1.本发明涉及一种资产状况监测方法以及被配置成执行这种方法的装置。
背景技术:
2.通常,在资产的调试阶段设置状况监测系统,并且在资产的操作期间很少更新状况监测系统。
3.传统地,状况监测系统紧密耦合到资产(例如工业机器人)。通常,状况监测逻辑在本地控制器上实现。然后,资产的状况以交通灯系统(traffic light system)或kpi的形式在本地呈现给用户。有时,这些kpi被传送到中央本地(central local),例如以用于报告生成或由服务工程师使用。
4.状况监测系统通常是静态的,并且不将它们自己随着时间的推移适于给定的状况,例如使用、环境、系统和/或应用。
技术实现要素:
5.因此,本发明的目的是要提供一种改进的资产状况监测方法。这个目的通过根据权利要求1所述的方法和根据权利要求12所述的装置来实现。
6.根据从属的专利权利要求,另外优选的实施例是明显的。
7.根据本发明,提供了一种利用自动异常检测的资产状况监测方法,包括以下步骤:接收来自资产队(asset fleet)的本地状况数据;识别所接收的本地状况数据中的至少一个异常;依赖于所确定的异常而识别新的潜在故障情况(failure case);依赖于所识别的潜在故障情况而确定特定状况模型,其中所述特定状况模型被配置用于预测所述新的潜在故障情况;以及向多个资产和/或向所述多个资产的数字模型提供所述特定状况模型。
8.优选地,资产队与多个资产相关。资产队优选地由资产的类型、消费者、资产队的应用、资产队的配置、资产队的操作周期、资产队的软件版本和/或不同资产的位置来确定。资产的数字模型与资产的数字孪生(digital twin)相关。由此,一个资产可以与多个资产队相关。
9.如本文使用的,术语“资产”包括适合于形成队的任何资产,优选为机器人,特别是工业机器人、马达、发电机和/或泵。
10.如本文使用的,术语“本地状况数据”与资产和/或资产队的状况和/或健康状态相关。另外,本地状况数据优选地包括资产和/或资产队的状况和/或健康状态的时间系列数据。
11.如本文使用的,术语“特定状况模型”也称为预测器(predictor),因为特定状况模型被配置用于预测新的(到这个时刻是未知的)潜在故障情况。例如,给定资产是工业机器人,则新的潜在故障与轴3中的新故障相关。特定状况模型然后被配置成预测这样的轴3中
的新故障以用于资产的状况监测。
12.优选地,将所接收的本地状况数据存储在云服务上。如果资产队被限制到一个位置,则云服务不是必要的,但是可以减轻来自本地基础设施的计算负担。然而,如果资产位于不同的位置处,特别是位于在不同的工厂处,则云服务的使用是优选的。虽然在资产的控制器中的本地执行受控制器的计算能力限制,但是原则上对于云中的相同资产可以并行地使用大量不同的算法。备选地,可以使用类似于云服务的本地设置,避免控制器上的计算负担。本地设置优选地包括用于资产队的专用控制器,例如工业pc。另外,可以组合本地设置和云服务用于混合方式。
13.优选地,依赖于例如资产类型、应用和/或客户的标准来确定特定状况模型。
14.优选地,所述异常利用异常检测方法识别,所述异常检测方法被配置用于处理时间系列数据和/或事件数据,进一步优选为自动编码器,特别是堆叠式自动编码器。优选地,识别所述异常包括利用故障情况来注释异常。由此,特定状况模型的确定被简化和/或结构化。
15.优选地,特定状况模型包括各自与特定故障情况相关的多个特定状况模型。然而,与不同的特定故障情况相关的单个特定状况模型也是可能的。
16.优选地,特定状况模型以监测的方式与资产一起使用,特别以用于监测报警和/或关键性能指标,优选地由技术专家来使用。此外,利用资产的数字模型,相同的特定状况模型用于预测性的维护(例如,如果预测到故障,则派遣技术专家)和/或用于根本原因分析。
17.优选地,完全自动地进行所接收的本地状况数据中的异常的识别。
18.通过迭代地识别新的潜在故障情况并确定用于预测新的潜在故障情况的特定状况模型,资产状况监测方法得到改进。换言之,资产状况监测方法从仅知道通用(generic)的潜在故障情况的标准化方法发展到能够识别资产特定的潜在故障情况的高度指定的方法。因此,资产状况监测方法不仅能够检测是否存在故障,而且还能够检测存在哪种特定故障情况。
