1.本发明属于图像聚类与强化学习领域,涉及一种多视角强化图像聚类方法。
背景技术:
2.随着网络信息与电子商务等技术的广泛应用,人类获取数据信息的方式愈加丰富,可收集的数据量越来越多,数据结构越来越复杂,数据维度也越来越高。多视角图像数据通常来自于数据对象的不同领域或多个角度的测量结果,包含着丰富的互补信息可有效增强数据分析的效果,但受多视角数据多源异构以及数据维度的影响,多视角数据中的互补信息难以被充分利用。因此,急需研究一种新方法来深入挖掘海量多视角图像数据间的互补信息。
3.聚类是机器学习和数据挖掘领域中的一种重要的数据分析和处理技术,其目标是将同类数据划分至相同子集,异类数据划分至不同子集。多视角聚类打破单个视角中数据信息不足对聚类效果的限制,考虑多个视角间的一致性和互补性,联合多个视角的表征信息,提升最终的聚类结果。早期的多视角聚类方法对多视角信息进行融合,关联视角间的特征,表现出相对于单视角聚类较好的结果。然而,早期的方法通常假设数据仅存在两个视角,难以处理存在三个及三个以上视角的多视角数据并易于出现多视角数据缺失的问题。对此,研究者受深度生成模型在单视角聚类中可以对缺失数据进行推理的启发,提出多视角变分自编码器(mvae)模型,通过专家网络组合每个视角独立的变分自动编码器(vae),学习多个视角的联合分布,获得更为深入且有效的多视角特征,提升多视角聚类的性能。
4.尽管当前的多视角聚类方法利用深度生成模型捕获多视角间的互补信息,取得了较好的聚类结果,但现有的多视角聚类方法仅考虑了多视角数据的固有属性,而忽视了多视角数据与聚类中心的关联性,易使得集群边缘逐渐模糊化。强化学习在与环境的交互中利用自发地学习策略以达到回报最大化,因此,在获得多视角图像数据的有效信息的前提下,基于强化学习思想关联多视角聚类环境中数据点和集群点的信息,提升多视角聚类效果的准确性,是一项值得研究的内容。
技术实现要素:
5.为解决上述问题,本发明提出一种多视角强化图像聚类方法,在使用多视角数据的一致性和互补性的基础上,考虑聚类迭代过程中对聚类中心与多视角数据的交互信息的使用问题,提高聚类效果。
6.首先,本发明利用深度自编码器对原始多视角高维图像数据进行降维,捕获数据各个视角的潜在特征表示。其次,本发明设计一种多视角特征融合策略,融合数据多个视角的潜在特征表示,获取多视角数据的高阶互补信息。最后,本发明提出了一种基于强化学习的在线奖赏策略,实现聚类环境中数据点和集群点的实时交互,充分利用融合特征表示,获得更准确的聚类结果。综上,本发明提出一种多视角强化图像聚类方法,该方法采用在线奖赏的学习方式从大规模图像数据的多个视角间学习融合表征信息并即时调整集群分配,以
提高多视角图像聚类的性能,并采用三个聚类评估指标:调整兰德指数(ari)、标准化互信息(nmi)和准确率(acc)验证模型效果。
7.为了达到上述目的,本发明的技术方案如下:
8.一种多视角强化图像聚类方法,包括以下步骤:
9.步骤1、预训练各视角独立的特征提取网络,获取各视角的潜在特征表示;
10.步骤2、预训练多视角特征融合网络,获得各视角的融合特征表示;
11.步骤3、采用k
‑
means方法初始化聚类环境,并为环境中的聚类原型分配伯努利单元;
12.步骤4、利用在线奖赏策略实时分配随机奖赏,动态更新环境中的伯努利单元;
13.步骤5、更新参数,迭代优化聚类原型直到满足收敛条件,完成多视角强化聚类过程。
