1.本发明涉及遥感影像中目标检测的技术领域,尤其涉及一种对松材线虫病树的检测方法。
背景技术:
2.松材线虫病是一种由松材线虫引起的具有毁灭性的森林病虫害,松树一旦感染该病,最快40天左右即可死亡,如不进行人工干预,3
‑
5年内便可摧毁成片的松树林。该病自1982年传入我国,已蔓延至全国18个省588个县级行政区域,发生面积达 974万亩,造成的松树死亡数量累计达到数十亿株,造成直接经济损失和生态服务价值损失上千亿元。
3.传统的松材线虫病识别的工作通常采用人工定位的方法进行,然而人工定位的方法既耗费时间也耗费物力,并且有些地方难以进行人工踏勘。
4.在现有技术中文献编号为1000
‑
1298(2020)07
‑
0228
‑
09的论文公开了一种基于 faster r
‑
cnn深度学习网络对松材线虫病树进行检测的方法,论文主要创新点在于通过根据病树冠幅修改rpn网络中建议框尺寸,达到更好的网络训练精度。但该现有技术对正负样本的平衡没有进行调整,仅仅通过修改建议框的尺寸无法平衡网络训练中正负样本的比例,而且也没有考虑到样本的难易程度对网络训练带来的影响。
5.本发明通过构建采样检测网络,解决网络训练中存在的样本不平衡问题,通过对样本阈值区间进行加权,提高网络的困难采样率,降低大量简单样本的采样率,提升样本采集质量,从而获取更为鲁棒的网络模型。
技术实现要素:
6.本发明的目的是为了能准确、可靠的对松材线虫病树进行定位,而提供了一种鲁棒的、基于影像处理技术的对松材线虫病树进行检测的方法。
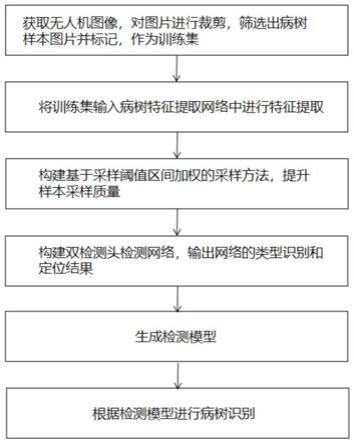
7.一种基于采样阈值区间加权松材线虫病树进行检测的方法,包括以下步骤:
8.步骤1:采集训练集图片,对包含病树样本的图片进行标记作为训练集;
9.步骤2:构建病树特征提取网络对训练集图片的特征进行提取,生成特征图;
10.步骤3:构建采样筛选网络,对特征图进行样本采集,并根据采样阈值区间加权算法对样本进行筛选;
11.步骤4:样本采集完成后送入解耦的网络检测头中,进行病树的识别,并生成初始双检测头识别模型;
12.步骤5:将需要检测的病树图片投入初始双检测头模型中进行识别,对验证集中错误样本进行统计,并制作成为负样本集,与训练集混合后再次放入采样筛选网络中进行训练,通过反复迭代获取高鲁棒性的识别模型;
13.步骤6:将最优模型的识别模型的识别结果输出为矢量,并校正位置,得到病树中心点经纬度坐标文件。
14.步骤2中,在构建病树特征提取网络时,具体采用以下步骤:
15.1)构建病树特征提取网络,病树特征提取网络主要由下采样模块组成,下采样模块采用残差模块进行堆叠生成。
16.2)将训练集图片送入病树特征提取网络中进行下采样,得到特征图;
17.步骤3中,构建采样筛选网络对对特征图进行样本采集,采用以下步骤:
18.(1):训练集图片在经过病树特征提取网络后变为特征图,采样筛选网络在特征图上通过滑窗方式生成预选框,滑窗大小为3*3,生成k个预选框,k一般设为9,预选框可视为一个个按照固定比例(长宽,大小)预定义的框;
19.(2):计算预选框和标注真值的iou交并比,iou计算公式为:
[0020][0021]
步骤3中,采样阈值区间加权算法具体实现方法如下:
[0022]
(1)通过对整体样本的iou阈值区间进行划分,将iou阈值区间按照正负样本分为两个区间,并在两个区间内划分难易样本区间,按照l的阈值区间将x以下及以上的区间各划分为k个阈值区间,一般将l设置为0.1,k设置为10,x设置为0.5,并对难例样本区间(靠近x的阈值区间)进行加权,加权公式如下:
[0023][0024][0025]
s
k
