音数据矢量列提供给语音识别装置220、
…
、234中的由来自语言选择部138的语言选择信号指定的装置;以及输出选择部256,其以接受来自多语言翻译装置240、
…
、254各自的输出的方式连接,用于选择由来自语言选择部138的语言选择信号指定的语音处理结果,分别将语音合成用的参数提供给语音信号合成装置146,将语音处理结果的文本提供给显示控制装置148。
[0059]
参照图5,多语言翻译装置240包含:七个自动翻译引擎262、
…
、274,其用于将与该多语言翻译装置240对应的语言的文翻译为其他七种语言,并且均以接受接受来自对方语言存储部122的对方语言选择信号的方式连接;翻译引擎选择部260,其分别从语言选择部138接受语言选择信号,从对方语言存储部122接受表示对方语言的信号,仅在被语言选择部138选择时进行动作,执行向自动翻译引擎262、
…
、274中的与来自对方语言存储部122的对方语言选择信号对应的自动翻译引擎提供语音识别装置220输出的文本的处理;以及输出选择部278,其以接受来自对方语言存储部122的对方语言选择信号的方式连接,用于选择自动翻译引擎262、
…
、274中的由对方语言选择信号选择的自动翻译引擎的输出,作为来自多语言翻译装置240的输出提供给图4所示的输出选择部256。
[0060]
在图6示出实现上述的多语言语音处理装置100的计算机系统290的一个例子的外观,在图7示出构成计算机系统290的计算机的一个例子的硬件框图。
[0061]
参照图6,该计算机系统290包含具有dvd(digital versatile disc,数字多功能盘)驱动器310的计算机300和均与计算机300连接的键盘306、鼠标308以及监视器104。
[0062]
参照图7,计算机300除了dvd驱动器310以外,还包含cpu316、gpu(graphic processing unit,图形处理单元)317、与cpu316、gpu317、dvd驱动器310连接的总线326、与总线326连接并存储计算机300的启动程序等的rom318、与总线326连接并存储程序指令、系统程序以及作业数据等的ram320、以及与总线326连接的作为非易失性存储器的硬盘驱动器(hdd)314。硬盘314用于存储cpu316以及gpu317所执行的程序、cpu316以及gpu317所执行的程序所使用的数据等。计算机300还包含:网络i/f304,其提供向使得能够进行与其他终端的通信的网络328的连接;以及usb存储器端口312,能够装卸usb存储器330,提供usb存储器330与计算机300内的各部分的通信。
[0063]
计算机300还包含:语音i/f324,其与麦克风102以及扬声器106和总线326连接,用于按照cpu316的指示读出由cpu316生成并保存于ram320或hdd314的语音信号,进行模拟变换以及放大处理来驱动扬声器106,或者将来自麦克风102的模拟的语音信号数字化,保存在ram320或hdd314的由cpu316指定的任意的地址。
[0064]
在上述实施方式中,图2所示的基本信息设定部120、对方语言存储部122、语言设定部124以及默认语言存储部126均由hdd314或ram320实现。典型地,它们例如从外部被写入hdd314,在计算机300执行时被加载到ram320,定期地作为备份被保存到硬盘314。
[0065]
成为处理对象的语音信号可以通过任意单元保持在计算机300,但是通常经由网
络i/f304从网络328上的其他计算机发送到计算机300,并保存在ram320或hdd314。
[0066]
用于使该计算机系统以实现多语言语音处理装置100及其各构成要素的功能的方式进行动作的计算机程序存储在安装在dvd驱动器310的dvd322,并从dvd驱动器310传送到hdd314。或者,该程序被存储在usb存储器330,将usb存储器330安装到usb存储器端口312,将程序传送到硬盘314。或者,该程序也可以通过网络328发送到计算机300并存储在hdd314。程序在执行时被加载到ram320。另外,也可以使用键盘306、鼠标308以及监视器104来编写源程序,通过编译器进行编译并将其输出的目标程序保存在hdd314。在脚本语言的情况下,可以使用键盘306等输入作为实现上述的处理的程序的脚本,并保存在hdd314。
[0067]
cpu316按照由其内部的被称为程序计数器的寄存器(未图示)表示的地址从ram320读出程序并解释指令,按照由指令指定的地址从ram320、硬盘314或除此其以外的设备读出指令的执行所需的数据并执行由指令指定的处理。cpu316将执行结果的数据存放在ram320、硬盘314、cpu316内的寄存器等由程序指定的地址。此时,程序计数器的值也通过程序来更新。计算机程序也可以从dvd322、usb存储器330、或经由网络直接加载到ram320。另外,在cpu316执行的程序中,针对一部分的任务(主要为数值计算),根据程序内的指令、或根据基于cpu316的指令执行时的解析结果,分配给gpu317。
[0068]
实现计算机300的各功能的程序包含使计算机300作为上述的各装置进行动作的多个指令。使其进行该动作所需的基本功能中的几个,由在计算机300上动作的操作系统(os)或第三方程序、或安装在计算机300的各种工具套件的模块提供。因此,该程序未必一定包含实现本实施方式的系统以及方法所需的全部功能。该程序在指令中仅包含通过以被控制为得到所希望的结果的方法调出适当的功能或“编程工具套件”来执行作为上述的各装置及其构成要素的动作的指令即可。计算机300的动作方法是公知的,因此在此不重复。另外,gpu317能够进行并行处理,能够同时并行或流水线地执行与大量的语音数据相关的语音识别处理、自动翻译处理、语音合成处理。
