1.本公开涉及集成电路技术领域,尤其涉及一种存内计算装置及运算装置。
背景技术:
2.在全球数据量井喷式增长的今天,现有计算系统正遭遇“存储墙”的严峻挑战。基于冯诺依曼体系架构的传统计算系统中计算单元和存储单元物理分离,数据在两者之间频繁调动造成系统功耗和速度的严重损耗。存算一体这一计算模式是解决“存储墙”瓶颈的一个重要方案,目前已经有很多基于传统或新兴器件的存内计算电路、系统和架构的研究成果。
3.然而,相关技术中的存算一体解决方案存在复杂度高、运算开销大、准确性低等问题。
技术实现要素:
4.根据本公开的一方面,提供了一种存内计算装置,所述装置包括:
5.计算阵列,包括多个存内计算模块,所述存内计算模块包括第一字线、第二字线、第三字线、第一位线、第二位线、第三位线、第四位线、第一存储单元及第二存储单元,所述第一存储单元及所述第二存储单元均连接于所述第一字线、所述第二字线、所述第三字线,所述第一存储单元还连接于所述第一位线、所述第二位线,所述第二存储单元还连接于所述第三位线、所述第四位线;
6.控制模块,连接于所述计算阵列,用于:控制所述第一字线、所述第三字线的电压状态,以控制所述存内计算模块的工作模式为写模式、读模式及保持模式的任意一种,
7.其中,在所述写模式下,所述控制模块通过所述第一位线及所述第三位线,向所述存内计算模块写入数据;在所述读模式下,所述控制模块通过所述第二位线、所述第四位线及所述第二字线从所述存内计算模块读取数据;在所述保持模式下,所述控制模块用于保持所述存内计算模块的状态。
8.在一种可能的实施方式中,所述第一存储单元包括第一晶体管、第二晶体管、第一存储电容,所述第二存储单元包括第三晶体管、第四晶体管、第二存储电容,其中,
9.所述第一晶体管及所述第三晶体管的第一端均连接于所述第一字线,所述第一晶体管的第二端连接于所述第一位线,所述第三晶体管的第二端连接于所述第三位线,
10.所述第一晶体管的第三端、第二所述晶体管的第一端及所述第一存储电容的第一端相连形成第一节点,第三晶体管的第三端、第四所述晶体管的第一端及所述第二存储电容的第一端相连形成第二节点,
11.所述第二晶体管及所述第四晶体管的第三端均连接于所述第二字线,所述第二晶体管的第二端连接于所述第二位线,所述第四晶体管的第二端连接于所述第四位线,
12.所述第一存储电容及所述第二存储电容的第二端均连接于所述第三字线。
13.在一种可能的实施方式中,所述控制模块通过所述第一位线及所述第三位线,向
所述存内计算模块写入数据,包括:
14.所述控制模块根据待写入数据的值,从所述第一存储单元及所述第二存储单元确定目标存储单元;
15.根据所述待写入数据的值配置所述第一位线、所述第三位线的电压以向所述目标存储单元写入所述待写入数据。
16.在一种可能的实施方式中,在所述写模式下,所述控制模块还用于:
17.若所述待写入数据的值为正数,则写入所述待写入数据的相反数到所述目标存储单元;或
18.若所述待写入数据的值为负数,则直接写入所述待写入数据到所述目标存储单元,
19.其中,正的写入数据与负的写入数据对应的目标存储单元不同。
20.在一种可能的实施方式中,当所述第一存储单元及所述第二存储单元中的其中一个用于写入数据时,另一个用于存储参考数据,其中,用于写入数据的存储单元的节点的电压为负电压,所述第一存储单元及所述第二存储单元中各个第二晶体管均处于关断状态。
21.在一种可能的实施方式中,所述控制模块用于:
22.将所述第一字线配置为高电压、将所述第三字线配置为低电压,以控制所述存内计算模块工作于所述写模式;
23.将所述第一字线配置为低电压、将所述第三字线配置为高电压,以控制所述存内计算模块工作于读模式;
24.将所述第一字线、所述第三字线均配置为低电压,以控制所述存内计算模块工作于保持模式,在保持模式下,各个存储单元的节点状态不变。
25.在一种可能的实施方式中,所述控制模块还用于:
26.根据输入数据配置所述第二字线的电压;
27.所述控制模块通过所述第二位线、所述第四位线及所述第二字线从所述存内计算模块读取数据,包括:
28.读取所述第二位线及所述的第四位线的电流;
29.根据所述第二位线及所述第四位线的电流差值得到所述输入数据及所述存内计算模块存储的数据的乘积。
30.在一种可能的实施方式中,所述计算阵列包括m行n列,其中,m、n均为大于0的整数,所述计算阵列中同一行的多个存内计算模块的第一字线、第二字线、第三字线分别相连,和/或,所述计算阵列中同一列的多个存内计算模块的第一位线、第二位线、第三位线、第四位线分别相连。
31.在一种可能的实施方式中,所述装置中每列存内计算模块包括多条读出通路,所述控制模块用于从各条读出通路读出多个数据,并对读出的多个数据进行加和处理,
32.其中,对于不需读出数据的各行,所述控制模块用于控制各行存内计算模块工作于保持模式。
33.在一种可能的实施方式中,所述控制模块还用于:
34.控制所述计算阵列中的第一数目的存内计算模块工作于写模式,控制所述计算阵列中的第二数目的存内计算模块工作于读模式,控制所述计算阵列中第一数目及第二数目
以外的其余存内计算模块工作于保持模式。
35.在一种可能的实施方式中,所述第一晶体管的漏电流小于预设值。
36.根据本公开的一方面,提供了一种运算装置,所述装置包括第一组件及第二组件,其中,
37.所述第一组件包括:
38.传感器阵列,所述传感器阵列用于进行数据采集,得到多个输入数据;
39.所述的存内计算装置,用于接收所述多个输入数据并从所述第二组件接收多个待写入数据,并得到各个输入数据及各个待写入数据的乘积和;
40.所述第二组件用于输出所述多个待写入数据,并对所述乘积和进行处理,得到处理结果。
41.本公开实施例提出的存内计算装置包括多个存内计算模块及控制模块,所述存内计算模块包括第一字线、第二字线、第三字线、第一位线、第二位线、第三位线、第四位线、第一存储单元及第二存储单元,控制模块控制所述第一字线、所述第三字线的电压状态,以控制所述存内计算模块的工作模式为写模式、读模式及保持模式的任意一种,本公开实施例的存内计算装置,具有存算一体的特点,在进行运算特别是大规模运算时,可以避免数据在分离架构的计算单元和存储单元之间频繁跳动造成的系统功耗高及运算速度慢的问题,具有低电路复杂度、低功耗、高准确度、较快运算速度的特点。
42.应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,而非限制本公开。根据下面参考附图对示例性实施例的详细说明,本公开的其它特征及方面将变得清楚。
