1.本发明属于骨质疏松症风险预测技术领域,具体涉及一种基于关系网络的骨质疏松症风险预测方法。
背景技术:
2.骨质疏松症是一种以骨组织微结构退化、骨量减少为特征的骨骼疾病,其增加了骨脆性和骨折的风险。随着人口老龄化,骨质疏松症患病率迅猛增加。据调查,全球每年由骨质疏松症导致的骨折超过890万例。骨质疏松症总体呈现患病率高、低骨量人群庞大、知晓率低、治疗费用高和致残、致死率高的特点。因此,骨质疏松症风险预测和早期筛查具有重要意义。
3.当前,医学上对骨质疏松症的诊断主要通过测量骨密度的方式,包括双能x射线吸收测定法(dxa)、定量ct法(qct)、定量超声测定法(qus)和单光子吸收测定法(spa)等。其中,dxa是目前通用的骨质疏松症诊断指标,是骨密度测量的金指标。骨密度通常以t值形式呈现:t值为-1及以上属于正常,在-1至-2.5之间为低骨密度,-2.5及以下为骨质疏松。骨密度测量的主要局限在于,其依赖专业设备的支持和医护人员的操作,因此凸显了基于风险因素的骨质疏松症早期筛查的重要性。
4.目前主要使用的预警模型,筛查评估工具如:国际骨质疏松症基金会推荐的一分钟自测题、亚洲人骨质疏松自我评估工具(osta)、骨质疏松性骨折风险评估(frax)等。近年来,机器学习和数据挖掘方法在辅助医疗诊断中的疾病筛查和风险预测领域备受青睐。由于能够处理多因素间的复杂关系,基于机器学习的骨质疏松筛查模型表现明显优于传统线性风险评估模型。研究中主要常用的方法有:支持向量机(svm,support vector machine)、决策树和贝叶斯算法等。现有的预测算法大都使用单分类器模型,容错性差且性能有限。
技术实现要素:
5.本发明要解决的技术问题是克服现有的缺陷,提供一种基于关系网络的骨质疏松症风险预测方法,以解决上述背景技术中提出的现有的预测算法大都使用单分类器模型,容错性差且性能有限的问题。
6.为实现上述目的,本发明提供如下技术方案:一种基于关系网络的骨质疏松症风险预测方法,包括以下步骤:
7.步骤一:建立数据集,数据集由受试者生理指标和调查问卷结果两部分组成;
8.步骤二:问卷类数据包括疾病史、膳食习惯、吸烟、饮酒、体力活动情况等;骨质疏松症的有无为模型的输出变量,骨质疏松症的诊断以who推荐的t值参考范围为标准:降低程度≥2.5个标准差为骨质疏松;
9.步骤三:数据集有骨质疏松症4808人,正常11880人,分别占总样本的28.8%和71.2%,为不平衡数据集;
10.步骤四:数据集中,个人与对应的饮食习惯、病史等信息可视为两个互不相交的子
集,这两个子集共同组成了一个二部图结构;
11.步骤五:具体的,原始图表示为g=(v,e),v为顶点集、e为边集,v由u和v两个子集构成,分别表示个人和对应的属性,e包含了连接u中顶点与v中顶点的边,即个人连接到其对应的饮食或病史特征;
12.步骤六:将原始的个人-属性的二部图转换为个人-个人的单部图结构,其现实意义可以理解为:在筛选与骨质疏松症相关的病史特征和饮食习惯特征后,如果两个人有相同的病史或相同的饮食习惯,则认为他们之间存在潜在的关系,相同病史反映了疾病之间共享的分子机制或环境因素,而疾病基因之间有很高的相互作用倾向,往往以共病形式表现,饮食习惯反映了日常摄入的各类营养因素,而饮食中的生物化学成分对疾病具有复杂的影响,相似的饮食习惯可能导致他们与某种疾病具有关联性,因此网络中的个人是相互关联的,他们可能有类似相关的疾病基因,环境因素或饮食结构;
13.步骤七:特征集构建:特征集由个人特征和网络特征两个子集共同组成,用于构建关系网络的特征包括病史特征和饮食特征,病史特征包括高血压病史、糖尿病病史、慢性支气管炎病史、肺气肿病史、冠心病/心肌梗塞/心绞痛病史、高胆固醇血症史、骨折病史、痛风病史和类风湿性关节炎病史;饮食特征包括蔬果不足、蛋类不足、奶类不足、豆类不足、高糖饮食、高脂饮食和高钠饮食;
14.步骤八:选择常见的五种网络特征:介数中心性、接近中心性、特征向量中心性、度中心性和节点层面的聚类系数;