[0069]
图8是示出使图6所示的计算机作为第1实施方式所涉及的语音处理装置发挥功能的计算机程序的控制构造的流程图。另外,语言识别神经网络132以及多语言语音翻译装置144通过与该程序不同的工艺来执行。
[0070]
参照图8,该程序包含:步骤350,其进行程序启动时的初始设定;步骤352,其判定是否输入了语音,并待机至输入语音为止;步骤354,其响应于输入了语音的情况,分别从图2的默认语言存储部126读出默认语言,从对方语言存储部122读出对方语言;步骤356,其以在步骤354中读出的语言的组合(从默认语言向对方语言)启动多语言语音翻译装置144;以及步骤358,其启动基于语言识别神经网络132的语言识别处理。
[0071]
根据图2可知,向语音数据选择部142以及语言识别神经网络132同时提供语音处理装置130的输出。在程序启动时,语言判定部134的输出选择默认语言。因此,向语言识别神经网络132和多语言语音翻译装置144同时提供相同的语音数据。在步骤356中启动语音翻译处理,在步骤358中启动语言识别处理,因此之后两者会并行地动作。
[0072]
该程序还包含:步骤360,其在步骤358之后,判定识别出的语言是否与存储在图2的默认语言存储部126的默认语言一致,根据其结果使控制的流程分支;步骤362,其在步骤360的判定为否定时,中止将翻译目标的语言指定为默认语言而在步骤356中启动的语音翻译处理;以及步骤364,其指定为进行识别结果的语言和存储在图2的对方语言存储部122的
对方语言的组合(从识别结果的语言向对方语言的语音翻译),启动多语言语音翻译装置144的语音翻译处理。
[0073]
该程序还包含步骤366,其在步骤364之后、以及步骤360的判定为肯定时执行,将存储于图2所示的对方语言存储部122的对方语言存放在默认语言存储部126,将语言选择部138输出的识别结果的语言存放在对方语言存储部122,使控制返回步骤352。
[0074]
图9是示出在图8中示出控制构造的程序的一部分即步骤358中执行的程序例程的一部分的流程图。通过该程序,实现后述的逐行方式的语言识别。参照图9,该程序例程包含:步骤380,其将0代入对用于控制基于逐行方式的语言识别处理的重复处理进行控制的变量i;步骤382,其分别将相当于1.75秒、2.5秒以及0秒的值{1.75、2.5、0}代入作为在逐行方式的语言识别处理中用于决定是否切换语言识别模型的讲话长度的阈值而准备的讲话长度阈值阵列;以及步骤384,其判定变量i的值是否比从在逐行方式的语言识别处理中使用的模型的数减去了1的值大,根据判定结果使控制的流程分支。另外,在步骤382中,还准备确定识别模型的三个要素的阵列(以下,称为“模型阵列”。),存放各识别模型的识别信息。在此,设为使用向三个识别模型的输入讲话长度作为识别信息,将表示各识别模型的输入语音数据长度的{1.5、2.0、3.0}这一值存放在模型阵列中。
[0075]
该程序还包含:步骤386,其在步骤384的判定为否定时,向模型[i]输入对该模型的输入讲话长度的语音数据;步骤388,其继步骤386,从模型[i]输出的各语言的概率中选择给定的三种语言的概率;步骤390,其对在步骤388中选择的三种语言的概率的值进行标准化;步骤392,其判定在步骤390中标准化后的概率的最大值是否为阈值以上,根据判定结果使控制的流程分支;以及步骤394,其在步骤392的判定为肯定时,将与该最大值对应的语言决定为识别语言并输出该信息,结束处理。
[0076]
该程序还包含:步骤398,其在步骤392的判定结果为否定时,判定输入讲话的讲话长度是否比讲话长度阈值[i]短,根据判定使控制的流程分支;步骤400,其在步骤398的判定为否定时,将在步骤390中标准化后的三种语言的概率存储在概率存储部194(参照图3);以及步骤402,其对变量i的值相加1而使控制返回到步骤384。
[0077]
该程序还包含:步骤396,其在步骤384的判定为肯定时(变量i的值比模型数
‑
1大时)、以及步骤398的判定为肯定时(讲话长度比讲话长度阈值[i]短时),将存储于概率存储部194(参照图3)的各语言的概率合并来决定最终的识别语言,并将控制移至步骤394。
[0078]
在步骤396中,例如针对存储于存储器的各语言的概率,计算各语言的平均。在该情况下,在步骤394中,即使该平均值的最大值小于在步骤392中使用的阈值,也将与该最大值对应的语言决定为识别语言。
[0079]
在图10示出三种语言识别模型所处理的讲话长度与在图9的步骤398中使用的讲话长度阈值的关系。参照图10,语言识别模型180将从讲话的开头起1.5秒的语音作为输入来识别该语言。语言识别模型182将从讲话的开头起2.0秒的语音作为输入来识别该语言。语言识别模型184将从讲话的开头起3.0秒的语音作为输入来识别该语言。在语言识别模型180中未识别出语言的情况下,使用语言识别模型182来识别语言,在语言识别模型182也无法识别的情况下,使用语言识别模型184来识别语言。
[0080]
但是,例如即使在语言识别模型180中无法识别,在讲话长度不足2秒的情况下,使用语言识别模型182也无法识别语言的可能性高。因此,在本实施方式中,在语言识别模型
180中无法识别语言时,在讲话长度如图10所示那样比1.75秒短的情况下,不进行语言识别模型182中的语言的识别,而使用由语言识别模型180计算出的概率来识别语言。同样地,即使在语言识别模型182中无法识别语言的情况下,在讲话如图10所示那样不足2.5秒的情况下,也不进行语言识别模型184中的语言识别,而使用由语言识别模型180以及182针对各语言计算出的概率来进行语言的识别。此时,只要这样计算出的概率的最大值为阈值以上就没有问题,但是即使在小于阈值时,也将与最大值对应的语言作为语言识别的结果。
