一种固定声源识别方法及装置
1.本技术要求于2020年5月14日提交中国专利局、申请号为202010404799.6、发明名称为“一种固定声源识别方法及装置”的中国专利申请的优先权。
技术领域
2.本技术涉及人工智能领域,更具体的说,涉及固定声源识别方法及装置。
背景技术:
3.随着技术的进步,智能语音识别功能被广泛的应用于电子设备中。例如,智能手机、智能音箱、智能电视和智能机器人等电子设备中均设置有智能语音识别功能。目前,在使用这一类电子设备的过程中,用户需要在安静的环境下发出语音指令,以使电子设备能够根据用户发出的语音指令来进行相应的操作。
4.如果用户所在的环境中存在噪音源,那么电子设备在接收到用户输入的语音指令的同时,还会接收到噪音源发出的噪音,使得用户输入的语音指令被噪音源发出的噪音所干扰,以使电子设备难以正确的识别出用户输入的语音指令对应的真实意图,从而导致电子设备识别语音的准确率降低。
5.因此,如何识别出电子设备周围环境下的噪音源,以避免电子设备受到环境噪音的干扰,成为目前亟须解决的技术问题。
技术实现要素:
6.本技术实施例提供一种固定声源识别方法及装置,以识别出电子设备周围环境中的固定声源。
7.第一方面,本技术实施例提供了一种固定声源识别方法,方法应用于电子设备中,方法包括:电子设备获取第一时间段内的第一音频流,第一音频流至少包括第一声音信号;所述电子设备在所述第一音频流中分离出所述第一声音信号;电子设备确定第一声音信号的第一属性信息;电子设备判断第一属性信息是否与固定声源库中的固定声源的属性信息相匹配,固定声源库中包括一个或多个固定声源对应的属性信息,固定声源为位于同一个位置且发出一种已知声音类型的声源;在第一属性信息与固定声源库中的固定声源的属性信息相匹配时,确定第一声音信号为固定声源发出的声音信号。
8.在第一方面中,电子设备能够将第一音频流中的第一声音信号的第一属性信息与预先生成的固定声源库进行匹配,如果第一属性信息与固定声源库中的固定声源的属性信息相匹配,说明第一声音信号为固定声源发出的声音信号,所以电子设备能够精准的识别出环境中存在的固定声源。
9.在第一方面的一种可能的实现方式中,电子设备包括麦克风阵列,电子设备获取第一时间段内的第一音频流,包括:电子设备利用麦克风阵列在第一时间段内采集电子设备所处环境中的声音生成第一音频流。
10.在第一方面的一种可能的实现方式中,第一属性信息包括第一声音信号的发声位
置、声音类型和发声时间。
11.在第一方面的一种可能的实现方式中,电子设备确定第一声音信号的第一属性信息,包括:电子设备利用麦克风阵列确定第一声音信号的发声位置;电子设备根据第一声音信号的声音特征确定第一声音信号的声音类型;电子设备确定第一声音信号的发声时间。
12.在第一方面的一种可能的实现方式中,第一属性信息包括第一声音信号的发声位置、声音内容和发声时间。
13.在第一方面的一种可能的实现方式中,电子设备确定第一声音信号的第一属性信息,包括:电子设备利用麦克风阵列确定第一声音信号的发声位置;电子设备根据第一声音信号的声音特征确定第一声音信号的声音内容;电子设备确定第一声音信号的发声时间。
14.在第一方面的一种可能的实现方式中,第一属性信息包括第一声音信号的发声位置、声音类型、声音内容和发声时间。
15.在第一方面的一种可能的实现方式中,电子设备确定第一声音信号的第一属性信息,包括:电子设备利用麦克风阵列确定第一声音信号的发声位置;电子设备根据第一声音信号的声音特征确定第一声音信号的声音类型;电子设备根据第一声音信号的声音特征确定第一声音信号的声音内容;电子设备确定第一声音信号的发声时间。