14.本发明的有益效果为:本发明针对图像数据设计了一种多视角强化图像聚类方法,主要考虑利用多视角图像数据中的互补信息学习高效的融合特征表示,提高图像聚类和特征学习效果,并为此设计了一种基于伯努利单元的强化学习框架,充分利用整个聚类环境的信息,提高聚类算法性能。本发明在聚类评估指标调整兰德指数(ari)、标准化互信息(nmi)和准确率(acc)上进行度量,并表明该方法可有效改善图像聚类的性能。
附图说明
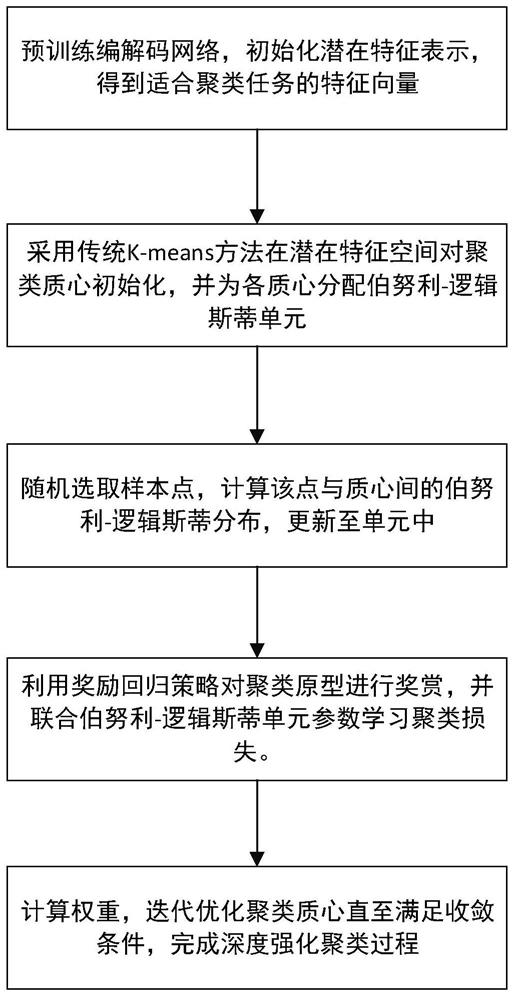
15.图1为本发明的多视角强化图像聚类方法框架图;
16.图2为本发明的多视角强化图像聚类方法整体流程图。
具体实施方式
17.下面结合附图对本发明的实施方式做进一步说明。
18.图1为本发明多视角强化图像聚类方法框架图。首先,通过深度自编码器分别对原始数据v个视角的高维特征进行降维,获取各个视角的潜在低维特征。其次,采用多视角融合特征网络对融合v个视角的潜在低维特征,生成多视角融合特征,联合各视角的一致信息和互补信息。然后,采用k
‑
means方法挖掘多视角数据的聚类质心作为聚类原型,并为其构建对应的伯努利单元,用于保存迭代优化过程中的聚类信息,完成聚类环境的初始化。然后,利用在线奖赏策略学习多视角融合特征与聚类原型间的交互信息,并通过奖惩信号实时改变伯努利单元,实现聚类环境的动态更新。最终,通过联合学习伯努利单元和奖惩信号的方式,使用强化学习算法迭代优化聚类环境直到满足收敛条件。
19.各步骤具体实施如下:
20.步骤1、预训练各视角独立的特征提取网络,获取各视角的潜在特征表示
21.原始的多视角图像数据具有结构复杂、维度较高的特性,会降低数据的可理解性和可用性,容易引发“模式崩溃”的问题。对此,本发明采用特征提取网络对同一对象的v个视角特征进行降维。具体地,特征提取网络由n个自编码器网络堆叠而成,而自编码器网络由对称网络结构的编码层和解码层构成。编码层逐层压缩输入的高维数据到低维特征空间,解码层在低维特征空间中重构数据。在训练过程中,将编码层的最后一层作为隐藏层,并最小化输入和重构间的误差,获取蕴含数据潜在结构的低维特征表示。
22.对于第v个视角,基于多个自编码器网络,通过将前一个自编码器隐藏层的输出作为下一个自编码器的输入,构建特征提取网络。假设为该视角的第j个输入图像数据,则当前视角的第一个自编码器网络的计算过程如下:
[0023][0024][0025]
其中,为该隐藏层输出的潜在特征表示,为该自编码器的重构数据。和分别为该自编码器的编码层和解码层的激活函数,为编码层和解码层的参数,该自编码器的训练采用重构损失
[0026]
对于该网络的第n个自编码器的编码层,当n为1时,自编码器的输入为原始图像数据,计算过程如公式(1)(2)所示。当n大于1时,第一个自编码器的输入为计算过程如(1)(2)所示,自编码器的输入为第n
‑
1个编码层的隐藏层特征计算过程可表示为:
[0027][0028][0029]
其中,与第一个自编码器相同,为该隐藏层输出的潜在特征表示,为该自编码器的重构特征表示。和分别为该自编码器的编码层和解码层的激活函数,为编码层和解码层的参数。该自编码器的训练采用重构损失
[0030]
最终,将第v个视角的n个自编码器拆分为n个编码层和n个解码层并按照对称的方式重新排列为构建该视角的特征提取网络,部分为编码器,部分为解码器。然后,最小化重构损失和随机梯度下降算法对该特征提取网络进行训练。
[0031]
依以上步骤,分别构建各视角对应的特征提取网络,生成各个视角的潜在特征表示,用于多视角特征融合网络。
[0032]
步骤2、预训练多视角特征融合网络,获得各视角的融合特征表示;
[0033]
图像数据中的信息可以从不同视角进行表示,使用单一视角进行聚类分析限制了聚类效果。对此,本发明设计多视角特征融合网络,并联合不同视角的特征提取网络以端到端的方式学习全部视角的融合特征表示,增强聚类效果。