[0081]
这样,在以短的讲话长度无法识别语言时,依次进一步考虑之后的语音数据来进行语言识别。在本说明书中将这样的方式称为逐行方式。
[0082]
在图9的步骤390中进行的标准化处理是通过将各语言的概率除以将三种语言的概率合计而得到的值,来重新计算各语言的概率的处理。
[0083]
<动作>
[0084]
以上说明了结构的多语言语音处理装置100如下进行动作。在多语言语音处理装置100启动时,在对方语言存储部122存储有该多语言语音处理装置100的用户在基本信息设定部120中存储的基本信息内使用的语言。在默认语言存储部126存储有用户在语言设定部124中存储的语言中临时选择为语音输入的语言的语言。作为用户,即使不是明确地知道对话的对方的语言,也能够推断而设定在默认语言存储部126。
[0085]
在以下的动作中,设为不是从用户开始说话,而是从对话的对方开始说话。在实际的对话处理中,作为用于推定对方的语言的处理,需要最初让对话的对方开始讲话。因此,优选在画面上用某一国的语言显示“请用自己的语言说点什么”这样的意思的文本。例如,如果将其用英语等显示,则可认为对方不会不知所措。
[0086]
参照图2,若对话的对方开始说话,麦克风102将语音变换为语音信号并提供给图2所示的语音处理装置130。语音处理装置130接收该语音信号,进行数字化、帧化,变换为表示各语音的语音数据矢量的时间序列,提供给语言识别神经网络132、语音数据选择部142以及缓冲器140。缓冲器140对该语音数据进行缓冲。此时,参照图3,分别向语言识别神经网络132内的语言识别模型180提供从讲话的开头起1.5秒期间的语音数据,向语言识别模型182提供从讲话的开头起2.0秒期间的语音数据,向语言识别模型184提供从讲话的开头起3.0秒期间的语音数据。
[0087]
另一方面,参照图2,语言变化判定部136设定语言选择部138以及语音数据选择部142,以使在启动时能够用默认语言来处理语音数据。即,语言选择部138选择默认语言存储部126的输出,并提供给多语言语音翻译装置144以及语音信号合成装置146。与默认语言相关的信息也被提供给对方语言存储部122,但是对方语言存储部122仅在由语言判定部134判定了语言时取入语言选择部138的输出。因此,在对方语言存储部122仍然存放有用户的语言。该值被提供给多语言语音翻译装置144以及语音信号合成装置146(图8的步骤354)。语音数据选择部142不是选择缓冲器140的输出而是选择语音处理装置130的输出,并提供给多语言语音翻译装置144。
[0088]
其结果是,多语言语音翻译装置144将从语音处理装置130经由语音数据选择部142提供的语音数据作为表示默认语言存储部126中存储的语言的语音的数据而开始语音处理(图8的步骤356)。
[0089]
参照图4,多语言语音翻译装置144具体如下进行动作。数据分配部258将来自语音
数据选择部142的语音数据分发给语音识别装置220、
…
、234中由来自语言选择部138的语言选择信号指定的装置,而不分发给除此以外的装置。此外,语音识别装置220、
…
、234均接收来自语言选择部138的语言选择信号,仅用于处理由语言选择信号指定的语言的装置(例如语音识别装置220)进行动作。
[0090]
语音识别装置220
…
、234中的由语言选择信号指定的语音识别装置将识别后的文本提供给对应的多语言翻译装置240。以下,作为例子,将语音识别装置220设为由语言选择信号指定,对来自语音数据选择部142的语音数据进行语音识别,将其结果的文本提供给多语言翻译装置240的装置,将多语言翻译装置240设为进行翻译处理的装置而进行说明。
[0091]
参照图5,在多语言翻译装置240的翻译引擎选择部260分别从语言选择部138被提供语言选择信号,从对方语言存储部122被提供表示对方语言的信号。翻译引擎选择部260仅在被语言选择部138选择时,向自动翻译引擎262、
…
、274中与来自对方语言存储部122的对方语言选择信号对应的自动翻译引擎提供语音识别装置220输出的文本。
[0092]
自动翻译引擎262、
…
、274均被提供来自对方语言存储部122的对方语言选择信号,仅被对方语言选择信号选择的自动翻译引擎进行自动翻译。在图5所示的例子中,例如如果自动翻译引擎262被对方语言选择信号选择,则由翻译引擎选择部260选择自动翻译引擎262,语音识别装置220的输出被提供给自动翻译引擎262。自动翻译引擎262将输入的文本自动翻译为对方语言。该对方语言与存储在对方语言存储部122的对方语言一致。
[0093]
输出选择部278也被提供来自对方语言存储部122的对方语言选择信号,输出选择部278选择自动翻译引擎262、
…
、274中的由对方语言选择信号选择的自动翻译引擎的输出,作为来自多语言翻译装置240的输出提供给图4所示的输出选择部256。
[0094]
输出选择部256选择与由来自语言选择部138的语言选择信号指定的语言对应的多语言翻译装置(例如多语言翻译装置240)的输出,向语音信号合成装置146以及显示控制装置148输出。
[0095]
即,多语言语音翻译装置144进行以下那样的动作,即,对所输入的语音数据进行语音识别,进行自动翻译,生成语音合成的参数,并依次输出它们。
[0096]
另一方面,语言识别神经网络132的语言识别模型180、182以及184均与多语言语音翻译装置144同时开始对语音数据表示的语音的语言进行识别的处理(图8的步骤358)。各模型所需的讲话长度分别为1.5秒、2.0秒以及3.0秒,它们从开头开始被图2所示的语音处理装置130处理并作为语音数据矢量列进行蓄积。在蓄积了与1.5秒对应的量的讲话数据的时间点,向语言识别模型180输入它们。同样地,在蓄积了与2.0秒对应的量的讲话数据的时间点,向语言识别模型182输入它们,在蓄积了与3.0行对应的量的讲话数据的时间点,向语言识别模型184提供它们。另外,在讲话不足1.75秒或2.5秒的情况下,通过未图示的标志来保存该信息。
