一种用于神经网络张量处理器的4d计算装置
技术领域
1.本发明涉及神经网络张量处理器技术领域,尤其涉及一种用于神经网络张量处理器的4d计算装置。
背景技术:
2.传统处理器(包括cpu、gpu以及dsp等)采用基于指令的计算方法,其数据计算受指令的限制,通常具有较低的计算密度。也即在一定的数据位宽下(例如512位的数据位宽),通常需要大量的电路结构用于处理指令。最低效率如cpu,一条指令通常仅带一个32位或64位数据。
3.对于高性能计算的gpu,其通过多线程技术改善了计算密度,也即通过数量众多的计算线程来为计算资源提供数据,但其本质仍然是指令集架构,通过多线程可以提高计算密度,但仍然无法避免由指令相关电路带来的计算冗余。
技术实现要素:
4.本发明的目的在于提供一种用于神经网络张量处理器的4d计算装置,采用非指令集架构,无需传统处理器中指令相关电路结构,从而解决传统处理器中由指令带来的计算密度较低的问题。
5.为实现上述目的,本发明提供了一种如下技术方案:
6.一种神经网络张量处理器的4d计算装置,包括片上存储单元、dat数据流处理单元、wt数据流处理单元、第一mac计算阵列单元、第二mac计算阵列单元和两个累加单元;
7.所述片上存储单元,用于保存4d计算装置计算所需的dat数据和wt数据;
8.所述dat数据流处理单元,用于接收来自所述片上存储单元的dat数据,并根据不同的计算模式整合该dat数据,最终形成后续计算所需的dat数据,并发送给所述第一mac计算阵列单元和所述第二mac计算阵列单元;
9.所述wt数据流处理单元用于接收来自所述片上存储单元的wt数据,并根据不同的计算模式整合该wt数据,最终形成后续计算所需的wt数据,并发送给所述第一mac计算阵列单元和所述第二mac计算阵列单元;
10.两所述累加单元分别用于实现第一mac计算阵列单元、第二mac计算阵列单元计算结果的累加操作,并将累加后的计算结果进行缓存、输出,用于后续计算。
11.进一步地,所述片上存储单元包括两个写接口、两个读接口和多个存储块,两个写接口分别用于写dat数据和wt数据,其中,dat数据的写地址、写数据和写使能信号由外部模块产生,wt数据的写地址、写数据和写使能信号由外部模块产生;所述读接口的位宽是m比特,所述写接口的位宽是m比特的x分之一;每个存储块包含x个宽度是m/x且深度为n的sram;每个存储块的容量是m*n比特,片上存储单元包含存储块的数量为y,片上存储单元总的存储容量为m*n*x*y比特;所述读接口的读地址由外部模块产生,该读接口的读数据分别发送给dat数据流处理单元和wt数据流处理单元。
12.进一步地,所述m等于1024,所述x等于2;所述n等于512。
13.进一步地,所述存储块的数量y为5或9。
14.进一步地,所述dat数据流处理单元、所述wt数据流处理单元接收来自外部的数据流控制指令,根据数据流控制指令的数据流控制信息,重新整合dat数据和wt数据,所述的整合工作包括:(1)产生dummy控制信号,替换片上存储单元中的原始数据为dummy数据,所述dummy数据是指值为0、数值表达范围内的最大负数或最大正数的数据;(2)根据外部控制信号选择输入数据中的部分数据;根据数据流控制指令中的数据有效位数信息选择输入数据中的部分数据;(4)根据数据流控制信息,对输入数据进行延时控制。
15.进一步地,所述对输入数据进行延时控制的方法为:将从片上存储单元获取的dat数据按16比特分成多个数据,并按顺序对数据进行0到n个时钟周期的延时操作;将从片上存储单元获取的wt数据按16比特分成多个数据,并按顺序对数据进行0到n个时钟周期的延时操作,所述n的取值与第一和第二mac计算阵列单元中的mac级联结构相关。
16.进一步地,所述第一mac计算阵列单元包括eep_4dcore_active、eep_4dcore_rt_out、k
‑
1组mac计算阵列和一组dw mac计算阵列;所述第二mac计算阵列单元包括eep_4dcore_active模块、eep_4dcore_rt_out模块和k组mac计算阵列;其中k=(m/q)/(16/y),式中,m为读接口的位宽,q为mac计算阵列包含的mac乘法累加单元数,y为计算精度,单位为比特;