19.与仅仅单个资产相比,使用来自资产队的本地状况数据,由此考虑整个资产系统(特别是整个生产线)提高了资产状况监测方法的可扩展性和/或可更新性。
20.优选地,接收本地状况数据包括自动地收集数据(特别是通过物理信号),和/或收集来自用户的资产反馈。
21.因此,提供了一种改进的资产状况监测方法。
22.在优选实施例中,所识别的异常与资产的非预期的状况数据相关。
23.换言之,如果现有的特定状况模型不能正确地预测资产的当前状况和/或健康状态,则检测到所接收的本地状况数据中的异常。因此,优选地,在可用的特定状况模型中的每一个上运行测试,并且将测试结果与所提供的本地状况数据进行比较。因此,可以利用依赖于资产队的本地状况数据的机器学习方法(特别是异常检测方法)和/或人工智能方法。
24.测试的结果优选地由时间计算(特别是每小时)来触发,每次执行特定状况监测循环时触发,作为流(特别是使用流分析计算引擎)来计算,和/或作为批(batch)(特别是用于按需分析)来计算。
25.优选地,识别至少一个异常包括运行通用测试。通用测试识别异常和/或将异常准备用于确定新的特定故障情况。
26.因此,提供了一种改进的资产状况监测方法。
27.在优选实施例中,识别所接收的状况数据中的异常包括对所识别的故障情况进行分类和/或隔离所识别的异常中的失效(fault)。
28.因此,提供了一种改进的资产状况监测方法。
29.在优选实施例中,本地状况数据包括资产部件特定数据,优选为资产部件的加速度,资产部件的速度,资产部件的位置,资产部件的扭矩,资产部件的振动,资产部件的电流,资产部件的电压,在资产部件的传动轴系(drive line)和/或传动系统中使用的摩擦的有效(live)估计,和/或资产部件的分配的材料流体和/或气体(特别是胶、线材、油漆和/或惰性气体)的流。
30.例如,资产是用于生产线的工业机器人,并且资产部件是机器人的轴的变速箱。
31.因此,提供了一种改进的资产状况监测方法。
32.在优选实施例中,该方法包括下列步骤:依赖于机器学习算法而验证特定状况模型,由此确定验证数据。
33.优选地,通过机器学习算法使用状况数据(特别是历史状况数据)来训练、开发、测试和/或验证特定状况模型。
34.优选地,所述机器学习算法包括(逻辑)回归、支持向量机和/或神经网络(特别是深度神经网络)。
35.优选地,所述机器学习算法包括迁移学习方法,其用于简化关于队配置的训练模型并且允许随时间推移的模型变换。
36.因此,提供了一种改进的资产状况监测方法。
37.在优选实施例中,该方法包括以下步骤:依赖于验证数据而调整特定状况模型,至少直到满足预定性能为止;并且如果特定状况模型满足预定性能,则将特定状况模型提供给多个资产和/或多个资产的数字模型。
38.如本文使用的,术语“性能”包括特定状况模型的可靠性和/或准确性。
39.优选地,使用边缘分析以用于调整特定状况模型,由此丢弃不必要的数据。
40.因此,提供了一种改进的资产状况监测方法。
41.在优选实施例中,所述方法包括以下步骤:从多个资产接收附加系统数据,其中所述附加系统数据潜在地对相应资产的状况具有影响;以及依赖于所确定的异常和所接收的系统数据而识别新的潜在故障情况。
42.因此,提供了一种改进的资产状况监测方法。
43.在优选实施例中,系统数据包括环境数据(优选地来自资产的马达、模拟工具、资产的模型)、传感器数据(优选为声音数据和/或温度数据)、资产设置和/或附加系统(优选为生产规划系统)。
44.因此,提供了一种改进的资产状况监测方法。
45.在优选实施例中,该方法包括下列步骤:将与不同的潜在故障情况相关的特定状况模型进行组合,以用于故障情况隔离。
46.例如,与第一轴相关的特定状况模型可以和与第二轴相关的特定状况模型相组合,所述第二轴类似于第一轴。因此,可以将资产的一个部件的潜在故障情况转移到资产的第二部件。
47.因此,提供了一种改进的资产状况监测方法。
