1.本发明涉及本发明属于交通匝道控制和智能交通技术领域,具体涉及一种解 决快速道路瓶颈路段拥堵问题的匝道控制方法。
背景技术:
2.在早、晚高峰期间,随着通勤者的加入,城市快速道路的交通流量大幅度增 长,上、下匝道口的驶入、驶出量快速上升,交织区内的车辆换道行为加剧,当 上、下匝道口或交织区路段(简称潜在瓶颈)流量、换道等交通参数上升到某一 特定阈值时(一般为通行能力值),该潜在瓶颈会出现通行能力下降的情况,形 成交通瓶颈,造成小范围拥堵;随着后续车辆不断到达瓶颈路段,拥堵会逐渐向 上游蔓延,造成大范围的交通拥堵与延误,导致经济与能源的大量浪费。
3.随着信息技术的发展,我们已经能够获取高解析度的动态交通运行数据高速 公路交通控制向主动型、智能化方向发展,快速道路常见智能交通控制技术包括: 匝道控制、主线控制、车道管理、通道控制。匝道控制指运用交通信号、交通标 志及自动栏杆等交通控制设备调节进入高速道路主线车辆的数量,让快速道路系 统以最优效率运行,并且改善通过匝道进入主线车辆的汇合安全性。
技术实现要素:
4.发明目的:
5.本发明主要提出一种解决快速道路瓶颈路段拥堵问题的匝道控制方法,通过 匝道控制来解决快速道路交通拥堵问题,相较于传统控制策略具有着智能、准确、 实时、主动的优点。
6.一种解决快速道路瓶颈路段拥堵问题的匝道控制方法,包括如下步骤:
7.步骤(1)确定快速道路瓶颈路段,安置线圈检测器;
8.步骤(2)在匝道进出口处设置信号灯,深度强化学习通过接收状态集和动 作集,计算出q值,智能体做出动作即改变信号灯色,控制进入主线的车流,调 节主线及匝道的车流密度;
9.步骤(3)应用sumo仿真平台进行仿真路网的搭建:
10.定义路网信息、路网尺寸、交通控制、检测器布设、驾驶模型、交通需求、 仿真时长,或者通过在xml文件中指定点、路段、交叉区域等路网物理属性的坐 标及相应长度,自动生成所需的路网结构;
11.步骤(4)确定深度强化学习的三个指标,状态集、动作集、回报函数,制 定控制策略;
12.步骤(5)智能体每次执行动作都会使信号灯色持续为绿(红)15秒或30 秒,统计这15秒内或30秒内的流量信息获得相应的回报,并在第16秒或31 秒重新选择动作;
13.同时,在每次仿真的低需求情况进行预热,匝道控制策略不启动,智能体不 进行
学习,从高需求开始每30秒或15秒学习一次直至本次仿真结束;
14.步骤(6)利用python语言调用sumo仿真平台的traci接口启动仿真,随 后利用语句实时获取仿真中的数据,提取有用信息,进行控制策略的计算,得出 相应的控制策略结果后,再调用traci接口设置仿真中的信号灯灯色以实现控制 策略的应用。
15.进一步的,步骤(4)后增加一个步骤:
16.增加参与控制的匝道个数减少匝道排队回溢现象,状态集为几个关键位置的 车辆密度;动作集为各个匝道入口的放行流量;回报函数取决于匝道的协同控制 目标:利用多个匝道的协同控制,提高主线的通行效率,并保持各匝道车辆排队 长度的均衡,减小不同匝道上车辆排队时间的差异,回报函数包含两部分别为 r1和r2:
17.r1=(t
no-t
rm
)/t
no
[0018][0019]
r=(1-δ)
×
r1 δ
×
r2[0020]
式中:tno为匝道没有实行匝道协同控制的总通行时间;trm为匝道没有实 行匝道协同控制的总通行时间;ti为第i个匝道的总等待时间;为各匝道平均 的总等待时间;δ为权重系数。智能体的目标为最大化无限折扣后的累计奖赏值:
[0021][0022]