为不同batch中的候选采样数,n为采样数,k为划分的区间数,将整个阈值区间均匀划分为k个区间,c为若整体采样数不够n值,则从整体样本空间内进行随机采样。σ为加权系数,加权系数中n
max
代表整个样本空间的样本数,n
h
表示当前阈值区间内样本数量,样本空间阈值的整体走向是呈u型的,整个样本空间内的样本数是恒定的,在难例样本区间内采样的数量相对于容易样本的采样数量是较为稀少的,实验将k个区间分为简单样本区间和困难样本区间,取样本空间两端的区间ψ为简单样本区间,其余区间为困难样本区间,在不同的样本区间内使用不同的加权系数σ,抑制简单样本提高困难样本的采样比例。
[0026]
步骤4中,将网络检测头进行解耦的具体实现步骤如下:
[0027]
(1)将网络检测头的类型识别定位支路进行解耦,分别建立定位支路和类型识别支路,并且两个支路的损失分别进行计算。
[0028]
步骤(1)中,将经过采样筛选网络的特征图进行池化获得7*7*256大小的特征图,在经过池化后的特征图后面建立两条检测支路,一条支路上串联两个卷积模块,另一个支路上串联两个全连接层,分别让两个检测支路专注于不同的任务,其中卷积模块采用k个残差模块进行堆叠,k可以根据显卡配置进行取值,显存越大的显卡k 值可以取越大。残差模块由三个模块组成,第一个模块主要用于将特征图的通道数从初始值a增加到目标值b,a和b一般设置为256和1024,第二个模块是瓶颈结构,通过在大卷积层前后堆叠1*1的小卷积层,降低训练使用的参数,第三个是non
‑
local 模块,用于提升卷积核的感受野,non
‑
local模块表达公式如下:
[0029][0030]
其中x是输入信号,在目标检测中一般使用的是特征图,i和j分别代表输入某个空间位置,f函数式计算i和j的相似度,g函数计算特征图在j位置的表示,最终y通过响应因子c(x)进行标准化处理后得到,通过non
‑
local模块可以计算任意两个位置之间的交互,从而捕捉远程依赖,脱离相邻点的局限,相当于构建了一个特征图谱尺寸一样大的卷积核,从而可以维持更多信息;
[0031]
(2)重新设置定位支路的损失函数,并得到最后类型识别结果和定位结果。在步骤(2)中,具体包括以下步骤:
[0032]
①
为解耦的定位支路重新设置损失函数。
[0033]
②
输出最后类型识别结果和定位结果
[0034]
在步骤
①
中:
[0035]
类型识别定位支路的损失定义如下:
[0036][0037]
和表示全连接层中类型识别损失,这里类型识别的损失选用交叉熵损失,λ
fc
表示全连接层中控制类型识别定位损失的权重值。定位的损失选用smooth
‑
l1损失函数。因为解耦成为两个支路,所以定位支路的损失不能和类型识别支路的损失一起计算,所以要重新设置定位支路的损失函数。类型识别支路损失函数则沿用上面的函数设置。
[0038]
定位支路的损失值定义如下:
[0039][0040]
和表示卷积层中类型识别定位损失,其中l使用的是smooth
‑
l1损失函数。λ
conv
表示定位支路中控制类型识别定位损失的权重值,λ
conv
与相乘代表定位支路专注于定位任务,其中λ
conv
和λ
fc
设置分别为m和n。
[0041]
样本框的定位结果表示如下:
[0042]
d
*(x,y,w,h)
(a)=w
*t
*φ
ꢀꢀꢀ
(a)
[0043]
其中φ(a)是对应样本框和特征图组成的特征向量,w
*
是需要学习的参数,d
*
(a) 是通过网络训练不断拟合数据得到的x,y,w,h,通过引入soomth
‑
l1损失函数计算样本框与真实标注值的差异值,smooth
‑
l1损失函数如下:
[0044][0045]
当差异值最小的时候就得到了物体的定位数据,通过反向传播计算梯度值,调节权重值来更新数据。经过不断反复更新计算,使得d
