基于长短期记忆网络lstm模型的新冠病毒传播预测方法
技术领域
1.本发明属于病毒传播模型技术领域,具体是指基于长短期记忆网络lstm 模型的新冠病毒传播预测方法。
背景技术:
2.新冠病毒covid
‑
19爆发,由于缺乏对sars cov
‑
2的足够认识以及此 病毒超强的传染性,造成covid
‑
19爆发,以往对于传染病传播趋势的预测多 采用基于仓室模型的机理预测法,仓室模型诞生于19世纪,是以感染者数量 为研究对象,根据传播机理建立微分方程模型,通过分析最终得到感染者数量 与时间的函数关系,从此函数关系中可以得到疫情什么时间进入高爆发期,什 么时间能够到达峰值,什么时间可以进入稳定可控阶段,根据不同的传播机理 一般常用的仓室模型有sis,sir,sirs,seir等模型,此次疫情中,一些学者 采用sirs,seir模型进行探索性的预测,但是实际数据表明预测结果只有理 论意义,缺乏实际应用价值,为此提出基于长短期记忆网络lstm模型的新冠 病毒传播预测方法来解决上述问题。
技术实现要素:
3.针对上述情况,为克服现有技术的缺陷,本发明提供了一种基于长短期记忆网络lstm模型的新冠病毒传播预测方法,解决了现有技术中预测结果缺乏实际应用价值的问题。
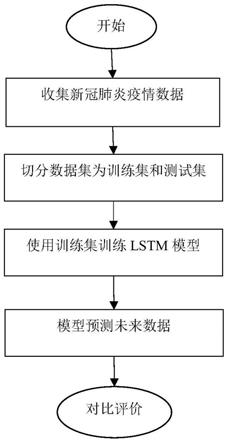
4.本发明的目的是提供一种基于长短期记忆网络lstm模型的新冠病毒传播预测方法,包括以下步骤:
5.步骤一:收集covid
‑
19病毒的传播数据,作为研究的基础数据,截取病毒爆发初期的数据得到数据集;
6.步骤二:分割数据集为训练数据集和测试数据集;
7.步骤三:将步骤2中得到的训练数据集训练长短期记忆网络lstm模型;
8.步骤四:利用步骤3中训练好得到的模型进行未来数据的预测,并与测试数据集中的真实数据做对比;
9.步骤五:量化预测误差,评价模型准确性。
10.进一步地,所述步骤一的具体步骤为:
11.步骤1.1,源获取新冠疫情数据,数据应包括新冠疫情累计确诊人数,累计死亡人数以及累计治愈人数的时间序列统计数据。由于目前新冠疫情已基本得到控制,可以选取疫情爆发初期的一个完整周期的数据作为数据集;
12.步骤1.2,通过数据集中的三个量计算出每日新增确诊人数,计算公式为
13.i
t
=c
t
‑
r
t
‑
d
t
14.其中,it代表每日新增确诊人数,ct代表每日累计确诊人数,rt代表每日累计治愈人数,dt代表每日累计死亡人数,得到新的数据集为包含日期和每日新增确诊人数i的时序
数据集。
15.进一步地,所述步骤二的具体步骤为:
16.步骤2.1,将数据集按7:3的比例进行分割;
17.步骤2.2,将分割好的数据前70%作为训练数据集,后30%作为测试数据集。由于lstm网络本身具有滞后性,因此在训练数据集和测试数据集的分界处,需要做一定的处理,具体方式为将测试数据集向前扩充3个数据,取值为时间步长减一。
18.进一步地,所述步骤三的具体步骤为:
19.步骤3.1,设置lstm网络的时间步长为3,据此在训练数据集上创建特征集和目标集,创建方式为,前3条数据为特征,第4条数据即为目标,从第一条数据依次往后循环上述操作,即可从训练数据集中得到特征集和目标集;
20.步骤3.2,损失函数采用均方误差(mse)。由于lstm模型自身可以很好的防止过拟合,将训练数据集训练若干个epochs,直到模型损失降低到1e
‑
4级别,得到该数据集的最优lstm预测模型。
21.进一步地,所述步骤四的具体步骤为:
22.步骤4.1,将测试数据集也采用步骤3.1的方式来创建测试数据集上的特征集和目标集;
23.步骤4.2,将测试数据集上的特征集带入到步骤3.2所得到的最优lstm模型,可以得到预测结果。将预测结果与测试数据集上的目标及作对比,评判预测的效果。
24.进一步地,所述步骤五的具体步骤为:
25.步骤5.1,我们用预测值和真实值之间的平均绝对误差值(mae)作为参考标准,mae的定义表达式如下:
[0026][0027]
其中,y
i
代表预测值,x
i
