技术特征:
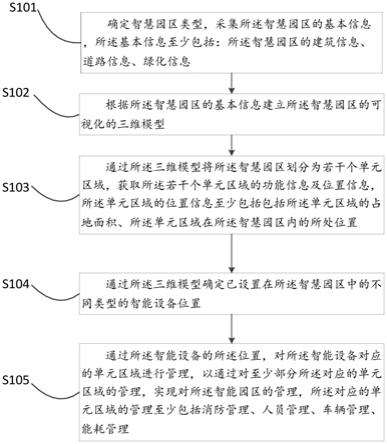
1.一种神经网络张量处理器的4d计算装置,其特征在于,包括片上存储单元、dat数据流处理单元、wt数据流处理单元、第一mac计算阵列单元、第二mac计算阵列单元和两个累加单元;所述片上存储单元,用于保存4d计算装置计算所需的dat数据和wt数据;所述dat数据流处理单元,用于接收来自所述片上存储单元的dat数据,并根据不同的计算模式整合该dat数据,最终形成后续计算所需的dat数据,并发送给所述第一mac计算阵列单元和所述第二mac计算阵列单元;所述wt数据流处理单元用于接收来自所述片上存储单元的wt数据,并根据不同的计算模式整合该wt数据,最终形成后续计算所需的wt数据,并发送给所述第一mac计算阵列单元和所述第二mac计算阵列单元;两所述累加单元分别用于实现第一mac计算阵列单元、第二mac计算阵列单元计算结果的累加操作,并将累加后的计算结果进行缓存、输出,用于后续计算。2.如权利要求1所述的神经网络张量处理器的4d计算装置,其特征在于:所述片上存储单元包括两个写接口、两个读接口和多个存储块,两个写接口分别用于写dat数据和wt数据,其中,dat数据的写地址、写数据和写使能信号由外部模块产生,wt数据的写地址、写数据和写使能信号由外部模块产生;所述读接口的位宽是m比特,所述写接口的位宽是m比特的x分之一;每个存储块包含x个宽度是m/x且深度为n的sram;每个存储块的容量是m*n比特,片上存储单元包含存储块的数量为y,片上存储单元总的存储容量为m*n*x*y比特;所述读接口的读地址由外部模块产生,该读接口的读数据分别发送给dat数据流处理单元和wt数据流处理单元。3.如权利要求2所述的神经网络张量处理器的4d计算装置,其特征在于:所述m等于1024,所述x等于2;所述n等于512。4.如权利要求2所述的神经网络张量处理器的4d计算装置,其特征在于:所述存储块的数量y为5或9。5.如权利要求1所述的神经网络张量处理器的4d计算装置,其特征在于:所述dat数据流处理单元、所述wt数据流处理单元接收来自外部的数据流控制指令,根据数据流控制指令的数据流控制信息,重新整合dat数据和wt数据,所述的整合工作包括:(1)产生dummy控制信号,替换片上存储单元中的原始数据为dummy数据,所述dummy数据是指值为0、数值表达范围内的最大负数或最大正数的数据;(2)根据外部控制信号选择输入数据中的部分数据;根据数据流控制指令中的数据有效位数信息选择输入数据中的部分数据;(4)根据数据流控制信息,对输入数据进行延时控制。6.如权利要求5所述的神经网络张量处理器的4d计算装置,其特征在于:所述对输入数据进行延时控制的方法为:将从片上存储单元获取的dat数据按16比特分成多个数据,并按顺序对数据进行0到n个时钟周期的延时操作;将从片上存储单元获取的wt数据按16比特分成多个数据,并按顺序对数据进行0到n个时钟周期的延时操作,所述n的取值与第一和第二mac计算阵列单元中的mac级联结构相关。7.如权利要求1所述的神经网络张量处理器的4d计算装置,其特征在于:所述第一mac计算阵列单元包括eep_4dcore_active、eep_4dcore_rt_out、k
‑
1组mac计算阵列和一组dw mac计算阵列;所述第二mac计算阵列单元包括eep_4dcore_active模块、eep_4dcore_rt_
out模块和k组mac计算阵列,其中k=(m/q)/(16/y),式中,m为读接口的位宽,q为mac计算阵列包含的mac乘法累加单元数,y为计算精度,单位为比特;所述eep_4dcore_active,用于将输入的dat数据和wt数据分配给mac计算阵列,其中,dat数据按照广播的方式发送给所有mac计算阵列,wt数据分别发送给mac计算阵列;所述mac计算阵列,用于实现乘法累加计算;所述dw mac计算阵列,用于实现乘法累加计算及执行并行乘法运算,其中的每个mac执行并行乘法计算时输出一个dw mac结果;所述eep_4dcore_rt_out模块,用于整合来自mac计算阵列的计算结果,并通过插入适当的流水线寄存器来调整神经网络张量处理器设计的时序性能。8.如权利要求7所述的神经网络张量处理器的4d计算装置,其特征在于:所述mac计算阵列由最大p组mac级联累加计算模块组成,mac计算阵列内部的p组mac级联累加计算模块通过两两相加的方式累加在一起,最终得到一个mac累加结果。9.如权利要求8所述的神经网络张量处理器的4d计算装置,其特征在于:每组mac级联累加计算模块内部包含t个级联累加计算树结构,并最终相加得到一个累加结果,该累加结果为该mac级联累加计算模块的输出。10.