附图说明
43.此处的附图被并入说明书中并构成本说明书的一部分,这些附图示出了符合本公开的实施例,并与说明书一起用于说明本公开的技术方案。
44.图1示出了相关技术中的近似非易失存储单元的示意图。
45.图2示出了相关技术中实现存内矩阵向量乘的示意图。
46.图3示出了根据本公开一实施例的存内计算装置的示意图。
47.图4示出了根据本公开一实施例的存内计算模块的示意图。
48.图5示出了根据本公开一实施例的运算装置的示意图。
49.图6a、图6b示出了对本公开实施例的存内计算装置的线性度分析的示意图。
50.图7示出本公开实施例的存内计算模块的读写仿真波形的示意图。
51.图8a及图8b示出了本公开实施例的存内计算模块保持时间分析以及蒙特卡洛仿真结果的示意图。
52.图9示出了根据本公开实施例的运算装置应用于第一层计算时在数据集上的性能表现的示意图。
53.图10a、图10b示出了本公开实施例的运算装置与传统数字处理器的对比结果的示意图。
具体实施方式
54.以下将参考附图详细说明本公开的各种示例性实施例、特征和方面。附图中相同的附图标记表示功能相同或相似的元件。尽管在附图中示出了实施例的各种方面,但是除非特别指出,不必按比例绘制附图。
55.在本公开的描述中,需要理解的是,术语“长度”、“宽度”、“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底”、“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本公开和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本公开的限制。
56.此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括一个或者更多个该特征。在本公开的描述中,“多个”的含义是两个或两个以上,除非另有明确具体的限定。
57.在本公开中,除非另有明确的规定和限定,术语“安装”、“相连”、“连接”、“固定”等术语应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或成一体;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通或两个元件的相互作用关系。对于本领域的普通技术人员而言,可以根据具体情况理解上述术语在本公开中的具体含义。
58.在这里专用的词“示例性”意为“用作例子、实施例或说明性”。这里作为“示例性”所说明的任何实施例不必解释为优于或好于其它实施例。
59.本文中术语“和/或”,仅仅是一种描述关联对象的关联关系,表示可以存在三种关系,例如,a和/或b,可以表示:单独存在a,同时存在a和b,单独存在b这三种情况。另外,本文中术语“至少一种”表示多种中的任意一种或多种中的至少两种的任意组合,例如,包括a、b、c中的至少一种,可以表示包括从a、b和c构成的集合中选择的任意一个或多个元素。
60.另外,为了更好地说明本公开,在下文的具体实施方式中给出了众多的具体细节。本领域技术人员应当理解,没有某些具体细节,本公开同样可以实施。在一些实例中,对于本领域技术人员熟知的方法、手段、元件和电路未作详细描述,以便于凸显本公开的主旨。
61.如背景技术所述,相关技术中的存算一体解决方案存在复杂度高、运算开销大、准确性低等问题,例如,请参阅图1,图1示出了相关技术中的近似非易失存储单元的示意图。
62.其中,近似非易失存储单元也称非易失氧化物半导体随机存取存储器(nonvolatile oxide semiconductor ram,nosram)。如图1所示,在结构上,所述近似非易失存储单元为2t1c结构,即,所述近似非易失存储单元包括2个晶体管(transistor,简称t)和1个电容(capacitor,简称c),因此,该单元也可称为2t1c增益单元。进一步地,该单元中的两个晶体管分别为氧化物半导体场效应晶体管(oxide semiconductor fets,os
‑
fet)以及硅基场效应晶体管(即,si
‑
fet)。
63.如图1所示,os
‑
fet的漏极分别与si
‑
fet的栅极以及电容的一端相连,形成存储节点sn(storage node)。此外,位线wbl、位线rbl以及线sl为列方向上的线(即,列线),字线wwl和字线rwl为行方向上的线(即,行线),所述行线和列线用于控制图1中两个晶体管以及电容的工作状态,以便对数据进行读写。
64.在图1中的所述单元中,用于写入操作的os
‑
fet被堆叠在用于读取操作的si
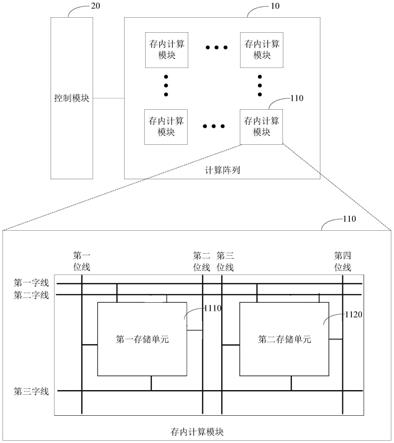
‑
fet上,通过os
‑
fet在存储节点sn存储的电荷不会泄露。由于os
‑
fet具有极低的关态(off
‑
state)电流(即,漏电流),因此图1中存储节点存储的数据能够保持较长的时间,降低了数据的刷新频率;相比于1t1c结构而言,图1中电容(即,cs)的值可以更小,因此,读写速度也更快。然而,图1的方案没有兼顾到存内计算,也没有与近传感应用相配合。
65.图2示出了相关技术中实现存内矩阵向量乘的示意图。
66.如图2所示,可使用基于os
‑
fet/si
‑
fet混合结构的模拟乘法器来模拟神经网络中权重的存储,从而实现存内矩阵向量乘的操作。所述模拟乘法器与图1中的2t1c增益单元基本相同。值得注意的是,该模拟乘法器的si
‑
fet已经预先接地,图2中的os
‑
fet采用的是基于铟
‑
镓
‑
锌系氧化物(in
‑
ga
‑
zn oxide,igzo)的os
‑
fet。
67.如图2所示,左侧虚线圆圈示出了所述模拟乘法器的结构。在图2中,所述存储单元以及参考单元均可使用相同的所述模拟乘法器的结构。所述模拟乘法器通过os
‑
fet控制向电容(即,节点fn)写入电荷来实现写入操作,包括写模式、保持模式以及读模式。和图1一样,由于os
‑
fet关态电流极小,节点fn的电荷能够长时间保持。为便于对后续本公开实施例的理解,这里对图2中模拟乘法器的工作原理作简要介绍。
68.如图2所示,在写模式下,ww偏置在高电压,vx偏置在0;电压w0 w被施加到bw上。此时os
‑
fet处于导通状态,电压w0 w被写入到节点fn。这个操作也可被简称为“写w”w。
69.如图2所示,在保持模式下,ww偏置在低电压,vx偏置在0,此时os
‑