15.步骤九:模型构建:从数据集中构建图结构的关系网络,并提取相应的网络特征,网络特征与个人特征共同构成输入的特征集,并基于logistic回归、支持向量机(svm)、xgboost、catboost和随机森林五种算法建立骨质疏松症风险预测模型进行比较;
16.步骤十:模型评价方法:采用5项常用评价指标来评价预测模型的性能,分别为准确率(accuracy)、灵敏度(sensitivity)、特异性(specificity)和受试者工作特征(receiver operating characteristic,roc)曲线下的面积(area under the roc curve,auc)。
17.优选的,所述步骤一中,数据集来源于某三甲医院的健康体检中心,该数据集包含16688例完整样本,其中13818名男性,2870名女性,受试者年龄在18-78岁之间。
18.优选的,所述步骤一中的生理指标包含身高、体重、身体指数(body mass index,bmi)、腰围、血压值、空腹血糖值、血脂四项等。
19.优选的,所述步骤四中,预实验结果表明,原始数据集的不平衡会导致模型偏向将结果预测为正常。
20.优选的,所述步骤五中,该图的无向二部图表示:g=(u,v),分析二部图的常用方法是进行投影,转换为单部图进行分析。
21.优选的,所述步骤七中,筛选个人特征时,对连续变量使用皮尔逊相关系数,对分类变量使用卡方检验进行分析,选择相关性大的变量作为候选特征,最终选择的个人特征为:性别、年龄、身高、体重、体重指数、腰围、空腹血糖、血脂、血尿酸、吸烟、饮酒、体力活动情况。
22.优选的,所述步骤八中,网络特征含义分别如下:
23.介数中心性:计算图中所有节点对间的最短路径,若多条最短路径经过某节点,则
认为该节点介数中心性较高;
24.接近中心性:计算某节点到所有其他节点的最短路径之和,总距离越小,则认为该节点接近中心性越高;
25.特征向量中心性:若某节点与很多高中心性的节点相连,则该节点特征向量中心性较高。可简单理解为,邻居节点越重要,该节点越重要;
26.度中心性:节点的度数,即与该节点连接的节点数量;
27.聚类系数:该节点的相邻节点之间相互连接的程度,即该节点的两个邻居节点也相邻的概率。
28.优选的,所述步骤九中,数据集以8:2比例划分训练集和测试集,其中训练集用以构建预测模型,测试集用以评价模型性能,试验全部以python语言编写,抽取的关系网络以(起点,终点,权重)三元组形式的边集保存,网络相关的特征计算提取通过igraph库实现,随机森林、svm和logistic回归模型通过scikit-learn库实现,xgboost和catboost分别由各自算法包实现。
29.优选的,所述步骤十中,准确率指正确分类样本占总样本的比例,灵敏度是指预测为正的样本占全部正样本的比例。
30.优选的,所述步骤十中,特异性是指预测为负的样本占全部负样本的比例。
31.与现有技术相比,本发明提供了一种基于关系网络的骨质疏松症风险预测方法,具备以下有益效果:
32.1、本发明通过提取关系网络中的关联信息,改进了模型的学习效果,使模型性能得到提高;使用网络特征来代替繁冗的病史和饮食类特征,解决了高维数据问题;
33.2、本发明通过构建关系网络,提取网络特征加入机器学习模型来建立骨质疏松症风险预测模型,经过多模型比较验证,随机森林模型的性能最好,准确率达到86.2%,auc为0.93,研究同时进行了基于个人特征加网络特征、个人特征和全量特征三种模型性能的评估比较,其中加入网络特征后的模型性能显著高于个人特征模型与全量特征模型,且后两者表现十分相近;
34.3、本发明通过引入关系网络,从单个个体特征间的关系拓展到个体与个体间的关系分析,从更高维度建立模型来挖掘数据的潜在信息,加入网络特征后,模型性能得到显著提高,表明骨质疏松症患者在构建的关系网络中具有相似的特性,构建关系网络并加入网络特征后,模型效果的提升体现了骨质疏松症与其共病的关联性和饮食习惯对骨质疏松症的影响;