进一步的,步骤(1)中,线圈检测器的安装位置为快速道路瓶颈上游、瓶 颈路段、瓶颈下游以及上匝道、下匝道路段,通过实时检测获取快速道路的交通 流数据信息;
[0023]
交通流数据信息包括交通量、速度、占有率数据。
[0024]
进一步的,步骤(4)中,状态集为瓶颈密度、瓶颈上游密度、匝道密度以 及匝道信号灯灯色组成;动作集有两个,分别为使信号灯变绿或变红;回报函数 如下:
[0025]
r=q
merge
[0026]
其中qmerge为瓶颈路段的流量;
[0027]
控制策略分别以15秒或30秒为周期。
[0028]
有益效果:
[0029]
本发明基于实测交通流数据训练智能体掌握不同交通流运行状态下的最优 q值,据此在匝道瓶颈拥堵路段发布当前交通流状态下的最优信号控制,采集信 号控制后的交通流数据使智能体依据新的交通环境与数据持续学习,由思维参数 进行存储,本方法能有效减少快速道路路段内系统通行时间,提高行车速度,还 能不断依据实际应用后的信号控制与交通流数据持续学习最优策略。
附图说明
[0030]
图1为状态集示意图。
[0031]
图2为深度q学习算法。
[0032]
图3为30秒控制周期下系统旅行时间随训练次数的变化。
具体实施方式
[0033]
下面结合实施例及附图对本发明进行详细说明:
[0034]
本发明提供了一种解决快速道路拥堵问题的匝道控制方法,包括如下步骤:
[0035]
步骤(1):确定快速道路瓶颈路段,安置断面检测器于快速道路瓶颈上游、 瓶颈路段、瓶颈下游以及上匝道、下匝道路段,通过实时检测获取快速道路的交 通流数据信息(包括交通量、速度、占有率数据);
[0036]
断面检测器位置为距路网起点的距离,匝道检测器的位置为距匝道起点的距 离;
[0037]
步骤(2):在匝道进出口处设置信号灯,深度强化学习通过接收状态集和动 作集,由神经网络计算出q值,智能体做出动作即改变信号灯色,控制进入主线 的车流,调节主线及匝道的车流密度;
[0038]
由于交通状态是在变化中的,因此这个最优值也是动态的,没有固定的信号 配时,在需求高时严格限制匝道车流汇入,当需求降低时大量释放匝道车流,同 时能够捕捉到高峰时刻通行能力尚未达到的状态,释放匝道车辆。这一方面是深 度强化学习匝道控制策略和传统匝道控制策略最大的不同,也是它最大的优点。
[0039]
步骤(3):应用sumo仿真平台进行仿真路网的搭建:
[0040]
定义路网信息、路网尺寸、交通控制、检测器布设、驾驶模型、交通需求、 仿真时长,或者通过在xml文件中指定点、路段、交叉区域等路网物理属性的坐 标及相应长度,自动生成所需的路网结构;
[0041]
步骤(4):确定深度强化学习的三个指标,状态集、动作集、回报函数:
[0042]
状态集为瓶颈密度、瓶颈上游密度、匝道密度以及匝道信号灯灯色组成;
[0043]
因此交通流状态集中的每个元素是一个记录了瓶颈位置上下游及匝道的密 度的状态向量s,在自由流、拥堵状态和关键密度附近分别对交通流状态进行划 分,信号灯色由0(绿)或1(红)代表,为了减少记忆库的储存量,瓶颈密度、 瓶颈上游密度以及匝道密度均取整计算,同时为了不让信号灯频繁变换,信号灯 色也被用作状态集的特征之一。
[0044]
动作集有两个,分别为使信号灯变绿或变红;
[0045]
回报函数如下:
[0046]
r=q
merge
[0047]
其中qmerge为瓶颈路段的流量。
[0048]
考虑到在匝道控制场景中,信号灯变绿后,主线与匝道的车辆需要一定的 时间来完成合流步骤,使得学习过程无法在动作执行后立刻获得回报。因此,本 控制策略分别以15秒或30秒为周期。