fet处于截止状态,节点fn上的电压w0 w处于保持状态,该节点的电荷的保持时间通过调整os
‑
fet的关态电流进行改变。
70.如图2所示,在读模式下,ww偏置在低电压,电压x0 x被施加到vx上,以便为模拟乘法器提供读取电流。此时,si
‑
fet的漏极电流(即,读取电流)为i(w,x),si
‑
fet工作在饱和区。在一定的近似范围内,i(w,x)=(β/2)(w0 w x0 x
‑
v
th
)2。其中,β可以是饱和迁移率、沟道的宽长比和单位面积的栅电容这三者的乘积,v
th
表示si
‑
fet的阈值电压。此外,si
‑
fet的漏极电流还满足下列等式:
71.y=i(w,x)
‑
i(0,x)
‑
i(w,0) i(0,0)=βwx。
72.也就是说,y可以从四个条件下的读取电流计算得到,所述四个条件可以是写入权重0或w以及输入0或x。将四个条件下的读取电流进行加减,即可得到权重w与输入x的乘积。由于多个模拟乘法器可以用矩阵(或者行列)方式进行排列,因此多个模拟乘法器能够实现矩阵向量乘的操作。
73.如图2所示,除了存储单元和参考单元,还需要配置偏置单元,以便控制或响应所述存储单元和参考单元。所述偏置电路包括电流源、电流镜(图2中的左半部分)、电流槽以及模拟开关。所述电流源由两个os
‑
fet、一个p沟道的si
‑
fet和一个电容组成;所述电流槽由两个os
‑
fet、一个n沟道的si
‑
fet和一个电容组成。其中,p沟道的si
‑
fet提供恒定的电流,n沟道的si
‑
fet吸收电流。
74.在图2中,还设置有6根行方向的控制线(图2中模拟开关附近,未注释),用于控制整个偏置单元的工作模式。例如,在所述偏置单元工作模式为读模式的情况下,存储单元的读取电流为i(w,x),参考单元的读取电流为i(0,x),电流源提供电流i(w,0),电流槽提供电流i(0,0)。根据这四个电流可计算y的值,从而实现神经网络的权重和输入的乘积。
75.由此可见,相关技术中实现矩阵相乘的技术方案结构十分复杂,一个存储单元要搭配另外三个额外的辅助单元以及大量中间布线和控制信号,控制复杂,额外能量开销大,面积利用率低。此外,传统的传感
‑
数字处理器数据流中需要大量的模数转换和缓存,造成了大量的能量消耗。从传感器读取数据后,立即在模拟域中进行数据预处理可以有效避免这一开销,提高能效。为了达到这一目标,传感和计算的数据通路应相互匹配以提高数据利用率。然而,传统的逐行扫描方式每次读出的数据为一整行,与二维卷积中每次处理的数据(一个卷积核)不相同,这就需要大量的数据缓存和复杂的数据调度。而二维卷积是大多数图像处理算法的基础,这就导致现有的近传感存内计算功能十分受限。
76.本公开实施例提出的存内计算装置包括多个存内计算模块及控制模块,所述存内计算模块包括第一字线、第二字线、第三字线、第一位线、第二位线、第三位线、第四位线、第一存储单元及第二存储单元,控制模块控制所述第一字线、所述第三字线的电压状态,以控制所述存内计算模块的工作模式为写模式、读模式及保持模式的任意一种,本公开实施例的存内计算装置,具有存算一体的特点,在进行运算特别是大规模运算时,可以避免数据在分离架构的计算单元和存储单元之间频繁跳动造成的系统功耗高及运算速度慢的问题,本公开实施例的存内计算装置具有结构简单、低电路复杂度、低功耗、高准确度、较快运算速度的特点。
77.本公开实施例的存内计算装置可以设置于终端设备、服务器或其它类型的电子设备中,其中,终端设备可以为用户设备(user equipment,ue)、移动设备、用户终端、终端、蜂窝电话、无绳电话、个人数字处理(personal digital assistant,pda)、手持设备、计算设备、车载设备、可穿戴设备等。并可以应用于多种领域中,如图像处理领域、大数据等,只要需要多值输入、多支存储,并进行乘法运算、实现矩阵乘法的计算均可以运用,例如,可以支持多种图像预处理算法,对神经网络的输入数据及权重数据执行矩阵乘法,以降低模数转换和缓存的使用,提高处理速度及能效水平。
78.请参阅图3,图3示出了根据本公开一实施例的存内计算装置的示意图。
79.如图3所示,所述装置包括:
80.计算阵列10,包括多个存内计算模块110,所述存内计算模块110包括第一字线、第二字线、第三字线、第一位线、第二位线、第三位线、第四位线、第一存储单元1110及第二存储单元1120,所述第一存储单元1110及所述第二存储单元1120均连接于所述第一字线、所述第二字线、所述第三字线,所述第一存储单元1110还连接于所述第一位线、所述第二位线,所述第二存储单元1120还连接于所述第三位线、所述第四位线;
81.控制模块20,连接于所述计算阵列10,用于:控制所述第一字线、所述第三字线的电压状态,以控制所述存内计算模块110的工作模式为写模式、读模式及保持模式的任意一种,其中,在所述写模式下,所述控制模块20通过所述第一位线及所述第三位线,向所述存内计算模块110写入数据;在所述读模式下,所述控制模块20通过所述第二位线、所述第四位线及所述第二字线从所述存内计算模块110读取数据;在所述保持模式下,所述控制模块20用于保持所述存内计算模块110的状态。
82.本公开实施例的控制模块20可以包括处理组件,在一个示例中,处理组件包括但不限于单独的处理器,或者分立元器件,或者处理器与分立元器件的组合。所述处理器可以包括电子设备中具有执行指令功能的控制器,所述处理器可以按任何适当的方式实现,例
如,被一个或多个应用专用集成电路(asic)、数字信号处理器(dsp)、数字信号处理设备(dspd)、可编程逻辑器件(pld)、现场可编程门阵列(fpga)、控制器、微控制器、微处理器或其他电子元件实现。在所述处理器内部,可以通过逻辑门、开关、专用集成电路(application specific integrated circuit,asic)、可编程逻辑控制器和嵌入微控制器等硬件电路执行所述可执行指令。在一个示例中,处理组件可以包括电压产生单元以根据需要产生对应的电压、电压转换单元将第一电压转换为第二电压或将输入的数据转换为相应的电压或将电压转换为数据等器件,本公开实施例对控制模块2020的具体实现方式不做限定,其各个器件、处理器等可以根据需要采用相关技术中的器件实现,只要可以实现本公开实施例的各个控制功能即可。
83.在一种可能的实施方式中,所述计算阵列10包括m行n列,其中,m、n均为大于0的整数,本公开实施例对计算阵列10的规模不做限定,本领域技术人员可以根据需要设置,以提高本公开实施例的存内计算装置的灵活性及适应性。