16.在第一方面的一种可能的实现方式中,电子设备根据第一声音信号的声音特征确定第一声音信号的声音类型,包括:电子设备确定声音事件库中是否存在与第一声音信号的声音特征对应的声音类型,声音事件库包括一种或多种声音类型;在声音事件库中存在与第一声音信号的声音特征对应的声音类型时,将第一声音信号的声音特征对应的声音类型确定为第一声音信号的声音类型;在声音事件库中不存在与第一声音信号的声音特征对应的声音类型时,电子设备向外部服务器发送第一网络请求,电子设备接收外部服务器发送的第一响应请求,第一网络请求包括第一声音信号的声音特征,第一响应请求包括第一声音信号的声音特征对应的声音类型;或者,在声音事件库中不存在与第一声音信号的声音特征对应的声音类型时,电子设备确定第一声音信号的声音特征在第一位置出现的次数是否大于第一阈值,第一位置为第一声音信号的发声位置,如果第一声音信号的声音特征在第一位置出现的次数大于第一阈值,确定第一声音信号的声音类型为已知声音类型。
17.在第一方面的一种可能的实现方式中,电子设备能够在声音事件库或外部服务器中获取与第一声音信号的声音特征对应的声音类型。
18.在第一方面的一种可能的实现方式中,方法还包括:电子设备获取第二时间段内的第二音频流,第二音频流至少包括第二声音信号;电子设备确定第二声音信号的第二属性信息;电子设备判断第二属性信息是否存在于固定声源库中,固定声源库中包括一个或多个固定声源对应的属性信息,固定声源为位于同一个位置且发出一种已知声音类型的声源;在第二属性信息不存在于固定声源库中时,将第二属性信息存储至固定声源库中。
19.其中,电子设备能够建立固定声源库,并且还可以不断的更新固定声源库中的内容。
20.第二方面,本技术实施例提供了电子设备,包括存储器和与存储器连接的处理器,存储器用于存储指令;处理器用于执行指令,以使计算机设备执行以下操作:获取第一时间段内的第一音频流,第一音频流至少包括第一声音信号;在第一音频流中分离出第一声音信号;确定第一声音信号的第一属性信息;判断第一属性信息是否与固定声源库中的固定
声源的属性信息相匹配,固定声源库中包括一个或多个固定声源对应的属性信息,固定声源为位于同一个位置且发出一种已知声音类型的声源;在第一属性信息与固定声源库中的固定声源的属性信息相匹配时,确定第一声音信号为固定声源发出的声音信号。
21.在第二方面的一种可能的实现方式中,电子设备包括麦克风阵列;处理器,具体用于利用麦克风阵列在第一时间段内采集电子设备所处环境中的声音生成第一音频流。
22.在第二方面的一种可能的实现方式中,第一属性信息包括第一声音信号的发声位置、声音类型和发声时间。
23.在第二方面的一种可能的实现方式中,处理器,具体用于利用麦克风阵列确定第一声音信号的发声位置;根据第一声音信号的声音特征确定第一声音信号的声音类型;确定第一声音信号的发声时间。
24.在第二方面的一种可能的实现方式中,第一属性信息包括第一声音信号的发声位置、声音内容和发声时间。
25.在第二方面的一种可能的实现方式中,处理器,具体用于利用麦克风阵列确定第一声音信号的发声位置;根据第一声音信号的声音特征确定第一声音信号的声音内容;确定第一声音信号的发声时间。
26.在第二方面的一种可能的实现方式中,第一属性信息包括第一声音信号的发声位置、声音类型、声音内容和发声时间。
27.在第二方面的一种可能的实现方式中,处理器,具体用于利用麦克风阵列确定第一声音信号的发声位置;根据第一声音信号的声音特征确定第一声音信号的声音类型;根据第一声音信号的声音特征确定第一声音信号的声音内容;确定第一声音信号的发声时间。
28.在第二方面的一种可能的实现方式中,处理器,具体用于确定声音事件库中是否存在与第一声音信号的声音特征对应的声音类型,声音事件库包括一种或多种声音类型;在声音事件库中存在与第一声音信号的声音特征对应的声音类型时,将第一声音信号的声音特征对应的声音类型确定为第一声音信号的声音类型;在声音事件库中不存在与第一声音信号的声音特征对应的声音类型时,向外部服务器发送第一网络请求,接收外部服务器发送的第一响应请求,第一网络请求包括第一声音信号的声音特征,第一响应请求包括第一声音信号的声音特征对应的声音类型;或者,在声音事件库中不存在与第一声音信号的声音特征对应的声音类型时,确定第一声音信号的声音特征在第一位置出现的次数是否大于第一阈值,第一位置为第一声音信号的发声位置,如果第一声音信号的声音特征在第一位置出现的次数大于第一阈值,确定第一声音信号的声音类型为已知声音类型。