48.在优选实施例中,特定状况模型代替现有的特定状况模型。
49.优选地,改进的特定状况模型代替现有的特定状况模型,以对特定状况模型进行迭代改进。然而,新确定的和/或新提供的特定状况模型也可以仅被添加到现有的特定状况模型以增加特定状况模型的种类。
50.因此,提供了一种改进的资产状况监测方法。
51.在优选实施例中,该方法包括以下步骤:指示资产的新的潜在故障情况和/或依赖于所提供的特定状况模型而预测资产的新的潜在故障情况。
52.优选地,所述指示和/或预测通过关键性能指标、热图和/或交通灯系统来可视化。
53.因此,提供了一种改进的资产状况监测方法。
54.根据方面,提供了一种装置,所述装置被配置用于执行如本文所述的方法。
55.根据方面,提供了一种计算机程序,所述计算机程序包括指令,当所述程序由计算机执行时,所述指令使所述计算机执行如本文所述的方法。
56.根据方面,提供了一种计算机可读数据载体,所述计算机可读数据载体将如本文所述的计算机程序存储在该计算机可读数据载体上。
57.本发明还涉及一种计算机程序产品,该计算机程序产品包括计算机程序代码,所述计算机程序代码用于控制装置的一个或多个处理器,所述装置适配于连接到通信网络和/或被配置成存储标准化配置表示,特别是包括计算机可读介质的计算机程序产品,该计算机可读介质在其中包含计算机程序代码。
附图说明
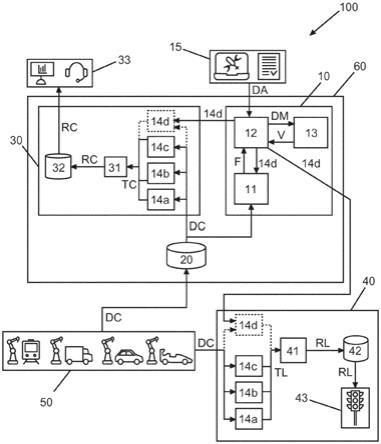
58.在下文中将参考在附图中图示的优选示范实施例更详细地解释本发明的主题,其中:图1示出了状况监测布置的示意图,所述状况监测布置具有装置,所述装置用于利用自动异常检测进行资产状况监测;图2示出了利用自动异常检测的资产状况监测方法的示意图;以及图3示出了分析单元的详细示意图。
59.附图中使用的参考符号及其含义以概要形式在参考符号列表中列出。原则上,附图中同一部件提供有相同的参考符号。
具体实施方式
60.优选地,功能模块和/或配置机制分别被实现为编程的软件模块或规程;然而,本领域的技术人员将理解,功能模块和/或配置机制可以全部或部分地在硬件中实现。
61.图1示出了状况监测布置100的示意图,所述状况监测布置100包括装置10、数据库20、云测试单元30、本地测试单元40、资产队50和云60。装置10、数据库和云测试单元30均在云60中运行。
62.在此示例中,资产队50包括多个资产,在此情况下是用于生产例如火车,卡车,汽车和/或运动汽车的不同交通工具的机器人。监测资产的状况并且由此确定与机器人中的每一个机器人的状况相关的本地状况数据dc。状况数据dc被收集在数据库20中。从那里,状
况数据20被提供给装置10。装置10包括分析单元11、模型单元12和机器学习单元13。分析单元11接收状况数据20。依赖于状况数据20,分析单元识别状况数据20中的异常a,并且依赖于异常a而识别新的潜在故障情况f。这种情况下的异常a与状况数据20中机器人的未知故障相关。通过分析异常a,特别是考虑到由相应机器人提供的附加系统数据(未示出)(在这种情况下是机器人的设置),可以识别故障情况f。例如,故障情况f描述了机器人的轴3的变速箱中的故障。
63.然后将新的潜在故障情况f提供给模型单元12,该模型单元12被配置用于依赖于所识别的新的潜在故障情况f来确定新的特定状况模型14d,其中新的特定状况模型14d被配置用于预测新的潜在故障情况f。然而,新的特定状况模型14d尚未满足预定的性能标准,换言之,特定状况模型14d没有以可靠或准确的方式预测机器人的故障和/或状况问题。因此,将与新的特定状况模型14d相关的模型数据dm提供给机器学习单元13。基于机器学习算法,机器学习单元13验证模型数据dm并且因此验证特定状况模型14d,由此确定验证数据v。基于验证数据v,模型单元12调整新的特定状况模型14d。重复模型单元12和机器学习单元13之间的该迭代,直到特定状况模型14确实满足预定的性能标准为止。该示例中的迭代过程由提供分析者数据da的分析者(analyst)15监督,以改进模型单元12与机器学习单元13之间的迭代过程。