代表真实值,mae值越小,说明预测值与真实值之间的误差越小,也就是预测效果越好。
[0028]
采用上述结构本发明取得的有益效果如下:本发明基于长短期记忆网络 lstm模型,摒弃了传统仓式模型不能考虑到现实情况中各种因素对于感染率的影响,预测结果只具有理论意义,没有太大实际参考作用的弊端,lstm模型基于数据出发,预测精度高,并且lstm模型自带防止过拟合的功能,能很好的避免过拟合的情况,因此,lstm模型能较好的预测新冠病毒的未来传播趋势,对于新冠肺炎疫情的发展和防控具有深远的意义。
附图说明
[0029]
图1是本发明基于长短期记忆网络lstm模型的新冠病毒传播预测方法的步骤图。
[0030]
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。
具体实施方式
[0031]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例;基于
本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0032]
本发明的目的是提供一种基于长短期记忆网络lstm模型的新冠病毒传播预测方法,包括以下步骤:
[0033]
步骤一:收集covid
‑
19病毒的传播数据,作为研究的基础数据,截取病毒爆发初期的数据得到数据集;
[0034]
步骤二:分割数据集为训练数据集和测试数据集;
[0035]
步骤三:将步骤2中得到的训练数据集训练长短期记忆网络lstm模型;
[0036]
步骤四:利用步骤3中训练好得到的模型进行未来数据的预测,并与测试数据集中的真实数据做对比;
[0037]
步骤五:量化预测误差,评价模型准确性;
[0038]
进一步地,所述步骤一的具体步骤为:
[0039]
步骤1.1,源获取新冠疫情数据,数据应包括新冠疫情累计确诊人数,累计死亡人数以及累计治愈人数的时间序列统计数据。由于目前新冠疫情已基本得到控制,可以选取疫情爆发初期的一个完整周期的数据作为数据集。
[0040]
步骤1.2,通过数据集中的三个量计算出每日新增确诊人数,计算公式为
[0041]
i
t
=c
t
‑
r
t
‑
d
t
[0042]
其中,it代表每日新增确诊人数,ct代表每日累计确诊人数,rt代表每日累计治愈人数,dt代表每日累计死亡人数,得到新的数据集为包含日期和每日新增确诊人数i的时序数据集。
[0043]
进一步地,所述步骤二的具体步骤为:
[0044]
步骤2.1,将数据集按7:3的比例进行分割;
[0045]
步骤2.2,将分割好的数据前70%作为训练数据集,后30%作为测试数据集。由于lstm网络本身具有滞后性,因此在训练数据集和测试数据集的分界处,需要做一定的处理,具体方式为将测试数据集向前扩充3个数据,取值为时间步长减一。
[0046]
进一步地,所述步骤三的具体步骤为:
[0047]
步骤3.1,设置lstm网络的时间步长为3,据此在训练数据集上创建特征集和目标集,创建方式为,前3条数据为特征,第4条数据即为目标,从第一条数据依次往后循环上述操作,即可从训练数据集中得到特征集和目标集。
[0048]
步骤3.2,损失函数采用均方误差(mse)。由于lstm模型自身可以很好的防止过拟合,将训练数据集训练若干个epochs,直到模型损失降低到1e
‑
4级别,得到该数据集的最优lstm预测模型。
[0049]
进一步地,所述步骤四的具体步骤为:
[0050]
步骤4.1,将测试数据集也采用步骤3.1的方式来创建测试数据集上的特征集和目标集。
[0051]
步骤4.2,将测试数据集上的特征集带入到步骤3.2所得到的最优lstm模型,可以得到预测结果。将预测结果与测试数据集上的目标及作对比,评判预测的效果。
[0052]
进一步地,所述步骤五的具体步骤为:
[0053]
步骤5.1,我们用预测值和真实值之间的平均绝对误差值(mae)作为参考标准,mae
的定义表达式如下:
[0054][0055]
其中,y
i
代表预测值,x
i
代表真实值,mae值越小,说明预测值与真实值之间的误差越小,也就是预测效果越好。