29.在第二方面的一种可能的实现方式中,处理器,还用于获取第二时间段内的第二音频流,第二音频流至少包括第二声音信号;确定第二声音信号的第二属性信息;判断第二属性信息是否存在于固定声源库中,固定声源库中包括一个或多个固定声源对应的属性信息,固定声源为位于同一个位置且发出一种已知声音类型的声源;在第二属性信息不存在于固定声源库中时,将第二属性信息存储至固定声源库中。
30.第三方面,本技术实施例提供了一种电子设备,包括:获取模块,用于获取第一时间段内的第一音频流,第一音频流至少包括第一声音信号;处理模块,用于在第一音频流中分离出第一声音信号;确定第一声音信号的第一属性信息;判断第一属性信息是否与固定
声源库中的固定声源的属性信息相匹配,固定声源库中包括一个或多个固定声源对应的属性信息,固定声源为位于同一个位置且发出一种已知声音类型的声源;在第一属性信息与固定声源库中的固定声源的属性信息相匹配时,确定第一声音信号为固定声源发出的声音信号。
附图说明
31.图1所示的为本技术实施例提供的一种场景示意图;
32.图2所示的为图1中的3个声源的方位示意图;
33.图3所示的为本技术实施例提供的一种固定声源识别方法的流程图;
34.图4所示的为本技术实施例提供的另一种场景示意图;
35.图5所示的为图4中的2个声源的方位示意图;
36.图6所示的为本技术实施例提供的另一种固定声源识别方法的流程图;
37.图7所示的为本技术实施例提供的又一种场景示意图;
38.图8所示的为本技术实施例提供的又一种固定声源识别方法的流程图;
39.图9所示的为本技术实施例提供的又一种场景示意图;
40.图10所示的为图9中的1个声源的方位示意图;
41.图11所示的为本技术实施例提供的一种电子设备的示意图;
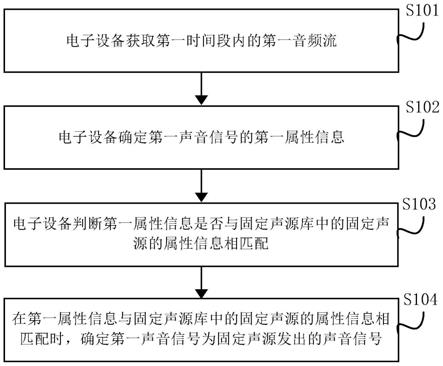
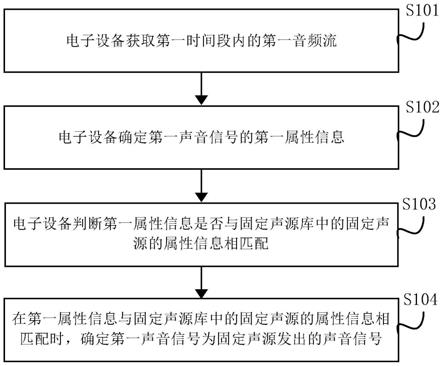
42.图12所示的为本技术实施例提供的又一种电子设备的示意图。
具体实施方式
43.请参见图1和图2所示,图1所示的为本技术实施例提供的一种场景示意图,图2所示的为图1中的3个声源的方位示意图。图1所示的场景示意图展示了智能音箱100、排油烟机200、空调300和用户400。其中,图1所示的智能音箱100能够执行本技术实施例提供的固定声源识别方法。
44.结合图1和图2所示,在一种可能的场景中,假设用户400的家中具有智能音箱100、排油烟机200和空调300等设备,而且智能音箱100、排油烟机200和空调300之间的相对位置如图1和图2所示。假设用户400想要让智能音箱100播放歌曲《abc》,用户400会向智能音箱100发出播放歌曲《abc》的语音指令,该语音指令为图1和图2中的声音信号c。
45.假设在用户400向智能音箱100发出声音信号c的过程中,排油烟机200处于工作状态,排油烟机200会向智能音箱100发出噪音,排油烟机200发出的噪音为图1和图2中的声音信号a。
46.假设在用户400向智能音箱100发出声音信号c的过程中,空调300处于工作状态,空调300会向智能音箱100发出噪音,空调300发出的噪音为图1和图2中的声音信号b。
47.此时,智能音箱100便可以利用本技术实施例提供的固定声源识别方法,来判断接收到的哪个声音信号属于固定声源。在智能音箱100确定了声音信号a和声音信号b属于固定声源以后,智能音箱100可以屏蔽接收到的声音信号a和声音信号b,仅识别接收到的声音信号c对应的语音指令,从而为用户播放歌曲《abc》。
48.在图1和图2所示的示例中,智能音箱100可以利用本技术实施例提供的固定声源识别方法,精准的识别出环境中存在的固定声源,并正确的识别出用户400输入的语音指令