35.4、本发明通过试验结果验证,引入网络指标的模型性能相较个人特征模型和全量模型得到显著提高。基于关系网络的模型中,与logistic回归、支持向量机、xgboost和catboost四类算法相比,随机森林算法的骨质疏松症的预测效果最好,准确率86.2%,灵敏度80.9%,特异性88.3%,auc为0.93,这表明该方法的可行性及其在骨质疏松症预测中具有重要应用价值。
附图说明
36.附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制,在附图中:
37.图1为本发明提出的一种基于关系网络的骨质疏松症风险预测方法中关系网络构建示意图;
38.图2为本发明提出的一种基于关系网络的骨质疏松症风险预测方法的关系网络构建算法;
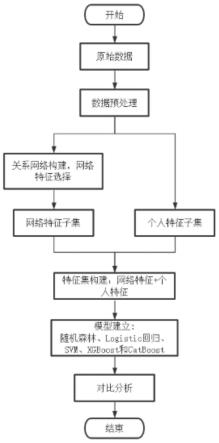
39.图3为本发明提出的一种基于关系网络的骨质疏松症风险预测方法的实验流程图;
40.图4为本发明提出的一种基于关系网络的骨质疏松症风险预测方法的不同模型的roc曲线;
41.图5为本发明提出的一种基于关系网络的骨质疏松症风险预测方法的随机森林模型特征重要性示意图;
42.图6为本发明提出的一种基于关系网络的骨质疏松症风险预测方法的网络特征组间分布箱线图。
具体实施方式
43.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
44.实施例
45.请参阅图1-6,本发明提供一种技术方案:一种基于关系网络的骨质疏松症风险预测方法,包括以下步骤:
46.步骤一:建立数据集,数据集由受试者生理指标和调查问卷结果两部分组成;
47.步骤二:问卷类数据包括疾病史、膳食习惯、吸烟、饮酒、体力活动情况等;骨质疏松症的有无为模型的输出变量,骨质疏松症的诊断以who推荐的t值参考范围为标准:降低程度≥2.5个标准差为骨质疏松;
48.步骤三:数据集有骨质疏松症4808人,正常11880人,分别占总样本的28.8%和71.2%,为不平衡数据集;
49.步骤四:数据集中,个人与对应的饮食习惯、病史等信息可视为两个互不相交的子集,这两个子集共同组成了一个二部图结构;
50.步骤五:具体的,原始图表示为g=(v,e),v为顶点集、e为边集,v由u和v两个子集构成,分别表示个人和对应的属性,e包含了连接u中顶点与v中顶点的边,即个人连接到其对应的饮食或病史特征;
51.步骤六:将原始的个人-属性的二部图转换为个人-个人的单部图结构,其现实意义可以理解为:在筛选与骨质疏松症相关的病史特征和饮食习惯特征后,如果两个人有相同的病史或相同的饮食习惯,则认为他们之间存在潜在的关系,相同病史反映了疾病之间共享的分子机制或环境因素,而疾病基因之间有很高的相互作用倾向,往往以共病形式表现,饮食习惯反映了日常摄入的各类营养因素,而饮食中的生物化学成分对疾病具有复杂的影响,相似的饮食习惯可能导致他们与某种疾病具有关联性,因此网络中的个人是相互关联的,他们可能有类似相关的疾病基因,环境因素或饮食结构;
52.步骤七:特征集构建:特征集由个人特征和网络特征两个子集共同组成,用于构建关系网络的特征包括病史特征和饮食特征,病史特征包括高血压病史、糖尿病病史、慢性支气管炎病史、肺气肿病史、冠心病/心肌梗塞/心绞痛病史、高胆固醇血症史、骨折病史、痛风病史和类风湿性关节炎病史;饮食特征包括蔬果不足、蛋类不足、奶类不足、豆类不足、高糖饮食、高脂饮食和高钠饮食;
53.步骤八:选择常见的五种网络特征:介数中心性、接近中心性、特征向量中心性、度中心性和节点层面的聚类系数;
54.步骤九:模型构建:从数据集中构建图结构的关系网络,并提取相应的网络特征,网络特征与个人特征共同构成输入的特征集,并基于logistic回归、支持向量机(svm)、xgboost、catboost和随机森林五种算法建立骨质疏松症风险预测模型进行比较;
