一种基于校验矩阵的规则f-ldpc码参数盲识别方法
技术领域
1.本发明属于智能通信技术领域,具体为一种基于校验矩阵的规则f-ldpc码参数盲识别方法。
背景技术:
2.f-ldpc码是一种串行级联校验系统码,其编码器由外部编码模块、交织器以及内部校验编码器三个模块级联构成,f-ldpc码具有极高的码率灵活度以及便于简单高速硬件译码器实现的优点,在民用通信系统和军用通信系统中都有着较好的应用前景。f-ldpc码编码原理和校验矩阵生成机制详情可参考《the f-ldpc family: high-performance flexible modern codes for flexible radio》。信道编码的盲识别是第三方在非合作通信场景下获取通信双方所传信息的一种技术手段,在军事情报分析、智能通信等领域中有着广泛应用。对于截获传输信号的第三方,信号的编码参数等信息通常是未知的,需要通过对码字数据的分析识别出信道编码参数进而实现译码,完成从信号层到信息层的突破。f-ldpc码作为一种应用前景广阔的信道编码方法,其参数盲识别具有重要研究价值。
[0003] f-ldpc码的盲识别工作主要包含校验矩阵识别和参数识别两部分,其中如何识别f-ldpc码编码参数是复现f-ldpc码编码器以及结构化存储f-ldpc码校验矩阵的关键问题。而目前国内针对f-ldpc码的参数盲识别研究尚处于起步阶段,研究成果较少。
技术实现要素:
[0004]
本发明的目的在于:提出一种基于校验矩阵的规则f-ldpc码参数盲识别方法,该方法是在已知f-ldpc码完整校验矩阵的前提下,通过分析校验矩阵的重量特性和结构特性,实现f-ldpc码编码参数的识别,以降低通信系统中译码器的存储开销;所述识别参数包括重复参数、删除参数、等效随机交织。
[0005]
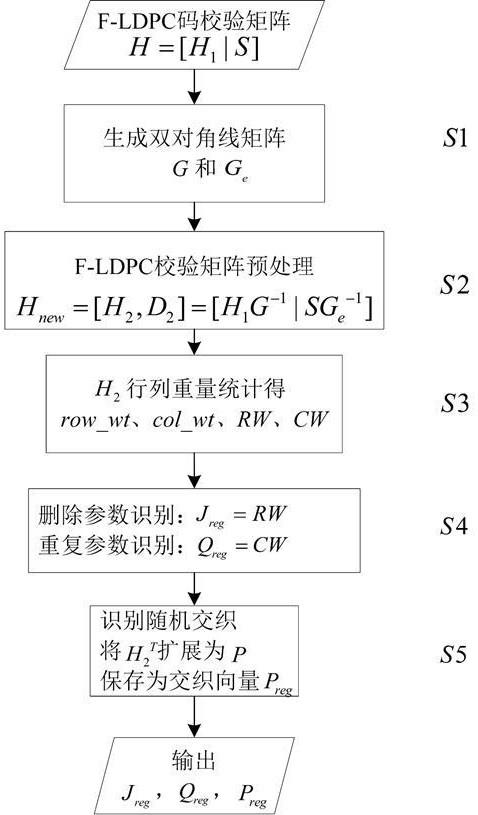
为实现上述目的,本发明采用如下技术方案:一种基于校验矩阵的规则f-ldpc码参数盲识别方法,该方法基于已知f-ldpc码的完整校验矩阵,实现f-ldpc码编码参数的识别;包括以下步骤:s1、根据f-ldpc校验矩阵的维数生成双对角矩阵和,;
s2、利用s1得到的双对角矩阵和对f-ldpc校验矩阵进行预处理,得到预处理后的校验矩阵;s3、统计预处理后校验矩阵的非对角线部分矩阵的行列向量的汉明重量;行向量汉明重量记为数组,列向量汉明重量记为数组;s4、根据编码原理,利用行向量的汉明重量识别删除参数,利用列向量的汉明重量识别重复参数;s5、根据s3得到的行列向量的汉明重量、s4识别的删除参数和重复参数、以及识别随机交织。
[0006]
进一步的,所述s2的详细操作步骤如下:根据校验矩阵维数对校验矩阵进行分区,有,其中是校验矩阵的非双对角线部分,是校验矩阵双对角线部分;令 ,其中,即为预处理后的校验矩阵。
[0007]
进一步的,所述s4按如下方法识别删除参数和重复参数:识别删除参数:统计中出现频次最高的元素记为rw,删除参数识别结果有;识别重复参数:统计中出现频次最高的元素记为cw,重复参数识别结果有。
[0008]
进一步的,所述s5采用随机交织盲识别算法识别随机交织,包括步骤如下:s5.1、记标准行向量重量,标准列向量重量;s5.2、对比s3中的统计结果与, 对比向量与向量,根据重量异常的行列位置确定中存在合并“1”的位置,以及该位置缺少的重量,并将中该位置的元素写为 ;s5.3、令,根据进行矩阵扩展,将维数为k行n-k列的扩展为行列的矩阵p;的第i行第j列的元素扩展为大小的矩阵块,块内填入个“1”,每次填入“1”后需判断扩展后的矩阵p每行、每列是否有且仅有一个“1”,是则继续扩展下一个块,否则重新扩展当前块;s5.4、全部元素扩展后得到随机交织矩阵p,恢复出的随机交织矩阵满足;根据随机交织矩阵与随机交织向量的映射关系将p保存为交织向量。
[0009]
本发明的有益效果:根据f-ldpc码校验矩阵能够完成f-ldpc码重复参数、删除参数以及随机交织的识别,识别所得参数可用于f-ldpc码校验矩阵结构化存储,以达到降低译码器开销的目的。
附图说明
[0010]
图1 是本发明实现的流程示意图;图2 (a)是实施例1中的f-ldpc码校验矩阵示意图;