64.然后将特定状况模型14返回提供到分析单元11。分析单元11由此通过新的方式被改进,以便基于状况数据dc来识别资产中的一个资产的特定故障。
65.另外,新的特定状况模型14d被提供给云测试单元30。云测试单元30包括已知的特定状况模型14b和14c以及通用状况模型14a。通用状况模型14a只能关于机器人做出是否预测到故障的声明,但是不能详细说明该故障。已知的特定模型14b和14c能够检测特定的故障,在这种情况下是与螺钉相关的故障和与机器人的马达相关的故障。基于状况数据dc,每个测试可以提供云测试结果tc,所述云测试结果tc由云失效隔离单元31来处理。云失效隔离单元31将云结果rc提供给云结果数据库32。从那里,可以将云结果rc提供给消费者33(在这种情况下是希望知道所处理的资产队50的状况故障的预测的客户端)。由于装置10已经提供了新的特定状况模型14d,因此还有可能预测特别是在机器人的轴3中的故障。
66.这同样适用于本地测试单元40。将新的特定状况模型14d提供给本地测试单元14。在这个应用中,状况模型14a、14b、14c和14d不试图预测机器人的未来的故障,而是指示特定机器人的已经存在的故障。因此,状况模型14a、14b、14c和14d提供本地测试结果tl,所述本地测试结果tl被提供给本地失效隔离单元41。本地失效隔离单元41将本地结果rl提供给本地结果数据库43。从那里,本地测试结果tl被提供给状况显示装置43(在这种情况下采取交通灯的形式),指示机器人的故障。基于新的状况模型14d,可以检测并指示特定机器人的特别是在轴3中的故障。
67.图2示出了利用自动异常检测的资产状况监测方法的示意图。在步骤s10中,从资产的队50接收本地状况数据dc。在步骤s20中,在所接收的状况数据dc中识别异常a。在步骤s30中,依赖于所识别的异常a来识别新的潜在故障情况f。在步骤s40中,依赖于所识别的新的潜在故障情况f来确定特定状况模型14d,其中特定状况模型14d被配置用于预测新的潜在故障情况f。在步骤s50中,将特定状况模型14d提供给多个资产和/或多个资产的数字模型。
68.图3示出了分析单元11的详细示意图。分析单元11包括异常识别单元16和故障情况识别单元17。在该示例中,分析单元11已经知道通用状况模型14a和特定状况模型14b和14c,如图1的云测试单元30中所述。基于状况模型14a、14b、14c,将测试数据dt提供给识别单元16。如果通用状况模型14a提供指示故障的测试数据dt,但特定状况模型14b、14c不指示故障,则确定异常a。在这种情况下,在机器人的轴3中存在故障,这不能通过通用状况模型14a和特定状况模型14b、14c来识别。基于异常a和测试数据dt,故障情况识别单元17识别新的故障情况f。基于故障情况f,模型单元12确定新的特定状况模型14d,然后将所述新的特定状况模型14d返回提供到分析单元11。模型单元12的分析过程由分析者15监督。分析者15参与该分析过程并且将分析者数据da提供给模型单元12。模型单元12因此基于故障情况f和分析者数据da来确定新的特定状况模型14d。因此,在将来,可以由分析单元11基于新的特定状况模型14d来识别机器人的轴3中的故障。因此,能够迭代改进用于状况监测的装置。
69.参考符号列表10 装置11 分析单元12 模型单元13 机器学习单元14a 通用状况模型14b 特定状况模型14c 特定状况模型14d 新的特定状况模型15 分析者16 异常识别单元17 故障情况识别单元20 数据库30 云测试单元31 云失效隔离单元32 云结果数据库33 消费者40 本地测试单元41 本地失效隔离单元42 本地结果数据库43 状况显示装置50 资产队60 云100 状况监测布置dc 状况数据v 验证数据dm 模型数据da 分析师数据
a 异常f 故障情况tc 云测试结果rl 云结果tl 本地测试结果rl 本地结果td 测试数据。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。