55.步骤十:模型评价方法:采用5项常用评价指标来评价预测模型的性能,分别为准确率(accuracy)、灵敏度(sensitivity)、特异性(specificity)和受试者工作特征(receiver operating characteristic,roc)曲线下的面积(area under the roc curve,auc);
56.步骤十一:预测模型性能分析:使用80%数据作为训练集,20%作为训练集进行验证分析,对训练集使用十折交叉验证确定最优超参数,即将训练样本分为10组,每次取其中一组为验证子集,其余为训练子集,每一轮训练时,训练子集使用smote算法进行过采样处理,经过网格搜索后的主要参数设置为:随机森林n_estimators为200;catboost的max_depth为5,学习率0.01;xgboost的max_depth为6,学习率0.01;svm使用高斯核函数,使用测试样本对所有模型进行评估,随机森林模型的准确率和auc最高,分别为86.2%和0.93。boosting类的xgboost和catboost性能相近,xgboost准确率和auc分别为83.6%和0.89,catboost准确率和auc分别为85.7%和0.91,svm和logistic回归模型性能较差,svm准确率为80.8%,logistic回归准确率为75.6%各模型的roc曲线如图4所示。
57.本实施例中,优选的,所述步骤一中,数据集来源于某三甲医院的健康体检中心,该数据集包含16688例完整样本,其中13818名男性,2870名女性,受试者年龄在18-78岁之间。
58.本实施例中,优选的,所述步骤一中的生理指标包含身高、体重、身体指数(body mass index,bmi)、腰围、血压值、空腹血糖值、血脂四项等。
59.本实施例中,优选的,所述步骤四中,预实验结果表明,原始数据集的不平衡会导致模型偏向将结果预测为正常。
60.本实施例中,优选的,所述步骤五中,该图的无向二部图表示:g=(u,v),分析二部图的常用方法是进行投影,转换为单部图进行分析,关系网络构建示意图如图1所示,构建算法如图2所示。
61.本实施例中,优选的,所述步骤七中,筛选个人特征时,对连续变量使用皮尔逊相关系数,对分类变量使用卡方检验进行分析,选择相关性大的变量作为候选特征,最终选择的个人特征为:性别、年龄、身高、体重、体重指数、腰围、空腹血糖、血脂、血尿酸、吸烟、饮酒、体力活动情况。
62.本实施例中,优选的,所述步骤八中,网络特征含义分别如下:
63.介数中心性:计算图中所有节点对间的最短路径,若多条最短路径经过某节点,则
认为该节点介数中心性较高;
64.接近中心性:计算某节点到所有其他节点的最短路径之和,总距离越小,则认为该节点接近中心性越高;
65.特征向量中心性:若某节点与很多高中心性的节点相连,则该节点特征向量中心性较高。可简单理解为,邻居节点越重要,该节点越重要;
66.度中心性:节点的度数,即与该节点连接的节点数量;
67.聚类系数:该节点的相邻节点之间相互连接的程度,即该节点的两个邻居节点也相邻的概率。
68.本实施例中,优选的,所述步骤九中,数据集以8:2比例划分训练集和测试集,其中训练集用以构建预测模型,测试集用以评价模型性能,试验全部以python语言编写,抽取的关系网络以(起点,终点,权重)三元组形式的边集保存,网络相关的特征计算提取通过igraph库实现,随机森林、svm和logistic回归模型通过scikit-learn库实现,xgboost和catboost分别由各自算法包实现,实验流程如图3所示。
69.本实施例中,优选的,所述步骤十中,准确率指正确分类样本占总样本的比例,灵敏度是指预测为正的样本占全部正样本的比例。
70.本实施例中,优选的,所述步骤十中,特异性是指预测为负的样本占全部负样本的比例。
71.尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。