84.在一种可能的实施方式中,所述计算阵列10中同一行的多个存内计算模块110的第一字线、第二字线、第三字线分别相连,以实现第一字线、第二字线、第三字线的共用,减少线路开销、控制开销,提高资源利用率。
85.在一种可能的实施方式中,所述计算阵列10中同一列的多个存内计算模块110的第一位线、第二位线、第三位线、第四位线分别相连,以实现第一位线、第二位线、第三位线、第四位线的共用,减少线路开销、控制开销,提高资源利用率。
86.在一种可能的实施方式中,所述装置中每列存内计算模块110包括多条读出通路,所述控制模块20用于从各条读出通路读出多个数据,并对读出的多个数据进行加和处理,以实现矩阵相乘运算。
87.在一个示例中,对于不需读出数据的各行,所述控制模块20用于控制各行存内计算模块110工作于保持模式,维持各个不需操作的存内计算模块110的内部节点的状态不变,以降低系统开销。
88.在一种可能的实施方式中,所述控制模块20还用于:
89.控制所述计算阵列10中的第一数目的存内计算模块110工作于写模式,控制所述计算阵列10中的第二数目的存内计算模块110工作于读模式,控制所述计算阵列10中第一数目及第二数目以外的其余存内计算模块110工作于保持模式。
90.本公开实施例通过对计算阵列10划定区域,可以实现资源的有效利用,例如,若存在多个任务,或一个大的任务划分的多个小任务,各个任务需要的资源之和小于该计算阵列10所能提供最大资源,则可以将各个任务同步进行,如第一数目的存内计算模块110可以用于写入数据,执行存储功能;第二数目对应的存内计算模块110可以将两个数据(如神经网络的输入数据及权重数据)进行矩阵相乘,这样,本公开实施例可以充分发挥结构简单、低电路复杂度、低功耗、高准确度、较快运算速度的特点,通过多任务共同执行,以提高运算效率。
91.本公开实施例的计算阵列10中,各个存内计算模块110的第一存储单元1110及第二存储单元1120可以具有相同或相似的结构,并且,第一存储单元1110及第二存储单元1120可以有多种实现方式,下面进行示例性介绍。
92.请参阅图4,图4示出了根据本公开一实施例的存内计算模块的示意图。
93.在一种可能的实施方式中,如图4所示,所述第一存储单元1110可以包括第一晶体管q1、第二晶体管q2、第一存储电容c1,所述第二存储单元1120可以包括第三晶体管q3、第四晶体管q4、第二存储电容c2,其中,
94.所述第一晶体管q1及所述第三晶体管q3的第一端1均连接于所述第一字线,所述第一晶体管q1的第二端2连接于所述第一位线,所述第三晶体管q3的第二端2连接于所述第三位线,
95.所述第一晶体管q1的第三端3、第二所述晶体管的第一端1及所述第一存储电容c1的第一端1相连形成第一节点n1,第三晶体管q3的第三端3、第四所述晶体管的第一端1及所述第二存储电容c2的第一端1相连形成第二节点n2,
96.所述第二晶体管q2及所述第四晶体管q4的第三端3均连接于所述第二字线,所述第二晶体管q2的第二端2连接于所述第二位线,所述第四晶体管q4的第二端2连接于所述第四位线,所述第一存储电容c1及所述第二存储电容c2的第二端2均连接于所述第三字线。
97.在一个示例中,如图4所示,第一晶体管q1、第二晶体管q2、第三晶体管q3、第四晶体管q4的第一端1均可以为晶体管的栅极,本公开实施例对各个晶体管的第二端2、第三端3中哪一个作为漏极,哪一个作为源极不做限定,本领域技术人员可以根据需要设置。
98.在一种可能的实施方式中,本公开实施例的所述第一晶体管q1可以采用具有低漏电特性的晶体管,以达到近似于非易失性存储器的效果,使得数据在存内计算模块110中可以保存较长时间,例如采用漏电流小于预设值的晶体管,本公开实施例对漏电流的预设值的大小不做限定,只要采用的晶体管可以满足低漏电特性即可,示例性的,预设值可以为10
‑
20
a,或其他。满足低漏电特性的晶体管可以包括多种,本公开实施例对晶体管的类型不做限定,例如可以包括氧化物半导体场效应晶体管os
‑
fet或者薄膜晶体管(thin film transistor,tft),所述第二晶体管q2例如可以包括si
‑
fet。
99.薄膜晶体管具有的优势可以使其应用于存内计算中时具有较高的性能。首先,薄膜晶体管广泛应用于传感阵列中,可以实现存算一体阵列与传感单元的融合,将“感、存、算”结合到一起,进一步降低数据调动的开销;其次,目前已经有一些工作利用氧化物薄膜晶体管实现近似于非易失的存储器甚至存内计算阵列10;另外,薄膜晶体管的许多独特优势如透明性、柔性、大面积集成等使其具有更为广泛的应用场景,对推动存内计算以及智能传感的进一步发展提供了新的发展方向。一般的igzo(indium gallium zinc oxide,铟镓锌氧化物)tft可以达到10
‑
16
a/m的漏电水平,而经过特殊工艺后,这一数值甚至能达到更低。低漏电在存储应用中是非常好的性质,以dram结构为例,传统cmos dram结构中由于漏电电流较高,需要不断进行刷新,而使用低漏电tft技术可以大大降低dram的刷新频率,节省能量,增大访问时间窗口。除了易失性存储之外,这种低电流还可以应用于近似于非易失存储器中。因此薄膜晶体管在存算一体这一领域具有巨大的潜力。
100.相关技术中存在利用tft实现存内计算的方案,然而相关技术存在以下问题:
101.1.目前的tft存储器和tft存内计算没有得到很好的结合。一方面,tft存储器进展迅速,在很多方面表现出优势,但这些工作都没有兼顾到存内计算,具体表现为,不支持多值存储和多值输入,不支持存内矩阵向量乘计算模式;而另一方面,现有的tft存内计算工作都需要相当大的额外开销。例如需要在一个存储单元上同时配置额外的3个辅助单元,使用非常复杂的电流加减关系才能得到运算结果,或者由于采用浮栅结构,写入非常复杂,造
成巨大的额外开销。
102.2.目前的tft存内计算工作精度与电路复杂度之间存在着权衡关系,如果要实现准确度较高的计算,则需要非常复杂的电路设计,而如果要以简单的电路设计来实现存内计算,则往往矩阵向量乘的关系不够理想,或者只支持低比特数的运算。目前仍然缺少一个既能支持较为准确的高精度乘法运算,同时结构又相对简单的tft存内计算实现方式。