如权利要求9所述的神经网络张量处理器的4d计算装置,其特征在于:所述级联累加计算树结构至少包括单精度模式和混合精度模式中的一种,在单精度模式下,所述级联累加计算树结构包括w个级联的fp16 mac,每个fp16 mac由一个乘法器和一个加法器组成,其乘法器的输出作为其加法器的一个输入;w个fp16 mac逐级累加输出一个mac累加结果;在混合精度模式下,所述级联累加计算树结构包括w个级联的fp16/int8 mac和w个级联的int8 mac,当配置为混合精度计算时,所述w个fp16/int8 mac逐级累加输出一个fp16/int8结果;当配置为int8精度计算时,所述w个int8 mac逐级累加输出一个int8结果。11.如权利要求10所述的神经网络张量处理器的4d计算装置,其特征在于:所述mac计算阵列的参数关系为:p=q/(t*w)。12.如权利要求11所述的神经网络张量处理器的4d计算装置,其特征在于:q=64,t=2;w=4;p=8。13.如权利要求8所述的神经网络张量处理器的4d计算装置,其特征在于:所述dw mac计算阵列由r组dw mac级联累加计算模块和p
‑
r组mac级联累加计算模块组成,r<p,所述dw mac计算阵列执行乘法累加计算模式或并行计算模式,在乘法累加计算模式下,r组dw mac级联累加计算模块和p
‑
r组mac级联累加计算模块通过两两相加的方式累加在一起,最后各自得到的临时结果相加最终得到一个mac累加结果;在并行计算模式下,mac级联累加计算模块内的各mac不进行累加计算,而是执行并行乘法计算,每个mac输出一个乘法计算结果。14.如权利要求13所述的神经网络张量处理器的4d计算装置,其特征在于:p=8;r=4。15.如权利要求13所述的神经网络张量处理器的4d计算装置,其特征在于:每组dwmac级联累加计算模块内部包含t个dw级联累加计算树结构,所述dw级联累加计算树结构至少包括单精度模式和混合精度模式的一种,在单精度模式下,所述dw级联累加计算树结构包括w个级联的fp16 mac,每个fp16 mac由一个乘法器和一个加法器组成,其乘法器的输出作
为其加法器的一个输入;w个fp16 mac逐级累加输出一个mac累加结果;在混合精度模式下,所述dw级联累加计算树结构包括w个级联的fp16/int8 mac和w个级联的int8 mac,当配置为混合精度计算时,所述w个fp16/int8 mac逐级累加输出一个fp16/int8结果所述w个fp16/int8 mac执行并行乘法计算各输出一个fp16/int8的dw mac结果当配置为int8精度计算时,所述w个int8 mac逐级累加输出一个int8结果,所述w个int8 mac执行并行乘法运算各输出一个int8的dw mac结果。16.如权利要求15所述的神经网络张量处理器的4d计算装置,其特征在于:t=2;w=4。17.如权利要求1所述的神经网络张量处理器的4d计算装置,其特征在于:所述累加单元包含模块:eep_4dcore_calculator、eep_4dcore_assembly_ctrl和eep_4dcore_delicery_buffer,所述eep_4dcore_calculator为累加计算模块,内部包含16组acc累加模块,每个acc累加模块拥有一个深度为32的缓存,用于存储待计算的临时结果;所述eep_4dcore_assembly_ctrl用于控制累加计算模块的行为,所述行为包括何时开始、何时结束以及何时输出计算结果;所述eep_4dcore_delivery_buffer是一个深度为256的结果缓存,其内部保存所述eep_4dcore_calculator的计算结果,并等待外部装置从中取出计算结果从而进行下一步的计算操作。18.如权利要求17所述的神经网络张量处理器的4d计算装置,其特征在于:所述acc累加模块内部包含一个累加器和一个acc缓存,用于实现数据的累加计算,acc累加模块的控制由eep_4dcore_assembly_ctrl提供,所述eep_4dcore_assembly_ctrl根据数据流控制指令的信息,提供准确的累加开始和累加结束信号,从而指示acc累加模块何时从acc缓存读入临时结果用于累加,何时把临时结果存储到acc缓存中,以及何时输出最终结果。
技术总结
本发明公开了一种神经网络张量处理器的4D计算装置,包括片上存储单元、dat数据流处理单元、wt数据流处理单元、两个MAC计算阵列单元和两个累加单元;其中,片上存储单元用于保存4D计算装置计算所需的dat数据和wt数据;dat数据流处理单元用于接收来自所述片上存储单元的dat数据,并根据不同的计算模式整合该dat数据,最终形成后续计算所需的dat数据,并发送给两个MAC计算阵列单元;wt数据流处理单元用于接收来自所述片上存储单元的wt数据,并根据不同的计算模式整合该wt数据,最终形成后续计算所需的wt数据,并发送给两个MAC计算阵列单元;累加单元用于实现MAC计算阵列单元计算结果的累加操作,并将累加后的计算结果进行缓存、输出,用于后续计算。用于后续计算。用于后续计算。
技术研发人员:罗闳訚 何日辉 周志新
受保护的技术使用者:厦门壹普智慧科技有限公司
技术研发日:2021.08.19
技术公布日:2021/11/14
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。