对应的真实意图,从而提高了智能音箱100识别语音指令的准确率。
49.请参见图3所示,图3所示的为本技术实施例提供的一种固定声源识别方法的流程图。图3所示的固定声源识别方法可以应用于电子设备中,电子设备可以为智能手机、智能音箱、智能电视和智能机器人等具有智能语音识别功能的设备。图3所示的方法包括以下步骤s101至s104。
50.s101、电子设备获取第一时间段内的第一音频流,第一音频流至少包括第一声音信号。
51.其中,第一时间段指的是用户向电子设备输入语音指令的时间段。
52.在电子设备包括麦克风阵列时,电子设备可以利用麦克风阵列在第一时间段内采集电子设备所处环境中的声音生成第一音频流。
53.示例的,请结合图1和图2所示,假设第一音频流包括声音信号a、声音信号b和声音信号c,其中,第一声音信号为声音信号a。
54.在s101以后且在s102以前,电子设备还需要在第一音频流中分离出第一声音信号,具体的分离过程包括步骤a1和步骤a2:
55.步骤a1、电子设备对第一音频流进行预处理操作得到修正后的第一音频流。
56.其中,预处理操作包括变量的中心化处理、白化处理、主成分分析降维处理和时间滤波处理。预处理操作的目的在于降低第一音频流中的噪声。
57.步骤a2、对修正后的第一音频流进行独立成分分析(independent component correlation algorithm,ica)处理得到第一声音信号。
58.其中,独立成分分析处理用于在第一音频流中分离出第一声音信号,以便于后续步骤可以对第一声音信号进行相应的处理。
59.s102、电子设备确定第一声音信号的第一属性信息。
60.其中,关于电子设备确定第一声音信号的第一属性信息存在多种实现方式,下面介绍几种具体的实现方式。
61.第一种实现方式,如果第一属性信息包括第一声音信号的发声位置、声音类型和发声时间,那么电子设备确定第一声音信号的第一属性信息,可以包括以下步骤:电子设备利用麦克风阵列确定第一声音信号的发声位置;电子设备根据第一声音信号的声音特征确定第一声音信号的声音类型;电子设备确定第一声音信号的发声时间。
62.在第一种实现方式中,第一声音信号的发声位置指的是第一声音信号对应的声源相对于电子设备的发声位置。示例的,请结合图1和图2所示,假设第一声音信号为声音信号a,那么声音信号a的发声位置为声音信号a对应的声源1相对于智能音箱100的发声位置。如果认为智能音箱100所处的位置是中心点,那么声音信号a对应的声源1相对于智能音箱100的发声位置为140度。
63.在第一种实现方式中,第一声音信号的声音特征包括但不限于梅尔频率倒谱系数(mel frequency cepstrum coefficient,mfcc)。第一声音信号的声音类型指的是第一声音信号对应的声源所发出的声音。示例的,请结合图1和图2所示,假设第一声音信号为声音信号a,那么声音信号a的声音类型为排油烟机200的声音。
64.在第一种实现方式中,第一声音信号的发声时间为电子设备接收到第一声音信号的时间。示例的,请结合图1和图2所示,假设第一声音信号为声音信号a,那么声音信号a的
发声时间为2020年4月10日18点30分。
65.第二种实现方式,如果第一属性信息包括第一声音信号的发声位置、声音内容和发声时间,那么电子设备确定第一声音信号的第一属性信息,可以包括以下步骤:电子设备利用麦克风阵列确定第一声音信号的发声位置;电子设备根据第一声音信号的声音特征确定第一声音信号的声音内容;电子设备确定第一声音信号的发声时间。
66.在第二种实现方式中,第一声音信号的声音内容为语音内容。示例的,请结合图1和图2所示,假设第一声音信号为声音信号c,在用户400对着智能音箱100说“播放歌曲abc”时,会生成声音信号c在空气中传播,声音信号c的声音内容为用户400用嘴说的“播放歌曲abc”。