103.3.目前的tft近传感存内计算工作所支持的数据流非常有限,传感器和处理器没有很好地配合起来。例如,相关技术中的核心都是矩阵向量乘,但是没有考虑近传感的应用,而且,相关技术中因为从传感阵列到处理器的数据流没有经过特别设计,因此只能进行单一算法的处理。在传感读取方面,这些工作均采用了逐行扫描的方式,因此非常不适合进行二维滤波操作,而这反而正是图像处理中非常重要的操作。目前仍然缺乏一个较为通用的近传感存内计算方案。
104.本公开实施例的存内计算模块110可以基于tft实现,且可以利用tft工艺实现大面积集成,通过增大电路面积进一步增加数据保持的时间,以降低运算时的刷新频率,达到节省能量、增大访问时间窗口的目的,以提高矩阵运算的完整性、准确性,结合本公开实施例提出的存内计算模块110的电路架构,可以克服相关技术中的缺点,使得存内计算模块110具有低电路复杂度、低功耗、高准确度、较快运算速度的特点更加显著。
105.下面对控制模块20的控制功能的实现方式进行示例性介绍。
106.在一种可能的实施方式中,所述控制模块20可以用于:
107.将所述第一字线配置为高电压、将所述第三字线配置为低电压,以控制所述存内计算模块110工作于所述写模式。
108.本公开实施例通过将所述第一字线配置为高电压、将所述第三字线配置为低电压,以控制所述存内计算模块110工作于所述写模式,可以实现将数据存储到存内计算模块110中。
109.在一个示例中,以所述第一晶体管q1、第二晶体管q2、第三晶体管q3、第四晶体管q4均为n沟道的器件为例,在开始对数据进行写入时,可将所述第一字线偏置在高电压(如10v)、将所述第三字线配置为低电压(如0v,例如接地),即,给所述第一字线施加控制信号以使第一存储单元1110的第一晶体管q1以及第二存储单元1120中的第三晶体管q3均导通,此时,第一存储单元1110中的第一节点n1与第一位线短路连接,第二存储单元1120中的第二结点与第三位线短路连接,第一位线上的电压能够即时施加到第一存储单元1110的第一节点n1上,第三位线上的电压能够即时施加到第二存储单元1120的第二节点n2上。
110.示例性的,通过将第三字线配置为低电压,可以为所述第一存储电容c1及所述第二存储电容c2提供参考电压。示例性的,在所述存内计算模块110模块对数据进行写入时,第一存储单元1110的第二晶体管q2以及第二存储单元1120中的第四晶体管q4均可处于截止状态(即,关断状态)。
111.在一种可能的实施方式中,所述控制模块20通过所述第一位线及所述第三位线,向所述存内计算模块110写入数据,可以包括:
112.所述控制模块20根据待写入数据的值,从所述第一存储单元1110及所述第二存储单元1120确定目标存储单元;
113.根据所述待写入数据的值配置所述第一位线、所述第三位线的电压以向所述目标
存储单元写入所述待写入数据。
114.在一种可能的实施方式中,在所述写模式下,所述控制模块20还可以用于:
115.若所述待写入数据的值为正数,则写入所述待写入数据的相反数到所述目标存储单元;或若所述待写入数据的值为负数,则直接写入所述待写入数据到所述目标存储单元,其中,正的写入数据与负的写入数据对应的目标存储单元不同。
116.在一种可能的实施方式中,当所述第一存储单元1110及所述第二存储单元1120中的其中一个用于写入数据时,另一个用于存储参考数据,其中,用于写入数据的存储单元的节点的电压为负电压,所述第一存储单元1110及所述第二存储单元1120中各个第二晶体管q2均处于关断状态。
117.在一个示例中,本公开实施例可根据待写入数据的值的正负确定将该数据将要写入的目标存储单元,以保证在目标存储单元的内部节点上写入的电压始终为负。例如,在待写入数据为负数(例如,
‑
0.8)时,可将该数据写入第一存储单元1110中;在待写入数据为正数(例如,0.8)时,可将该数据的相反数(即,
‑
0.8)写入第二存储单元1120中。值得注意的是,在将待写入数据通过第一位线或第三位线加载到所述存内计算模块110中的其中一个存储单元的内部节点时,所述存内计算模块110中的另外一个存储单元可作为参考单元。例如,无论是待写入数据为正数(例如0.8)还是负数(例如
‑
0.8),参考单元均写入0,通过目标存储单元和参考单元之差实现任意数据的存储。
118.本公开实施例根据待写入数据的值的正负确定将该数据将要写入的目标存储单元,能够保证在目标存储单元的内部节点上写入的电压始终为负,从而使得在第三字线为低电压的情况下第一存储单元1110的第二晶体管q2以及第二存储单元1120中的第四晶体管q4的栅源电压小于阈值电压,第一存储单元1110的第二晶体管q2以及第二存储单元1120中的第四晶体管q4始终处于关断状态,不需要额外将所述第三字线的电压设置为负电压来确保第一存储单元1110的第二晶体管q2以及第二存储单元1120中的第四晶体管q4关断;同时,通过根据待写入数据的值的正负确定将待写入数据将要写入的目标存储单元,也降低了输入的动态范围。
119.在一种可能的实施方式中,所述控制模块20可以用于:
120.将所述第一字线配置为低电压、将所述第三字线配置为高电压,以控制所述存内计算模块110工作于读模式;
121.本公开实施例通过将所述第一字线配置为低电压、将所述第三字线配置为高电压,以控制所述存内计算模块110工作于读模式,在读模式下,可以读取输入数据及所述存内计算模块110存储的数据的乘积,以实现矩阵相乘。
122.在一种可能的实施方式中,所述控制模块20还可以用于:
123.根据输入数据配置所述第二字线的电压;
124.所述控制模块20通过所述第二位线、所述第四位线及所述第二字线从所述存内计算模块110读取数据,可以包括:
125.读取所述第二位线及所述的第四位线的电流;
126.根据所述第二位线及所述第四位线的电流差值得到所述输入数据及所述存内计算模块110存储的数据的乘积。
127.通过以上装置,本公开实施例的所述控制模块20可以对存内计算模块110的数据
进行读取。以所述第一晶体管q1、第二晶体管q2、第三晶体管q3、第四晶体管q4均为n沟道的器件为例,在开始对数据进行读取时,可将所述第一字线配置为低电压(如
‑
4v)、将第三字线的电压设置为高电压(如18v),以使得存内计算模块110进入读取模式。示例性的,通过将第三字线的电压设置为高电压,可以以便为计算阵列10中该第三字线对应的该行的所有的第二晶体管q2及第四晶体管q4提供一个较高的栅极电压,从而使该行的所有的第二晶体管q2及第四晶体管q4均处于线性区。示例性的,所述第三字线还兼具行选择的作用,对于不需要读取的行,第三字线可仍然保持为低电平(如0v),以使得这些不需要进行读取行进入写模式或进入保持模式,在第三字线可仍然保持为0的情况下,由于本公开实施例中的存储单元的内部节点的电压始终为负电压,因此可以保证该行的第二晶体管q2及第四晶体管q4的栅源电压低于阈值电压,进而保证所述存内计算模块110读操作的正确性。相比于传统的行列开关,采用第三字线进行行选择不会对输出通路造成分压,从而影响乘法运算的结果。
