1.本发明涉及无人车技术领域,特别是涉及一种基于深度强化学习的无人车的导航方法。
背景技术:
2.无人车的导航是各种避免障碍和达到目标位置的技术,然而在未知的环境中航行比已知的环境要困难得多,当环境未知时,机器人的运动极度地依赖于从传感器收集的数据以及算法的效率,以此来找到一条好的路径,位于移动机器人上的传感器将帮助检测障碍物,并在导航时绘制出环境地图,用来导航到目标位置。将深度强化学习方法的应用于导航问题的研究时,一个成功的训练模型高度依赖于训练集信息,所以不可避免的需要大量时间地进行训练数据的采集,如何有效的减少训练时间也成为了该领域的研究重点。
3.现有发明有以视觉作为输入的,有两个明显的缺点,1.受光照的影响较大,不同光照条件下图像识别效果差;2.相对于深度图像的输入,对环境的适应能力较差,从训练环境到另一个未知环境中的普适性差;所需训练时间较长。
技术实现要素:
4.本发明实施例提供一种基于深度强化学习的无人车的导航方法,以解决现有的无人车导航方法对环境的适应能力较差,从训练环境到另一个未知环境中的普适性差,所需训练时间较长的技术问题。
5.本发明的一方面,提供一种基于深度强化学习的无人车的导航方法,包括:
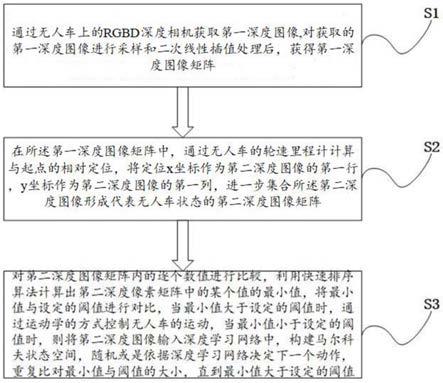
6.步骤s1,通过无人车上的rgbd深度相机获取depth深度图像,对获取的深度图像进行采样,获得分辨率为160*120的图像,再进行二次线性插值处理获得尺寸为80*80*1的深度图像,由所有尺寸为80*80*1的深度图像组成深度图像矩阵;
7.步骤s2,在深度图像矩阵中,通过无人车的轮速里程计计算与起点的相对定位,将定位x坐标作为第二深度图像的第一行,y坐标作为第二深度图像的第一列,进一步集合所述第二深度图像形成代表无人车状态的第二深度图像矩阵;
8.步骤s3,对第二深度图像矩阵内的逐个数值进行比较,利用快速排序算法计算出第二深度像素矩阵中的某个值的最小值,将最小值与设定的阈值进行对比,当最小值大于设定的阈值时,通过运动学的方式控制无人车的运动,当最小值小于设定的阈值时,则将第二深度图像输入深度学习网络中,构建马尔科夫状态空间,随机或是依据深度学习网络决定下一个动作,再次比对最小值与阈值的大小,直到最小值大于设定的阈值。
9.进一步,在步骤s1中,所述对获取的深度图像进行采样,获得分辨率为160*120的图像,再进行二次线性插值处理获得尺寸为80*80*1的深度图像具体过程为,利用高斯金字塔算法平滑处理图像,保留图像的所有边界特征的,通过梯度下采样获得分辨率160*120的图像,然后通过图像二次线性插值法处理降采样后的160*120图像,得到尺寸为80*80*1的深度图像。
10.进一步,
11.所述图像二次线性插值法处理降采样后的160*120图像,得到尺寸为80*80*1的深度图像具体过程为,根据以下公式对像素在图像矩阵中一个方向上进行线性插值,然后在另一个方向上进行线性插值:
[0012][0013]
其中,x为像素在图像矩阵中x轴的坐标系数,y为像素在图像矩阵中y轴的坐标系数。
[0014]
进一步在步骤s3中,所述设定的阈值根据实际车速进行调整,当无人车的转弯半径变大时,则将设定的阈值调大,当无人车的转弯半径变小时,则将设定的阈值调小;如果设定的阈值过大,则训练时间变长,如果设定的阈值过小,则与障碍物的碰撞。
[0015]
进一步,
[0016]
所述通过运动学约束的方式控制无人车的运动具体计算过程为根据以下公式进行计算:
[0017][0018]
其中,x
g
和y
g
为目标点在笛卡尔坐标系中的坐标,k为第一比例系数;
[0019]
ω=k
ω
(θ
g
θθ)
[0020]
其中,θ
g
为目标点的方向,θ为当前点的方向,θ为目标点和当前点的两个角度的差,k
ω
为第二比例系数。
[0021]
进一步
[0022]
在步骤s3中,所述深度学习网络为包括四层卷积层和两层全连接层的卷积神经网络,所述深度学习网络根据以下公式对策略函数π
θ
(s,a)进行梯度下降处理:
[0023][0024]
其中,θ为神经网络的参数,a(s)为评价策略梯度更新的优势函数,π为圆周率;
[0025]
所述深度学习网络根据以下公式对评价函数v(s,θ
v
)的进行梯度下降处理:
[0026][0027]
其中,r为对应的奖励值,γ为贪婪系数,v为状态价值函数,v为无人车的速度值。
[0028]
进一步,所述奖惩值r为靠近障碍物的惩罚值,单回合的最终的惩罚值为所有惩罚值之和,所述惩罚值具体包括碰撞惩罚值、直行或拐弯的惩罚值、驶向目标点的惩罚值、背离目标点的惩罚值、靠近障碍物的惩罚值。
[0029]
进一步,
[0030]
所述直行或拐弯的惩罚值根据以下公式计算:
[0031]
(0.1*v)/(|ω| 0.1)
[0032]
其中,v为无人车的速度取值,ω为无人车的角速度;
[0033]
所述靠近障碍物的惩罚值根据以下公式计算:
[0034]-1/(x-0.4)
[0035]
其中,x
·
为第二深度图像矩阵内的最小值。
[0036]
进一步,在步骤s3中,所述马尔科夫状态空间由多个数组组成,单个所述数组内至少包括无人车本次状态数据、无人车本次动作数据、无人车本次对应的奖励值数据、下无人车下次的状态数据。
[0037]
进一步,在步骤s1中,该方法还包括对深度图像进行预处理以降低图像中黑白相间的亮暗点噪声,所述预处理至少包括中值滤波、图像裁剪、快速行进修复。
[0038]
综上,实施本发明的实施例,具有如下的有益效果:
[0039]
本发明提供的基于深度强化学习的无人车的导航方法,结合运动学约束模型优化机器人在前期的状态空间构建,在相同的训练时间下,基于本文提出的训练模式构建的状态空间更加合理有效,能使网络学习效率更高,误差收敛的值更小,使得实现未知环境的避障效果更好;
[0040]
解决目前在未知的环境下无人车导航的问题,免去使用地图的端到端的运动决策的导航方式;,同时,使用本发明进行未知环境下的建图工作,免去人为的控制设备进行地图采集的麻烦,提高地图的采集效率。
附图说明
[0041]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,根据这些附图获得其他的附图仍属于本发明的范畴。
[0042]
图1为本发明提供的基于深度强化学习的无人车的导航方法的运动决策模型示意图。
[0043]
图2为本发明提供的基于深度强化学习的无人车的导航方法的主流程示意图。
[0044]
图3为本发明提供的基于深度强化学习的无人车的导航方法的逻辑示意图。
[0045]
图4为本发明提供的基于深度强化学习的无人车的导航方法的奖惩规则图表。
[0046]
图5为本发明提供的基于深度强化学习的无人车的导航方法的训练环境俯视示意图。
[0047]
图6为本发明提供的基于深度强化学习的无人车的导航方法的误差值曲线示意图。
具体实施方式
[0048]
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步地详细描述。
[0049]
如图1所示,本发明提供的基于深度强化学习的无人车的导航方法,提出基于最小景深信息的训练方式,结合运动学约束模型优化机器人在前期的状态空间构建,即通过人为引导的方式减少训练时间。在相同的训练时间下,基于本文提出的训练模式构建的状态空间更加合理有效,能使网络学习效率更高,误差收敛的值更小,使得实现未知环境的避障
效果更好;克服了dqn算法只能使机器人输出有限的执行动作的局限性,使得机器人可以在连续的速度与转角数值区间中输出执行动作。
[0050]
如图2所示,为本发明提供的一种基于深度强化学习的无人车的导航方法的一个实施例的示意图。在该实施例中,所述方法包括以下步骤:
[0051]
步骤s1,通过无人车上的rgbd深度相机获取depth深度图像,对获取的深度图像进行采样,获得分辨率为160*120的图像,再进行二次线性插值处理获得尺寸为80*80*1的深度图像,由所有尺寸为80*80*1的深度图像组成深度图像矩阵;
[0052]
具体一个实施例中,所述对获取的深度图像进行采样,获得分辨率为160*120的图像,再进行二次线性插值处理获得尺寸为80*80*1的深度图像具体过程为,利用高斯金字塔算法平滑处理图像,保留图像的所有边界特征值,通过梯度下采样获得分辨率160*120的图像;高斯金字塔是现有的算法,常用在图像下采样中,可以较好的保留图像的特征的前提下,平滑处理图像;这里的边界特征值为计算机视觉中的特征点,指图像中拐角、纹理剧烈变化等地方,具体是指像素矩阵中一阶导数较大的像素处,可以参考sift算子检测算法;再然后通过图像二次线性插值法处理降采样后的160*120图像,得到尺寸为80*80*1的深度图像作为观测到的状态,这个尺寸的越大在深度学习的时候越花费gpu内存,需要的学习时间也就越长,但是尺寸太小又无法充分保留图像中的边界信息,影响学习结果。在具体实施例中可根据电脑的gpu性能设定或改变此数值。