[0097]
从语言识别模型180、182以及184分别输出其识别结果(图3所示的概率174、176以及178)。此时,语言识别模型180开始识别处理为止的时间比其他两个模型早,其结果最早得到。语言识别模型182开始识别处理为止的时间比语言识别模型180长,但是比语言识别模型184短,因此在得到基于语言识别模型180的识别结果之后且在得到基于语言识别模型184的识别结果之前得到。来自语言识别模型184的识别结果最晚得到。
[0098]
图3所示的语言判定部134使用从这些语言识别模型180、182以及184输出的概率,
如以下那样执行语言的识别处理。另外,以下,为了尽可能简明地进行说明,以讲话比2.5秒长作为前提来说明语言判定部134的动作。
[0099]
参照图3,若检测到讲话,则语言决定部208首先将计数器196的值初始化为0(图9的步骤380)。接下来,语言决定部208向由计数器196的值(=0)决定的模型(在该例子的情况下为语言识别模型180)提供与1.5秒对应的量的语音数据(步骤386),对模型选择部190进行控制以使选择其输出(步骤388)。模型选择部190选择语言识别模型180输出的概率174并提供给语言选择部200,语言选择部200从语言识别模型180输出的八种语言的概率174中选择与选择语言存储部128中存储的三种语言相关的概率(图9的步骤388)并提供给概率标准化部202。概率标准化部202计算该三种语言的概率之和,将各概率的值除以该和,由此对与三种语言相关的概率进行标准化(图9的步骤390)。最大概率选择部204选择其中的最大值,阈值比较部206将该最大值与阈值进行比较(图9的步骤392)。如果最大值为阈值以上(在步骤392中为“是”),则阈值比较部206将表示与最大值对应的语言的概率为阈值以上的信号提供给语言决定部208。语言决定部208基于概率标准化部202输出的标准化后的三种语言的概率、最大概率选择部204输出的最大概率、以及阈值比较部206的比较结果,决定与最大概率对应的语言是否为语音数据的语言。在本实施方式中,基本上,在最大概率为阈值以上的情况下,将与该概率对应的语言作为识别语言,在哪个概率都不是阈值以上的情况下,将逐行地进行的过去的一次或两次判定时的各语言的概率和当前的概率合并(例如计算平均值),无论该值是否为阈值以上,都将与最大的值对应的语言作为识别语言。如果决定为是语音数据的语言,则语言决定部208向语言变化判定部136输出该值。语言决定部208进而将表示识别完成的信号向语言变化判定部136以及对方语言存储部122输出。由此完成语言识别。
[0100]
如果概率的最大值小于阈值,则认为识别结果不可靠,将概率标准化部202输出的三种语言的概率保存在概率存储部194,将计数器196中存储的变量i的值增加1,控制模型选择部190选择下一个语言识别模型、即语言识别模型182。
[0101]
如果作为基于语言识别模型182的识别结果的概率176被输出,则模型选择部190对其进行选择,并提供给语言选择部200。以下,执行与以上相同的处理。
[0102]
在通过基于语言识别模型182的识别结果也无法决定语言时,语言决定部208进一步增加计数器196而设为2,控制模型选择部190,下次使其选择作为语言识别模型184的输出的概率178。模型选择部190选择来自语言识别模型184的概率178,并提供给语言选择部200。以下,重复与以上相同的处理,直到语言决定部208的处理为止。
[0103]
另外,在图9的步骤392的处理的判定即使使用语言识别模型184的结果也为否定的情况下,如以下那样进行处理。在该情况下,控制进入步骤398。然而,在该情况下,i=2,讲话阈值长度[2]=0,因此图9的步骤398的判定一定为否定,执行步骤400以及402。在之后的循环处理的开头的步骤384中判定为否定,会经过步骤396以及394识别语言。
[0104]
在语言决定部208中,在概率的最大值为阈值以上的情况下,与其他情况同样地,将与该概率对应的语言作为语言识别的结果输出到语言变化判定部136,将表示完成了语言识别的信号输出到语言变化判定部136以及对方语言存储部122。这与i=0以及1的情况相同。
[0105]
但是,在最大值小于阈值时,语言决定部208如以下那样决定。即,语言决定部208
在该情况下合并存储在概率存储部194的、至此为止的各语言的概率。例如计算各语言的概率的平均值,将其作为该语言的合并后的概率。然后,将该合并后的概率最大的语言决定为讲话数据的语言。在该情况下,即使该概率小于阈值,也决定为该语言。这是因为,既然将该装置使用于对话,就需要以某种形式在给定时间内进行输出。
[0106]
另外,在讲话长度不足1.75秒时,仅使用语言识别模型180的结果来执行上述识别处理。在该情况下,即使最终的概率的最大值小于阈值,也与上述的i=2的情况同样地输出语言识别的结果。在讲话长度不足2.5秒时也相同,仅使用语言识别模型180的输出以及语言识别模型182的输出来执行识别处理。即使在该情况下,在概率的最大值即使使用语言识别模型182的结果也小于阈值时,也与i=2时同样地,按每个语言合并至此为止存储的各语言的概率(例如计算平均值),将最高的概率的语言作为识别结果。该值为阈值以上,这不作为必要条件。
[0107]