17.所述eep_4dcore_active,用于将输入的dat数据和wt数据分配给mac计算阵列,其中,dat数据按照广播的方式发送给所有mac计算阵列,wt数据分别发送给mac计算阵列;
18.所述mac计算阵列,用于实现乘法累加计算;
19.所述dw mac计算阵列,用于实现乘法累加计算及执行并行乘法运算,其中的每个mac执行并行乘法计算时输出一个dw mac结果;
20.所述eep_4dcore_rt_out模块,用于整合来自mac计算阵列的计算结果,并通过插入适当的流水线寄存器来调整神经网络张量处理器设计的时序性能。
21.进一步地,所述mac计算阵列由最大p组mac级联累加计算模块组成,mac计算阵列内部的p组mac级联累加计算模块通过两两相加的方式累加在一起,最终得到一个mac累加结果。
22.进一步地,每组mac级联累加计算模块内部包含t个级联累加计算树结构,并最终相加得到一个累加结果,该累加结果为该mac级联累加计算模块的输出。
23.进一步地,所述级联累加计算树结构至少包括单精度模式和混合精度模式中的一种,在单精度模式下,所述级联累加计算树结构包括w个级联的fp16 mac,每个fp16 mac由一个乘法器和一个加法器组成,其乘法器的输出作为其加法器的一个输入;w个fp16 mac逐级累加输出一个mac累加结果;在混合精度模式下,所述级联累加计算树结构包括w个级联的fp16/int8 mac和w个级联的int8 mac,当配置为混合精度计算时,所述w个fp16/int8 mac逐级累加输出一个fp16/int8结果;当配置为int8精度计算时,所述w个int8 mac逐级累加输出一个int8结果。
24.进一步地,所述mac计算阵列的参数关系为:p=q/(t*w)。
25.进一步地,q=64,t=2;w=4;p=8。
26.进一步地,所述dw mac计算阵列由r组dw mac级联累加计算模块和p
‑
r组mac级联
累加计算模块组成,r<p,
27.所述dw mac计算阵列执行乘法累加计算模式或并行计算模式,
28.在乘法累加计算模式下,r组dw mac级联累加计算模块和p
‑
r组mac级联累加计算模块通过两两相加的方式累加在一起,最后各自得到的临时结果相加最终得到一个mac累加结果;
29.在并行计算模式下,mac级联累加计算模块内的各mac不进行累加计算,而是执行并行乘法计算,每个mac输出一个乘法计算结果。
30.进一步地,p=8;r=4。
31.进一步地,每组dw mac级联累加计算模块内部包含t个dw级联累加计算树结构,所述dw级联累加计算树结构至少包括单精度模式和混合精度模式的一种在单精度模式下,所述dw级联累加计算树结构包括w个级联的fp16 mac,每个fp16 mac由一个乘法器和一个加法器组成,其乘法器的输出作为其加法器的一个输入;w个fp16 mac逐级累加输出一个mac累加结果;在混合精度模式下,所述dw级联累加计算树结构包括w个级联的fp16/int8 mac和w个级联的int8 mac,当配置为混合精度计算时所述w个fp16/int8mac逐级累加输出一个fp16/int8结果,所述w个fp16/int8 mac执行并行乘法计算各输出一个fp16/int8的dw mac结果;当配置为int8精度计算时,所述w个int8 mac逐级累加输出一个int8结果,所述w个int8 mac执行并行乘法运算各输出一个int8的dw mac结果。
32.进一步地,t=2,w=4。
33.进一步地,所述累加单元包含模块:eep_4dcore_calculator、eep_4dcore_assembly_ctrl和eep_4dcore_delivery_buffer,
34.所述eep_4dcore_calculator为累加计算模块,内部包含16组acc累加模块,每个acc累加模块拥有一个深度为32的缓存,用于存储待计算的临时结果;
35.所述eep_4dcore_assembly_ctrl用于控制累加计算模块的行为,所述行为包括何时开始、何时结束以及何时输出计算结果;
36.所述eep_4dcore_delivery_buffer是一个深度为256的结果缓存,其内部保存所述eep_4dcore_calculator的计算结果,并等待外部装置从中取出计算结果从而进行下一步的计算操作。