67.第三种实现方式,如果第一属性信息包括第一声音信号的发声位置、声音类型、声音内容和发声时间,那么电子设备确定第一声音信号的第一属性信息,可以包括以下步骤:电子设备利用麦克风阵列确定第一声音信号的发声位置;电子设备根据第一声音信号的声音特征确定第一声音信号的声音类型;电子设备根据第一声音信号的声音特征确定第一声音信号的声音内容;电子设备确定第一声音信号的发声时间。
68.当然,并不局限于上述提到的三种实现方式,还可以在第一属性信息中增加其他类型的信息。
69.在第一属性信息包含的内容不同时,可以识别不同类型的场景。
70.对于第一种实现方式而言,第一属性信息包括第一声音信号的发声位置、声音类型和发声时间。第一种实现方式的应用场景为:电子设备可以识别只发出一种声音类型的声源。
71.对于第二种实现方式而言,第一属性信息包括第一声音信号的发声位置、声音内容和发声时间。第二种实现方式的应用场景为:电子设备可以识别发出语音内容的声源。
72.对于第三种实现方式而言,第一属性信息包括第一声音信号的发声位置、声音类型、声音内容和发声时间。第三种实现方式的应用场景为:不仅可以识别只发出一种声音类型的声源,而且可以识别发出语音内容的声源。
73.s103、电子设备判断第一属性信息是否与固定声源库中的固定声源的属性信息相匹配。
74.其中,固定声源库中包括一个或多个固定声源的属性信息,固定声源为位于同一个位置且发出一种已知声音类型的声源。
75.示例的,请结合表1、图1和图2所示,表1所示的为固定声源库中的多个固定声源的属性信息,表1中的固定声源的属性信息为智能音箱100根据历史信息预先学习并生成的数据。关于表1的生成过程,后面的实施例会详细的介绍。
[0076][0077]
表1
[0078]
在表1、图1和图2的示例中,假设第一声音信号为声音信号a,智能音箱100确定声音信号a的属性信息包括声音信号a的发声位置、声音类型和发声时间。其中,声音信号a的发声位置为140度,声音信号a的声音类型为排油烟机200的声音,声音信号a的发声时间为2020年4月10日18点30分。
[0079]
在智能音箱100获取到声音信号a的属性信息以后,智能音箱100会判断声音信号a的属性信息是否与表1的固定声源库中的固定声源的属性信息相匹配。通过表1可以得知,声音信号a的属性信息与表1中的编号1对应的固定声源的属性信息相匹配,说明声音信号a对应的声源1为固定声源发出的声音信号。
[0080]
s104、在第一属性信息与固定声源库中的固定声源的属性信息相匹配时,确定第一声音信号为固定声源发出的声音信号。
[0081]
在图3所示的实施例中,电子设备能够将第一音频流中的第一声音信号的第一属性信息与预先生成的固定声源库进行匹配,如果第一属性信息与固定声源库中的固定声源的属性信息相匹配,说明第一声音信号为固定声源发出的声音信号,所以电子设备能够精准的识别出环境中存在的固定声源。
[0082]
请参见图4和图5所示,图4所示的为本技术实施例提供的另一种场景示意图,图5所示的为图4中的2个声源的方位示意图。图4所示的场景示意图展示了智能音箱100、用户400和智能电视600。其中,图4所示的智能音箱100能够执行本技术实施例提供的固定声源识别方法。
[0083]
结合图4和图5所示,在一种可能的场景中,假设用户400的家中具有智能音箱100和智能电视600等设备,而且智能音箱100和智能电视600之间的相对位置如图4和图5所示。假设用户400想要让智能音箱100播放歌曲《abc》,用户400会向智能音箱100发出播放歌曲《abc》的语音指令,该语音指令为图4和图5中的声音信号f。
[0084]
假设在用户400向智能音箱100发出声音信号f的过程中,智能电视600处于工作状态,智能电视600会向智能音箱100发出噪音,智能电视600发出的噪音为图4和图5中的声音信号e。
[0085]