*
(a)拟合越来越靠近真实标注框;
[0046]
在步骤
②
中:
[0047]
经过1*1024全连接层得到一组特征向量,再用softmax对其进行类型识别, softmax函数公式如下:
[0048][0049]
经过softmax计算后输出每个特征向量的相对概率,特征向量最大的类别即为最后输出的类别。定位结果则直接使用定位支路的结果。得到训练结果后,将网络参数固定,并生成初始双检测头识别模型。
[0050]
在步骤5中,将需要检测病树的无人机图片进行裁剪,投入到初始双检测头识别模型中进行识别,对识别结果的错误样本进行筛选,要获取高鲁棒性的模型,错误样本的学习也是必须的,在数百平方公里的遥感影像内存在各种类型的地物,其中可能包含大量与病树相似的近似样本,模型容易对这些近似样本检测错误,对识别结果的错误样本进行整理,与训练集一起放入模型中再次训练,可以使模型获得区别错误样本的能力,经过反复迭代,最后可以得到高鲁棒性的双检测头检测模型。
[0051]
在步骤6中,将最优模型识别的验证集图片拼接,通过检测框左上角横纵坐标 (x1,y1),右下角的横纵坐标(x2,y2),计算检测框的中心点的坐标值,计算公式如下:
[0052][0053][0054]
将结果矢量化,位置配准,得到病树的精确位置。
[0055]
一种采样阈值区间加权方法,其特征在于,包括以下步骤:
[0056]
步骤1:对整体样本的iou阈值区间进行划分,将iou阈值区间按照正负样本分为两个区间;
[0057]
步骤2:在两个区间内划分难易样本区间,按照l的阈值区间将x以下及以上的区间各划分为k个阈值区间,并对难例样本区间进行加权。
[0058]
所采用的加权公式如下:
[0059][0060][0061]
s
k
为不同batch中的候选采样数,n为采样数,k为划分的区间数,将整个阈值区间均匀划分为k个区间,c为若整体采样数不够n值,则从整体样本空间内进行随机采样。
[0062]
如果整体采样数量没有达到候选采样数,则进行随机采样补齐,σ为加权系数,加权系数中n
max
代表整个样本空间的样本数,n
h
表示当前阈值区间内样本数量,样本空间阈值的整体走向是呈u型的,整个样本空间内的样本数是恒定的,在难例样本区间内采样的数量相对于容易样本的采样数量是较为稀少的,实验将k个区间分为简单样本区间和困难样本区间,取样本空间两端的区间ψ为简单样本区间,其余为困难样本区间,在不同的样本区间内使用不同的加权系数σ,抑制简单样本提高困难样本的采样比例,经过采样网络对预选框
进行筛选后,剩余的预选框被当做样本框送入网络检测头部分对样本框进行类型识别定位。
[0063]
与现有技术相比,本发明具有如下技术效果:
[0064]
1)本发明为了高效、准确的对松材线虫病树进行定位,而提供了一种较为鲁棒的,通过无人机影像识别松材线虫病树的方法;本发明提出了采样检测网络,通过采样阈值区间加权策略,提升样本采样质量,对松材线虫病树进行精确定位。相较于现有技术,本方法考虑到了网络训练中正负样本的比例调配和难易样本的比例问题,并且提出了一种解耦特征检测头,将卷积和全连接层进行分离,使其特征不共享,以提升网络识别精度。
[0065]
2)本发明通过构建采样检测网络,解决网络训练中存在的样本不平衡问题,通过对样本阈值区间进行加权,提高网络的困难采样率,降低大量简单样本的采样率,提升样本采集质量,从而获取更为鲁棒的网络模型。
[0066]
3)本发明是基于样本采样的一种病树检测模型,只需要采用少量的无人机标注样本,通过反复迭代训练就可以获得高鲁棒性的检测模型。将病树的位置转化为矢量输出,经过配准后可以在遥感影像里精确的定位病树的经纬度,避免了人工巡视,减少了大量的人力,物力耗费。