[0056]
实施例1
[0057]
基于长短期记忆网络lstm模型的新冠病毒传播预测方法,包括以下步骤:
[0058]
步骤1.1,从约翰
·
霍普金斯大学系统科学与工程中心发布的全球疫情统计数据网站获取的1月22日至4月11日的新冠疫情数据,数据包括累计确诊人数,累计死亡人数以及累计治愈人数的时间序列统计数据。
[0059]
步骤1.2,通过新冠疫情数据集中的三个量计算出每日新增确诊人数,计算公式为
[0060]
i
t
=c
t
‑
r
t
‑
d
t
[0061]
其中it代表每日新增确诊人数,ct代表每日累计确诊人数,rt代表每日累计治愈人数,dt代表每日累计死亡人数。得到新的数据集为包含日期和每日新增确诊人数i的新冠疫情时间序列数据集;
[0062]
步骤2.1,数据集共81条数据,将数据集按7:3的比例进行分割。得到训练数据集为56条,测试数据集25条;
[0063]
步骤2.2,由于lstm网络本身具有滞后性,因此在训练数据集和测试数据集的分界处,需要做一定的处理,具体方式为将测试数据集向前扩充3个数据(取值为时间步长减一)。将测试数据集向前扩充3条数据为28条。此时,测试数据集与训练数据集有3条重复数据;
[0064]
步骤3.1,设置lstm网络的时间步长为3,据此在训练数据集上创建特征集和目标集,创建方式为,前3条数据为特征,第4条数据即为目标,从第一条数据依次往后循环上述操作,即可从训练数据集中得到特征集和目标集。此时,测试数据的特征集可以表示为train_x=[[0,1,2],[1,2,3],[2,3,4]
…
[53,54,55]],测试数据的目标集可以表示为train_y=[3,4,5,
…
56];
[0065]
步骤3.2,损失函数采用均方误差(mse)。由于lstm模型自身可以很好的防止过拟合,将训练数据集训练若干个epochs,直到模型损失降低到1e
‑
4级别,得到该数据集的最优lstm预测模型;
[0066]
步骤4.1,将测试数据集也采用步骤3.1的方式来创建测试数据集上的特征集和目标集。此时,测试数据的特征集可以表示为 test_x=[[54,55,56],[55,56,57],
…
[77,78,79]],测试数据的目标集可以表示为 test_y=[57,58,
…
80];
[0067]
步骤4.2,将测试数据集上的特征集带入到步骤3.2所得到的最优lstm模型,可以得到预测结果。将预测结果与测试数据集上的目标及作对比,评判预测的效果;
[0068]
步骤5.1,我们用预测值和真实值之间的平均绝对误差值(mae)作为参考标准,mae的定义表达式如下:
[0069][0070]
其中y
i
代表预测值,x
i
代表真实值,mae值越小,说明预测值与真实值之间的误差越
小,也就是预测效果越好。计算得到在本实例中预测值和真实值之间的mae为1125,对比改进的sis模型预测的mae值为14789和arima 模型预测的mae值为12187,lstm模型的预测效果有了显著的提升。
[0071]
本发明通过将lstm模型应用于新冠肺炎疫情的预测,摒弃了传统机理模型预测效果不具有实际意义的弊端,从数据本身出发,得到数据变化的规律,从而实现预测的目的,当训练数据量越大时,模型可以学习到更多的规律,也就可以达到更好的预测效果,满足实际状况的需求。
[0072]
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。
[0073]
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
[0074]
以上对本发明及其实施方式进行了描述,这种描述没有限制性,附图中所示的也只是本发明的实施方式之一,实际的结构并不局限于此。总而言之如果本领域的普通技术人员受其启示,在不脱离本发明创造宗旨的情况下,不经创造性的设计出与该技术方案相似的结构方式及实施例,均应属于本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。