[0053]
具体的,通过图像二次线性插值法处理降采样后的160*120图像具体是根据以下公式对像素在图像矩阵中一个方向上进行线性插值,然后在另一个方向上进行线性插值:
[0054][0055]
其中,x为像素在图像矩阵中x轴的坐标系数,y为像素在图像矩阵中y轴的坐标系数。
[0056]
步骤s2,在深度图像矩阵中,通过无人车的轮速里程计计算与起点的相对定位,将定位x坐标作为第二深度图像的第一行,y坐标作为第二深度图像的第一列,进一步集合所述第二深度图像形成代表无人车状态的第二深度图像矩阵;建立坐标转换,将实际环境中的坐标与采集到的图像坐标相对应形成统一的坐标转换,根据无人车在实际空间的位置关系调整将相机的位置,转换到地图的全局坐标中去;最后,标定轮速里程计的定位精度,实现实际空间位置与图像内位置的定位统一,提高精准度。
[0057]
步骤s3,对第二深度图像矩阵内的逐个数值进行比较,利用快速排序算法计算出第二深度像素矩阵中的某个值的最小值,将最小值与设定的阈值进行对比,当最小值大于设定的阈值时,通过运动学的方式控制无人车的运动,当最小值小于设定的阈值时,则将第二深度图像输入深度学习网络中,构建马尔科夫状态空间,随机或是依据深度学习网络决定下一个动作,重复比对最小值与阈值的大小,直到最小值大于设定的阈值。
[0058]
具体一个实施例中,经过之前对图像的处理获取无人车状态,包括定位、depth深度图像。基于深度图像最小值的有选择训练模式提升模型的训练速度,如图3所示,通过逐个数值比较,计算第二深度像素矩阵中的某个值的最小值,此处使用已有成熟的算法,具体的方法可以参考快速排序算法等;当这个最小值大于之前设定的阈值,本实施例中具体为
0.7m,通过点到点运动学约束的方式控制机器人的运动,使机器人平滑地向目标点运动,在移动的过程中,一旦深度图像中的最小值小于了阈值,便将深度图像输入深度学习网络,构建马尔科夫状态空间,随机或是依据网络决定下一个动作,若是最小值再次大于阈值,再次以运动学约束机器人的下一个动作,如此循环往复;
[0059]
具体的,通过运动学约束的方式控制无人车的运动具体为,利用运动学约束的方式控制机器人从当前点平滑地向目标点运动,进一步根据以下公式对目标点到当前点的运动参数进行计算:
[0060][0061]
其中,x
g
和y
g
为目标点在笛卡尔坐标系中的坐标,k为第一比例系数,由于无人车平台的运动学参数不同,此参数用来进行标定,具体的数值可根据具体的应用情况进行调整和标定,v为无人车的运动速度;
[0062]
ω=k
ω
(θ
g
θθ)
[0063]
其中,θ
g
为目标点的方向,θ为当前点的方向,θ为目标点和当前点的两个角度的差,属于(-π,π]的一个值,k
ω
为第二比例系数,具体实验或实施例中标定,ω为无人车运动的角速度。
[0064]
具体的,最小深度阈值的设定,需要根据实际车速进行调整,如果无人车的转弯半径变大需要将此值适当调大,反之亦然;如果设置过大,则可能导致训练时间变长,如果设置过小,则可能导致与障碍物的碰撞,这也是后期检查时非常重要的地方。
[0065]
本实施例中,将第二深度图像输入深度学习网络中目的是为了用a3c算法进行学习,使用本发明建立的神经网络来进行策略函数π
θ
(s,a)与评价函数v(s,θ
v
)的梯度下降,以此来评价本发明中的决策是否合理;
[0066]
所述深度学习网络为包括四层卷积层和两层全连接层的卷积神经网络,神经网络的搭建层数、学习率、贪婪学习率等参数都需要进行控制;根据处理图像的尺寸,也就是之前所述80*80*1的深度图像,决定卷积神经网络的层数,搭建四层的卷积神经网络可以较好的提取各个层面的图像细节;学习率不能设置的太低或太高,太小学习时间会过长,太高会导致收敛到局部最优,根据实际的学习过程调整其为10-6
;
[0067]