此时,智能音箱100便可以利用图3所示的固定声源识别方法,来判断接收到的哪个声音信号属于固定声源。在智能音箱100确定了智能电视600属于固定声源以后,智能音箱100可以屏蔽接收到的声音信号e,仅识别接收到的声音信号f对应的语音指令,从而为用户播放歌曲《abc》。
[0086]
具体的,假设第一音频流包括声音信号e和声音信号f,其中,第一声音信号为声音
信号e。智能音箱100确定声音信号e的属性信息包括声音信号e的发声位置、声音内容和发声时间。假设声音信号e的发声位置为230度,声音信号e的声音内容为“欢迎收看def节目”,声音信号e的发声时间为18点30分。
[0087]
结合表2、图4和图5所示,表2所示的为固定声源库中的多个固定声源的属性信息,表2中的固定声源的属性信息为智能音箱100根据历史信息预先学习并生成的数据。
[0088][0089]
表2
[0090]
在表2、图4和图5的示例中,在智能音箱100获取到声音信号e的属性信息以后,智能音箱100会判断声音信号e的属性信息是否与表2所示的固定声源库中的固定声源的属性信息相匹配。通过表2可以得知,声音信号e的属性信息与表2中的编号1对应的固定声源的属性信息相匹配,说明声音信号e对应的声源5为固定声源发出的声音信号。
[0091]
请参见图6所示,图6所示的为本技术实施例提供的另一种固定声源识别方法的流程图。图6所示的方法为图3的s102中的细化步骤,具体为“电子设备根据第一声音信号的声音特征确定第一声音信号的声音类型”的细化步骤。图6所示的方法包括以下步骤s201至s203。
[0092]
s201、电子设备确定声音事件库中是否存在与第一声音信号的声音特征对应的声音类型。如果存在,执行步骤s202;如果不存在,执行步骤s203。
[0093]
其中,声音事件库包括一种或多种声音类型,声音事件库内的声音类型均为预先设置好的。
[0094]
示例的,请结合表3、图1和图2所示,表3所示的为声音事件库中的声音特征与声音类型的对应关系表。
[0095]
声音特征声音类型声音特征x排油烟机200的声音声音特征y空调300的声音
……
[0096]
表3
[0097]
在表3、图1和图2的示例中,假设第一声音信号为声音信号a,智能音箱100确定出声音信号a的声音特征x。然后,智能音箱100确定表3所示的声音事件库中是否存在与声音信号a的声音特征x对应的声音类型。通过表3可以得知,与声音信号a的声音特征x对应的声音类型为排油烟机200的声音。最后,智能音箱100可以确定声音信号a的声音特征x对应的声音类型为排油烟机200的声音。
[0098]
s202、将第一声音信号的声音特征对应的声音类型确定为第一声音信号的声音类型。
[0099]
s203、电子设备向外部服务器发送第一网络请求,电子设备接收外部服务器发送的第一响应请求。
[0100]
其中,第一网络请求包括第一声音信号的声音特征,第一响应请求包括第一声音信号的声音特征对应的声音类型。
[0101]
示例的,请参见图1和图7所示,图7所示的为本技术实施例提供的又一种场景示意图,智能音箱100可以通过互联网连接外部的服务器1000。假设在智能音箱100的声音事件库不存在与声音信号a的声音特征x对应的声音类型,那么智能音箱100会向服务器1000发送第一网络请求,第一网络请求包括声音信号a的声音特征x。在服务器1000接收到第一网络请求以后,服务器1000会在云存储器中查询到与声音信号a的声音特征x对应的声音类型为排油烟机200的声音,然后服务器1000会向智能音箱100发送第一响应请求,第一响应请求包括声音信号a的声音特征x对应的声音类型为排油烟机200的声音。在智能音箱100接收到服务器1000发送的第一响应请求以后,智能音箱100便可以得知声音信号a的声音特征x对应的声音类型为排油烟机200的声音。
[0102]
在图6所示的实施例中,电子设备能够在声音事件库或外部服务器中获取与第一声音信号的声音特征对应的声音类型。
[0103]