37.进一步地,所述acc累加模块内部包含一个累加器和一个acc缓存,用于实现数据的累加计算,acc累加模块的控制由eep_4dcore_assembly_ctrl提供,所述eep_4dcore_assembly_ctrl根据数据流控制指令的信息,提供准确的累加开始和累加结束信号,从而指示acc累加模块何时从acc缓存读入临时结果用于累加,以及何时把临时结果存储到acc缓存中,以及何时输出最终结果。
38.本发明和现有技术相比,其显著特点为:本发明实现一种用于神经网络张量处理器的4d计算结构,该4d计算结构采用数据流架构,计算过程无指令,无需传统处理器中指令相关电路结构,从而解决传统处理器中由指令带来的计算密度较低的问题,实现高效率和高密度的计算。
附图说明
39.图1是本发明的4d计算装置所涉及的神经网络张量处理器的数据流计算引擎;
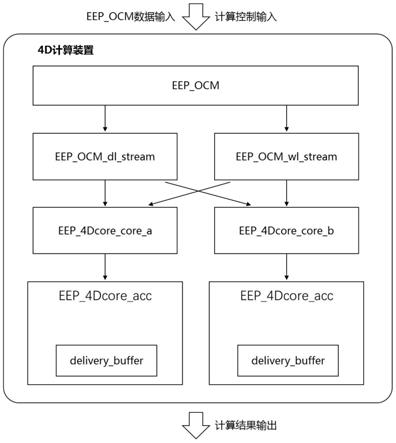
40.图2是本发明的4d计算装置的内部结构框图;
41.图3是本发明的eep_ocm模块的内部结构框图;
42.图4是本发明的eep_4dcore_core_a的内部结构框图;
43.图5是本发明的mac计算阵列的内部结构框图;
44.图6是本发明的级联累加计算树的内部结构框图;
45.图7是本发明的dw mac计算阵列的内部结构框图;
46.图8是本发明的dw级联累加计算树的内部结构框图;
47.图9是本发明的混合精度级联累加计算树的内部结构框图;
48.图10是本发明的eep_4dcore_core_b的内部结构框图;
49.图11是本发明的eep_4dcore_acc的内部结构框图;
50.图12是本发明的eep_4dcore_calculator的内部结构框图;
51.图13是本发明的acc累加模块的内部结构框图。
具体实施方式
52.为进一步说明各实施例,本发明提供有附图。这些附图为本发明揭露内容的一部分,其主要用以说明实施例,并可配合说明书的相关描述来解释实施例的运作原理。配合参考这些内容,本领域普通技术人员应能理解其他可能的实施方式以及本发明的优点。图中的组件并未按比例绘制,而类似的组件符号通常用来表示类似的组件。
53.现结合附图和具体实施方式对本发明进一步说明。
54.实施例1:
55.本发明的4d计算装置涉及前案专利(发明名称为:一种神经网络张量处理器,申请号为:202011421828.6)中的
″
4d计算模块
″
,如图1所示。
56.本实施例给出了4d计算装置的一种具体的内部结构。
57.4d计算装置内部拥有存储资源(eep_ocm)和计算资源(mac计算阵列),其主要作用是实现乘法累加计算,而相关计算控制信息,包括eep_ocm数据读地址和控制信息,则由外部的控制模块产生。上述计算控制信息以数据流序列的方式存在,以紧凑的方式(每个clock一个)进行传输,实现每个clock都进行的计算操作,最终达到较高的计算资源利用率。
58.在本实施例中,4d计算装置的内部结构如图2所示,其中,外部输入的是计算控制信息和eep_ocm数据输入,输出计算结果。
59.4d计算装置包含如下主要模块:
60.[0061][0062]
4d计算装置的基本计算流程如下:
[0063]
4d计算装置拥有16组fp16 mac乘法累加树结构或者32组int8 mac乘法累加树结构,每个时钟周期的计算可以获得16个fp16结果或者32个int8结果,该结果会由eep_4dcore_acc累加模块进行累加计算。经过多次的累加计算操作后,可以获得16个fp16最终结果或者32个int8最终结果。该最终结果将存储在delivery buffer中并且在1dcore模块就绪的情况下,把结果发送给1dcore用于后续计算。
[0064]
eep_ocm
[0065]
eep_ocm是用于为4d计算装置保存计算所需的dat数据和wt数据的片上存储器。在本实施例中,eep
‑
ocm拥有两个512比特数据宽度的写接口,分别用于写dat数据和wt数据。其中,dat数据的写地址、写数据和写使能信号由外部模块产生,wt数据的写地址、写数据和写使能信号由外部模块产生。
[0066]
eep
‑
