技术特征:
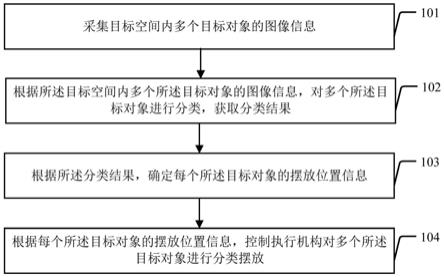
1.一种基于注意力的连续手语语句识别方法,其特征在于,步骤如下:步骤1、采集m个彩色视频模态的手语视频,100<m<10000,使用tv
‑
l1算法对彩色视频模态的手语视频的光流信息进行提取,并形成帧数相同的光流图像序列,提供光流视频模态的手语视频;采用cnn对上述两种模态的每个手语视频的关键帧分别进行提取,对应得到像素大小为h
×
b、关键帧均匀采样至n帧的两种模态的关键帧手语视频,10<n<100,在得到的两种模态的关键帧手语视频中各选取m个相对应的视频构成训练集,100<m<m,两种模态的关键帧手语视频中剩余的视频构成测试集;步骤2、使用两个相同结构的i3d网络分别提取两种模态的关键帧手语视频的关键帧序列的时空特征,对应得到测试集对应的关键帧序列的时空特征和训练集对应的关键帧序列的时空特征;步骤3、构建基于注意力的连续手语语句识别模型:基于注意力的连续手语语句识别模型包括基于注意力的双模态编码网络和基于ctc的解码网络;基于注意力的双模态编码网络分为两路且结构相同,每路均包括blstm与注意力网络相结合的模型;基于ctc的解码网络包括lstm、内在映射层和ctc损失层;步骤4、将训练集对应的关键帧序列的时空特征送入基于注意力的双模态编码网络,通过blstm提取高层时空特征,并利用注意力网络为其分配注意力,得到分配过注意力权重的融合特征序列;基于ctc的解码网络使用lstm对基于注意力的双模态解码网络输出的融合特征序列进行时序建模,再通过内在映射层生成每个视频关键帧的概率分布,最后使用ctc损失层根据概率分布计算得到实际语义的后验概率,得到最终的语义序列,即获得训练好的连续手语语句识别模型;步骤5、将测试集对应的关键帧序列的时空特征序列,输入在训练好的基于注意力的连续手语语句识别模型,输出识别出的连续手语语句,测试模型准确率。2.根据权利要求1所述的一种基于注意力的连续手语语句识别方法,其特征在于,步骤3中,在基于注意力的连续手语语句识别模型中,基于注意力的双模态编码网络由两路结构相同的blstm与注意力网络构成,blstm由一组双向的lstm神经单元组成,分为前向网络和后向网络,同时传递t时刻之前时刻与之后时刻的信息;在t时刻,基于注意力的双模态编码网络中前向lstm和后向lstm的隐藏层状态分别为和它们的隐含层单元传递信息的方向是相反的,对应的传递函数为:对应的传递函数为:对应的传递函数为:其中,h
t
‑1为前一时刻特征向量,h
t 1
为后一时刻特征向量,f
t
为训练集对应的关键帧序列的时空特征,u1和w1为前向网络的共享权重,u2和w2为后向网络的共享权重,b1和b2为偏置;前向lstm和后向lstm都通过各自的传递函数进行隐藏单元之间的特征传递,通过拼接前向lstm层和后向lstm层的隐藏状态,得到经过lstm网络后在t时刻关键帧序列的高层特征:
彩色视频模态和光流模态的关键帧手语视频对应的输出高层特征序列,分别用和表示;在使用注意力机制时,对于每个时刻,特征为h
i
,其中i∈[t
‑
1,t 1],则根据输入特征与上一时刻输出加权向量计算h
i
对t时刻输出的相似度分数计算方式如下:其中,w
a
、w
b
、w为权重矩阵,σ为tanh函数,b
a
为偏置向量,h
t
为t时刻输入特征,a
t
‑1为t
‑
1时刻多层感知机输出特征;对三个特征向量h
t
,h
t
‑1,h
t 1
的相似度进行指数归一化,归一化后的序列位置t处的注意力系数为:其中,α