在图6所示的实施例中,还可以包括步骤s204(图6中未示出s204),s204可以替换s203构成另外一种实施方式。其中,s204可以包括以下步骤:电子设备确定第一声音信号的声音特征在第一位置出现的次数是否大于第一阈值,第一位置为第一声音信号的发声位置,如果第一声音信号的声音特征在第一位置出现的次数大于第一阈值,确定第一声音信号的声音类型为已知声音类型。另外,在确定第一声音信号的声音类型为已知声音类型以后,电子设备还可以将第一声音信号的声音特征与已知声音类型存储至声音事件库中。
[0104]
在s204中,第一位置为第一声音信号对应的声源相对于电子设备的发声位置,即第一位置为第一声音信号的发声位置。第一阈值为预先设定的次数,例如,可以预先将第一阈值设定为3次。已知声音类型指的是不确定具体的声音类型但却属于固定声源的声音类型。
[0105]
其中,如果第一声音信号的声音特征在第一位置出现的次数大于第一阈值,说明第一声音信号对应的声源属于固定声源,但由于第一声音信号的声音特征对应的声音类型未存储在声音事件库中,所以电子设备可以将第一声音信号的声音类型确定为已知声音类型。
[0106]
例如,电子设备可以将第一声音信号的声音类型确定为已知声音类型a,虽然电子设备不确定已知声音类型a属于哪种具体的声音类型,但是,电子设备可以确定已知声音类型a是经常能够接收到的一种声音类型。
[0107]
请参见图8所示,图8所示的为本技术实施例提供的又一种固定声源识别方法的流程图。图8所示的方法包括以下步骤s301至s304。
[0108]
s301、电子设备获取第二时间段内的第二音频流,第二音频流至少包括第二声音信号。
[0109]
其中,第二时间段指的是用户未向电子设备输入语音指令的一个时间段。在用户未向电子设备输入语音指令时,电子设备会实时的获取周围环境的固定声源发出的声音信号。第二音频流为在用户未向电子设备输入语音指令时,电子设备利用麦克风阵列在第二时间段内采集电子设备所处环境中的声音生成的音频流。
[0110]
示例的,请参见图9和图10所示,图9所示的为本技术实施例提供的又一种场景示
意图,图10所示的为图9中的1个声源的方位示意图。图9所示的场景示意图展示了智能音箱100和饮水机500。其中,智能音箱100在一段时间段内获取到第二音频流,第二音频流仅包括声音信号d,声音信号d为饮水机500发出的声音信号。
[0111]
s302、电子设备确定第二声音信号的第二属性信息。
[0112]
其中,图8的s302与图3的s102的执行过程是相同的,关于图8的s302的详细内容请参见图3的s102的详细描述。
[0113]
s303、电子设备判断第二属性信息是否存在于固定声源库中。
[0114]
其中,固定声源库中包括一个或多个固定声源对应的属性信息,固定声源为位于同一个位置且发出一种已知声音类型的声源。
[0115]
如果第二属性信息存在于固定声源库中,说明第二声音信号对应的声源的属性信息已经存储在固定声源库中。如果第二属性信息不存在于固定声源库中,说明第二声音信号对应的声源的属性信息未存储在固定声源库中,即第二声音信号对应的声源对于电子设备而言是新的固定声源。
[0116]
s304、在第二属性信息不存在于固定声源库中时,将第二属性信息存储至固定声源库中。
[0117]
示例的,请结合表1、图9和图10所示,假设第二声音信号为声音信号d,智能音箱100确定声音信号d的属性信息包括声音信号d的发声位置、声音类型和发声时间。其中,声音信号d的发声位置为180度,声音信号d的声音类型为饮水机500的声音,声音信号d的发声时间为2020年4月10日18点10分至18点13分。
[0118]
在智能音箱100获取到声音信号d的属性信息以后,智能音箱100会判断声音信号d的属性信息是否存在于固定声源库中。通过表1可以得知,声音信号d的属性信息并未存在于固定声源库中,所以智能音箱100会将声音信号d的属性信息存储至固定声源库中。