ocm内部包含多个存储块bank,每个存储块bank包含两个宽度是512比特且深度为512比特的sram(容量为32kb),因此,每个存储块bank的存储器容量为64kb。eep
‑
ocm写接口的位宽是512比特,可通过特定的信号来选择bank内部的两个sram。
[0067]
eep
‑
ocm可以有多种容量配置。eep
‑
ocm的容量越大,计算时对数据和计算的拆分就越少(计算时,需要把本次计算所需的dat数据和wt数据缓存入ocm中,通常情况下,对于完整的一次计算,dat数据和wt数据的尺寸往往大于ocm的存储容量,因此需要把计算拆解为多个子计算,使得每次子计算的dat和wt数据可以存入eep
‑
ocm)。通常情况下,计算的拆分会引入一些计算冗余,该计算冗余会小量增加计算延迟。通常情况下,eep
‑
ocm的容量越大,相同算法的计算延迟会越低。然而,eep
‑
ocm的容量越大,芯片后端物理设计时的难度就会越大。因此,从经验上来讲,bank数为5或9为宜。也即典型情况下存储器容量为320kb或576kb。
[0068]
eep
‑
ocm拥有两个1024比特数据宽度的读接口,该读接口的读地址由外部模块产生,该读接口的读数据分别发送给eep_ocm_dl_stream和eep_ocm_wl_stream。
[0069]
以bank数为5,ocm的内部结构框图如图3所示。
[0070]
eep_ocm_dl_stream
[0071]
在本实施例中,eep_ocm_dl_stream从eep_ocm获取1024比特数据宽度的dat数据,该数据经过一定处理后,会分别发送给eep_4dcore_core_a和eep_4dcore_core_b。
[0072]
由于eep_4dcore_core_a/eep_4dcore_core_b内的mac计算阵列采用以4个mac为一组的级联方式实现乘法累加,并且每个mac的输出都直接连接到一个寄存器上。因此,需要在eep_ocm_dl_stream中对对应数据进行一定的延迟操作,从而匹配级联的乘法累加方式。
[0073]
eep_ocm_dl_stream把1024比特的输入数据按16比特分为64个数据,并按顺序对数据进行delay 0 clock,delay 1 clock,delay 2 clock以及delay 3 clock操作。
[0074]
eep_ocm_dl_stream会根据来自外部的控制信息产生dummy数据(固定为某个可以配置的值)。该dummy数据会代替来自ocm的数据输出(dummy数据输出过程中,ocm读数据是无效的)。另外,eep_ocm_dl_stream会根据来自外部的控制信息选择1024比特中的有效数据,该有效数据的选择与mac计算阵列的有效mac数以及计算模式相关。
[0075]
eep_ocm_dl_stream的核心功能是接收来自ocm的1024比特的计算数据,并接收来自外部的数据流控制指令。根据数据流控制信息,重新整合正确的1024比特的计算数据并发送给mac计算阵列。
[0076]
上述1024比特数据重新整合工作主要包括如下几个方面:
[0077]
(1)根据dummy控制信号,替换ocm原始数据为dummy数据;
[0078]
(2)在某些模式下(例如depthwise模式),根据外部控制信号选择1024比特中的一部分(以256比特为单位长度分为四部分);
[0079]
(3)根据控制指令中的数据有效位数信息选择1024比特中的一部分(以256比特为单位长度分为四部分);
[0080]
另外,除了1024比特的数据,同时发送给mac计算阵列的还有部分控制指令,从而实现后续mac阵列和acc累加计算的控制。
[0081]
eep_ocm_wl_stream
[0082]
在本实施例中,eep_ocm_wl_stream从eep_ocm获取1024比特的wt数据,该数据经过一定处理后,会分别发送给eep_4dcore_core_a和eep_4dcore_core_b。
[0083]
由于eep_4dcore_core_a/eep_4dcore_core_b内的mac计算阵列采用以4个mac为一组的级联方式实现乘法累加,并且每个mac的输出都直接连接到一个寄存器上。因此,需要在eep_ocm_wl_stream中对对应数据进行一定的延迟操作,从而匹配级联的乘法累加方式。