[0049]
步骤(5):由于单个匝道排队空间有限,会出现匝道排队回溢现象,因此 可以增加匝道自身属性也可以增加参与控制的匝道个数。由于前种方法没有太大 改进空间而且改动较大,所以采取第二种。在协同控制中:状态集为几个关键位 置的车辆密度;动作集为各个匝道入口的放行流量;回报函数取决于匝道的协同 控制目标:利用多个匝道的协同控制,提高主线的通行效率,并保持各匝道车辆 排队长度的均衡,减小不同匝道上车辆排队时间的差异,回报函数包含两部分别 为r1和r2:
[0050]
r1=(t
no-t
rm
)/t
no
[0051][0052]
r=(1-δ)
×
r1 δ
×
r2[0053]
式中:t
no
为匝道没有实行匝道协同控制的总通行时间;t
rm
为匝道没有实行匝 道协同控制的总通行时间;t
i
为第i个匝道的总等待时间;为各匝道平均的总 等待时间;δ为权重系数。智能体的目标为最大化无限折扣后的累计奖赏值:
[0054][0055]
步骤(6):智能体每次执行动作都会使信号灯色持续为绿(红)15秒或30 秒,统计这15秒内或30秒内的流量信息获得相应的回报,并在第16秒或31 秒重新选择动作。同时,在每次仿真的低需求情况进行预热,匝道控制策略不启 动,智能体不进行学习,从高需求开始每30秒或15秒学习一次直至本次仿真结 束。由于学习间隔为15秒或30秒,每一次仿真会提供360个或720个记忆存储, 因此刚开始智能体一直处于存储记忆的状态,仿真全时段的总系统旅行时间波动 大;然后智能体开始逐渐学习,系统旅行时间出现下降趋势,最终达到整个仿真 过程的系统旅行时间最小值。由于深度强化学习在进行动作选择时存在随机性, 因此每一次的学习过程中,智能体寻找到最优解所需的仿真次数存在不确定性。 当随机选择的动作序列接近最优解时,智能体可以更快的向最优解方向进行梯度 下降。当智能体学习到接近于最优解附近区间时,可以终止智能体的学习过程, 存储神经网络参数以及记忆库。
[0056]
步骤(7)利用python语言调用sumo仿真平台的traci接口启动仿真,随后 利用语句实时获取仿真中的数据,提取有用信息,进行控制策略的计算,得出相 应的控制策略结果后,再调用traci接口设置仿真中的信号灯灯色以实现控制策 略的应用。
[0057]
下面利用仿真路进行验证:
[0058]
经过上匝道进入主线的车辆,经下匝道离开主线的车辆会在交织区内进行 变道、超车等操作以实现自己的出行目标。
[0059]
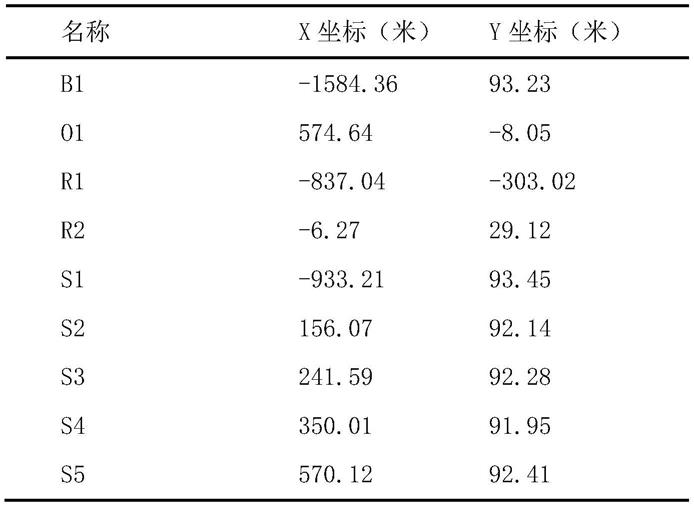
表1仿真路网节点信息
[0060][0061]
表2仿真路网路段信息
[0062][0063]
为了论证快速道路瓶颈路段拥堵产生的原因,利用搭建的路网与快速道路 仿真系统进行了仿真。线圈检测器被安置于快速道路瓶颈上游、瓶颈路段、瓶颈 下游以及上匝道、下匝道路段,各检测器的指标如表3所示:
[0064]
表3线圈检测器布设信息
[0065][0066]
主线检测器位置表示距路网起点的距离(m),匝道检测器为至匝道起点的距 离(m),
[0067]
其中merge2_1,merge2_2,merge2_3与merge2_4检测器为位于瓶颈处的检 测器。在仿真过程中,位于瓶颈处的检测器收集到的流量、速度以及占有率数据 对于交通流的研判具有十分重要的作用。
[0068]
