1.本发明属于神经网络算法模型复用领域,该技术基于迁移学习,使得在相似主题中,神经网络算法模型可以复用,供用户参考使用。
背景技术:
2.随着业务数据量的增多,企业面对多方面的主题分析时往往将其视为独立的项目,即每次进行主题分析时均需重新获取数据、重新进行数据预处理、重新构建模型。在进行多主题分析时,这种方式往往导致主题间算法模型重用性差等问题。在实际的应用中,通常不会针对一个新任务,从头开始训练一个神经网络。这样的操作是非常耗时的。尤其是,训练数据不可能像image net那么大,可以训练出泛化能力足够强的深度神经网络。即使有如此之多的训练数据,从头开始训练,其代价也是不可承受的。迁移学习告诉我们,利用之前已经训练好的模型,将它很好地迁移到新的模型训练任务上即可。
技术实现要素:
3.本发明的目的是提供一种基于迁移学习的神经网络模型复用的方法,使得在相似主题中,神经网络模型可以共享复用,大大的提升模型利用的效率,节约分析成本。
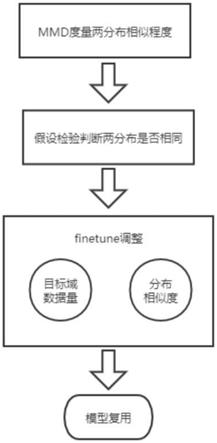
4.根据mmd(最大平均差异)来度量目标域与源域两个分布的相似性。再根据假设检验来判断目标域与源域的分布是否相同。若假设检验判断为两分布相同,则对深度神经网络模型进行finetune调整,实现深度神经网络模型的复用。
5.为了解决以上问题,本发明的技术方案:
6.一种基于迁移学习的神经网络模型复用方法,包括以下步骤:
7.步骤1:当源域服从p分布、目标域服从q分布时,用mmd来度量两个分布的相似程度。
8.步骤2:基于假设检验,判断源域p分布、目标域q分布是否相同。
9.步骤3:根据假设检验的结果,若判定分布p、q为同分布,则可以进行基于finetune对神经网络模型进行迁移。
10.步骤4:不同场景下的finetune方法。
11.在本发明的一个优选实施例中,
12.本发明具有以下有益效果:
13.(1)不需要针对新任务从头开始训练网络,节省了时间成本;
14.(2)神经网络的前3层基本都是general feature,进行迁移的效果会比较好;
15.(3)finetune可以比较好地克服数据之间的差异性;
16.(4)预训练好的模型通常都是在大数据集上进行的,无形中扩充了我们的训练数据,使得模型鲁棒性、泛化能力更好。
附图说明
17.图1为本发明的基于迁移学习的神经网络模型复用流程图;
18.图2为本发明的有无finetune的模型精度对比图。
具体实施方式
19.以下结合附图对本发明的特征及其它相关特征作进一步详细说明,以便于同行业技术人员的理解。
20.步骤1:当源域服从p分布、目标域服从q分布时,用mmd来度量两个分布的相似程度。
21.mmd的统计检验方法是指:对于两个分布的样本,通过寻找在样本空间上的连续函数,求两个不同分布的样本在上函数值的均值,通过把两个均值作差可以得到两个分布对应于的平均差异。寻找一个使得这个平均差异有最大值,由平均差异便得到了mmd的值,最后取mmd作为检验统计量,从而判断两个分布是否相同。同时这个值也用来判断两个分布之间的相似程度。如果用表示一个在样本空间上的连续函数集,则mmd可表示为:
[0022][0023]
假设x和y分别是从分布p和q通过独立同分布采样得到的两个数据集,数据集的大小分别为m和n,基于x和y可以得到mmd的估计为:
[0024][0025]
步骤2:基于假设检验,判断源域p分布、目标域q分布是否相同。
[0026]
对于一个双样本检测,设定原假设为:分布p和分布q是相同的,备择假设为:分布p和分布q是不相同的。通过将测试集估计值和一个给定的阈值进行比较,来判断两分布p、q是否相同。如果mmd大于阈值,那么就拒绝原假设,接受备择假设,也就是认为两个分布p、q不相同。如果mmd小于给定的阈值,就接受原假设,认为分布p、分布q相同。