128.在一个示例中,在对所述存内计算模块110的数据进行读取时,需要保持输出电流与存储的数据(如神经网络的权重值)和输入电压(如神经网络的输入数据对应的电压)的乘积之间满足线性关系,而是否满足线性关系可通过所述第二晶体管q2、第四晶体管q4线性区工作时读出的电压决定。其中,输出电流可以是第一存储单元1110或第二存储单元1120中的第二晶体管q2、第四晶体管q4源漏之间的电流,或者称漏极电流,所述存储的数据可以是第一存储单元1110或第二存储单元1120中的内部节点所存储的数据,输入电压可以是所述第二晶体管q2或第四晶体管q4的栅源电压。
129.在一个示例中,在第一存储单元1110以及第二存储单元1120中的第二晶体管q2及第四晶体管q4位于线性区的情况下,所述第二晶体管q2及第四晶体管q4的漏源之间电流与各端口电压之间的关系近似可以由公式1表示:
[0130][0131]
其中,k可以表示饱和迁移率、沟道的宽长比和单位面积的栅电容的常数;vgs可表示所述存内计算模块110中任一第二晶体管q2或任一第四晶体管q4的栅源电压;vds可表示所述存内计算模块110中任一第二晶体管q2或任一第四晶体管q4的漏源电压;ids可表示所述存内计算模块110中任一第二晶体管q2或任一第四晶体管q4的漏源之间的电流;vth可表示所述存内计算模块110中任一第二晶体管q2或任一第四晶体管q4的阈值电压。
[0132]
示例性的,由于所述第二晶体管q2的源漏之间的电流等于第二晶体管q2漏源的之间的电流,由于所述第四晶体管q4的源漏之间的电流等于第四晶体管q4漏源的之间的电流,因此,电流或电压方向的不同并不影响本发明的发明实质。
[0133]
在本公开实施例中,第一存储单元1110的第二晶体管q2的栅源电压与第二存储单元1120的第四晶体管q4的栅源电压的差值可以为写入的数据电压(如写入的内部节点上的权重值对应的权重电压)。此时,第一存储单元1110的第二晶体管q2的源漏之间的电流与第二存储单元1120的第四晶体管q4的源漏之间的电流的差值可以由公式2表示:
[0134]
δi
ds
=i
ds
(v
gs
v
weight
,v
input
)
‑
i
ds
(v
gs
,v
input
)=kv
weight
v
input
ꢀꢀꢀ
公式2
[0135]
其中,v
weight
可以表示已经存储的内部节点上的电压,该电压的大小可以根据写入的数据值(权重值)的大小的不同而不同;v
input
可表示输入的电压值,通过第二字线进行施加;δi
ds
可表示所述电流差值。在一个示例中,第一存储单元1110的第二晶体管q2的源漏之
间的电流可从第二位线读出;第二存储单元1120的第四晶体管q4的源漏之间的电流可从第四位线读出。
[0136]
通过上述公式2可以得到输入数据(如神经网络的输入)和存储的数据(如神经网络的权重)的乘积。在公式2的基础上,可以同时导通所述存内计算装置的多行,将各行的输出可以进行加和,实现矩阵向量乘的操作。
[0137]
在一种可能的实施方式中,所述控制模块20可以用于:
[0138]
将所述第一字线、所述第三字线均配置为低电压(如
‑
4v),以控制所述存内计算模块110工作于保持模式,在保持模式下,各个存储单元的节点状态不变。
[0139]
示例性的,对于没有进行读写的行中的存内计算模块110存内计算模块110可处于保持状态,本公开实施例通过将所述第一字线、所述第三字线均配置为低电压,以控制所述存内计算模块110工作于保持模式,在保持状态下,每个存内计算模块110存内计算模块110中的内部节点均可保持在原来的状态不变,以降低功耗,提高资源利用率。
[0140]
下面对各个模式下各个字线、位线的电压配置进行示例性介绍。
[0141]
如表1所示,在一种可能的实现方式中,所述存内计算模块110可工作在三种工作模式:写模式、读模式以及保持模式。在不同的工作模式下,第一字线、第二字线、第一位线、第二位线和第三位线的电压设置有所不同。示例性的,在读写数据时,所述存内计算模块110中的其中一个存储单元可以作为参考单元,因此,表1中写模式的第一位线和第二位线也可以分别是第三位线和第四位线。
[0142]
表1
[0143] 写模式读模式保持模式第一字线10v
‑
4v
‑
4v第一位线[
‑
4v,0v]0v0v第二字线0v[0v,3v]0v第二位线0v0v0v第三字线0v18v0v
[0144]
当然,以上对各个模式中各个字线、位线的电压值描述是示例性的,不应视为是对本公开实施例的限定,本领域技术人员可以根据需要设置相应的值,例如,各个字线、位线的电压值还可以是以下范围中的任意一个。
[0145]
在写模式中,第一字线的电压范围可以是10~30v;第二字线的电压范围可以是:0~3v;第三字线的电压范围可以是18~30v;第一位线的电压范围可以是
‑
4~0v;第二位线的电压可以是0v(接地,如0v);第三位线的电压范围可以是
‑
4~0v;第四位线的电压可以是0v。
[0146]
在读模式中,第一字线的电压范围可以是
‑
15v~
‑
5v;第二字线的电压范围可以是0~3v;第三字线的电压范围可以是
‑
15~0v;第一位线的电压范围可以是
‑
15~15v;第二位线的电压可以是0v;第三位线的电压范围可以是
‑
15~15v;第四位线的电压可以是0v。
[0147]
应该明白的是,以上对各个模式下电压范围的描述,是针对某一种tft工艺下的电压范围的示例性的说明,应该理解的是,即使对于完全同类型的tft(例如金属氧化物tft),因为工艺的不同,工作电压会有着根本的差别,例如使用同样的材料,可以实现这里给出的工作电压在~10v左右的晶体管,也可以实现工作电压在~3v左右的,因此各个字线、位线
的电源范围可以根据实际情况确定,本公开实施例不做限定。
[0148]
请参阅图5,图5示出了根据本公开一实施例的运算装置的示意图。
[0149]
如图5所示,所述装置包括第一组件及第二组件,其中,
[0150]
所述第一组件可以包括:
[0151]
传感器阵列,所述传感器阵列用于进行数据采集,得到多个输入数据;
[0152]