前3600秒为低需求状态,车流平稳行驶;从第3600秒开始直至10800秒的 2小时内为高需求状态,主线流量上升,匝道流量大幅度上升,瓶颈路段内大量 换道、停车、排队行为出现,瓶颈路段呈现出过饱和的情况,拥堵产生并蔓延; 从10800秒开始,需求恢复低需求状态,拥堵开始逐渐消散直至14400秒仿真结 束。
[0069]
为了合理的体现出真实世界中的高速公路运行特性,以及跟驰换道行为,本 文采用了仿真内自带的krauss跟驰模型,部分参数采用了原始的设定,对于主 线车流、上匝道车流以及下匝道车流,其跟驰模型参数相同,在换道模型中赋予 了不同的参数值,以更好的模拟出由于换道行为导致的通行能力下降现象,跟驰 模型如表4所示,主线、上匝道、下
匝道车流的换道模型的参数如表5所示。
[0070]
表4跟驰模型参数
[0071][0072]
表5换道模型参数
[0073][0074]
其中lcstrategic代表车辆采取策略性换道行为的意图,值越大意图越强烈; lcspeedgain为车辆采取换道行为以获取更快的速度的意图,值越大意图越强烈; lclookheadleft为车辆观察前方左侧车道一定范围内的情况以判断是否有必要 换道,值越大观察距离越长;lccooperative为车辆配合其他车辆换道的遵从度, 值越大越配合其他车辆换道;lcassertive为车辆为采取换道行为可接受的最小 间隔参数,用以除最小间隔值,值越大可接受的最小间隔越小;lcpushy为车辆 采取换道行为压迫侧向车辆的意图,值越大意图越强烈。通过对换道模型参数的 设定,可以使主线车流更倾向于在前方发生拥堵时,提前进行策略性的判断,通 过观察前方情况,换道离开路肩车道选择外侧车道行驶;使上匝道的汇入车流在 进入瓶颈路段的时具有更强的变道意图,同时更注重自身的换道行为,不配合其 他的车辆的换道行为,更符合真实世界中的驾驶员心理。
[0075]
匝道控制对交通系统的影响机理:从交通系统的角度来说,系统的目标希 望获得最小的系统旅行时间对瓶颈路段的交通系统而言,一定时间范围内进入 瓶颈系统的车量与离开瓶颈系统的车流量代表着系统旅行时间。当匝道的需求大 时,施加过于严格的匝道控制策略会适得其反,匝道排队积压,匝道延误加重, 会同时降低系统的最大离开流率,造成系统层面的延误加大。因而,从系统的 角度而言,提升最大离开流率可以从根本上减少系统的总延误,然而在严格的匝 道控制策略下,最大离开流率下降,系统旅行时间不降反增。其中系统总旅行时 间(ttt)的计算方法如下:
[0076][0077]
其中n(k)为在k时刻路网中的总车辆数,n(k)的计算方法为:
[0078][0079]
其中n(0)为在仿真开始时路网中的总车辆数,q(к)为к时刻的系统总到 达车流量,s(к)为к时刻的系统总离开达车流量,因此通过结合公式与,可 以获得系统总旅行时间的计算公式:
[0080][0081]
综上所述,合理的匝道控制策略,可以减少匝道汇入车辆对于主线的干扰, 分时段的控制匝道车辆汇入主线,在保障主线通行效率的同时,能够同时避免匝 道排队车辆的大量延误,使系统旅行时间达到最优。
[0082]
基于检测器数据的深度q学习匝道控制策略,深度q学习算法如图2所示, 将控制策略嵌入仿真路网,进行控制效果仿真评价。状态集由瓶颈密度、瓶颈上 游密度、匝道密度以及匝道信号灯灯色组成,信号灯色由0(绿)或1(红)代 表,其中为了减少记忆库的储存量,瓶颈密度、瓶颈上游密度以及匝道密度均取 整计算,同时为了不让信号灯频繁变换,信号灯色也被当做状态的特征之一。
[0083]
动作集有两个,分别为为信号灯变绿或变红;回报函数如下:
[0084]
r=q