再次参照图2,语言变化判定部136响应于表示完成了识别的来自语言判定部134的信号,将默认语言存储部126中存储的默认语言与语言判定部134输出的识别结果的语言进行比较,将表示相同还是变化的判定信号提供给语言选择部138以及语音数据选择部142。将相同的情况下的判定信号的值设为第1值,将不同的情况下的判定信号的值设为第2值。以下,分为识别结果的语言与默认语言一致的情况和不一致的情况来说明多语言语音处理装置100的动作。
[0108]
‑
识别结果的语言与默认语言一致的情况
‑
[0109]
在语言变化判定部136的判定信号为第1值的情况下,语言选择部138选择默认语言存储部126的输出,并提供给对方语言存储部122、多语言语音翻译装置144以及语音信号合成装置146。在该情况下,将与原来提供的信息相同的信息提供给多语言语音翻译装置144以及语音信号合成装置146。
[0110]
语音数据选择部142响应于从语言变化判定部136提供了第1值的判定信号的情况,继续进行将来自语音处理装置130的语音信号提供给多语言语音翻译装置144的处理。
[0111]
由于来自语言选择部138的语言选择信号的值没有变化,图4所示的数据分配部258在语音识别装置220、
…
、234中,向原本提供了语音数据的语音识别装置,之后也继续提供语音数据。同样地,在图4的多语言翻译装置240、
…
、254中根据默认值进行动作的自动翻译装置的翻译引擎选择部260(图5)向相同的翻译引擎继续提供语音识别结果。此外,由于来自对方语言存储部122的对方语言选择信号的值也没有变化,因此在根据默认的语言选择信号进行动作的多语言翻译装置中,由对方语言选择信号选择的自动翻译引擎也同样地继续动作。其他语音识别装置以及自动翻译装置不动作。关于输出选择部256也相同,在决定识别结果之前选择动作中的语音识别装置以及多语言翻译装置的输出,并提供给语音信号合成装置146以及显示控制装置148。
[0112]
参照图2,语音信号合成装置146以及显示控制装置148也继续对从多语言语音翻译装置144输出的、与之前相同的语言的语音翻译结果进行处理。
[0113]
然后,对方语言存储部122中存储的对方语言存储在默认语言存储部126,表示从语言选择部138提供的新的识别结果的语言的信息存储在对方语言存储部122。
[0114]
若有新的语音输入,则重新进行指定默认语言存储部126中存储的默认语言和对方语言存储部122中存储的对方语言的语音处理。
[0115]
‑
识别结果的语言与默认语言不一致的情况
‑
[0116]
在该情况下,语言变化判定部136响应于两个输入不一致的情况,将第2值的判定信号提供给语言选择部138以及语音数据选择部142。语言选择部138响应于该判定信号,选择语言判定部134输出的识别结果的语言,提供给对方语言存储部122、多语言语音翻译装置144以及语音信号合成装置146。
[0117]
语音数据选择部142响应于来自语言变化判定部136的判定信号,选择缓冲器140的输出,提供给多语言语音翻译装置144。
[0118]
参照图4,数据分配部258从至此为止选择的语音识别装置以及自动翻译装置切换为表示从语言选择部138提供的识别结果的语言的新的语音识别装置以及自动翻译装置而提供语音数据选择部142的输出。
[0119]
在语音识别装置220、
……
、234中,由于来自语言选择部138的选择信号的值进行了变化,因此至此为止执行了语音翻译处理的语音识别装置中止语音识别处理。多语言翻译装置也相同。另一方面,在语音识别装置220、
…
、234中,由新的选择信号指定的语音识别装置开始从由数据分配部258提供的、被缓冲的语音数据的开头开始进行处理。此外,接受该语音识别装置的输出的多语言翻译装置也开始动作,其中由对方语言选择信号确定的自动翻译引擎开始翻译。翻译结果由输出选择部278以及输出选择部256输出。
[0120]
以下,重新开始了处理的装置的输出被提供给图2所示的语音信号合成装置146以及显示控制装置148。语音信号合成装置146进行如下的处理,即,基于从多语言语音翻译装置144输出的语音合成参数,合成向对方语言存储部122中存储的对方语言的语音信号,并提供给扬声器106。
[0121]
若对所输入的语音数据的处理完成,则对方语言存储部122中存储的对方语言被存储在默认语言存储部126而成为默认语言,语言选择部138输出的识别结果的语言被存储在对方语言存储部122而成为对下一个语音的语音翻译处理的目标语言。
[0122]
若概括以上的多语言语音处理装置100的动作,则如下。首先,若与用户对话的对方讲话,则设为该讲话是默认语言而开始语音识别。语音识别的结果被输出。如果语言的识别结果与默认语言一致,则继续进行该处理,语音识别结果依次被自动翻译为在对方语言存储部122中存储的语言(用户的语言)。根据自动翻译的结果合成语音并输出。
[0123]
另一方面,如果语言的识别结果与默认语言不一致,则在中途中止语音识别,将语言切换为识别结果的语言,对蓄积在缓冲器140的语音数据开始进行语音识别和自动翻译,进而开始进行语音合成。
[0124]
若对语音的处理结束,则作为默认语言,设定在先前的处理中为对方语言的语言,作为对方语言,设定识别结果的语言。其结果是,若接着多语言语音处理装置100的用户与对方调换而讲话,则如果语言识别良好则识别结果的语言与默认语言一致,无需中断多语言语音翻译装置144开始的语音处理而而迅速地输出。
[0125]
如果对该语音的处理结束,则下次对方语言和默认语言被调换,对方语言的语音被语音翻译为默认语言。下次由于对方语言与识别语言一致,因此无需中止多语言语音翻译装置144开始的语音翻译处理而继续进行,从而能够迅速地得到语音翻译结果。
[0126]
参照图11至图13,对该第1实施方式所涉及的多语言语音处理装置100的效果进行说明。
[0127]