[0084]
eep_ocm_wl_stream把1024比特的wt数据按16比特分为64个数据,并按顺序对数据进行delay 0 clock,delay 1 clock,delay 2 clock以及delay 3 clock操作。
[0085]
eep_ocm_wl_stream的核心功能是接收来自ocm的1024比特参数,接收来自eep_4dcore_ctrl_wl的数据流控制指令。根据数据流控制信息,重新整合正确的1024比特参数并发送给eep_4dcore_core_a和eep_4dcore_core_b。
[0086]
上述1024比特重新整合工作主要包括如下几个方面:
[0087]
(1)某些模式下(例如depthwise模式),根据数据流控制信息选择1024比特中的一部分(以256比特分为四部分);
[0088]
(2)根据数据流控制指令中的数据有效位数信息对1024比特参数进行移位操作;另外,除了1024比特的数据,同时发送给mac计算阵列的还有mac阵列选择信号。
[0089]
eep_4dcore_core_a和eep_4dcore_core_b分别拥有8组mac计算阵列(总共16组)。计算时,参数分16个时钟周期分别发送参数数据给16组mac计算阵列,而这16组参数就通过特定信号来实现选择控制。
[0090]
eep_4dcore_core_a
[0091]
在本实施例中,如图4所示,eep_4dcore_core_a包含7组mac计算阵列和1组dw mac计算阵列,每组mac计算阵列由最大8组mac级联累加计算模块组成,每组mac级联累加计算模块由两列相加的级联累加计算树组成,每个级联累加计算包含4个fp16mac乘法累加器(单精度模式下)或者4个fp16/int8 mac乘法累加器 4个int8 mac乘法累加器(混合精度模式下)。
[0092]
如图4所示,eep_4dcore_core_a包含如下模块:
[0093]
(1)eep_4dcore_active,主要作用是把输入的dat数据和wt数据分配给mac计算阵列,其中,dat数据按照广播的方式发送给所有mac计算阵列,计算wt数据分别发送给mac计算阵列(每个时钟周期发送给一个mac计算阵列,由8比特信号选择更新的mac阵列计算阵列);
[0094]
(2)mac计算阵列,主要作用是实现乘法累加计算;
[0095]
(3)eep_4dcore_active,主要作用是整合来自mac计算阵列的计算结果,并通过插入适当的流水线寄存器来调整神经网络张量处理器设计的时序性能。
[0096]
mac计算阵列
[0097]
在本实施例中,eep_4dcore_core_a包含8组计算阵列,其中7组是mac计算阵列,其内部包含8组mac级联累加计算模块,mac计算阵列的具体内部结构框图如图5所示。
[0098]
mac计算阵列内部的8组mac级联累加计算模块通过两两相加的方式累加在一起,最终得到一个mac累加结果。
[0099]
每个mac级联累加计算模块内部包含两个级联累加计算树结构,并最终相加得到一个累加结果。
[0100]
每个级联累加计算树结构包含四个级联的mac,每个mac由一个乘法器和一个加法器组成,其内部结构如图6所示。
[0101]
为了得到更好的时序性能,级联累加计算树结构中的每个mac输出端都配有一个输出寄存器,因此,输入经过四个时钟周期可以得到级联累加计算结果,而为了适配这种级联流水的计算结构,相邻的输入数据必须经过delay从而匹配上述级联计算范式。
[0102]
有关eep
‑
tpu的mac数量:
[0103]
从上述结构框图可以看到,mac级联累加计算模块包含两个级联累加计算树,因此mac级联累加计算模块的mac数为8;mac计算阵列包含8个mac级联累加计算模块,因此mac计算阵列的mac数为64;eep
‑
tpu总共包括16组mac计算阵列,因此总的mac数为1024。如果使用混合精度计算,总的mac数量翻倍,为2048(包含1024个fp16/int8混用mac和1024个int8专用mac)。
[0104]
dw mac计算阵列
[0105]