所述的存内计算装置,用于接收所述多个输入数据并从所述第二组件接收多个待写入数据,并得到各个输入数据及各个待写入数据的乘积和;
[0153]
所述第二组件用于输出所述多个待写入数据,并对所述乘积和进行处理,得到处理结果。
[0154]
本公开实施例的运算装置包括第一组件及第二组件,所述第一组件可以包括:传感器阵列,所述传感器阵列用于进行数据采集,得到多个输入数据;所述的存内计算装置,用于接收所述多个输入数据并从所述第二组件接收多个待写入数据,并得到各个输入数据及各个待写入数据的乘积和;所述第二组件用于输出所述多个待写入数据,并对所述乘积和进行处理,得到处理结果。本公开实施例的存内计算装置,具有存算一体的特点,在进行运算特别是大规模运算时,可以避免数据在分离架构的计算单元和存储单元之间频繁跳动造成的系统功耗高及运算速度慢的问题,本公开实施例的存内计算装置具有结构简单、低电路复杂度、低功耗、高准确度、较快运算速度的特点。通过所述存内计算装置实现的运算装置,能够实现传感器阵列与存内计算装置之间的数据通路,支持多种图像预处理算法,降低了模数转换和缓存的使用,相比于传统数字运算单元更高的处理速度和能效水平。
[0155]
本公开实施例的传感器阵列可以包括多个传感器,传感器阵列可以用于采集图像或其他数据,所述传感器例如可以为ccd(charge
‑
coupled device,电荷耦合元件)、cmos(complementary metal oxide semiconductor,互补金属氧化物半导体)等光传感器,对此,本公开实施例不做限定。示例性的,传感器阵列可以被时限为照相机、摄像机等,如图5所示,传感器阵列可以通过扫描接口进行数据采集,采集到的输入数据可通过传感器读取接口输出,并进行排队处理,并按照队列的处理方式(如fifo、lifo等)输出到存内计算装置中。另一方面,存内计算装置可以接收第二组件的存储器中存储的待写入数据,并将待写入数据写入计算阵列10的存内计算模块110中,存内计算装置可以将待写入数据及输入数据进行计算(矩阵乘法),得到计算结果。示例性的,经过队列处理的输入数据可作为输入数据送到存内计算装置中,所述存内计算装置可接受来自权重写入接口的权重数据,经过存内计算装置进行处理后所得到的计算结果可以送入第二组件中。
[0156]
在一个示例中,如图5所示,第二组件还可以包括模拟单元(如可以包括补偿器、放大器等)、模数转换单元(例如模数转换器adc)、通信处理器,利用模拟单元可以对计算结果进行补偿、放大等模拟运算,经过模拟单元处理后的数据可以利用模数转换单元进行模数转换,得到例如二进制形式的数字量,并利用通信处理器进行处理。示例性的,经过模数转换后的数字形式的数据也可以存入存储器或者内存中。
[0157]
示例性的,通信处理器可以包括各种通用处理器,例如cpu(central processing unit,中央处理器),也可以是用于执行人工智能运算的人工智能处理器(ipu),人工智能处理器可例如包括gpu(graphics processing unit,图形处理单元)、npu(neural
‑
network processing unit,神经网络处理单元)、dsp(digital signal process,数字信号处理单
元)、现场可编程门阵列(field-programmable gate array,fpga)芯片中的一种或组合,是联系的,通信处理器还可以集成有数据传输的通信功能,例如可以实现与其他模块、其他设备的通信,例如可以接入基于通信标准的无线网络,如wifi,2g或3g,或它们的组合。
[0158]
示例性的,存储器可以包括计算机可读存储介质,计算机可读存储介质可以是可以保持和存储由指令执行设备使用的指令的有形设备。计算机可读存储介质例如可以是――但不限于――电存储设备、磁存储设备、光存储设备、电磁存储设备、半导体存储设备或者上述的任意合适的组合。计算机可读存储介质的更具体的例子(非穷举的列表)包括:便携式计算机盘、硬盘、随机存取存储器(ram)、只读存储器(rom)、可擦式可编程只读存储器(eprom或闪存)、静态随机存取存储器(sram)、可编程只读存储器(prom)、便携式压缩盘只读存储器(cd
‑
rom)、数字多功能盘(dvd)、记忆棒、软盘、机械编码设备、例如其上存储有指令的打孔卡或凹槽内凸起结构、以及上述的任意合适的组合。
[0159]
本公开实施例的运算装置支持近传感的应用,可以适用于多种算法的处理,支持的数据流可以包括多种,实现了传感器阵列和处理器的良好配合,非常适合二维滤波操作。
[0160]
本公开实施例利用包括tft的晶体管等晶体管的低漏电特性实现存内计算,实现存内计算装置,并进一步提出了一种近传感存内计算架构(所述运算装置)。所述存内计算装置、所述运算装置均可以应用于低功耗神经网络的预处理操作中。相比于相关技术,本公开实现了近似于非易失的存算一体的存内计算模块110及计算阵列10,可以以更为简单的电路结构实现精确的矩阵向量乘运算;同时实现了一种通用的大面积、实时数据处理的近传感存内计算架构,相比于现有的工作支持更多的算法,如二维卷积操作等。此外,本公开相比于传统数字处理单元能够实现速度以及能效的提升。
[0161]
下面对本公开实施例的存内计算装置、运算装置的性能的测试与仿真情况进行介绍。
[0162]
图6a、图6b示出了对本公开实施例的存内计算装置的线性度分析的示意图。
[0163]
如图6a、图6b所示,为测试矩阵向量乘的准确性,对本公开实施例的电路结构进行了电路仿真,得出了δids(读取模式中第二位线、第四位线的电流差值)与v
input
(第二字线的输入数据对应的电压)和v
weight
(存内计算模块110中的存储数据对应的电压)之间的关系,对于多组不同的v
input
和v
weight
,所有曲线线性回归的r2值都大于0.999,这一结果显示出了极好的线性关系,即输出电流与权重和输入之间的乘法关系成立,存内矩阵向量乘操作可行性得到了验证。
[0164]
图7示出本公开实施例的存内计算模块的读写仿真波形的示意图。
[0165]
如图7所示,为测试存内计算模块110的读(read)写(write)延时,对存内计算模块110的电路结构进行了瞬态仿真,得出了存内计算模块110的工作波形。为准确模拟阵列读取操作,此仿真考虑了的所有波形均与预期一致,且读频率最高可以达到15mhz。对于写操作来说,由于所选的第一晶体管q1、第三晶体管q3(如tft)导通电流较小,且为了增长保持时间,电容设置得较大,因此读操作所花费的时间相对较长,但在一般的边缘计算问题中,这一存储器并不需要频繁写入,且一般的刷新操作只需要对电压进行微调,用时相对短很多,因此写操作时间较长对整个系统影响不大,图7中,休眠表示standby。