merge
ꢀꢀꢀ
(5-26)
[0085]
其中q
merge
为瓶颈路段的流量。考虑到在匝道控制中场景中,信号灯变绿后, 主线与匝道的车辆需要一定的时间来完成合流步骤,使得学习过程无法在动作执 行后立刻获得回报。因此,本控制策略分别以15秒或30秒为周期,每次执行动 作都会使信号灯色持续为绿(红)15秒或30秒,统计这15秒内或30秒内的流 量信息获得相应的回报,并在第16秒或31秒重新选择动作。同时,在每次仿真 的前3600秒(低需求情况)进行预热,匝道控制策略不启动,智能体不进行学 习,从第3601秒开始每30秒或15秒学习一次直至本次仿真仿真结束。
[0086]
路网中的线圈检测器可以实时采集路网中的交通量、速度、占有率数据,直 至仿真结束,随后重新开始下一次仿真,直至智能体通过自主学习找到最优策略。
[0087]
由于学习间隔为15秒或30秒,每一次仿真会提供360个或720个记忆存储, 因此在约前15次或30次仿真中智能体一直处于存储记忆的状态,仿真全时段的 总系统旅行时间波动大;从第16次或31次仿真开始,智能体开始逐渐学习,系 统旅行时间出现下降趋势,最终分别在第203和第159次仿真时达到整个仿真过 程的系统旅行时间最小值。由于深度强化学习在进行动作选择时存在随机性,因 此每一次的学习过程中,智能体寻找到最优解所需的仿真次数存在不确定性。当 随机选择的动作序列接近最优解时,智能体可以更快的向最优解方向进行梯度下 降。当智能体学习到接近于最优解附近区间时,可以终止智能体的学习过程,存 储神经网络参数以及记忆库,从而使得智能体能够利用获得最优解时的参数
对仿 真进行控制。
[0088]
基于上述讨论,30秒控制周期的第203次与15秒控制周期的第159次仿真 中的全时间段流量、速度、占有率等数据将被用于随后的交通流分析之中。
[0089]
斜累积流量曲线与alinea控制策略下的斜累积流量曲线相似,高峰时段开 始后并未出现明显、长时间的通行能力下降现象。当通行能力出现下降趋势时, 智能体能够对匝道餐区严格的控制。斜累积流量曲线在区间240左右开始下降, 不过主要是由于交通需求的下降(10800仿真秒开始的低需求情况),而并非是 由于匝道车流汇入而造成的通行能力下降。
[0090]
分别给出了无控制、基于检测器数据的深度强化学习匝道控制策略情况下的 占有率曲线与速度曲线。可以发现在未进行交通流分析,未对智能体提供任何交 通模型,智能体同样能够通过自主学习对匝道进行有效的控制,保障较高的通行 速度。
[0091]
比较了从第3600仿真秒开始,无控制与基于检测器数据的深度强化学习匝 道控制策略情况下的瓶颈输出流量。高峰期间,该策略通过智能体对交通装填的 自主研判,设定每个周期的控制信号灯色,控制匝道车辆的汇入,既保障了主线 的通行效率,又不会导致匝道排队的长时间积压,系统的整体输出流量维持在较 高水平(约3450辆/小时)。全仿真过程一共360个控制周期(10800秒),与反 馈式匝道控制策略相似,智能体同样能够识别出需求下降的情况,并在平峰期开 始后,大部分时间选择接近全绿的控制模式。
[0092]
从系统旅行时间的角度而言,基于检测器数据的深度强化学习匝道控制策略 可以实现匝道的流量的实时调节,在需求高时严格限制匝道车流汇入,当需求降 低时大量释放匝道车流,同时能够捕捉到高峰时刻通行能力尚未达到的状态,释 放匝道车辆,使系统旅行时间得到了大幅度的下降。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。