[0034]
首先,根据多个视角的互补特性,将步骤1得到的同一样本的各个视角的潜在特征表示h
v
进行串联拼接:
[0035]
h
f
=cat(h1...h
v
)
ꢀꢀꢀ
(5)
[0036]
其中,v为视角的数量,h1,
…
,h
v
为各个视角的潜在特征表示,cat(
·
)表示拼接运
算,h
f
为融合特征表示。
[0037]
多视角特征融合网络由n个自编码器网络堆叠而成,在预训练过程中,将融合特征表示h
f
作为输入,学习全局关联的融合特征表示。具体地,该网络最外侧自编码器计算过程如下:
[0038][0039][0040]
其中,为外侧编码层输出的潜在特征,该特征维度小于h
f
的维度;ho
f
为内侧解码器输出的重构特征,该特征维度等同于的维度;为外侧解码层输出的重构表示,该特征维度等同于h
f
的维度。当该网络仅由一个自编码器构成时,ho
f
即为g
e,f
(
·
)和g
d,f
(
·
)分别是编码层和解码层的激活函数,为模型参数。
[0041]
对于构建好的多视角融合网络,采用端到端的学习方式,通过随机梯度下降算法和最小化重构损失预训练网络。然后,将各个视角的特征提取网络的解码器输入维度设置为拼接后的潜在特征h
f
的维度,输入数据为
[0042]
最终,训练后的多视角融合网络将j个多视角图像数据作为输入,生成全局关联的多视角融合特征h,即堆叠自编码机最内侧编码层的潜在特征
[0043]
步骤3、初始化聚类环境,分配伯努利单元;
[0044]
利用步骤2中得到的j个多视角图像数据的多视角融合特征并从中随机选取k个点作为初始的聚类质心集合采用k
‑
means方法在融合特征h上更新聚类质心集合c至满足收敛条件,以得到k个初始虚拟原型,实现聚类环境的初始化。
[0045]
具体地,k
‑
means方法是根据距离越小,相似度越大;距离越大,相似度越小的标准,将数据点划分到k个集群中。采用欧氏距离计算各数据点间的距离,计算公式如下:
[0046][0047]
其中,h
i
和h
j
表示两个不同的数据点的多视角融合特征,dist(
·
)表示两者之间的距离。
[0048]
在集群的划分过程中,每次迭代需要重新计算同一集群中的多视角数据点融合特征的平均值,并将其作为质心c={c
k
|k=1,2,...,k},计算公式为:
[0049][0050]
其中,c
k
表示第k个集群的质心,h
i
表示位于该集群的数据点的多视角融合特征。
[0051]
首先从样本集中随机选取k个点作为初始的聚类质心集合采用公式(8)计算各数据点与各聚类质心的距离,并将各数据点分配给距离最近的聚类质心。
[0052]
最终,通过启发式的迭代方法更新聚类质心至收敛,得到k个优化后的聚类质心作
为数据点聚类质心集合并将优化后的质心集合c作为强化聚类过程中的初始虚拟原型,并对每个原型构建相应的伯努利单元,存储当前聚类环境下的对应信息:
[0053]
bunit={w,p,dist,f}
ꢀꢀꢀ
(10)
[0054]
其中,w为该虚拟原型的权重,p为该虚拟原型的指示变量,dist为当前数据点到该虚拟原型的距离,f为状态参数。初始条件下,w设置为k
‑
means算法更新后的质心权重,p、dist、f设置为0,三者随着强化聚类过程的迭代发生改变。
[0055]
通过上述过程,完成聚类环境的初始化。
[0056]
步骤4、多视角强化聚类;
[0057]
在得到输入图像数据的多视角融合特征,并完成聚类环境初始化后,执行多视角融合特征与聚类环境中虚拟原型的在线交互,完成多视角强化聚类过程。具体地,多视角强化聚类过程包括以下两个步骤。步骤4