[0067]
4)相比现有技术,本发明在识别模型的构建上,我们设计了解耦特征检测头,将检测头进行解耦合,让不同分支专注于单独任务,从而取得更好效果。并且,相比现有技术,本发明考虑到了网络训练中简单困难样本不平衡带来对网络训练带来的影响,并提出了一种基于采样阈值区间加权的方法,提升困难样本区间的采样率,降低简单样本的采样比例,缓解了样本采集中难易样本采样的不平衡问题。综合以上的改进方法可以很大提升检测框架的精度。
附图说明
[0068]
下面结合附图和实施例对本发明作进一步说明:
[0069]
图1为本发明的流程图;
[0070]
图2为本发明中网络结构图;
[0071]
图3为本发明中残差模块结构图;
[0072]
图4为本发明中双分支检测头结构图;
具体实施方式
[0073]
一种基于采样阈值区间加权的松材线虫病树检测方法,包括以下步骤:
[0074]
步骤1:采集训练集图片,对包含病树样本的图片进行标记作为训练集;
[0075]
步骤2:构建病树特征提取网络对训练集图片的特征进行提取,生成特征图;
[0076]
步骤3:构建采样筛选网络,对特征图进行样本采集,并根据采样阈值区间加权算法对样本进行筛选;
[0077]
步骤4:样本采集完成后送入解耦的网络检测头中,进行病树的识别,并生成初始双检测头识别模型;
[0078]
步骤5:将需要检测的病树图片投入初始双检测头模型中进行识别,对验证集中错误样本进行统计,并制作成为负样本集,与训练集混合后再次放入采样筛选网络中进行训
练,通过反复迭代获取高鲁棒性的双检测头识别模型;
[0079]
步骤6:将最优模型的识别模型的识别结果输出为矢量,并校正位置,得到病树中心点经纬度坐标文件。
[0080]
在步骤2中,构建采样筛选网络,具体采用以下步骤:
[0081]
1):构建病树特征提取网络,训练集图片传入病树特征提取网络中进行特征提取;
[0082]
2):由病树特征提取网络生成的特征图进入采样检测网络,通过滑窗在特征图上生成预选框,通过与标注真值计算iou比,大于0.5计算为正样本,小于0.5计算为负样本。将样本阈值进行区间划分,通过采样阈值区间加权采样方法对预选框进行筛选,获得样本框。经过筛选的样本框中困难样本占比提升,抑制简单样本占比。经过采样筛选后的特征图送入网络检测头部分,进行类型识别定位。
[0083]
3)将网络检测头部分解耦成类型识别支路和定位支路,类型识别支路上串联两个全连接层,定位支路上串联两个卷积模块,通过分离类型识别定位特征,使其特征不共享,让单个支路专注于单个任务,网络检测头部分类型识别结果和定位结果通过两个支路分别输出;
[0084]
在步骤1)中,主干网络使用残差模块进行堆叠;
[0085]
在步骤2)中,样本采样过程可以分为如下几步:
[0086]
(1):采样检测网络在特征图上在通过滑窗生成预选框,滑窗大小为3*3,生成 9个预选框,预选框可视为一个个按照固定比例(长宽,大小)预定义的框;
[0087]
(2):计算预选框和标注真值的iou交并比,iou计算公式为:
[0088][0089]
iou大于0.5的视为正样本,iou小于0.5的视为负样本。因为病树样本在标注图像中占比较小,所以大量的预选框交并比都是远远小于0.5的,这些交并比远远小于0.5样本被称为易负样本,易负样本数量远远大于网络训练需要的难负样本和正样本,占据总损失的大部分,这样的训练使得模型的优化方向不会朝向我们希望的方向进行。我们通过对整体样本的iou阈值区间进行划分,将iou阈值区间按照正负样本分为两个区间,并在两个区间内划分难易样本区间。按照0.1的阈值区间将0.5以下及以上的区间各划分为5个阈值区间。并对难例样本区间(靠近0.5的阈值区间)进行加权,加权公式如下:
[0090][0091][0092]
s
k
为不同batch中的候选采样数,n为采样数,k为划分的区间数,这里k=10,将整个阈值区间从0到1以0.1的阈值区间均匀划分,如果整体采样数量没有达到候选采样数,则进行随机采样补齐。σ为加权系数,加权系数中n
max
代表整个样本空间的样本数,n
h
表示当前阈值区间内样本数量。样本空间阈值的整体走向是呈u型的,整个样本空间内的样本数是恒定的,在难例样本区间内采样的数量相对于容易样本的采样数量是较为稀少的,实验将10
个区间分为简单样本区间和困难样本区间,取样本空间两端的区间[0,0.1),[0.1,0.2),[0.8,0.9),[0.9,1),为简单样本区间和困难样本区间,在不同的样本区间内使用不同的加权系数σ,以控制简单样本和困难样本的采样比例。
[0093]
在步骤3)中,解耦网络检测头部分网络包含包括以下步骤:
[0094]
(1)将网络检测头的类型识别定位支路进行解耦,分别建立定位支路和类型识别支路;
[0095]
步骤(1)中,将经过采样筛选网络的特征图进行池化获得大小为7*7*256的特征图,池化为固定大小是为了统一特征图大小,使网络输入训练图片大小可以任意设置。在经过池化后的特征图后面建立两条检测支路,一条支路上串联两个卷积模块,另一个支路上串联两个全连接层。根据全连接层更适用于类型识别任务而卷积层在定位任务中有更好的效果,分别让两个检测支路专注于不同的任务。其中卷积模块采用 5个残差模块进行堆叠,残差模块由3个模块组成,第一个模块主要用于将特征图的通道数从256增加到1024,第二个模块是瓶颈结构,通过在大卷积层前后堆叠1*1 的小卷积层,降低训练使用的参数,第三个是non
‑
local模块,用于提升卷积核的感受野,non
‑
local模块表达公式如下:
[0096][0097]
其中x是输入信号,在目标检测中一般使用的是特征图,i和j分别代表输入某个空间位置。f函数式计算i和j的相似度,g函数计算特征图在j位置的表示,最终y通过响应因子c(x)进行标准化处理后得到。通过non
‑
local模块可以计算任意两个位置之间的交互,从而捕捉远程依赖,脱离相邻点的局限。相当于构建了一个特征图谱尺寸一样大的卷积核,从而可以维持更多信息;
[0098]
(2)重新设置定位支路的损失函数,并得到最后类型识别结果和定位结果;
[0099]
在步骤(2)中,具体包括以下步骤:
[0100]
①
为解耦的卷积层重新设置损失函数。
[0101]
②
输出最后类型识别结果和定位结果
[0102]
在步骤
①
中:
[0103]
网络检测头部分的类型识别定位支路损失函数定义如下:
[0104][0105]
和表示类型识别定位支路中类型识别定位损失,这里类型识别的损失选用交叉熵损失,λ
fc
表示全连接层中控制类型识别定位损失的权重值。定位的损失选用smooth
‑
l1损失函数。因为解耦成为两个支路,所以定位支路的损失不能和类型识别支路的损失一起计算,所以要重新设置定位支路的损失函数。
[0106]
定位支路的损失值定义如下:
[0107][0108]
和表示定位支路中类型识别损失和定位损失,其中l使用的是smooth
‑
l1损失函数。λ
conv
表示定位支路中控制类型识别定位损失的权重值,λ
conv
与相乘代表定位支路专注于定位任务,其中λ
conv
和λ
fc
设置分别为0.8和0.7。
[0109]
样本框的定位结果表示如下:
[0110]
d
*(x,y,w,h)
(a)=w
*t
*φ(a);
[0111]
其中φ(a)是对应样本框和特征图组成的特征向量,w
*