在本实施例中,eep_4dcore_core_a包含8组计算阵列,其中1组是dw mac计算阵列
模块,其内部包含4组mac级联累加计算模块和4组dw mac级联累加计算模块,具体内部结构框图如图7所示。
[0106]
dw mac计算阵列的核心功能是在实现传统乘法累加计算的同时,实现并行乘法(不累加)计算,这种并行乘法(不累加)计算模式被定义为depthwise计算模式,被用于多种算子,包括dw卷积、pooling、argmax等。
[0107]
dw mac级联累加计算模块拥有两类输出,一类是和mac级联累加计算模块相同的mac累加输出(一个输出数据),该另一类是dw mac输出(8个输出数据)。4个dw mac级联累加计算模块总共输出32个输出数据。
[0108]
在并行计算模式下,dw mac级联累加计算模块内部的mac不进行累加计算,而是并行输出乘法计算结果(每个mac输出一个)。因此,1个dw mac级联累加计算模块内包含8个mac,输出8个dw mac结果。
[0109]
dw级联累加计算树的内部结构框图如图8所示。
[0110]
eep
‑
tpu拥有混合精度计算模式。在拥有混合精度计算模式的设计中,拥有两类mac:fp16/int8混用mac和int8 mac。其中,
[0111]
fp16/int8混用mac可同时计算fp16精度乘法累加和int8精度乘法累加,其输入和输出数据通路在不同精度下公用,因此数据位宽为可支持fp16计算的最大配置。int8计算下复用fp16的数据资源和计算资源。
[0112]
int8 mac为int8计算专用mac,该mac的输入和输出数据通道仅支持8bit计算,拥有int8计算下专用的数据资源和计算资源,不可被其他模式所复用。
[0113]
混合精度级联累加计算树可支持fp16计算和int8计算,其内部结构如图9所示。
[0114]
无论是fp16精度还是int8精度,参考eep_ocm相关模块的描述,ocm的输出数据带宽都是每个时钟周期1024bit,在fp16模式下,1024bit可被当作64个数据被mac计算阵列的64个mac所使用;在int8模式下,1024bit可被当作128个数据被mac计算阵列的64个fp16/int8混用mac和64个int8专用mac所使用。从而实现最大的mac计算利用率。
[0115]
eep_4dcore_core_b
[0116]
在本实施例中,eep_4dcore_core_b与eep_4dcore_core_a几乎完全相同,其包含8组mac计算阵列。与eep_4dcore_core_a不同的是,eep_4dcore_core_b不能实现并行乘法计算模式,没有dw mac计算阵列。
[0117]
eep_4dcore_core_b的内部结构框图如图10所示。
[0118]
内部具体结构及描述,可参考eep_4dcore_core_a模块相关描述。
[0119]
eep_4dcore__acc
[0120]
eep_4dcore_acc是mac计算结果累加模块。eep_4dcore_core_a和eep_4dcore_core_b拥有共16组mac计算阵列,通常情况下,16组mac计算阵列会计算得到16个乘法累加结果,而该16个乘法累加结果会输出给eep_4dcore_acc模块暂存,同时新输入的数据不断和暂存的旧数据进行累加,直到获得最终结果后输出。
[0121]
在本实施例中,如图11所示,eep_4dcore_acc主要包含如下模块:
[0122]
(1)eep_4dcore_calculator,累加计算模块,内部包含16组完全并行的acc累加模块,每个acc累加模块拥有一个深度为32的缓存,用于存储待计算的临时结果。
[0123]
(2)eep_4dcore_assembly_ctrl,控制累加计算模块的行为,包括何时开始、何时
结束以及何时输出计算结果等。
[0124]
(3)eep_4dcore_delivery_buffer是一个深度为256的结果缓存,其内部保存上述eep_4dcore_calculator的计算结果,并等待1dcore从中取出从而进行下一步的计算操作。eep_4dcore_delivery_buffer的主要目的是匹配4dcore和1dcore的计算速度,进一步提高运行性能。