‑
1,计算输入图像数据的多视角融合特征与虚拟原型间的状态参数,度量输入图像数据对当前聚类环境中虚拟原型的指示程度,并选取临近虚拟原型作为强化对象;步骤4
‑
2,执行在线奖赏策略,为临近虚拟原型分配奖赏信号r,即奖赏或惩罚。通过步骤4
‑
1和步骤4
‑
2,更新聚类环境,迭代收敛至获得最优的虚拟原型作为聚类中心。
[0058]
步骤4
‑
1选取强化对象
[0059]
本发明采用伯努利分布作为辅助分布用于激活目标单元,即通过伯努利分布度量输入图像对虚拟原型的指示性,选取准确的强化对象,保证聚类结果的置信度。
[0060]
首先,在输入图像的融合特征集合h中随机选取特征向量h
j
,采用前述的欧氏距离计算h
j
与虚拟原型c
k
间的距离d
k
;其次,通过sigmoid函数计算二者之间的状态系数,计算过程如下:
[0061]
d
k
=dist(h
j
,c
k
)
ꢀꢀꢀ
(11)
[0062][0063]
在获得状态系数后,使用代价函数度量多视角图像潜在特征对虚拟原型的指示程度。计算公式如下:
[0064]
p
k
=j(d
k
)=2
×
(1
‑
f(d
k
))
ꢀꢀꢀ
(13)
[0065]
其中,p
k
为指示变量,用于表示输入图像与虚拟原型c
k
的间指示程度。理想情况下,p
k
值较大,意味着融合特征与聚类原型的距离越小,二者相似度越高,输入图像对虚拟原型的指示性越强;反之则越弱。选取指示性较强的虚拟原型作为强化对象。
[0066]
由于伯努利分布为离散型分布,具有不确定性,为确保选取的强化对象的有效性,本发明设置随机种子p同已选定的虚拟原型的指示变量p
k
进行比较,获得校准变量y,修正无效虚拟原型对整个聚类结果的负面影响。计算过程如下:
[0067][0068]
在执行上述步骤4
‑
1过程中,实时更新聚类环境中对应单元的相关信息,
[0069]4‑
2在线奖赏策略
[0070]
为高效利用图像数据的多个视角间的一致信息和互补信息,并突出考虑图像数据
与聚类环境的交互信息,本发明采用强化学习的思想,对于当前设定下的伯努利单元,通过合适的在线奖赏策略,明确对聚类环境的作用效果,获得最优的虚拟原型。对此,在根据指示性的强弱完成强化对象的选取后,利用在线奖赏策略为该强化对象对应的伯努利单元施加决策信号,以实时反馈输入图像与聚类原型交互后产生的行为,在对有效强化对象进行奖赏的同时,对无效强化对象进行惩罚,解决多视角图像聚类过程中缺乏对数据与集群间关联性充分考虑的问题。
[0071]
首先,根据校准变量y为选定的强化对象分配奖惩因子r
j
:
[0072][0073]
其中,当校准变量为1时,选定的强化对象为有效对象,且该单元对应的虚拟原型接近输入图像并符合理想情况,应对施加正向决策,即为其分配奖赏因子,则反之,选定的强化对象为无效对象,且该单元对应的虚拟原型远离输入图像而违背理想情况,应对施加反向决策,即为其分配惩罚因子。
[0074]
在执行上述策略过程中,虚拟原型的权重不发生变化。
[0075]
步骤5、更新参数,优化聚类结果;
[0076]
在执行多视角强化聚类步骤后,本发明采用策略梯度算法更新选定的强化对象的权重参数,如下公式所示。
[0077][0078]
其中,α表示学习率,其值应大于0;r为多视角强化聚类步骤中获得的奖惩因子,b
j,k
为强化基线。g
j
=g
j
(y
j
;w
j
,h
j
)为概率密度函数,该值受输入图像的多视角融合特征h
j
及其权重为w
j
的选定强化对象在当前聚类环境下校准变量的影响。用于衡量策略梯度更新过程中的特征变换度,随概率密度函数g