[0166]
图8a及图8b示出了本公开实施例的存内计算模块保持时间分析以及蒙特卡洛仿真结果的示意图。
[0167]
如图8a所示,为测试近似非易失存储的保持时间,对存内计算模块110结构进行了模拟存储保持过程的电路仿真,在500s的时间后,漏电造成的误差仅为2%,这一误差在绝大部分问题中都是可以接受的,即此系统的刷新周期可以达到分钟量级,达到了较好的近似非易失特性。
[0168]
如图8b所示,为测试因为器件偏差造成的影响,对本公开实施例的电路进行了蒙特卡洛仿真(mc simulation samples),此时对结果影响最大的是阈值电压的偏差,在仿真中根据实际选用的器件模型,取整个计算阵列10上的阈值电压分布的标准差为0.3v,而相邻两个器件的均一性较好,取失配标准差为0.03v,并取权重量化间隔为0.5v,此时进行蒙特卡洛仿真得到了如图8b所示的输出电流分布,可以看到,各量化权重(存储数据)对应的电流分布之间没有交叠,即对于单个存内计算模块110,可以达到无符号3bit量化结果,而对于存内计算模块110对,则可以达到正负4bit量化结果。这表明存内计算模块110可以支持较高比特数的多值存储。
[0169]
本公开实施例在仿真时特别考虑了使用所述运算装置进行神经网络预处理的情况。神经网络在图像处理中的应用越来越广泛,而近年来兴起的二值化神经网络因为体量小、计算简单,更适合部署于终端系统上。然而,二值化网络的第一层一般都是全精度的,这一层的处理开销仍然非常大,不仅是计算开销,更有模数转换和数据缓存的开销。因此把这个最接近传感器的全精度层放到模拟域中计算,可以很大程度上降低计算开销,同时,由于后级神经网络的输入均为二值化,因此只需要使用非常简单的比较器替代高精度模数转换器即可,大大降低模数转换的开销。因此,用本公开实施例的近传感存内计算架构(运算装置)对二值神经网络进行预处理具有很大的优势。
[0170]
图9示出了根据本公开实施例的运算装置应用于第一层计算时在数据集上的性能表现的示意图。
[0171]
示例性的,在分析过程中选取了非常典型的二值化神经网络xnor
‑
net(当然,也可以应用于其他的神经网络,本公开不做限定),用这一网络对cifar
‑
10数据集进行分类。在第一层中,使用4bit量化精度的权重,而输出则是1bit。在部署过程中考虑到了三方面的误差:1)因为矩阵向量乘关系不准确导致的偏差;2)因为漏电而导致的权重衰减;3)因为器件偏差导致的随机噪声。最终此神经网络在此分类问题中的表现如图9所示,其中准确率基准线(bseline accuracy)代表理想全精度情况下的准确率,而各个点圈则代表在不同阈值电压偏差的情况下多次模拟的准确率(accuracy)。可以看到,在阈值电压失配(v
th mismatch)小于0.1v时,本公开实施例的运算装置的平均精度损失均在3%以内。
[0172]
图10a、图10b示出了本公开实施例的运算装置与传统数字处理器的对比结果的示意图。
[0173]
将本公开实施例的运算装置与传统数字处理器进行了对比,所采用的基准方案为一个32bit矩阵向量乘处理单元。在论证过程中,根据电路仿真的结果得出运算装置的处理延时和功耗,而对于基准数字电路方案,则采用synopsis design compiler(概要设计编译器)仿真出延时和功耗数据,同时对于额外的数据访存,采用cacti仿真器进行功耗和延时的估计。最终,两种方案的对比如图10a、图10b所示,图10a示出了延时(delay)对比示意图,图10b示出了功耗(power)对比示意图。因为采用了高并行度的矩阵向量乘操作,同时避免了高精度模数转换器的使用,本公开实施例的系统最多可以达到3.17倍的速度提升和9.57
倍的能效提升。
[0174]
其中,图10a中,近传感存内计算为(near
‑
sensor cim),其中cim表示computing
‑
in
‑
memory,存内计算;near
‑
sensor表示近传感计算;cim array为本公开实施例提出的所述的计算阵列;readout circuit表示外围数据读取电路;digital mac core表示使用传统数字电路架构实现的乘累加计算单元;adc表示analog
‑
digitalconverter,模数转换器;logic表示前述的乘累加计算单元的主题计算部分;memory指的是存储器;input vector length表示乘累加操作中输入向量长度;delay表示操作用时;power表示功耗。
[0175]
请参阅表2,表2给出了本公开实施例提出的存内计算装置及运算装置与其他现有工作的对比。
[0176]
表2
[0177][0178]
表2中,vlsi表示超大规模集成电路论坛(very large scale integration symposium)的简称,为集成电路领域的顶级会议。isscc表示国际固态电路大会(international solid state circuit conference),为集成电路领域的顶级会议。jjap表示日本应用物理期刊(japanese journal of applied physics),mac支持表示乘累加操作(multiplication
‑
and
‑
accumulation),是在边缘计算中最常见的运算形式。本公开实施例的存内计算装置及运算装置的实现1及实现2的tft具有不同的工艺。
[0179]
本公开实施例的系统可以以低电路复杂度实现高精度的存储和运算,同时,采用更为先进的工艺进行了估计,这一结果表明tft存算系统有着巨大的潜力,随着工艺水平的逐渐提升,本公开实施例的存内计算装置及运算装置将会得到更为广泛的应用。
[0180]
以上已经描述了本公开的各实施例,上述说明是示例性的,并非穷尽性的,并且也不限于所披露的各实施例。在不偏离所说明的各实施例的范围和精神的情况下,对于本技术领域的普通技术人员来说许多修改和变更都是显而易见的。本文中所用术语的选择,旨在最好地解释各实施例的原理、实际应用或对市场中的技术的改进,或者使本技术领域的其它普通技术人员能理解本文披露的各实施例。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。