[0125]
eep__4dcore_calculator
[0126]
在本实施例中,eep_4dcore_calculator内部包含16路完全并行的acc累加模块,其结构框图如图12所示。
[0127]
acc累加模块(eep_4dcore_calc_ef16_int8)内部包含一个累加器和一个acc缓存,其核心功能是实现数据的累加计算,其内部结构如图13所示。
[0128]
acc累加模块的控制由eep_4dcore_assembly_ctrl模块提供。eep_4dcore_assembly_ctrl的核心功能是根据数据流控制指令的信息,提供准确的累加开始和累加结束信号,从而指示累加器中何时从acc缓存读入临时结果用于累加,何时把临时结果存储到acc缓存中,以及何时输出最终结果。
[0129]
eep__4dcore__delivery_buffer
[0130]
eep_4dcore_delivery_buffer的核心功能是为4dcore提供一个可以缓存其计算结果的存储空间,该存储空间从宏观角度可以被看作一个fifo。该fifo的写端口来自4dcore,读端口来自外部输出模块。
[0131]
在本实施例中,eep_4dcore_delivery_buffer的存储空间深度为256,数据位宽为388比特,其读地址和写地址都由eep_4dcore_delivery_ctrl模块提供。
[0132]
eep_4dcore_delivery_ctrl模块的核心功能是维护存储fifo的读信号和写信号(包括写地址和写数据)。
[0133]
当读信号有效时,读数据直接发送给外部输出模块。
[0134]
以上给出了4d计算装置的一实施例。在实际应用中,基于本结构的4d计算装置,其模块、单元的数量及数据宽度等参数,可做如下结构性设定:
[0135]
(1)在本4d计算装置中,一个片上存储器对应一个dat数据流处理单元、一个wt数据流处理单元、n个mac计算阵列和n个累加模块。
[0136]
(2)片上存储器的读接口位宽是m比特,写接口位宽是m比特的x分之一,实施例1中选择的读接口位宽m=1024比特,写接口位宽为512比特。
[0137]
(3)mac计算阵列和累加模块的数量n与张量处理器的计算精度有关,如果计算精度是y比特,则n=m/(y*64),其中的64指mac计算阵列单元包含64个mac(如图7所示)可以处理64个y比特精度的数据。例如,对于m=1024,y=16(16位计算精度)的系统,n=1;对于m=1024,y=8(8位计算精度)的系统,n=2(本实施例使用8比特精度计算);对于m=1024,y=1的情况,n=16。
[0138]
(4)1个mac计算阵列与1个累加模块共同产生16个输出结果数据,n个mac计算阵列单元与n个累加单元共同产生16*n个输出结果数据。n越大计算并行度越高。因此,为了提高系统性能,可以采用读接口数据位宽更大的片上存储单元,或者使用更低的计算精度,如n=1比特。
[0139]
(5)mac级联累加计算模块包含t个级联累加计算树,本实施例中t=2。
[0140]
(6)级联累加计算树内的级联层级为w,包含w个mac,本实施例中w=4。
[0141]
(7)mac级联累加计算模块的mac数量为t*w,如前所述mac计算阵列的mac数量为q,因此,p=q/(t*w),本实施例中,选择q=64,t=2,w=4,因此p=8。
[0142]
(8)eep_ocm_wl_stream把1024比特的wt数据按16比特分为64个数据,并按顺序对数据进行delay 0 clock,delay 1 clock,delay 2 clock以及delay 3 clock操作。其中延时时钟数n的取值与图6中的级联累加计算树内的级联层级w有关,n=w
‑
1。本实施例的级联层级w为4,n为3。
[0143]
尽管结合优选实施方案具体展示和介绍了本发明,但所属领域的技术人员应该明白,在不脱离所附权利要求书所限定的本发明的精神和范围内,在形式上和细节上可以对本发明做出各种变化,均为本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。