是需要学习的参数,d
*
(a) 是通过网络训练不断拟合数据得到的x,y,w,h,通过引入soomth
‑
l1损失函数计算样本框与真实标注值的差异值,smooth
‑
l1损失函数如下:
[0112][0113]
当差异值最小的时候就得到了物体的定位数据,通过反向传播计算梯度值,调节权重值来更新数据。经过不断反复更新计算,使得d
*
(a)拟合越来越靠近真实标注框。
[0114]
在步骤
②
中:
[0115]
经过1*1024全连接层得到一组特征向量,再用softmax对其进行类型识别, softmax函数公式如下:
[0116][0117]
经过softmax计算后输出每个特征向量的相对概率,特征向量最大的类别即为最后输出的类别。定位结果则直接使用定位支路的结果。
[0118]
在步骤3中,将需要检测病树的无人机图片进行裁剪,投入深度学习模型中进行检测。
[0119]
在步骤4中,将检测图像拼接,通过检测框左上角横纵坐标(x1,y1),右下角的横纵坐标(x2,y2),计算检测框的中心点的坐标值,计算公式如下:
[0120][0121]
将结果矢量化,位置配准,得到病树的精确位置。
[0122]
在步骤5中,对识别结果的错误样本进行筛选,要获取高鲁棒性的模型,错误样本的学习也是必须的,在数百平方公里的遥感影像内存在各种类型的地物,其中可能包含大量与病树相似的近似样本,模型容易对这些近似样本检测错误。对识别结果的错误样本进行整理,与训练集一起放入模型中再次训练,可以使模型获得区别错误样本的能力。经过反复迭代,最后可以得到高鲁棒性的检测模型。
[0123]
一种采样阈值区间加权方法,其特征在于,包括以下步骤:
[0124]
步骤1:对整体样本的iou阈值区间进行划分,将iou阈值区间按照正负样本分为两个区间;
[0125]
步骤2:在两个区间内划分难易样本区间,按照l的阈值区间将x以下及以上的区间各划分为k个阈值区间,并对难例样本区间进行加权。
[0126]
所采用的加权公式如下:
[0127]
[0128][0129]
s
k
为不同batch中的候选采样数,n为采样数,k为划分的区间数,将整个阈值区间均匀划分为k个区间,c为若整体采样数不够n值,则从整体样本空间内进行随机采样。
[0130]
如果整体采样数量没有达到候选采样数,则进行随机采样补齐,σ为加权系数,加权系数中n
max
代表整个样本空间的样本数,n
h
表示当前阈值区间内样本数量,样本空间阈值的整体走向是呈u型的,整个样本空间内的样本数是恒定的,在难例样本区间内采样的数量相对于容易样本的采样数量是较为稀少的,实验将k个区间分为简单样本区间和困难样本区间,取样本空间两端的区间ψ为简单样本区间,其余为困难样本区间,在不同的样本区间内使用不同的加权系数σ,抑制简单样本提高困难样本的采样比例,经过采样网络对预选框进行筛选后,剩余的预选框被当做样本框送入网络检测头部分对样本框进行类型识别定位。
[0131]
一种采样阈值区间加权方法,它考虑到了训练中存在的样本不均衡问题和样本难易程度问题,随机采样方法是在样本空间内对所有的样本进行随机采样,不判断样本的正负性以及难易程度,而由于正负样本的比例差距过大,使得随机采样法会偏向大量采集简单的负样本,大量的简单负样本对网络训练没有任何帮助,还会主导训练损失,使模型不能很好拟合带有正样本信息样本,影响模型精度。本方法对网络训练需要的困难样本提高其占比权重,减小网络不需要的简单的样本的占比权重,考虑到了网络的正负样本失衡和判断困难简单样本,通过对样本权重进行调整,提高了网络学习样本的质量,获得更好的训练效果。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。