所述深度学习网络根据以下公式对策略函数π
θ
(s,a)进行梯度下降处理:
[0068][0069]
其中,θ为神经网络的参数,a(s)为评价策略梯度更新的优势函数,π为圆周率;
[0070]
所述深度学习网络根据以下公式对评价函数v(s,θ
v
)的进行梯度下降处理:
[0071][0072]
其中,r为对应的奖励值,γ为贪婪系数,v为状态价值函数,v为无人车的速度值。
[0073]
本实施例中,在深度学习网络中进行学习时,引入奖罚值,也就是奖励值,具体的奖惩规则如图4所示,其中v为机器人的速度取值范围为[0.1,0.6],ω为机器人的角速度,取值范围为[-1,1],无人车直行运动时奖励值越大,而进行拐弯时的奖励值变小;当检测到
深度图像的最小值x
·
低于0.7m时,开始考虑靠近障碍物的奖惩值r,也就是靠近障碍物的惩罚值,单回合的最终的惩罚值为所有惩罚值之和,所述惩罚值具体包括碰撞惩罚值、直行或拐弯的惩罚值、驶向目标点的惩罚值、背离目标点的惩罚值、靠近障碍物的惩罚值。
[0074]
所述碰撞的惩罚值为-20,所述驶向目标点的惩罚值为4,所述背离目标点的惩罚值为-2,
[0075]
所述直行或拐弯的惩罚值根据以下公式计算:
[0076]
(0.1*v)/(|ω| 0.1)
[0077]
其中,v为无人车的速度取值,ω为无人车的角速度;
[0078]
所述靠近障碍物的惩罚值根据以下公式计算:
[0079]-1/(x-0.4)
[0080]
其中,x
·
为第二深度图像矩阵内的最小值。
[0081]
本实施例中,所述马尔科夫状态空间由多个数组组成,单个所述数组内至少包括无人车本次状态数据、无人车本次动作数据、无人车本次对应的奖励值数据、下无人车下次的状态数据,所述马尔科夫状态空间为模型训练提供数据集。
[0082]
本发明提供的这种基于深度强化学习的无人车的导航方法,为了使移动机器人获得更好的避障能力,需要设计的仿真训练环境应具有一定的复杂程度。环境中应包括狭窄的可通过路段、墙壁、带棱角的障碍、圆滑的障碍,如图5所示,这就需要在训练环境下进行模型的学习,用以积累足够的数据,可以提高实际应用中的决策速度,但实际导航过程中是否使用此训练策略都可以实现导航;这里所述训练策略具体为分别进行训练量为3万步左右和训练时间为6小时左右的积累训练,最终的误差值曲线对比如图6所示,水平方向的坐标轴代表迭代次数,竖直方向的坐标轴代表误差值,其中,1号曲线(直接训练)为2号曲线(本发明训练规则)使用中位值平均滤波后得到的结果。
[0083]
本实施例中,为了验证训练效果,可以在测试环境中指定7个点进行导航,通过运动学约束的方式使机器人依次经过1-7号位置,当机器人距离障碍物过近(小于0.6m)的时候,利用本发明的深度强化学习网络中的模型进行避障控制,实现对未知环境的探索,至少经过两种训练模式的路径规划能力。
[0084]
本发明提供的这种基于深度强化学习的无人车的导航方法,如果是在室内环境进行无人车导航,为了提高算法的效果及可行性,考虑到真实深度相机采集到的深度图像有一些的黑白相间的亮暗点噪声,故需要对步骤s1中的深度图像进行预处理,包括中值滤波、图像裁剪、快速行进修复算法等处理;然后,再进行步骤s2,建立坐标转换,将相机的位置,转换到地图的全局坐标中;标定轮速里程计的定位精度;将训练好的模型放到真实的无人车在真实的环境下进行导航。
[0085]
综上,实施本发明的实施例,具有如下的有益效果:
[0086]
本发明提供的基于深度强化学习的无人车的导航方法,结合运动学约束模型优化机器人在前期的状态空间构建,在相同的训练时间下,基于本文提出的训练模式构建的状态空间更加合理有效,能使网络学习效率更高,误差收敛的值更小,使得实现未知环境的避障效果更好;
[0087]
解决目前在未知的环境下无人车导航的问题,免去使用地图的端到端的运动决策的导航方式;,同时,使用本发明进行未知环境下的建图工作,免去人为的控制设备进行地
图采集的麻烦,提高地图的采集效率。
[0088]
以上所揭露的仅为本发明一种较佳实施例而已,当然不能以此来限定本发明之权利范围,因此依本发明权利要求所作的等同变化,仍属本发明所涵盖的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。