图11是示出基于以往的方法的语音处理的时间经过的示意图。若有语音的输入,则首先开始语言识别440,使用其结果开始语音识别442。若语音识别442的结果被依次输出,则针对语音识别442执行自动翻译444。针对自动翻译444的输出执行语音合成446。
[0128]
如图11所示,在与上述实施方式进行比较的意义上,在以往的方法中,将语言识别440开始到语音合成446开始为止的时间称为tc。
[0129]
图12是示出在本发明的第1实施方式中,在短时间内得到最终的语音处理结果时的语音处理的时间经过的示意图。参照图12,在上述实施方式中,语言识别440和语音识别460同时开始。语音识别460是从默认语言向对方语言的语音识别。若其结果被输出,则开始自动翻译处理462。如果基于语言识别440的识别结果的语言与默认语言一致,则语音识别460以及自动翻译处理462无需中止而继续进行,针对自动翻译的结果开始语音合成464。
[0130]
在图12所示的例子中,语音识别460与语言识别440同时开始,因此到语音合成464开始为止所需的时间t1明显比图11的时间tc短。如果比较图11和图12,则可知时间t1比时间tc短与语言识别440所需的时间对应的量。
[0131]
图13是示出在本发明的第1实施方式中,得到最终的语音处理结果的时间成为最长的情况下的语音处理的时间经过的示意图。该例子是由语言识别440识别出的语言与默认语言不同的情况。在该情况下,语音识别460与语言识别440同时开始,自动翻译处理应该在语音识别后开始这一点与图12相同,但是在语言识别440结束的时间点中止语音识别460,重新开始识别后的语言下的语音识别480、其结果的向对方语言的自动翻译482、以及针对自动翻译的结果的语音合成484。语音识别480从输入的语音的最初开始进行,因此在该情况下从语音输入到语音合成484开始为止的时间t2与图11所示的tc相同。
[0132]
即,根据本实施方式,在默认语言与识别出的语言一致的情况下,到语音翻译处理的结果的输出开始为止所需的时间比以往的时间短。该时间至少变短与最初的语言识别所需的时间对应的量。即使默认语言与识别出的语言不一致,到语音翻译处理的结果的输出开始为止所需的时间也与以往的时间相同。
[0133]
其结果是,能够得到如即使在不知道语音信号所表示的语音的语言的情况下,也能够快速得到语音处理的结果那样的语音处理装置。
[0134]
此外,不是直接使用语言识别神经网络132的输出来识别语言,而是从多种语言(在实施方式中为八种)中选择预先指定的多种语言(在实施方式中为三种)的概率,在将它们标准化后的基础上选择最高的概率的语言。通过将该语言的概率与阈值进行比较来决定受理还是舍弃识别结果。其结果是,无需使基于语言识别神经网络132的判定处理本身复杂化,而能够进行精度高的语言识别。此外,由于能够在多种语言中进一步选择一部分语言来指定为预先处理的对象,因此,即使在对方讲话的语言不明时,只要对该对方的出身地域等进行推断,就能够以较高的概率指定包含语言识别的对象那样的语言的组合,还具有对话顺畅地开始的可能性变高的效果。
[0135]
进而,在上述实施方式中,在识别出语言之后,将语音处理的对方语言设定为新的默认语言,将识别出的语言设定为下一个对方语言。其结果是,具有如下的效果,即,在两个讲话者进行对话时,能够顺畅地进行从一种语言向另一种语言的语音翻译处理。另外,在本实施方式中,设想了两个讲话者交替地讲话的情况,但是也能够容易地扩展到讲话者仅为1人时、以及讲话者为3人时等。另外,设定它们的处理能够通过进行通常的对话型处理的程
序容易地实现。
[0136]
另外,在上述实施方式(方法1)中,作为语言识别模型,使用了三个模型(讲话长度1.5秒、2.0秒、3.0秒)。但是,本发明并不限定于这样的实施方式。例如也可以使用四个语言识别模型,将作为对象的讲话长度设为1.0秒、1.5秒、2.0秒、3.0秒(方法2)。或者,也能够考虑使用相同的三个语言识别模型,将讲话长度设为1.0秒、1.5秒、2.0秒(方法3)。在这样的结构中,精度为方法1>方法2>方法3,等待时间为方法3<方法2<方法1。
[0137]
在实验中,在阈值=0.85时,在上述三个方法中精度均达成了95%以上。此外,在使用方法2以及3的情况下,等待时间成为平均1.3秒这样的非常短的等待时间。
[0138]
此外,根据目的,可以考虑各种各样的识别模型的组合。当然,仅使用一个识别模型的情况也是对象。
[0139]
此外,在上述的方法中,语言识别模型的对象均为从讲话的开头起给定长度的语音数据。但是,本发明并不限定于这样的实施方式。例如也可以使得以相同的讲话长度(例如1.0秒或1.5秒)且开头各偏移0.5秒的语音数据为对象依次进行语言识别。在该情况下,语言识别模型能够使用相同的语言识别模型。在该情况下,作为对象的讲话长度以及所使用的语言识别模型的数量也能够根据目的而选择各种。
[0140]
[第2实施方式]
[0141]
<结构>
[0142]
第1实施方式所涉及的多语言语音处理装置100通过单独的计算机来实现,但是当然也可以进行使其在多个计算机之间分担多语言语音处理装置100的各功能那样的处理。
[0143]
图14是示出本发明的第2实施方式所涉及的语音对话系统的整体结构的概略图。如图14所示,该第2实施方式所涉及的语音翻译系统500准备具备第1实施方式所涉及的多语言语音处理装置100的功能的大部分的多语言语音翻译处理服务器(以下,简称为“服务器”。)506,针对从智能手机504那样的装置经由因特网502被提供的语音翻译请求,进行语音的语言识别、自动翻译以及语音合成,将语音信号从服务器506返回给智能手机504。为了实现这样的结构,在本实施方式中,设为使用智能手机504中存放的使用该智能手机504的用户的基本信息(使用语言),进而设为使智能手机504的用户如上述第1实施方式所叙述的那样,能够从八种对方语言中选择三种语言。这样的信息由于在服务器506中的语言识别处理中需要,因此设为与语音数据一起发送到服务器506。