图2 (b)是预处理后的校验矩阵示意图,图中黑点表示矩阵中该位置为“1”,空白表示矩阵中该位置为“0”;图3 (a)是实施例1中的f-ldpc码校验矩阵预处理后的非对角部分矩阵示意图;图3 (b)是根据扩展出的矩阵p,对应扩展关系如图中箭头所示,图中黑点表示矩阵中该位置为“1”,空白表示矩阵中该位置为“0”。
具体实施方式
[0011]
下面将结合附图和实施例,对本发明的技术方案进行进一步说明。
[0012]
本实施例的目的在于展现本发明的实现过程。
[0013]
假设在一次情报侦察行动中,某通信系统采用码长20比特,码率0.5的规则f-ldpc码作为其信道编码方案,f-ldpc码编码参数如下:重复参数为 ,删除参数为2,编码过程中随机交织向量为,对应的随机交织矩阵。信号侦测方通过截获上述通信系统发送的信号已经识别出该f-ldpc码的校验矩阵,但由于译码器存储能力有限无法存储整个f-ldpc校验矩阵,所以信号侦测方需要进一步对该f-ldpc码的编码参数进行识别,然后利用编码参数进行译码以达到降低译码器的存储开销的目的。如图1所示,编码参数识别方案具体执行如下:s1、输入的f-ldpc码校验矩阵如图2(a)所示,根据校验矩阵的维数生成双对角矩阵和,;s2、利用s1得到的双对角矩阵和对f-ldpc校验矩阵进行预处理,得到预处理后的校验矩阵,如图2 (b)所示;
[0014]
s3、汉明重量统计:统计预处理后校验矩阵的非对角线部分矩阵的行列向量的汉明重量,行向量的重量记为数组,列向量的重量记为数组;s4、根据s3得到的行列向量的汉明重量识别删除参数和重复参数;统计中出现频次最高的元素记为rw,删除参数识别结果有;统计中出现频次最高的元素记为cw,重复参数识别结果有。
[0015]
s5、识别随机交织:令,将扩展为20行20列的随机交织矩阵,的第i行第j列元素扩展为大小的矩阵块。扩展过程如图3所示,图3(a)中的扩展为图3 (b)中第
一个矩形框内的子矩阵,图3(a)中的扩展为图3(b)中第二个矩形框内的子矩阵,图3(a)中的扩展为图3(b)中第二个矩形框内的子矩阵,每次填入“1”后需判断扩展后的矩阵p每行、每列是否有且仅有一个“1”,以此类推将全部元素扩展。中所有元素扩展后得到图3(b)所示矩阵,即识别出的随机交织矩阵p,该矩阵每行、每列都有且仅由一个“1”。将交织矩阵p转化为交织向量保存,表示矩阵的第i列中“1”所在行的标号,识别结束。
[0016]
从实施例1中的识别过程可知重复参数与删除参数识别成功,识别获得的随机交织矩阵p与原编码随机交织矩阵虽然不相等,但是根据f-ldpc码校验矩阵生成原理,有,即根据识别所得随机交织生成的校验矩阵与原校验矩阵相等,识别所得交织为编码时的原随机交织等效。综上所述,本发明识别出了f-ldpc码的参数,,,识别结果可以用于f-ldpc码校验矩阵的结构化存储,降低译码器的存储开销,发明有效。
[0017]
为方便描述本发明的具体步骤,本实施例中采用码长较小的f-ldpc码作为识别目标,实际应用中码长通常为103比特至104比特量级,对应的f-ldpc校验矩阵规模很大,对译码器存储能力要求较高。
实施例
[0018]
本实施例目的在于验证本发明对于不同码长、码率的规则f-ldpc码参数盲识别的有效性。采用固定重复参数,删除参数,则f-ldpc码码率,码长比特,信息位为5000,4000,1500,350,190比特的f-ldpc码进行实验。使用本发明对校验矩阵进行识别,识别成功记为“√”,失败记为
“×”
,盲识别结果如表1所示。
[0019]
表1不同码率规则 f-ldpc码编码参数盲识别情况码率码长q识别j识别随机交织识别1/210000√√√2/36000√√√3/42000√√√7/8500√√√19/20200√√√从实施例2的实验结果表1可以看出,重复参数q、删除参数j以及随机交织皆能成功识别,本发明在已知完整正确的校验矩阵前提下,能够实现全码率、全码长的规则f-ldpc重复参数、删除参数及等效随机交织的正确识别。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。