j
的值发生改变。
[0079]
根据多视角强化聚类的指示程度,联合校准变量和奖赏因子,在设置强化基线b
j,k
=0的条件下,得到最终的虚拟原型的权重更新公式:
[0080][0081]
在迭代优化的过程中,虚拟原型通过公式(16)进行更新,当聚类结果达到预设训练次数时,多视角强化图像聚类任务完成。
[0082]
方法流程描述:
[0083]
本发明的整体流程分为四个部分:各视角特征预处理过程、多视角特征融合过程、聚类环境初始化过程以及多视角强化聚类过程。首先,为图像数据的各个视角构建深层自编码器网络,采用堆叠自编码器对各个视角的高维图像数据进行降维处理,获取各个视角的潜在特征表示。其次,构建多视角融合网络,融合各个视角的潜在特征表示,获取全部视角的融合特征表示。然后,基于多视角特征融合过程中提取的融合特征表示,采用k
‑
means方法挖掘聚类质心,并将的带的聚类质心作为虚拟原型存储至对应的伯努利单元中,完成
聚类环境的初始化。最后,采用在线奖赏策略,通过多视角融合特征以及虚拟原型的实时交互,并联合伯努利单元反馈交互信息,更新聚类环境中的参数直至收敛。具体流程见图2。
[0084]
验证结果:
[0085]
在本发明的实验中,选择两个通用的图像数据集验证本发明的有效性,其中数据集的详细信息如表1所示。
[0086]
mnist手写数字数据集:由70000张手写数字图像组成,每个数据样本是一个28*28像素的灰度图像。本发明将每个图像重构为784维向量。
[0087]
fashion
‑
mnist数据集:由70000张服饰图像组成,每个数据样本是一个28*28像素的灰度图像。本发明将每个图像重构为784维向量。
[0088]
表1数据集的详细信息
[0089]
数据集样本数量样本维度类别数量mnist7000078410fashion
‑
mnist7000078410
[0090]
本发明的评价标准为聚类精确度(accuracy,acc)、调整兰德指数(adjusted rand index,ari)和标准化互信息(normalized mutual information,nmi)。
[0091]
为了验证本发明的性能,选择深度多视角聚类方法(mae k
‑
means)进行比较。
[0092]
本发明提出的方法与对比方法在mnist和fashion
‑
mnist数据集上的acc、ari和nmi性能结果如表2、表3所示。
[0093]
表2各实验在mnist数据集上结果比较
[0094]
experimentsaccarinmimae k
‑
means0.999850.999670.99951本发明0.99990.99990.9998
[0095]
从表2和表3中,可以观察到本发明提出的方法在mnist和fashion
‑
mnist数据集的三个评价指标acc、ari和nmi上都优于对比基线方法,这证明了本发明的有效性。具体地,与mae k
‑
means方法相比,本发明的优势在于采用伯努利单元和在线奖赏策略,通过输入图像数据与聚类原型的交互反馈正确的决策行为,实现对多视角互补信息的充分利用以及对聚类环境的突出考虑,提高聚类性能。
[0096]
表3各实验在fashion
‑
mnist数据集上结果比较
[0097]
experimentsaccarinmimae k
‑
means0.494430.366530.54398本发明0.56460.43930.5754
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