t
为注意力系数,0≤α
t
≤1,且将注意力系数α
t
作为权重,通过加权求和的方式计算a
t
,表示为:通过双模态编码网络分别得到彩色视频模态和光流模态的关键帧手语视频的加权特征序列,分别表示为将其进行特征拼接后得到分配过注意力权重的融合特征序列a=(a1,a2,...,a
t
)。3.根据权利要求1所述的一种基于注意力的连续手语语句识别方法,其特征在于,步骤3中,在基于注意力的连续手语语句识别模型中,使用lstm和ctc损失层组成基于ctc的解码网络;将融合特征序列a作为lstm的输入,对两个模态的特征序列进一步整合,并与时间关系建模,通过lstm得到新的特征序列g
t
表示为:g
t
=lstm(a
t
‑1,a
t
)其中,a
t
为t时刻多层感知机输出特征;采用ctc损失层进行训练:首先使用一个由softmax函数组成的内在映射层,将解码器的lstm层每个时刻的输出特征g
t
映射为分布概率其中,k为手语词典元素表所含元素个数;再通过ctc损失层,根据每个视频关键帧的分布概率计算得到实际语义的后验概率;采用通用损失函数训练l个标签的目标词典时,将产生|l|个输出;在基于ctc的解码网络中引入空白标签<blank>并创建拓展词典序列l
′
=l∪{<blank>},并定义一个拓展词典序列π和目标标签序列l之间的映射函数,映射函数b表示为:b:l
′
t
→
l
u
,(u≤t)其中,π∈l
′
t
,l∈l
u
;l
′
t
为包含空白标签<blank>的拓展词典序列,其长度为t,l
u
为将l
′
t
中去除重复标签与空白标签后的语义标签序列,u为折叠后语句中语义标签数量;当ctc损失层的输入序列为解码器中lstm输出的特征序列g=(g1,g2,...,g
t
),定义一
个逆映射函数b
‑1,它生成所有可能与目标标签序列l相对应的拓展词典序列π,那么给定输入特征序列a对应于标签序列l的概率为:根据输出序列的概率分布p(l|k),调整模型参数使得p(l|k)最大;根据前后向算法计算得到ctc损失函数:l
ctc
=
‑
ln(p(l|a))使用梯度下降法对网络进行训练,并计算ctc损失函数的梯度;获得ctc的损失函数与梯度之后,然后对其解码,用公式表示为:y(a)=arg max p(l|a)找到输出序列的概率分布中概率最大的路径后,输出对应序列找到最佳输出序列w=(w1,w2,...,w
u
),其中u为每个连续手语语句视频包含的词语数量。
技术总结
本发明公开了一种基于注意力的连续手语语句识别方法,首先,分别提取彩色视频和光流视频模态的关键帧手语视频的关键帧序列的时空特征,将提取到的时空特征输入构建的基于注意力的连续手语语句识别模型,该模型本质上是一个序列到序列模型:通过基于注意力的双模态编码网络得到两个模态的融合特征序列,并输入基于连接时序分类的解码网络,得到最终的语义序列。本发明通过利用序列到序列模型将手语序列转换到另一个语言序列,解决输出长度不确定的问题,改善输入与输出序列的不规则对齐问题。同时,在完成具有冗余信息的复杂任务时,使用注意力模型将注意力聚焦于视频特征的重要区域,对连续手语语句识别效果有显著的提升。对连续手语语句识别效果有显著的提升。对连续手语语句识别效果有显著的提升。
技术研发人员:王军 袁静波 李玉莲 潘在宇 申政文 鹿姝
受保护的技术使用者:中国矿业大学
技术研发日:2021.07.13
技术公布日:2021/11/4
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。