[0144]
图15是示出在第2实施方式中用作终端的智能手机的概略的硬件结构的框图。参照图15,该智能手机504具备摄像机520、触摸面板显示器522、扬声器524以及麦克风526。智能手机504还包含作为用于进行各种各样的处理的计算机的处理器550、与处理器550连接的存储器控制器556、均与存储器控制器556连接的sdram(static dynamic access memory,静态动态存取存储器)558以及闪速存储器560、与处理器550连接的电源、音频lsi570、与处理器550以及电源、音频lsi570连接的无线通信用的调制解调器552、与调制解调器552连接的具有无线收发用天线的无线通信装置554。
[0145]
智能手机504还包含作为处理器550的周边设备的gps(global positioning system,全球定位系统)模块562、加速度传感器、温度传感器、湿度传感器等传感器组564、wi
‑
fi模块566、近距离无线通信装置568。
[0146]
处理器550执行的程序存储在闪速存储器560,在执行时加载到sdram558。处理器
550通过执行该程序来控制智能手机504内的各模块,执行设定值的存储、经由麦克风526的讲话者的语音数据的获取、经由调制解调器552以及无线通信装置554或gps模块562的向服务器506的语音数据的发送以及来自服务器506的语音翻译结果的接收、使用了扬声器524的语音的再生等。
[0147]
图16是示出图15所示的智能手机的功能的结构的框图。将通过处理器550执行的程序来实现的功能以框图形式示出的图。
[0148]
参照图16,智能手机504在功能上包含:基本信息设定部600,其用于设定智能手机504的基本信息(至少包含用户的使用语言);对方语言存储部602,其存储语音翻译的对方语言;语言设定部604,其与实施方式同样地,对在八种语言中选择哪三种语言、将其中的哪种语言作为默认语言进行设定;默认语言存储部606,其用于存储语音翻译处理时的默认语言;以及选择语言存储部612,其用于存储与由语言设定部604设定的语言相关的信息。在语音翻译处理的启动时,在对方语言存储部602存储基本信息设定部600内的用户的使用语言,在默认语言存储部606存放由语言设定部604设定的默认语言。
[0149]
智能手机504还包含:预处理装置608,其用于对语音信号执行对从麦克风526获取到的语音信号进行与图2所示的语音处理装置130同样的处理而输出语音数据矢量列等的预处理;发送数据生成部610,其用于根据选择语言存储部612中存储的选择语言、对方语言存储部602中存储的对方语言、默认语言存储部606中存储的默认语言以及预处理装置608输出的语音数据矢量列,生成用于向服务器506请求语音翻译的发送数据;以及通信i/f614,其用于经由图15所示的调制解调器552以及无线通信装置554或wi
‑
fi模块566进行发送数据生成部610生成的发送数据向服务器506的发送以及来自服务器506的处理后的数据的接收。
[0150]
智能手机504还包含:语言信息提取部616,其从通信i/f614从服务器506接收到的数据中提取表示对方语言的信息;语音信号提取部618,其用于从通信i/f614接收到的数据中提取语音翻译后的语音信号;语音信号放大部620,其用于通过对该语音信号进行模拟变换、放大并驱动扬声器524,从而输出语音翻译后的语音;文本提取部622,其用于从通信i/f614从服务器506接收到的数据中提取语音翻译后的文本;以及显示控制部624,其用于在触摸面板显示器522显示该文本。
[0151]
图17是示出在图15所示的智能手机中设定语言的画面的示意图。参照图17,在触摸面板显示器522中显示的语言设定画面650中显示能够成为选择对象的八种语言660的名称,在其每一个中显示有表示是否选择的开关。如果使该开关向右移动,则选择该语言,如果使其向左移动,则该语言从选择中解除。在图17所示的例子中,日语、英语以及中文被选择,除此以外的语言未被选择。另外,关于基本信息设定画面以及默认语言设定画面等也能够通过同样的接口来实现。
[0152]
图18是图15所示的服务器506的功能的框图。参照图18,服务器506具有与图2所示的多语言语音处理装置100类似的结构,包含与图2所示的结构同样的选择语言存储部128、对方语言存储部122、语言设定部124、语言识别神经网络132、语言判定部134、语言选择部138、缓冲器140、语音数据选择部142、多语言语音翻译装置144以及语音信号合成装置146。
[0153]
多语言语音翻译处理服务器506还包含:通信装置680,其用于与智能手机504等终端装置进行通信;数据分离装置682,其用于从通信装置680接收到的请求语音翻译的数据
中分离出与选择语言相关的信息和与默认语言相关的信息,并分别将前者存放在选择语言存储部128,将后者存放在语言设定部124;以及发送信息生成装置684,其用于根据多语言语音翻译装置144输出的语音翻译后的文本以及语音信号合成装置146输出的语音翻译后的合成语音信号和语言选择部138输出的与由语言识别神经网络132以及语言判定部134识别出的语言相关的信息,生成向发送来语音翻译请求的智能手机504等终端装置发送的发送信息并提供给通信装置680。
[0154]
在此并未示出使图15所示的智能手机504作为语音翻译系统的客户端而发挥功能的程序的构造,但是简单地说,进行如下的处理。
[0155]
·