[0119]
请参见表4所示,表4为表1所示的固定声源库中存储了声音信号d的属性信息以后的状态。
[0120][0121]
表4
[0122]
在图8所示的实施例中,电子设备能够建立固定声源库,并且还可以不断的更新固定声源库中的内容。通过图8所示的方法,可以建立表1或表4所示的固定声源库。
[0123]
请参见图11所示,图11所示的为本技术实施例提供的一种电子设备的示意图。图
11所示的电子设备包括以下模块:
[0124]
获取模块11,用于获取第一时间段内的第一音频流,所述第一音频流至少包括第一声音信号。
[0125]
处理模块12,用于在第一音频流中分离出第一声音信号;确定所述第一声音信号的第一属性信息;判断所述第一属性信息是否与固定声源库中的固定声源的属性信息相匹配,所述固定声源库中包括一个或多个固定声源对应的属性信息,所述固定声源为位于同一个位置且发出一种已知声音类型的声源;在所述第一属性信息与所述固定声源库中的固定声源的属性信息相匹配时,确定所述第一声音信号为所述固定声源发出的声音信号。
[0126]
其中,获取模块11和处理模块12能够实现的附加功能、实现上述功能的更多细节请参考前面各个方法实施例中的描述,在这里不再重复。
[0127]
图11所描述的装置实施例仅仅是示意性的,例如,模块的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个模块或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。在本技术各个实施例中的各功能模块可以集成在一个处理模块中,也可以是各个模块单独物理存在,也可以两个或两个以上模块集成在一个模块中。
[0128]
请参见图12所示,图12所示的为本技术实施例提供的又一种电子设备的示意图。图12所示的电子设备包括处理器21和存储器22。
[0129]
在图12所示的实施例中,处理器21用于执行存储器22中存储的指令,以使电子设备执行以下操作:获取第一时间段内的第一音频流,所述第一音频流至少包括第一声音信号;在第一音频流中分离出第一声音信号;确定所述第一声音信号的第一属性信息;判断所述第一属性信息是否与固定声源库中的固定声源的属性信息相匹配,所述固定声源库中包括一个或多个固定声源对应的属性信息,所述固定声源为位于同一个位置且发出一种已知声音类型的声源;在所述第一属性信息与所述固定声源库中的固定声源的属性信息相匹配时,确定所述第一声音信号为所述固定声源发出的声音信号。
[0130]
处理器21是一个或多个cpu。可选的,该cpu为单核cpu或多核cpu。
[0131]
存储器22包括但不限于是随机存取存储器(random access memory,ram)、只读存储器(read only memory,rom)、可擦除可编程只读存储器(erasable programmable read-only memory,eprom或者快闪存储器)、快闪存储器、或光存储器等。存储器22中保存有操作系统的代码。
[0132]
可选地,电子设备还包括总线23,上述处理器21和存储器22通过总线23相互连接,也可以采用其他方式相互连接。
[0133]
本说明书中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于系统实施例而言,由于其基本相似于方法实施例,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
[0134]
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的范围。这样,倘若本技术的这些修改和变型属于本发明权利要求的范围之内,则本发明也意图包括这些改动和变型在内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。