[0027]
步骤3:根据假设检验的结果,若判定分布p、q为同分布,则可以进行基于finetune对神经网络模型进行迁移。
[0028]
finetune,也叫微调,是深度学习中的一个重要概念,利用先前已经训练好的网络,针对自己的任务再进行调整,finetune是迁移学习的一部分。
[0029]
在神经网络中,粗略的可以分为输入层、隐含层、输出层。在隐含层中进行一系列的学习,转化,计算等工作。根据相关实验以及文献,在深度神经网络中,前面几层学习到的是通用的特征;随着网络层次的加深,后面的网络更偏重于学习任务特定的特征。比如:假设一个网络要识别一只猫,那么一开始它只能检测到一些边边角角的东西,和猫根本没有关系;然后可能会检测到一些线条和圆形;慢慢地,可以检测到有猫的区域;接着是猫腿、猫脸等等。
[0030]
为了更好地说明神经网络finetune(微调)的结果,提出概念:anb和bnb。其中,anb:迁移a网络的前n层到b;bnb:固定b网络的前n层。这里,所有实验都是针对数据b来说的,anb:将a网络的前n层拿来并冻结,
[0031]
剩下的层随机初始化,然后对b进行分类。相应地,有bnb:把训练好的b网络的前n
层拿来并冻结,剩下的层随机初始化,然后对b进行分类。如图2所示,蓝色的是bnb和bnb (bnb加上finetune)。
[0032]
由图2可知,对bnb而言,原训练好的b模型的前3层直接拿来就可以用而不会对模型精度有什么损失。到了第4和第5层,精度略有下降,不过还是可以接受。然而到了第6、7层,精度回升。原因如下:对于一开始精度下降的第4第5层来说,到了这一步,feature变得越来越specific,所以下降了。对于第6第7层精度又不变,因为整个网络设置为8层,我们固定了第6第7层,网络可以学习的内容不多,所以精度和原来的b网络几乎一致。对bnb 来说,结果基本上都保持不变。
[0033]
说明finetune对模型结果有着很好的促进作用。再看anb 。加入了finetune以后,anb 的表现对于所有的n几乎都非常好,甚至比最初的b还要好一些。这说明:finetune对于深度迁移有着非常好的促进作用。
[0034]
步骤4:不同场景下的finetune方法。
[0035]
(1)目标域数据集较小且和源域数据集相似时:因为目标域数据集比较小(比如<5000),如果finetune可能会过拟合;又因为目标域与源域数据集类似,因此期望两者高层特征亦类似,可以使用预训练网络当做特征提取器,用提取的特征训练线性分类器,此时只训练分类器即可。
[0036]
(2)目标域数据集大且和源域数据集相似时:目标域数据集大于10000时,可以finetune整个网络。
[0037]
(3)目标域数据大且和源域数据集相似度不高时,因为目标域数据集足够大,可以重新训练。但是实践中finetune预训练模型还是有益的,新数据集足够大,可以finetune整个网络。
[0038]
(4)目标域数据集小且和源域数据集相似度不高时,此时最好不要finetune,因为效率不高。
[0039]
与重新训练相比,因为训练好的网络模型权重已经平滑,因此,finetune要使用更小的学习率。
[0040]
虽然本发明所揭露的实施方式如上,但所述的内容仅为便于理解本发明而采用的实施方式,并非用以限定本发明。任何本发明所属领域内的技术人员,在不脱离本发明所揭露的精神和范围的前提下,可以在实施的形式及细节上进行任何的修改与变化,但本发明的专利保护范围,仍须以所附的权利要求书所界定的范围为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