通过用于设定基本信息的程序,接受智能手机504的基本信息的登记并存储在sdram558等存储装置。该处理与语音翻译系统无关,是购买智能手机504的用户最初进行的基本的处理。基本信息包含与用户使用的语言相关的信息。
[0156]
·
通过用于设定语言的程序(该系统的客户端程序的一部分),接受成为处理对象的八种语言中的三种语言的选择,存储在sdram558等存储装置。同时,接受将选择的三种语言中的任何一个指定为默认语言的输入,将默认语言存储在存储装置。
[0157]
·
若语音翻译的程序启动,则读出选择语言存储部612中存储的语言信息、默认语言存储部606中存储的默认语言、对方语言存储部602中存储的对方语言,与所输入的语音一起生成请求语音翻译的发送数据,发送到服务器506。
[0158]
·
等待从服务器506发送来数据。
[0159]
·
如果从服务器506发送来数据,则提取语音信号进行播放。此外,提取语音翻译后的文本进行播放。进而,提取数据中包含的与被识别出的语音相关的信息,作为对方语言而存储在存储装置。
[0160]
·
以后,每当被输入语音时,执行如上那样的处理。
[0161]
图19是示出用于使计算机作为图18所示的多语言语音翻译系统而发挥功能的计算机程序的控制构造的流程图。
[0162]
图19所示的流程图具有与图8所示的流程图十分相似的构造。不同的点在于,代替图8的步骤352以及354而包含直到从智能手机504等客户端接收语音翻译请求为止进行待机的步骤720和响应于接收到语音翻译请求的情况,提取请求中包含的与默认语言、对方语言以及选择语言相关的信息并分别存储在给定的存储装置的步骤722,以及包含在图8的步骤366之后,将识别出的语言发送到客户端并使控制返回步骤720的步骤724。
[0163]
<动作>
[0164]
关于智能手机504的动作,从上述的程序的控制构造中是显而易见的。
[0165]
另一方面,关于服务器506的动作,如果比较图8和图19,则可以认为是明确的。应该注意的是,在本实施方式中,需要将服务器506识别出的语言发送到智能手机504的情况和相对于在图8的例子中使用附属于装置的输出来输出处理结果,在该服务器506中需要发送到智能手机504等客户端的情况。
[0166]
关于除此以外的点,服务器506的动作与第1实施方式的多语言语音处理装置100相同。因此,在该第2实施方式中,也与第1实施方式同样地,如果默认语言与识别结果的语言一致,则到得到语音翻译处理的结果为止的时间比以往短即可,即使不同,也能够以与以往相同的时间得到结果。
[0167]
语言识别的机构也与第1实施方式相同,能够得到同样的效果。
[0168]
进而,关于语言的设定,也与第1实施方式相同,因此与第1实施方式相同,具有即使简化语言识别神经网络132也能够提高语言识别的精度的效果。
[0169]
另外,在上述实施方式中,成为选择对象的语言为八种,从其中选择的语言为三种,但是本发明显然并不限定于这样的数字。如果成为选择对象的语言的数量比选择的语言的数量大且选择的语言为多个,则能够得到与上述实施方式同样的效果。
[0170]
此外,在上述实施方式中,默认语言仅为一个。但是,如果计算机的计算资源允许,则也可以将默认语言设为两个以上。即,接收语音,开始语言识别,同时以两个以上的默认语言对语音开始处理,在语言识别的结果明确的时间点,仅继续进行该语言的处理,中止基于其他语言的处理即可。与如专利文献1那样以全部的语言进行语音识别,以最终的分数来选择语音识别结果中的任意一个的情况相比,能够使必要的计算资源变小。另外,此时的多语言语音处理装置100等的结构即使从第1实施方式不进行那么大的变更也能够实现。只要进行存储多个默认语言、使向多语言语音翻译装置144包含的语音识别装置220、
…
、234(图4)等按语言区分的装置提供的选择信号能够指定它们中的多个装置、以及使数据分配部258能够向这些多个装置供给语音数据等变更即可。
[0171]
本次公开的实施方式仅仅是例示,本发明并不仅限于上述的实施方式。本发明的范围在参考发明的详细的说明的记载的基础上,由权利要求书的各权利要求表示,包含与在此记载的文字等同的意思以及范围内的全部变更。
[0172]
符号说明
[0173]
100:多语言语音处理装置;
[0174]
120、600:基本信息设定部;
[0175]
122、602:对方语言存储部;
[0176]
124、604:语言设定部;
[0177]
126、606:默认语言存储部;
[0178]
128、612:选择语言存储部;
[0179]
130:语音处理装置;
[0180]
132:语言识别神经网络;
[0181]
134:语言判定部;
[0182]
142:语音数据选择部;
[0183]
144:多语言语音翻译装置;
[0184]
146:语音信号合成装置;
[0185]
170:卷积层组;
[0186]
172:全连接层;
[0187]
202:概率标准化部;
[0188]
204:最大概率选择部;
[0189]
206:阈值比较部;
[0190]
220、222、224、226、228、230、232、234:语音识别装置;
[0191]
240、242、244、246、248、250、252、254:多语言翻译装置;
[0192]
262、264、266、268、270、272、274:自动翻译引擎;
[0193]
440:语言识别;
[0194]
442、460、480:语音识别;
[0195]
444、462、482:自动翻译;
[0196]
446、464、484:语音合成;
[0197]
500:语音翻译系统;
[0198]
506:多语言语音翻译处理服务器。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。